
株式会社truestar プロダクト開発部所属のしんやです。
当エントリでは、2025年09月11日(木)、12日(金)にグランドプリンスホテル新高輪 国際館パミールで開催された『Snowflake World Tour TOKYO 2025』のセッション『AI時代を見据えたANAグループのデータ戦略:Iceberg導入のリアルと今後の展望』の参加・聴講内容をレポートします。
セッション概要
公式サイトのセッションタイムテーブルによるセッション概要は以下の通りです。
セッションレポート
ここからは本セッションの参加・聴講内容をレポートします。
1. ANA's データマネジメント
-
各種情報紹介
- 登壇者自己紹介(北原氏)
- ANAグループの歴史と数字の紹介
- ANAグループの組織紹介
-
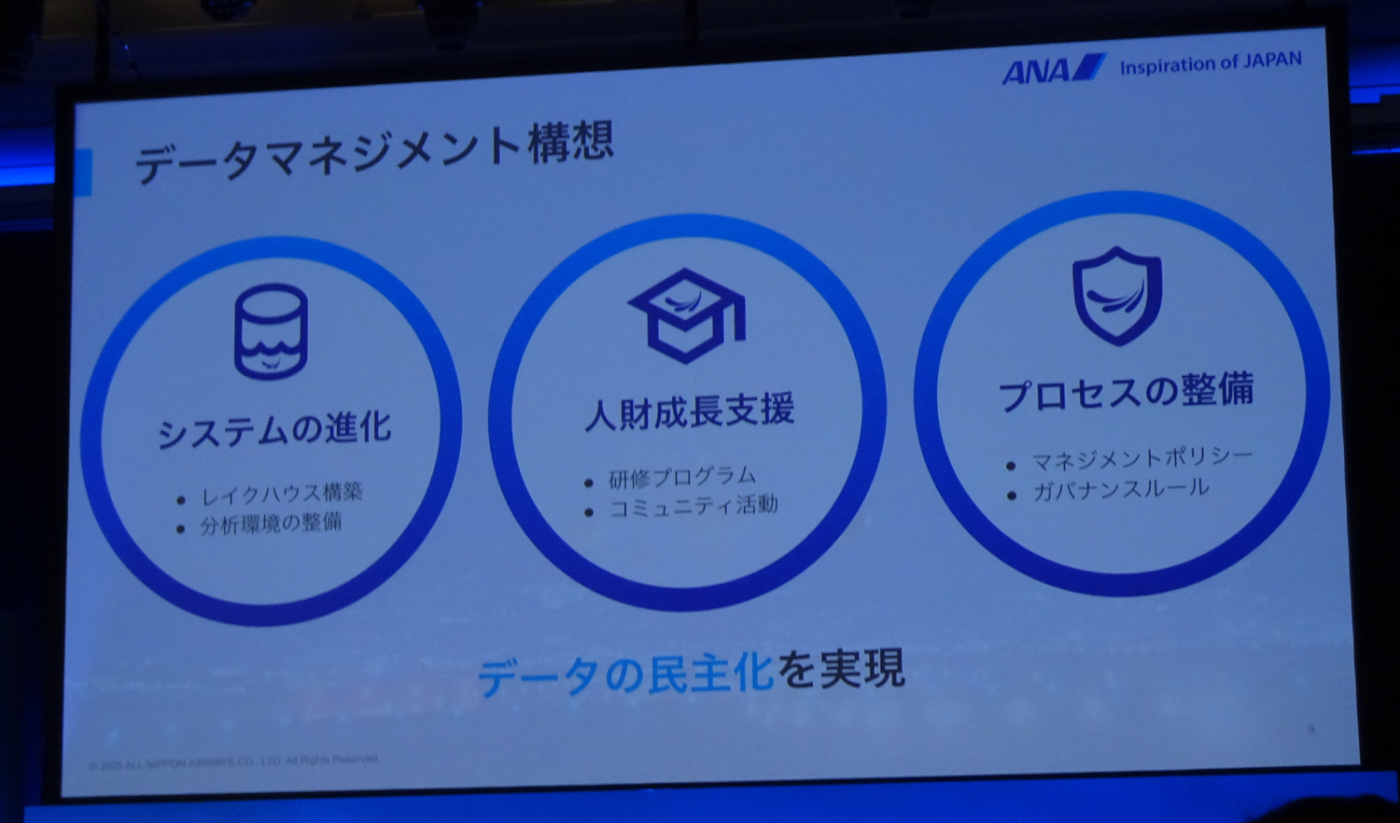
ANAグループの「データの民主化」に取り組むにあたり、データマネジメント構想を掲げ、3つの柱で推進してきた。本日は1つめにフォーカスを当てて紹介していく。
- システムの進化、データを扱う環境の提供
- 人材成長、データを扱う人材のスキルの底上げ
- プロセスの整備、データを扱う上でのルール策定を通じたガバナンスの担保
-
データの民主化を支える基盤を「BlueLake(ブルーレイク)」と命名して整備。整備ポイントは以下3つある。
- 1.疎結合なアーキテクチャ:技術の進化に追従できるように柔軟性と俊敏性を確保
- 2.中央集権的なデータ管理:Single Source of Truthを確立し、一貫性を向上
- 3.メタデータファースト:4万人のグループ社員へメタデータを解放
-
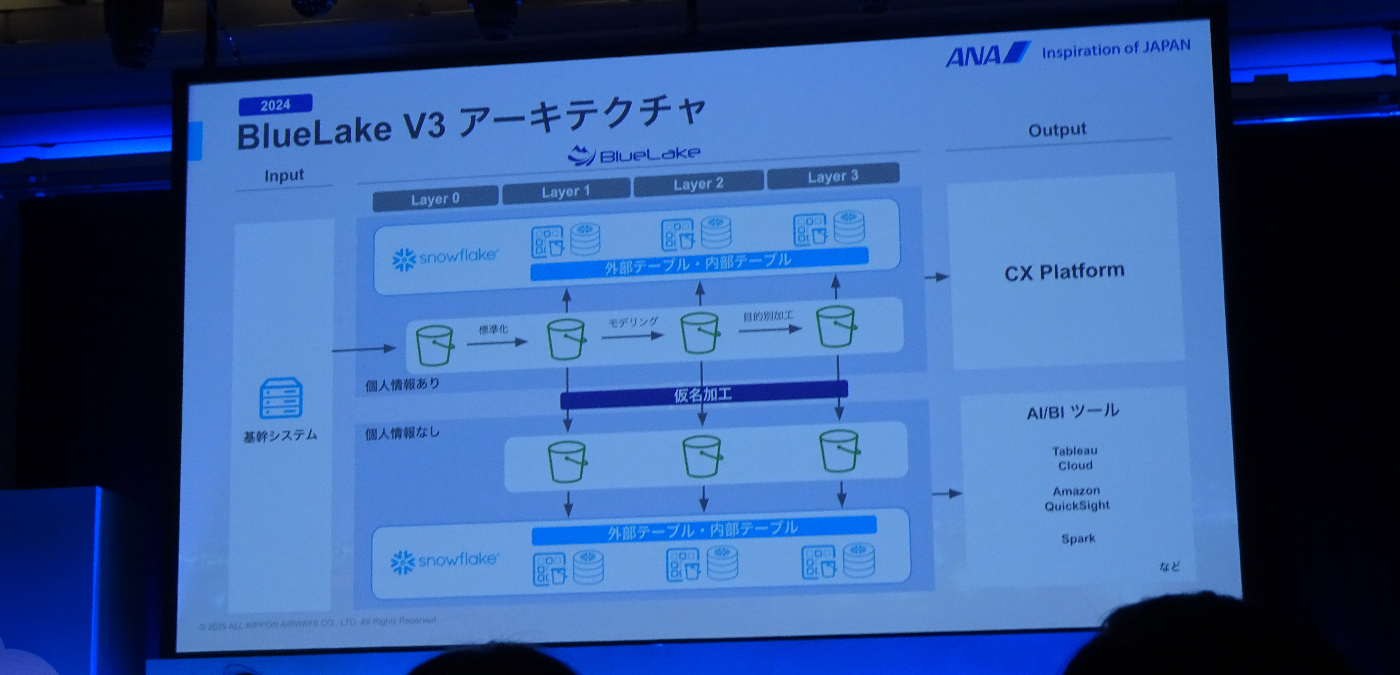
BlueLake v3のアーキテクチャ
- S3にデータを取り込み、そのデータをSnowflakeの外部テーブル、内部テーブルで公開
- メダリオンアーキテクチャ(データレイクにおけるデータ品質と構造を段階的に向上させるための設計パターン)を採用し、データをレイヤーで分けている
- データ量増加に伴い、幾つかの課題が出てきた。
- パフォーマンス:データ変換処理に時間が掛かるようになった
- コスト:S3と内部テーブルそれぞれでデータを持つことになり、ストレージコストが二重で発生
- メンテナンス負荷:内部にデータを持つことで他のDWHソリューションからのアクセスに手間
- 総合運用性:手作業開発していたのでヒューマンエラーが発生しやすい状況にあった
-
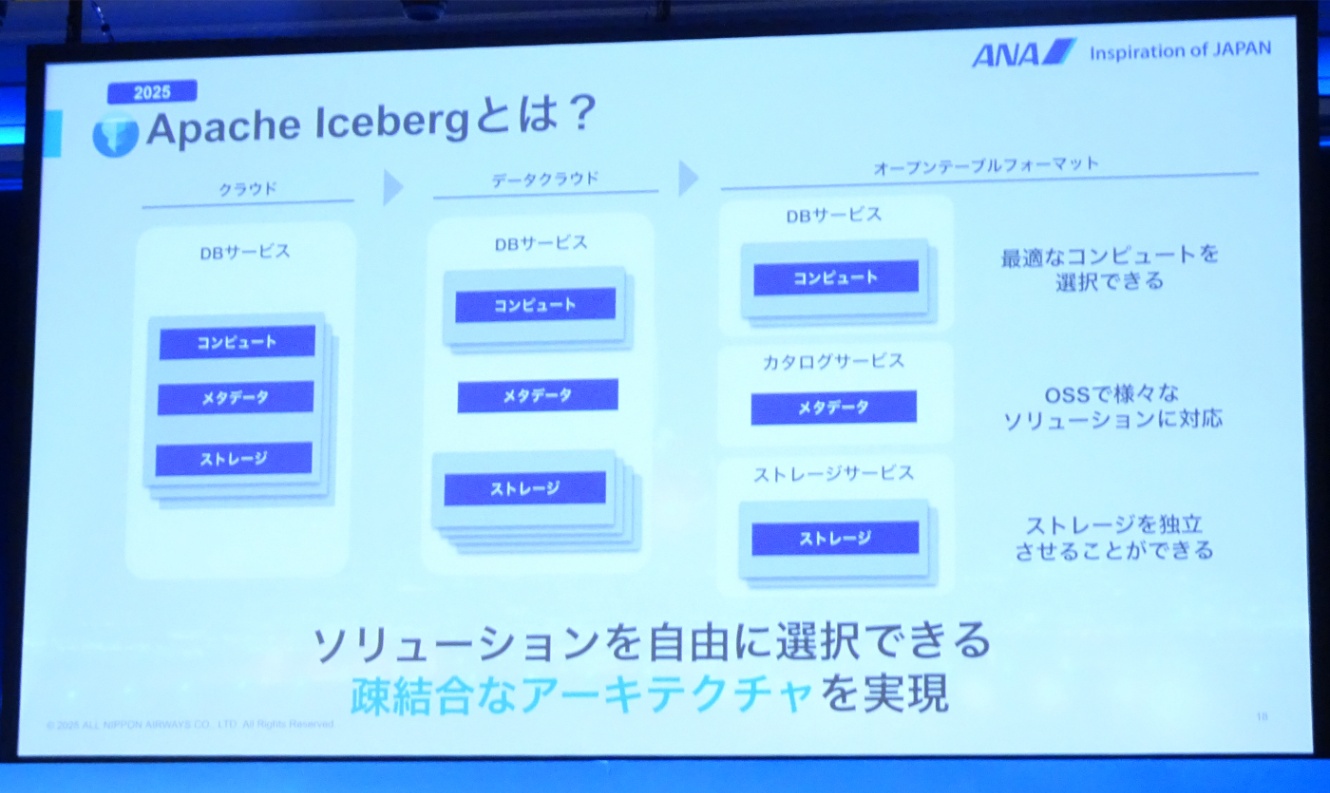
オープンテーブルフォーマット:Apache Icebergの採用
- BlueLake v3の課題を解決できるソリューションとして、最新アーキテクチャv4で採用。
- Icebergを中心としたBlueLake v4の開発を約2ヶ月で実施。
2. BlueLakeのアーキテクチャ解体新書
- 登壇者自己紹介(田中氏)
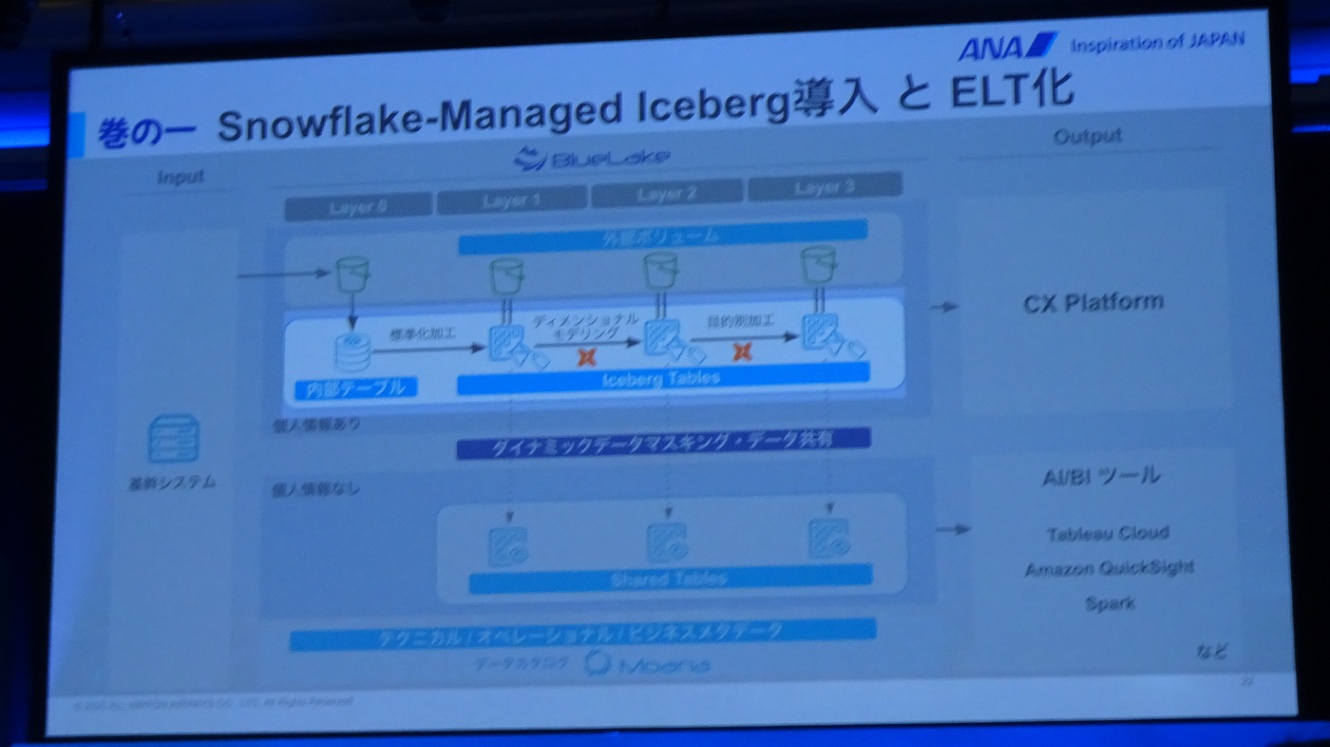
#1. Snowflake-Managed Iceberg投入とELT化
-
データはSnowFlake-Managed Icebergという共通フォーマットのテーブルへ取り込まれる
- Manage Apache Iceberg™ tables | Snowflake Documentation
- Icebergの利点:S3にファイルを保管しておきながら、Snowflake内部テーブルと同等のプレイパフォーマンスを発揮
-
データの変換・加工はELT(データをウェアハウス投入後にSnowflakeのパワフルなエンジンで対応)で行う方針に
- dbt Projects on Snowflakeを活用する事で効率的で宣言的にデータパイプラインを構築
- 結果、可結合による相互運用性の確保、クエリパフォーマンスの向上、そして、データ加工の効率化という3つのメリットを実現することができた

#2. ストレージの集約化とマスキングの効率化
- データの保管方法とマスキング方法:コストと運用負荷にダイレクトに効いてくるとても重要なポイント。
- v3時代では「個人情報データ」と「個人情報を隠したマスク済のデータ」をそれぞれ持っていた
- v4では1箇所に集約
- ダイナミックデータマスキング(アクセスするユーザーの権限に応じて、リアルタイムでデータを動的にマスキング)で対応
- 結果、ストレージの量を約70%削減。また、データの重複が減り、複雑さからも解放され、ガバナンスが強化された。

#3. Icebergテーブル生成の自動化
-
EXCELを編集するだけで正確、高速にテーブルを更新できる仕組みを確立。
- 従来の手順は手作業によるものだった。
- 最新のテーブル設計書をEXCELでダウンロード:常に最新の定義に基づいて作業を始められるようになった
- EXCELにはフォーマットに従って設計を定義:エンジニアでなくても直感的に編集が可能に
- 設計書をS3にアップロード&チェック
- 承認完了後設計書の情報に基づいて本番環境にIcebergのテーブルやタグが生成される
- 以上、Pull/Design/Check/Applyのサイクルを回すことで開発効率の向上とヒューマンエラーなどの防止ができるようになった。

なぜSnowflake-Managed Icebergを採用したのか
- なぜ選んだのか?
- 既存データを直接参照する外部テーブル、データを直接Snowflakeに取り込む内部テーブルはそれぞれに課題があった。
- Icebergはコンピュート、カタログ、ストレージを完全に分離できるため、将来にわたって技術選択の自由度を確保できると判断。
- 課題の1つであったパフォーマンス面においても外部テーブルと比較して大きく向上が見込めると確認出来た。
- また、Icebergを選んだ最大の理由は「マネージド(Managed)」の部分。パフォーマンスの最適化や、コンパクションといった煩雑なテーブルのメンテナンスを、すべてSnowflakeが自動で行ってくれる。
- 外部カタログでの運用方式と比べると確かに相互運用性は劣るが、Snowflake-Managed Icebergには外部カタログにSnowflakeオープンカタログへテーブル情報を自動的に同期する機能が備わっている。これにより採用を決めた。

BlueLake v4稼働後の変化
- 3つの点で劇的な改善を達成
- 開発工程の期間短縮:約半分に
- データ移行作業の期間短縮:約300テーブルのデータ移行作業に、V3では約20日間かかってたのがV4ではわずか1日で完了
- ランニングコスト:90%(!)も削減出来た

3. AI時代を見据えたデータ戦略
- これからはAIが自らタスクを組み立てて、必要なデータを集めて実行する、自律的に動くAIの時代。人だけではなく、AIがデータを扱う時代に変化していくと考えている。
- AIがデータを理解し、必要なデータを選択できるようにするための環境を整備する必要がある。それを叶えるのがセマンティックレイヤー(Semantic Layer)。
- データを意味付けする層であり、データを活用する人やAIと、データを蓄積するデータベースの間に位置。
- セマンティックレイヤーには、項目や指標の説明、その計算ロジック、ビジネスルールが含まれており、みんながセマンティックレイヤーを使うことで共通の指標でデータを分析、活用できるようになる

- まとめ
- ANAのデータマネジメントにおいては基本方針は変わらない。しかし、今まで以上にメタデータ管理が重要になってくる。
- これまで通りのデータマネジメントを着実に進め、より一層メタデータファーストを設定することで、AI-Readyなデータ基盤に進化できると考えている。
まとめ
以上、Snowflake World Tour 2025のセッション『AI時代を見据えたANAグループのデータ戦略:Iceberg導入のリアルと今後の展望』のイベントレポートでした。
SnowflakeでのIceberg活用に関しては我々も注目していましたが「便利そうなのはわかるがパフォーマンス面での性能は果たしてどんな感じなのだろうか」と思ってもいました。今回このセッションを拝聴し、パフォーマンス面の懸念は払拭でき、またそれ以上に良い面・メリットが多く「こりゃ使わない手は無いな」と思うに至りました。とてもいい話が聞けたセッションだったと思います。ありがとうございました!
