
AIと連携し、Excel感覚で操作できるクラウドBIサービス、Sigma(Sigma Computing)。
当エントリでは、Sigmaの機能として提供・実装されている『Materialization』(マテリアライゼーション)について、Sigma Quickstartで展開されているチュートリアル『Materialization with Sigma』を試してみた内容を紹介していきます。
#1. 概要
Sigmaにおけるマテリアライゼーション(Materialization)に関しては、先日投稿した下記エントリにて紹介しています。合わせてお読み頂けますと幸いです。
そして当エントリの内容は下記環境・状況を想定して進めていきます。いずれもトライアルアカウントとして用意した環境で実践に臨みました。
- Snowflakeアカウント(適切な管理者権限とセキュリティ管理者権限を持っていること)
- Sigmaアカウント(Sigmaデータセットへの接続で書き込み権限が有効になっている必要あり)
#2. ユースケース背景
Sigmaにおけるマテリアライゼーションも基本性能・特徴は他サービスでも実装・提供されているようなものと同様です。所謂"キャッシュ"の一種で、クエリ結果をデータウェアハウス内のテーブルに書き込み、定期的に(多くの場合は毎日)更新しておくことでクエリが実行されるたびに結果を再計算するよりも効率的かつ迅速にアクセスできるようにする...という代物です。
マテリアライゼーションの利用することによる主なメリット主な利点は以下の通り。
-
クエリパフォーマンスの向上:
- マテリアライズドテーブルは繰り返し計算の必要性を排除し、クエリ応答時間を短縮。
-
リソース消費の削減:
- マテリアライズドテーブルは結果を事前に計算して保存することで、クエリ実行に必要な計算リソースを削減し、リソース利用効率を向上。
-
クエリ最適化:
- マテリアライズドテーブルは、特定のクエリパターンに合わせてインデックスを作成し、最適化できるため、パフォーマンスがさらに向上。
-
同時実行性の向上:
- マテリアライズドテーブルは事前に計算された結果を保存するため、複数のクエリを互いに干渉することなく同時に実行でき、システム全体の同時実行性が向上。
-
データパイプラインの簡素化:
- マテリアライズドテーブルは、中間結果または最終結果を簡単に保存および再利用できるようにすることで、複雑なデータパイプラインを簡素化。
#3. 考慮事項
Sigmaでは、以下のユースケースにおいてユーザーがマテリアライゼーションのメリットをすぐに享受できる...としています。
- 複雑な結合のフラット化
- データの粒度の低減(集約されたテーブルレベルのマテリアライゼーション)
- 処理の遅い計算(JSON 抽出など)のフラット化
- 永続的で制限的なフィルターを適用する場合(例えば、1億行あるが、分析に関連するのは5万行のみの場合など)
マテリアライズ化によってメリットを得られるユースケースは多岐にわたります。例えば以下のようなケースが代表的なものとして挙げられるでしょう。
- 複雑でリソースを大量に消費するクエリ
- データ分析とレポート作成
- 時間依存データ
- リソース管理
- ニーズに合わせた粒度の調整
- 頻繁にアクセスされるデータ
#4. オプション
ソフトウェア市場では、特定のニーズや使用している技術スタックに応じて、キャッシュ/マテリアライゼーションのための複数のオプションが利用可能です。マテリアライゼーションのための一般的なオプションを以下に示します。
- 1).データウェアハウスソリューション(およびほとんどのRDBMS):
- Amazon Redshift、Google BigQuery、Snowflakeなどのデータウェアハウスプラットフォームは、大規模なデータ分析ワークロードを処理するために設計されています。
- これらのプラットフォームは、マテリアライズドビュー、キャッシュメカニズム、クエリ最適化手法など、マテリアライズ化に最適化された機能を提供することで、クエリパフォーマンスを向上させます。
- 2).インメモリデータベース:
- SAP HANA、Redis、Apache Igniteなどのインメモリデータベースは、データをディスクではなくメモリ内に格納するため、クエリパフォーマンスを大幅に向上させることができます。
- これらのデータベースは、列指向ストレージ、データレプリケーション、頻繁にアクセスされるデータの事前ロードなど、データのマテリアライズ化のための組み込みメカニズムを備えていることがよくあります。
- 3).キャッシュシステム:
- MemcachedやRedisなどのキャッシュシステムは、頻繁にアクセスされるデータをマテリアライズ化するために使用できます。クエリ結果や計算済みデータをメモリ内に格納することで、これらのシステムは迅速な取得を可能にし、繰り返し計算の必要性を軽減します。
- 4).カスタムデータパイプラインとETLプロセス:
- 場合によっては、データパイプラインやETL(抽出・変換・ロード)プロセスを用いたカスタムマテリアライゼーションソリューションの実装が必要になることがあります。
- dbt Labs, Apache Airflow, Apache Sparkなどのツールやカスタムスクリプトを利用することで、マテリアライゼーションプロセスをスケジュールおよび自動化し、マテリアライズされたデータが常に最新の状態に保たれるようにすることができます。
マテリアライゼーションオプションの可用性と具体的な機能は、選択するソフトウェアによって異なる場合があります。お客様の要件、既存のインフラストラクチャ、そして組織で使用しているテクノロジースタックに基づいて、これらのソリューションの機能、拡張性、使いやすさ、そして統合の可能性を評価することが重要です。
5. Sigmaを使って実現するか否かを判断
Sigmaを使用して実現することによる「明白な利点」は幾つか存在します。
- Sigma を使えばブラウザで簡単にセットアップできるので、非常にシンプルかつ迅速に作業できる
- データエンジニアリングの専門知識は不要で、開発サイクルを短縮できる
- ロールベースのアクセス制御により、マテリアライズできるユーザーを制限できる
- マテリアライズされたデータはCDW内に保存される
- Sigmaが複雑な処理をすべて自動的に管理するため、時間と労力を節約できる
Sigmaを使用してマテリアライズを行う場合、Sigma内でマテリアライズを実行できるユーザーを制御することが重要です。デフォルトでは、Sigma 管理者のみがマテリアライズを実行できます。また、「マテリアライズを実行できるクリエイター」というカスタムアカウントタイプを作成し、そのユーザーにマテリアライズ権限を付与することもできます。
Sigmaにおけるマテリアライズの実行権限は、何らかの方法で管理する必要があります。通常、多数のクリエイターが、重複する可能性のある数百、数千ものオブジェクトをマテリアライズすることは望ましくありません。SigmaのRBACシステムを使用して、特定の少数のクリエイターにマテリアライズ権限を付与するのが一般的です。
- How to Configure Role-Based Access Controls inside Sigma | Sigma
- Use Role-Based Access Control (RBAC), No More Micromanaging Permissions | Sigma
#6. 初期設定
ここからは実際に環境準備と実践を進めていきます。実装周りのSigma Materializationに関する特徴やポイントは以下の通り。
- Sigmaのクエリコンパイラは、最新のマテリアライゼーションを自動的かつ透過的に使用
- Sigmaに表示されるすべてのデータは、ウェアハウス(今回のQuickstartの場合はSnowflake)から直接クエリされる
- Sigmaの実装では、データセットによって生成されたSQLクエリの結果セットを格納するために
CREATE TABLE ASステートメントが使用される - 複数のグループ化レベルを含む Sigma テーブルをマテリアライズするには、マテリアライズするグループ化レベルを選択
- マテリアライズは、スケジュールに基づいて設定することも、Sigma APIを介してトリガーすることもできる
- データセットをマテリアライズすることで、非常に複雑なクエリを単純な
SELECTにフラット化できるため、下流のすべてのクエリの負荷が大幅に軽減される - Sigmaのマテリアライゼーションには、データセットの接続で書き込みアクセスが有効になっている必要があり、組織管理者であるか、マテリアライゼーション権限を持つカスタムアカウントタイプが割り当てられている必要がある
Snowflake環境の準備
Sigmaでデータをマテリアライズする際に使用するデータベースとスキーマをSnowflakeに作成する必要があります。SnowflakeのアカウントにAccountAdminとしてログインし、以下の処理を実行します。
-- SELECT WAREHOUSE
--// use WAREHOUSE COMPUTE_WH;
-- CREATE DATABASE AND GRANT USAGE
--// CREATE DATABASE if not exists SIGMA_WRITEDB;
--// use DATABASE SIGMA_WRITEDB;
--// grant usage on database SIGMA_WRITEDB to role ACCOUNTADMIN;
-- SCHEMA AND GRANT USAGE
--// CREATE SCHEMA QUICKSTART;
--// grant usage, create table, create view, create stage on schema QUICKSTART to role ACCOUNTADMIN
/** 当エントリをイチから環境準備する場合は上記SQLクエリを実行。 */
/** 今回実践した際は上述理由により下記SQL文のみを実行する形で進めました. */
USE DATABASE SIGMA_WRITE_ACCESS_DB;
CREATE SCHEMA MATERIALIZATION_TEST;
GRANT USAGE, CREATE TABLE, CREATE VIEW, CREATE STAGE ON SCHEMA MATERIALIZATION_TEST TO ROLE ACCOUNTADMIN;
書き込みアクセスの設定
次いで、Sigmaにおける書き込みアクセス(Write Access)に関する設定を行います。こちらの設定についても、詳細設定は下記エントリ実践の際に用意したものがありますのでそれを流用し、当エントリでの解説は割愛します。ご了承ください。

(対象データ接続設定がWrite access = EnabledになっていればOKです)
#7. Sigmaにおけるマテリアライゼーション
当項ではSigmaにおけるマテリアライゼーションの実装について、概要を説明します。
- マテリアライゼーションは、マテリアライゼーションをスケジュールすることで作成されます。マテリアライゼーションのスケジュールはデータの鮮度に影響を与えます。Sigmaに表示されない長時間実行クエリもマテリアライゼーション可能です。
- マテリアライゼーションにはスケジュールを 1 つだけ含めることができますが、スケジュールには複数のマテリアライゼーションを含めることができます。
- マテリアライゼーションは、いつでも一時停止(手動で、またはユーザーが指定した未使用期間後)したり、削除したりできます。
- マテリアライゼーションスケジュールを削除すると、対応するウェアハウステーブルが24時間以内に削除されます。
制限事項
パラメータまたはシステム関数を使用するデータセットではマテリアライゼーションは利用できませんが、いくつかの例外があります。
- 例えば、システム関数
Today()は動作します。これらのデータセットは、パラメータが変更されると異なる値を返すことが想定されています。 - 一方、マテリアライズドテーブルは常に同じ値(マテリアライゼーション実行時のデータセットの固定出力)を返します。そのため、パラメータまたはシステム関数を使用するデータセットのマテリアライゼーションバージョンを使用すると、予期しない結果が生じる可能性があります。
マテリアライゼーションは行レベルセキュリティと互換性がありません。行レベルセキュリティ(ユーザー属性)関数を参照する場合、マテリアライゼーションでエラーが発生します。
複製または結合によって他のデータセットを参照するデータセットは、通常はマテリアライゼーションできます。ただし、基になるデータセットのいずれかがマテリアライゼーションできない場合は、この限りではありません。
#8. シンプルなマテリアライゼーション(Simple Materialization)
このQuickstart実践では、Snowflakeが提供するサンプルデータベース「TPCH_SF10」を利用します。このデータベースには、9列 1,500万行からなるORDERSテーブルが含まれています。
通常、マテリアライズ時にテーブルの結合、グループ化、計算列の追加を行うには、Sigmaを使用します。前述のように、フラットテーブルではマテリアライズのメリットはありません。
データには結合と計算列が含まれていると仮定しますが、Sigmaでそれらの操作方法を理解していることを前提としているため、このセクションではそれらの作業は省略します。まずは、Sigmaでマテリアライズを行う方法に焦点を当てます。より複雑なグループ化されたテーブルの例については、後ほど説明します。
Sigmaにログインし、管理メニューから[Connection]を選択。該当の接続を選択。

接続詳細の[Browse connection]を選択。
SNOWFLAKE_SAMPLE_DATA → TPCH_SF10 → ORDERSを選択。データがプレビュー表示されるので画面右上の[Explore]を押下。
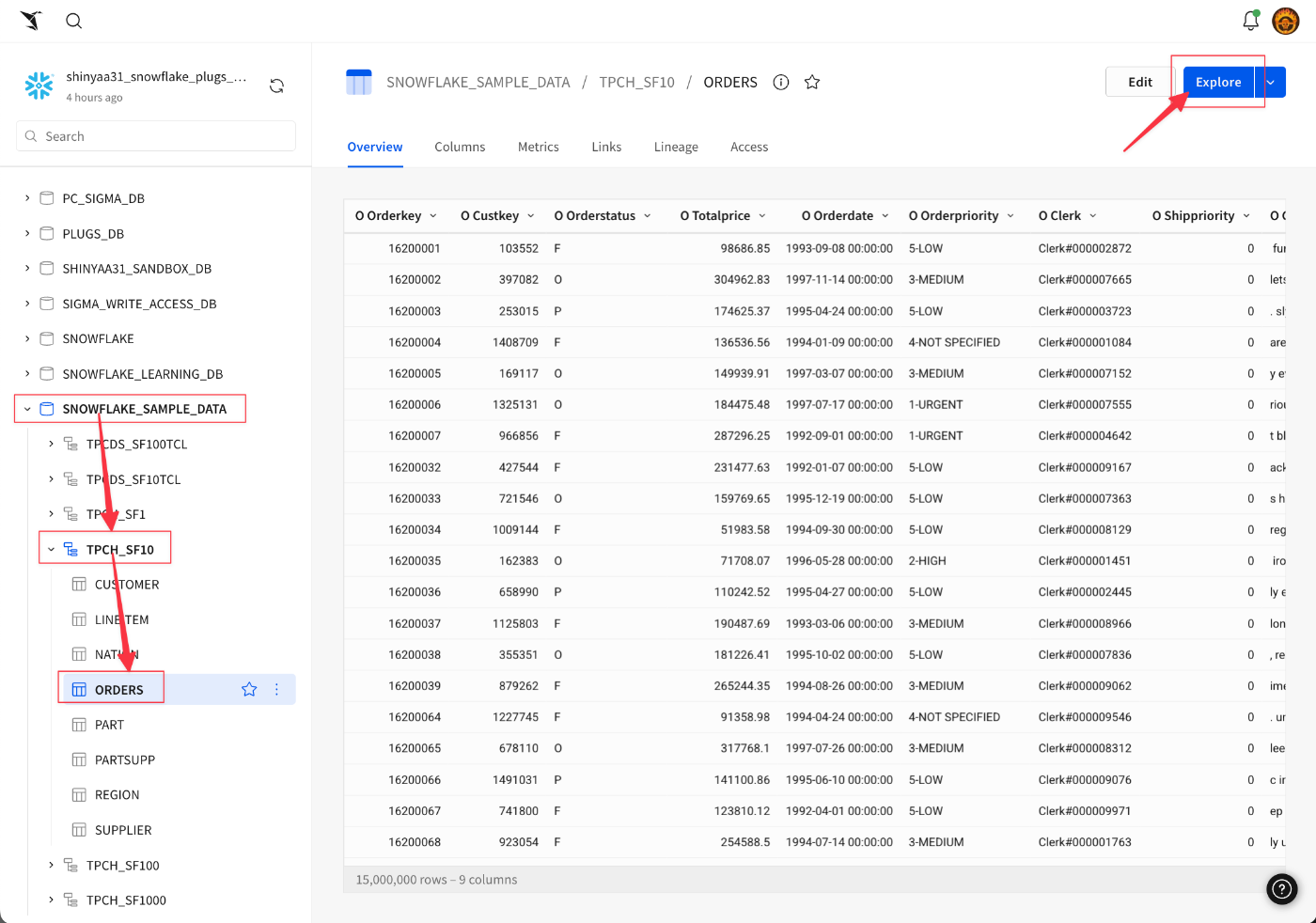
未保存のワークブックでOrdersテーブルが開かれました。すべての列が選択されており、1500万行が利用可能となっています。

このワークブックを任意の名前を付けて保存します。
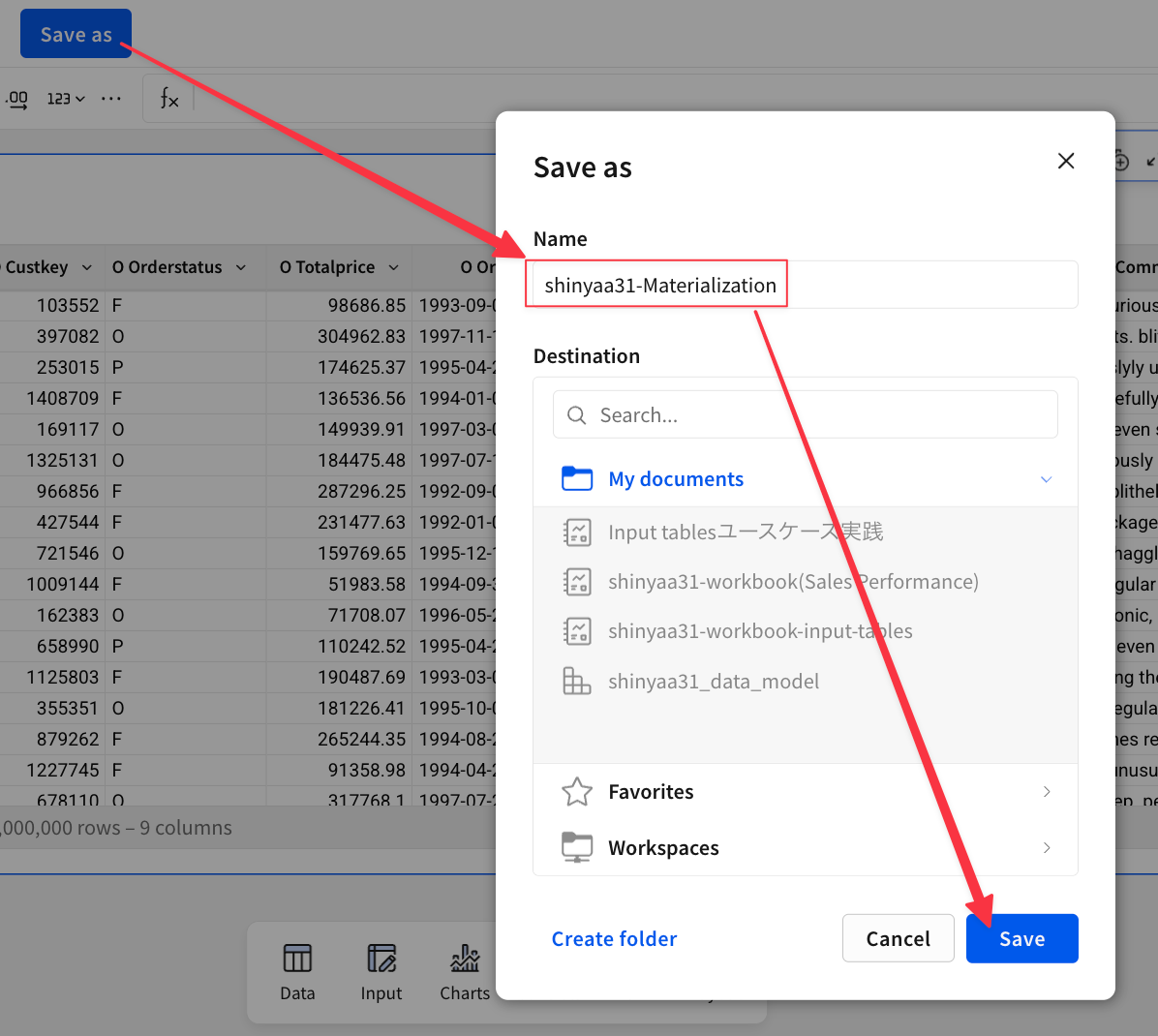
保存したワークブックのテーブルにある3点メニューから[Advanced options]→[Schedule materialization...]を選択。
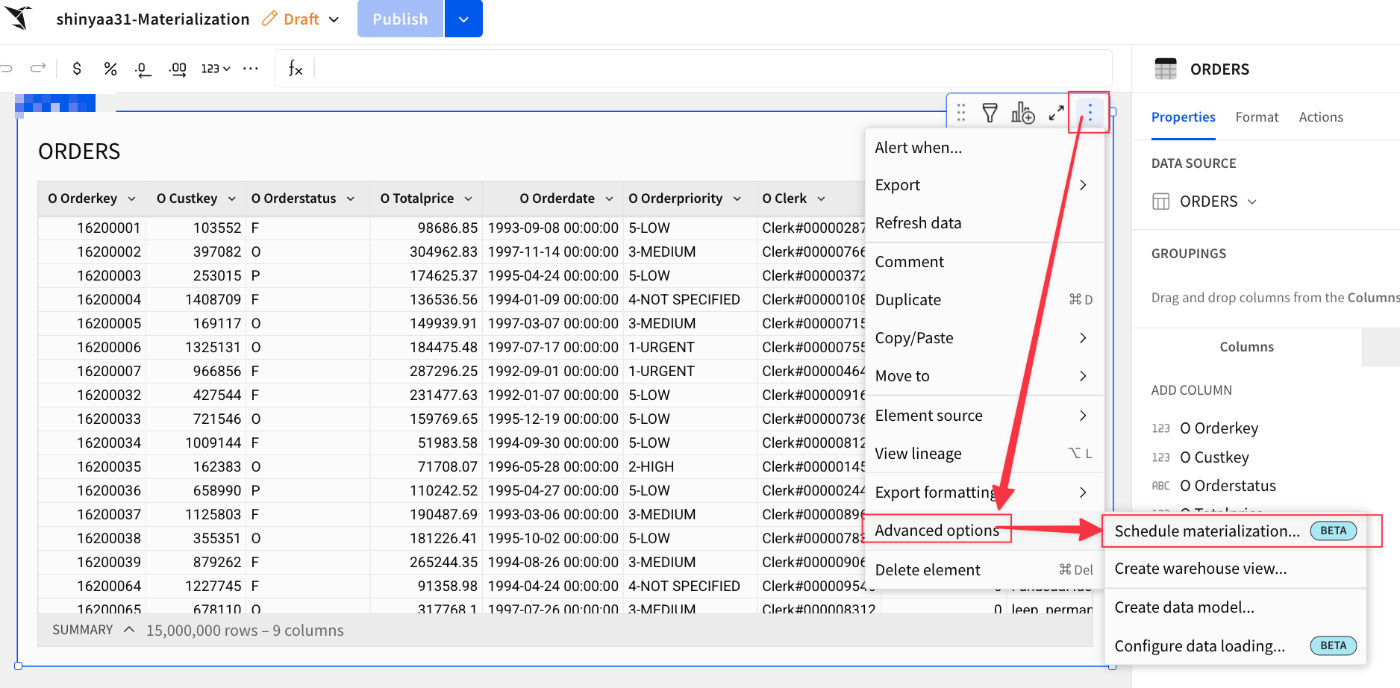
スケジュール画面では、このマテリアライズを実行する時間を1つ以上設定できます。
ワークブックには要素が1つ(ページ1 - 注文)しかなく、グループ化もされていないため、これが選択されています。ここではスケジュールを1日1回、午前3時45分に、タイムゾーンを指定して実行するように設定してみました。[Save Schedules]押下。

スケジュールが作成されました。実行前なのでステータスは[Pending]となっています。

時間が来てスケジュールが実行され、ステータスが[✅️Success]に変わっていました。

Administration > Materializationsに戻り、現在のジョブのリストを確認します。ここでは、最後の実行のステータスと所要時間を確認できます。今回の実行内容は所定のウェアハウスを使用して17秒で1500万行が処理されていたようです。

作成したワークブックのORDERSテーブルに移動し、[View materialization info] (iマークアイコン)をクリック。最新の実行情報とMaterialize now(今すぐマテリアライゼーション)、View schedule(スケジュールを表示)へのリンクが表示されます。

ここは試しにMaterialize nowのリンクを押下してみます。処理キューが即座に作成され、
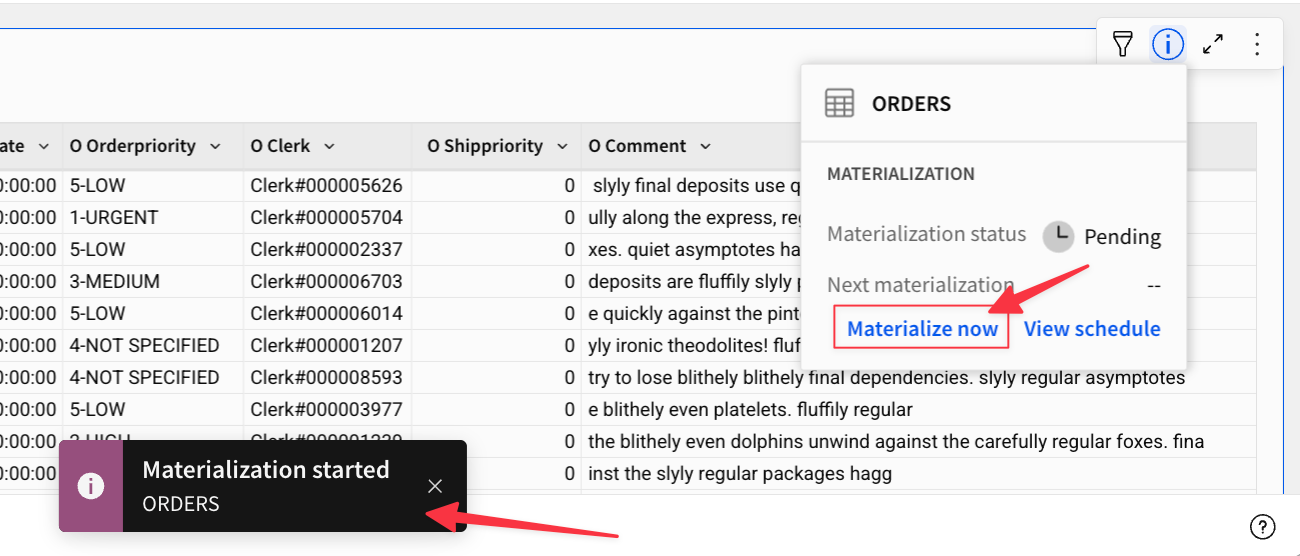
実行が為されました。しかし結果としては(前回のマテリアライゼーションから変化変更が無かったため)、マテリアライゼーションの処理自体はスキップされています。

#9. Snowflakeのマテリアライズドテーブル
ここまでの処理でSigmaが9列、1500万行の構成に基づいてSnowflakeに新しいテーブルを作成したことがわかりますが、列データは読み取り可能な形式ではありません。この"スクラッチスキーマ"はSigmaによって管理されており、Sigmaユーザーには透過的です。

マテリアライゼーションにより、データ ウェアハウスが要素または子要素となるSigma分析で使用されるときにデータの再計算を回避できるため、クエリパフォーマンスが向上します。
他のアプリケーションからこのデータにアクセスするには、Sigmaのデータセットウェアハウスビュー機能を参照してください。
#10. ワークブックのマテリアライゼーション
ワークブックのマテリアライゼーションはデータセットに似ていますが、ユースケースのニーズに応じた大きな利点があります。
- ワークブックの任意の要素(テーブル、ビジュアライゼーション、ピボット)をマテリアライゼーションし、別の要素のデータソースとして使用できる
- ワークブックのマテリアライゼーションは、公開時によりスマートな更新を実現する
- ドキュメントを公開すると、必要な場合にのみマテリアライゼーションが更新される。たとえば、マテリアライゼーションされた要素が変更されていない場合、マテリアライゼーションは実行されない。
- データセットは、公開時に常にマテリアライゼーションを更新。これは、データセットが非常に大きい場合、ウェアハウスコストの観点から重要である
- ワークブックのマテリアライゼーションは、さまざまな参照レベルをサポート
- グループ化レベルは個別にマテリアライゼーションできる
- データセットは、1つのグループ化レベルでのみマテリアライゼーションされる
- マテリアライゼーションは、ワークブックの表示と編集時に使用される
- データセットは編集モードではマテリアライゼーションを使用しない
- ワークブック閲覧者には、新しい「アラート」センター(アプリ内通知と統合予定)とトーストでマテリアライゼーションのアクティビティが通知される
これを証明する最も簡単な方法として、Sigmaテンプレートを"ワークブック"として使用してみましょう。
Sigmaの画面左側メニューからTemplateに移動し、Plugs Electronics Sales Performanceテンプレートを選択。

独自のデータを使用するかどうかを尋ねるポップアップは閉じてください。
右上の「名前を付けて保存」をクリックし、ワークブックに任意の名前を付けます。

ワークブック内グラフのドロップダウンメニューをクリックすると、基盤となるデータをマテリアライズできることがわかります。

ビジュアライゼーションはグループ化されたデータを基盤とすることが多いため、これはグループ化されたデータをマテリアライズする最初の例です。この例では、Sigmaが複雑な処理をすべて処理します。最初にダッシュボードを設計し、「ちょうど良い」状態にしてから、スケジュールに基づいてどの部分をマテリアライズするかを決定することも可能です。
#11. 集約ナビゲーション(Aggregate Navigation)
集計ナビゲーション(Aggregate Navigation)は高度なBI設計であり、異なる粒度の複数のマテリアライズドテーブルをバックグラウンドで作成し、ユーザーが分析粒度を変更すると、これらのテーブル間でデータソースをシームレスに切り替えることができます。
集計ナビゲーションのメリットは、高粒度の分析における高速なパフォーマンスと、低粒度の分析における詳細な分析を両立できることです。これらはすべてエンドユーザーからは透過的で、目に見えません。
従来のBIツールでは、集計ナビゲーションの作成にかなりのコストがかかります。これは、複数の集計テーブルを手動で作成してデータを入力し、それらのテーブル間を自動で移動するための高度で記述の難しい計算式を追加する必要があるためです。
これに対し、Sigmaの集計ナビゲーションは簡単です。そして、集計ナビゲーションを活用するテーブルは、マテリアライズの有力な候補と成り得ます。
-
集計関数または演算子は、データのグループに適用され、統合された値を計算する
- 一般的な集計関数には、合計、個数、平均、最小値、最大値、中央値などがある
- これらの関数は、売上高や気温などの数値データだけでなく、異なるカテゴリの出現回数を数えるなどのカテゴリデータにも適用できる
-
集計は、レポートの作成、傾向の分析、データセットからの有意義な統計情報の導出などによく使用される
- 例えば、売上データベースでは、集計を使用することで、製品カテゴリごとの総売上高を計算したり、顧客あたりの平均売上高を求めたり、最も売上の高い地域を特定したりすることができる
-
集計は、データセット全体、特定のグループやカテゴリ、さらには複数のディメンションにまたがるなど、さまざまなレベルで実行
- 集計方法の選択は、具体的な分析目標とデータの構造によって異なる
このエントリでは、4つの結合テーブルで構成され、6,000万行のテーブルを構築する方法を実践していきます。
一般的なルール:
- 複数のレベルを持つマテリアライゼーションでは、選択したレベルとその上位の各レベルに対してテーブルが作成されます。
- 4つのグループとベースレベルがある場合、「すべての列」を集計すると、合計5つの新しいテーブルが作成されます。
- すべてのビジュアライゼーションには、少なくとも1つのグループレベルがあります。
- ユーザーが単一の集計グループレベルをマテリアライズしたい場合は、子テーブルを作成してマテリアライズすることができます。
- すべてのグループレベルをマテリアライズすることで、下流の要素で適切に参照できる集計テーブルを非常に簡単に構築できます。
例:
テーブル要素に5つのグループ化レベルがあり、3番目のレベルでマテリアライズすると、最上位レベル、2番目のレベル、3番目のレベルそれぞれに、3つの個別のマテリアライズが作成されます。4番目、5番目、そして基本のグループ化レベルはマテリアライズされません。
これは重要な点です。なぜなら、ここではパフォーマンスと、あまり使用されないグループ化レベルのストレージコストの間でトレードオフが生じるからです。
レベル4と5にマテリアライズできない数億件のレコードがある場合、Sigmaはレベル1から3までをマテリアライズできます。処理速度は遅くなりますが、優れたパフォーマンスと必要に応じて詳細な情報を得ることができます。
既存のワークブックを基にしてデータを拡張してデモンストレーションを行います。
サンプルユースケースの準備
Sigmaコンテンツを閲覧しているユーザーは、Region/Nation/Customerレベルで集計された売上データと、各グループごとの売上合計と注文数の内訳を常に確認したいと考えています。明細項目の詳細を確認することはほとんどないものの、時折確認できるオプションは必要です。
まず、既存のマテリアライズスケジュールを一時停止して、実行されないようにします。
先程作成したワークブックを開き。テーブルメニューのView scheduleオプションを選択。

スケジュールのメニューからPause(一時停止)を選択。
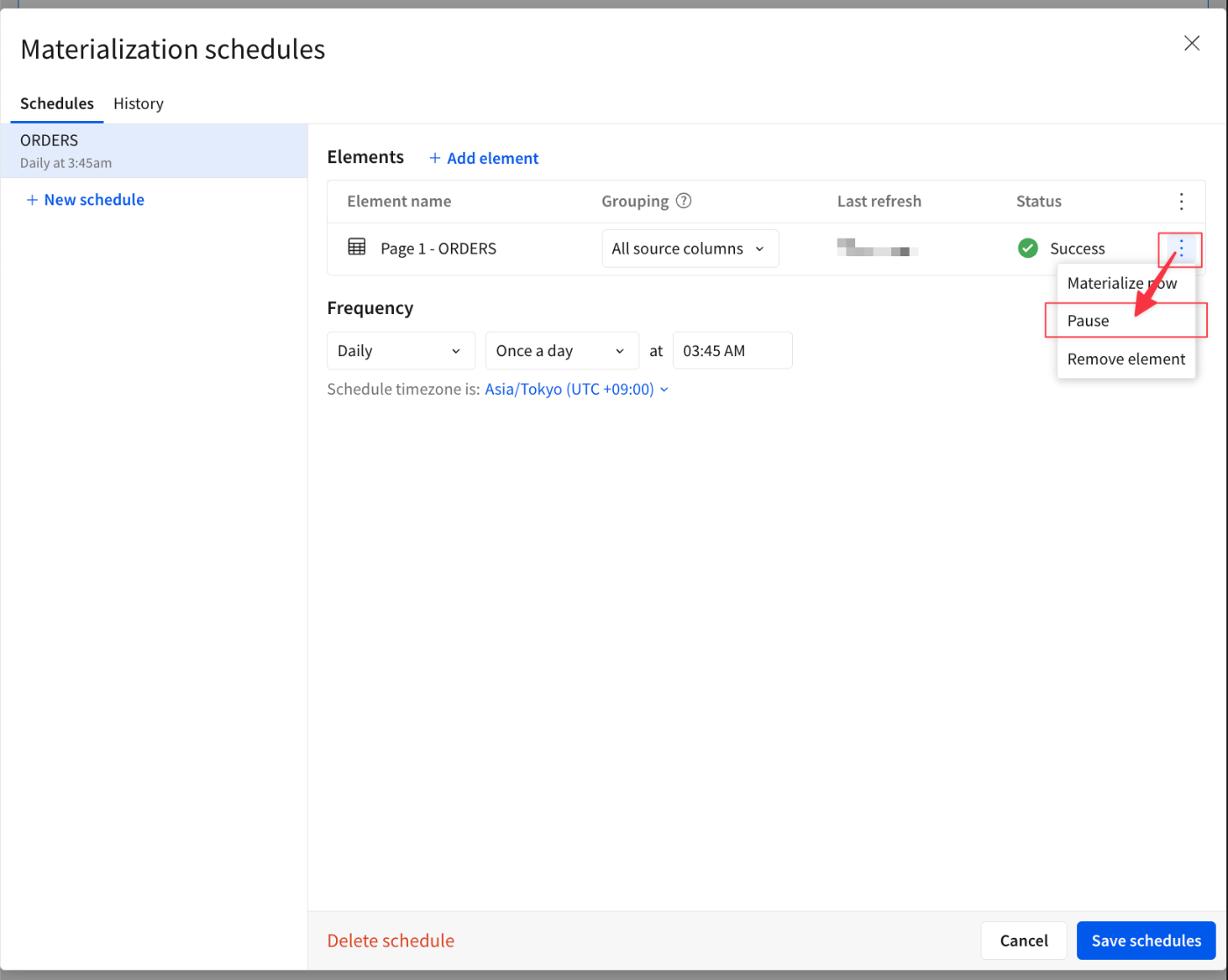
ステータスが変更されました。[Save schedules]を押下し、設定を保存します。

続けて、Ordersテーブルを複製します。
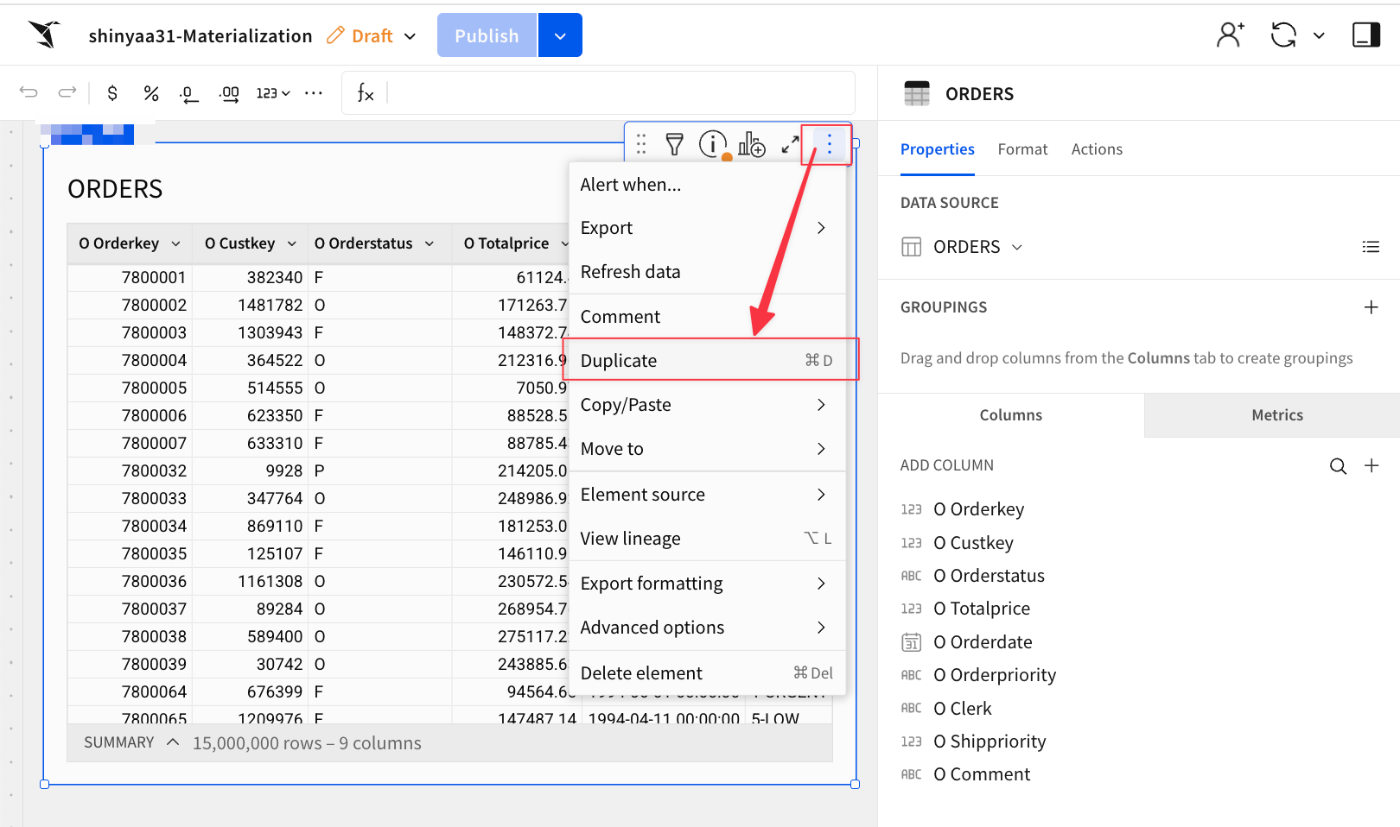
複製した情報の名前をORDERS by Customerに変更。そしてこのコンテンツを新しいページに移動させます。

結合:Customerテーブル+Ordersテーブル
移動したコンテンツ、CustomerをOrdersと結合させます。メニューから[Element source]→[Join]を選択。

SNOWFLAKE_SAMPLE_DATA配下にあるTPCG_SF10/CUSTOMERを選択し、[Select]を押下。

Join typeにLeft Outer join、Join keysにO Custkey = C Custkeyの結合キーを設定。注文をまったくしない顧客もいれば、複数の注文をする顧客もいることが見て取れます。[Preview Output]を押下。

データがどのようにマッピングされているかを視覚的に表現したリネージ(Lineage)が表示されました。
内容を確認し、[Done]を押下。
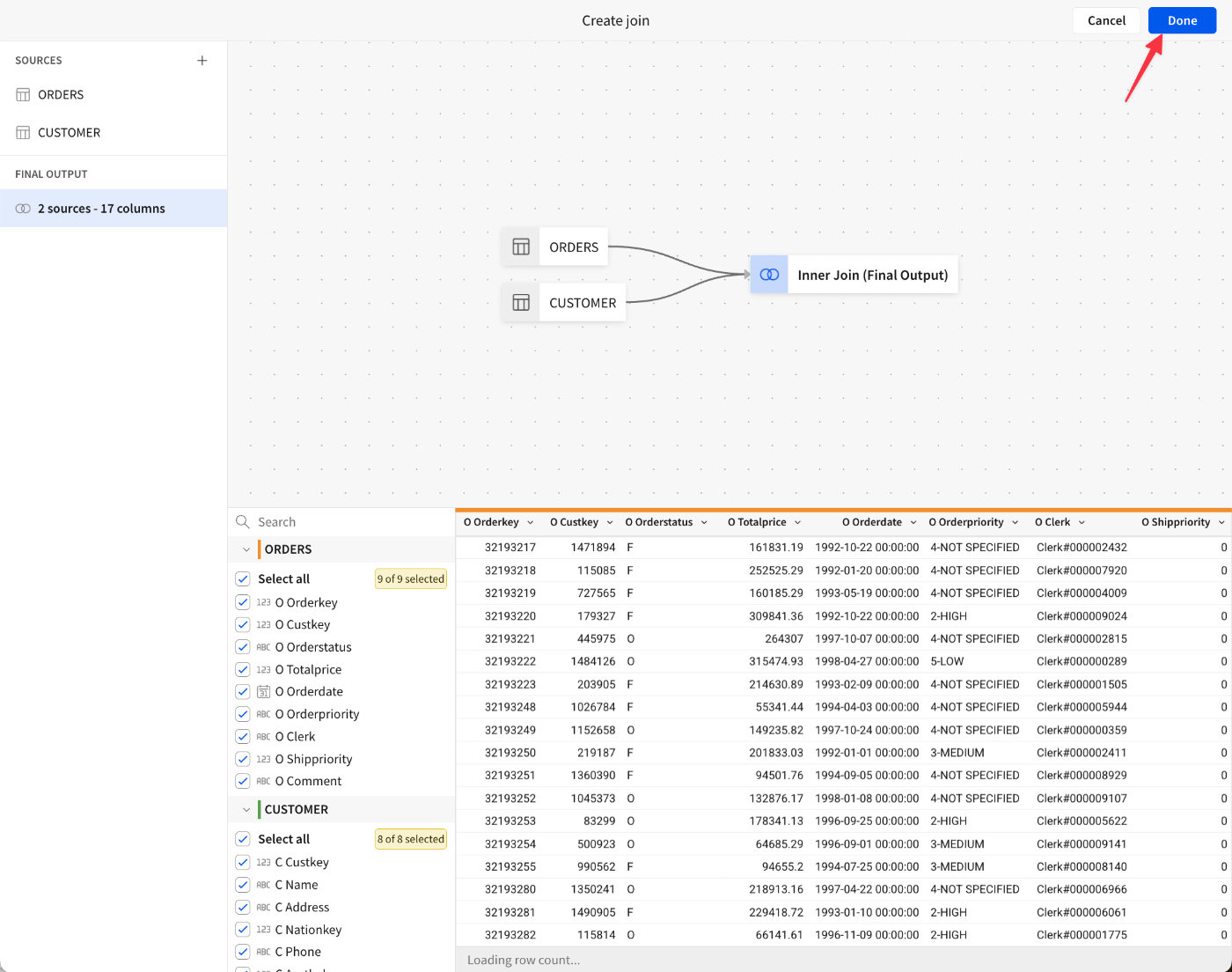
今回の内容ではすべての列を使用しますが、パフォーマンスとコンピューティング/ストレージコストの向上のために不要な列を削除するのがベストプラクティスです。また、ユーザーインターフェースも少しすっきりします。
結合:+Nationテーブル
同じような手順でテーブルを結合させていきます。先程のJoinに対する編集を行い、

結合を追加を実施。
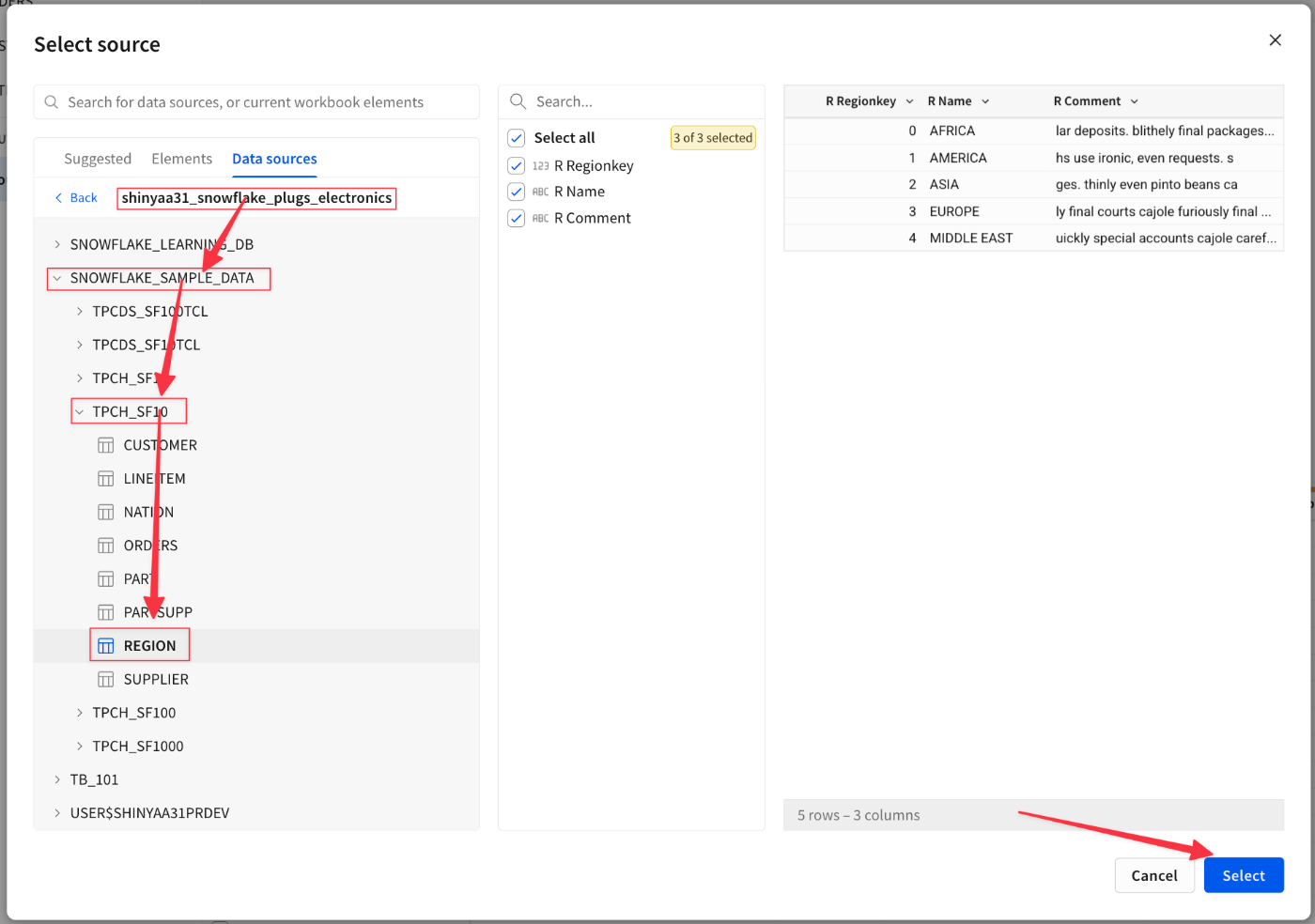
Nationテーブルを指定し、

CustomerテーブルとNationkeyで結合。

結合:+Regionテーブル
Regionテーブルを指定し、
NationテーブルとRegionkeyで結合。

結合:+Lineitemテーブル
Lineitemテーブルを指定し、
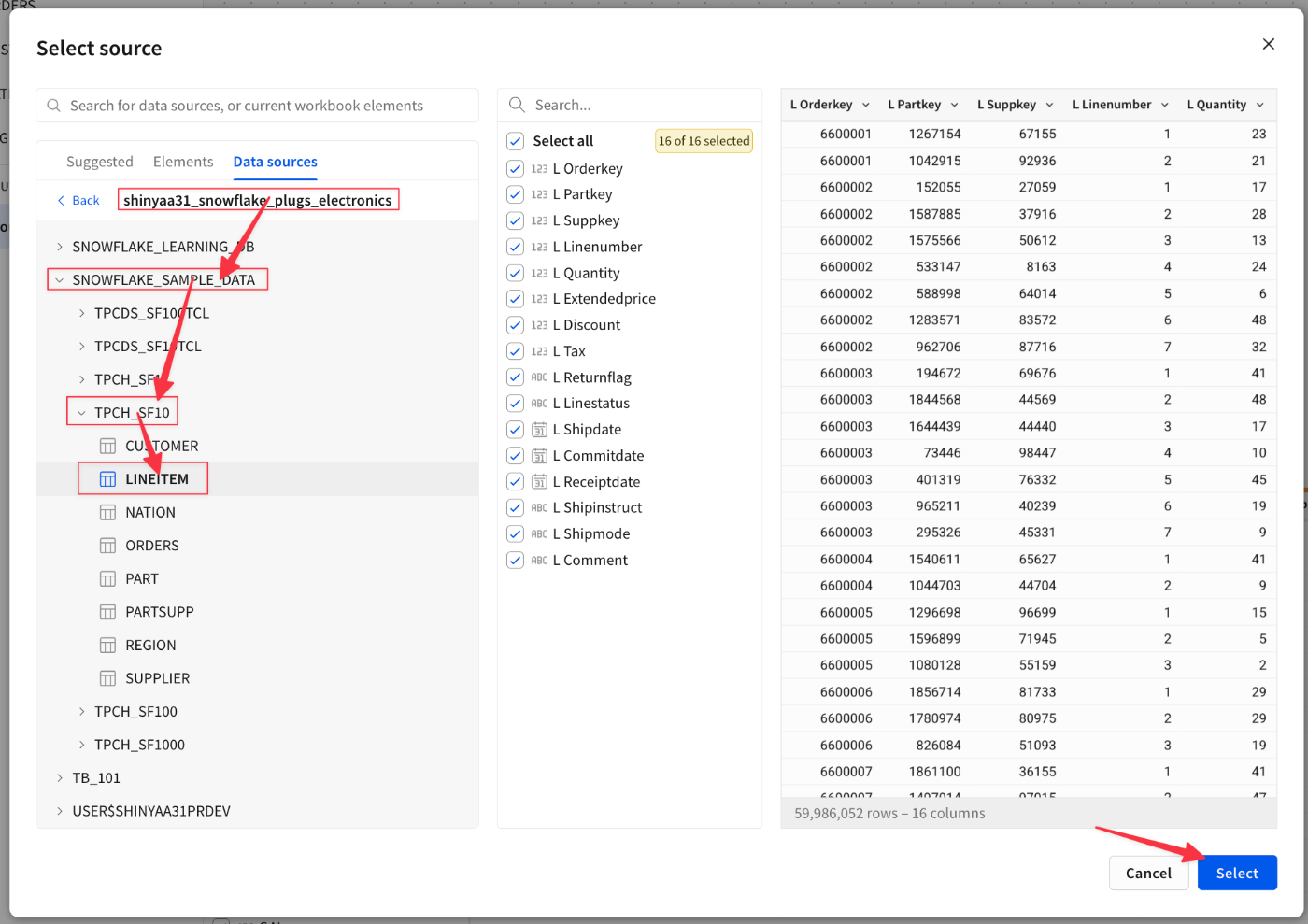
OrdersテーブルとOrderkeyで結合。

ここまで追加してきた内容をリネージで確認してみます。Region レベルで具体化し、LineItem レベルを「ベース」または具体化したくないあまり使用されないデータと見なすことができます。

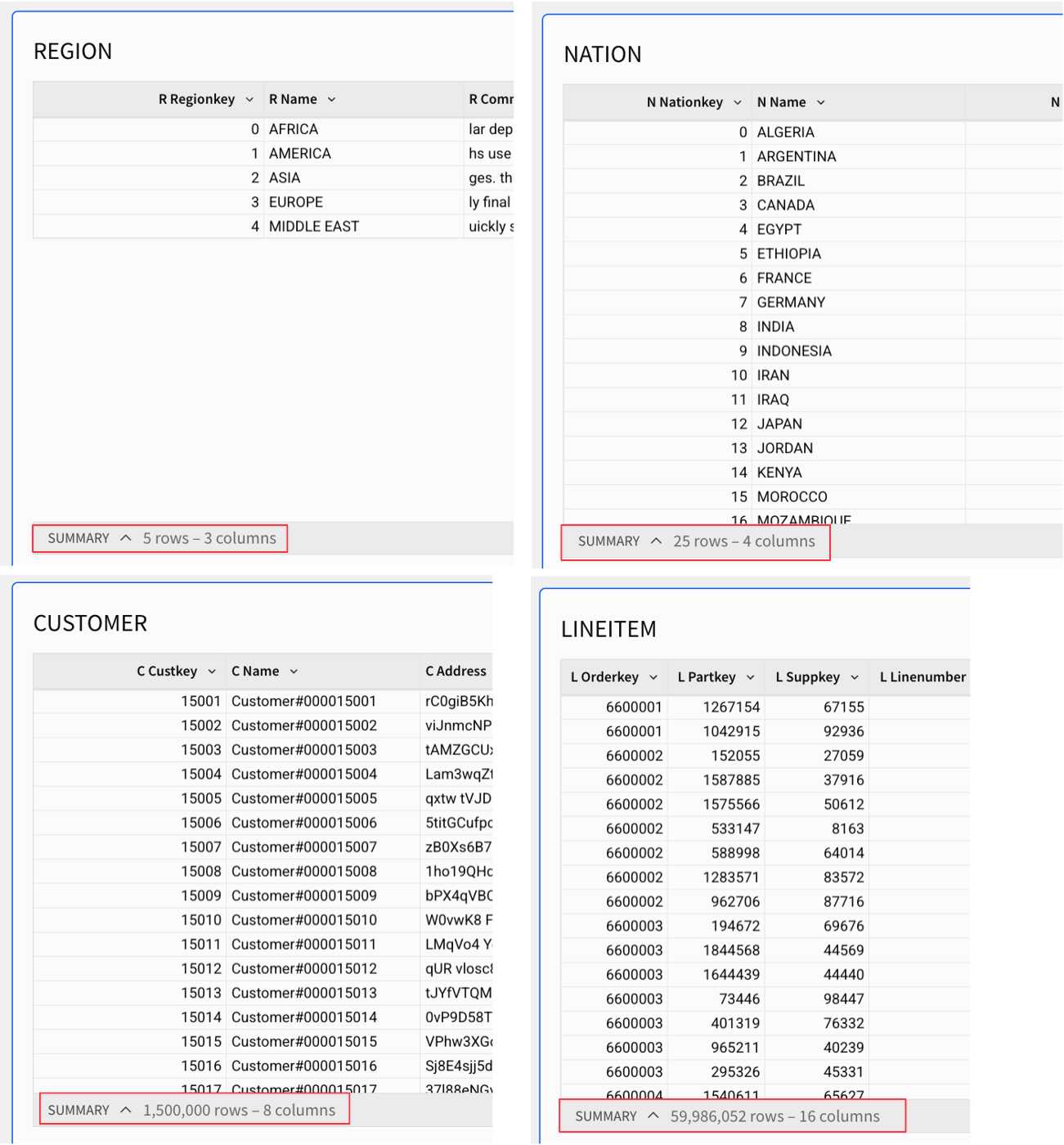
現在、顧客別の注文明細は約6,000万行あります。
各テーブルの行数を確認するために、テーブル情報を見てみます。行数が増えるにつれて、「詳細」または「ベース」レベルが最下位レベルとなり、サイズと使用頻度に応じてグループ化またはマテリアライズされないのが一般的です。
グルーピング設定
上記内容は一旦除去し、既存結合を行ったテーブルに対して「グルーピング」設定を施していきます。操作はテーブル設定の[GROUPINGS]欄で行います。
以下に示すように、都合3つのグルーピング設定(赤枠内単位)を作成します。
GROUP BYの項目は既存項目を指定、
CALCULATIONSの項目は計算式を記入した項目を新規作成(ADD COLUMN)していきます。
項目指定内容:
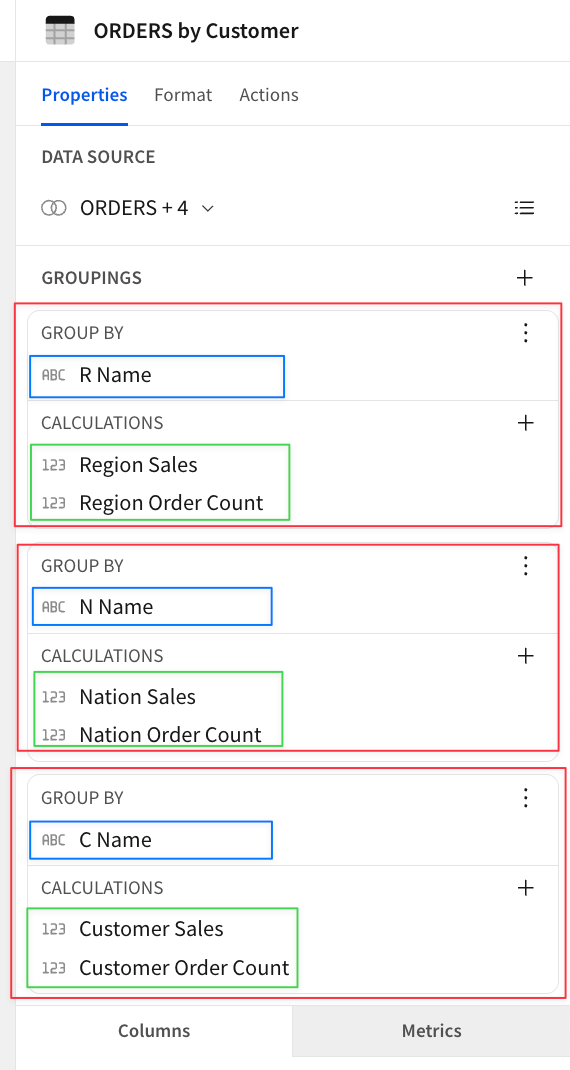
計算式内容:
CALCULATION: FORMULA: (note: they are all the same, using the groupings)
Region Sales Sum([O Totalprice])
Region Order Count CountDistinct([O Orderkey])
Nation Sales Sum([O Totalprice])
Nation Order Count CountDistinct([O Orderkey])
Customer Sales Sum([O Totalprice])
Customer Order Count CountDistinct([O Orderkey])
設定が完了すると、指定の項目っでグルーピング処理が為され、項目単位でドリルダウン展開が出来るようになります。これは便利ですね!
Regionでのグルーピング:

Regionをドリルダウン(Region配下のNationを展開):

Nationをドリルダウン(Nation配下のCustomerを展開):
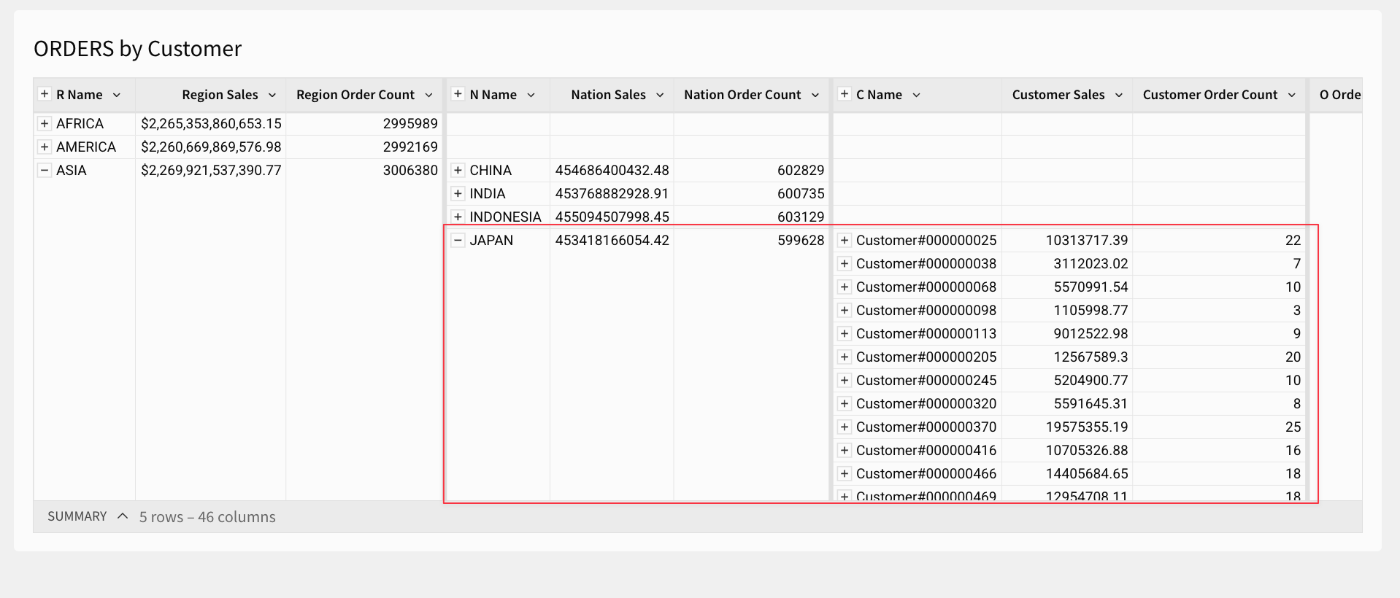
Customerをドリルダウン(Customerの件数内容を展開し詳細情報を表示):
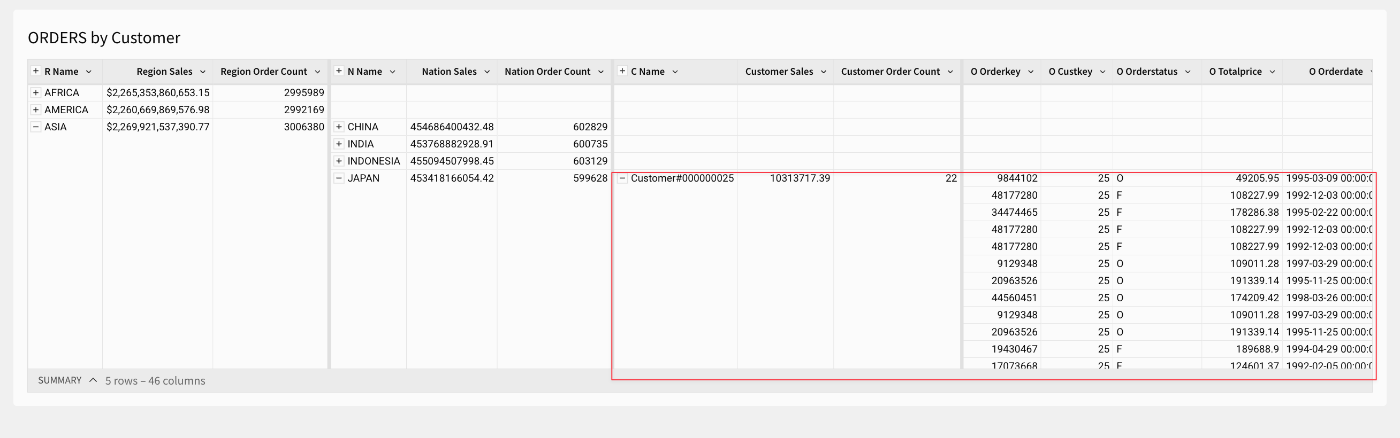
マテリアライズスケジュールの作成
必要なテーブルが完成したので、再度マテリアライズを実行できます。今回は、テーブルのグループ化レベルを選択できるようになりました。
Schedule materializationを選択。
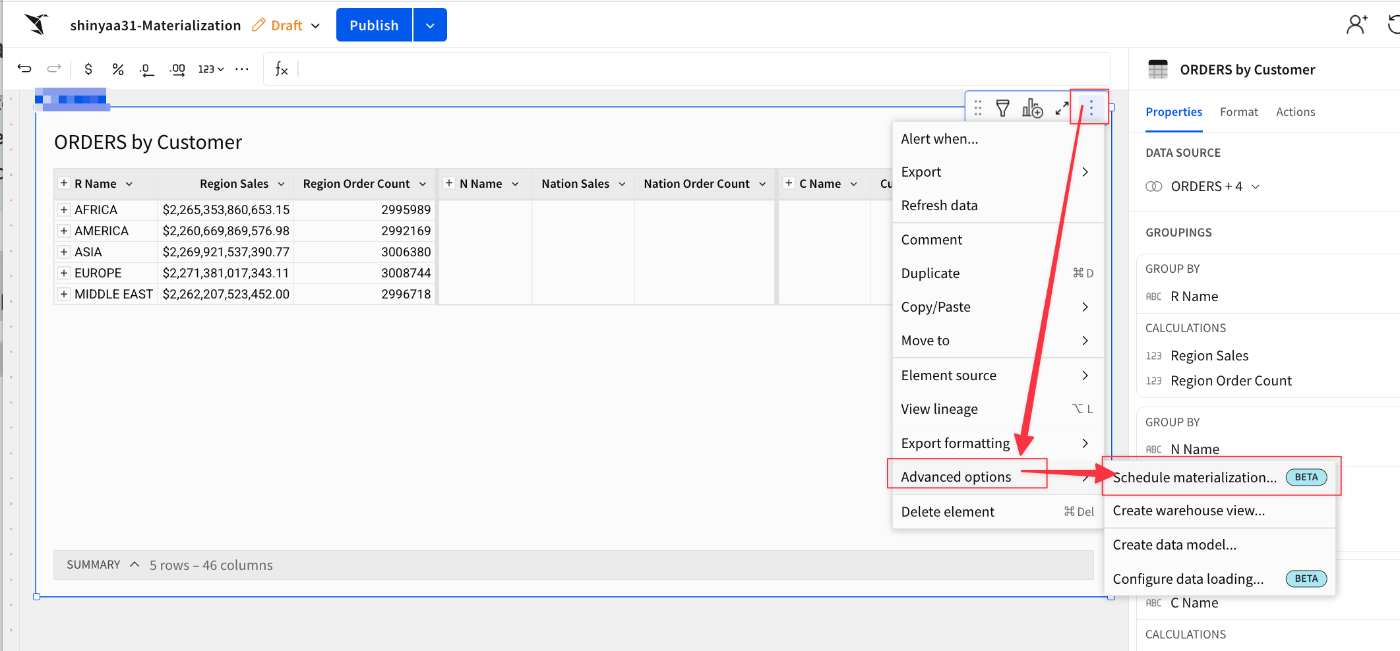
マテリアライズのレベルをグルーピング単位で指定が可能となっています。ここではCustomer(C Name)レベルを指定。

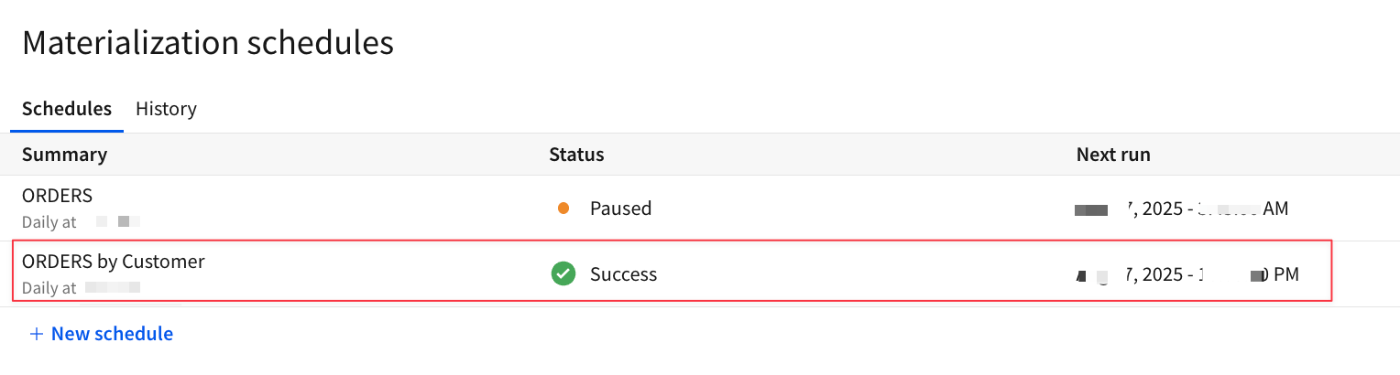
スケジュールが作成され、所定の時間を迎えて処理が実行、無事完了しました。
マテリアライゼーションが完了すると、Snowflakeに3つの新しいテーブルが作成されていることがわかります。これらのテーブルはSigmaによって管理されており、通常の操作では確認する必要はありませんが、ここでは結果を示し、いくつか重要な点について触れておきます。
Sigma WriteDBを確認すると、3つのテーブルが作成されていることがわかります(テーブル名の最後の文字が「_0.、_1、_3」になっていることに注目してください)。最後のテーブル(最上位のグループレベル)には、Sigmaの最初のグループに対応する3つの列があります。
列名は「フレンドリ名」ではありません。これは仕様です。
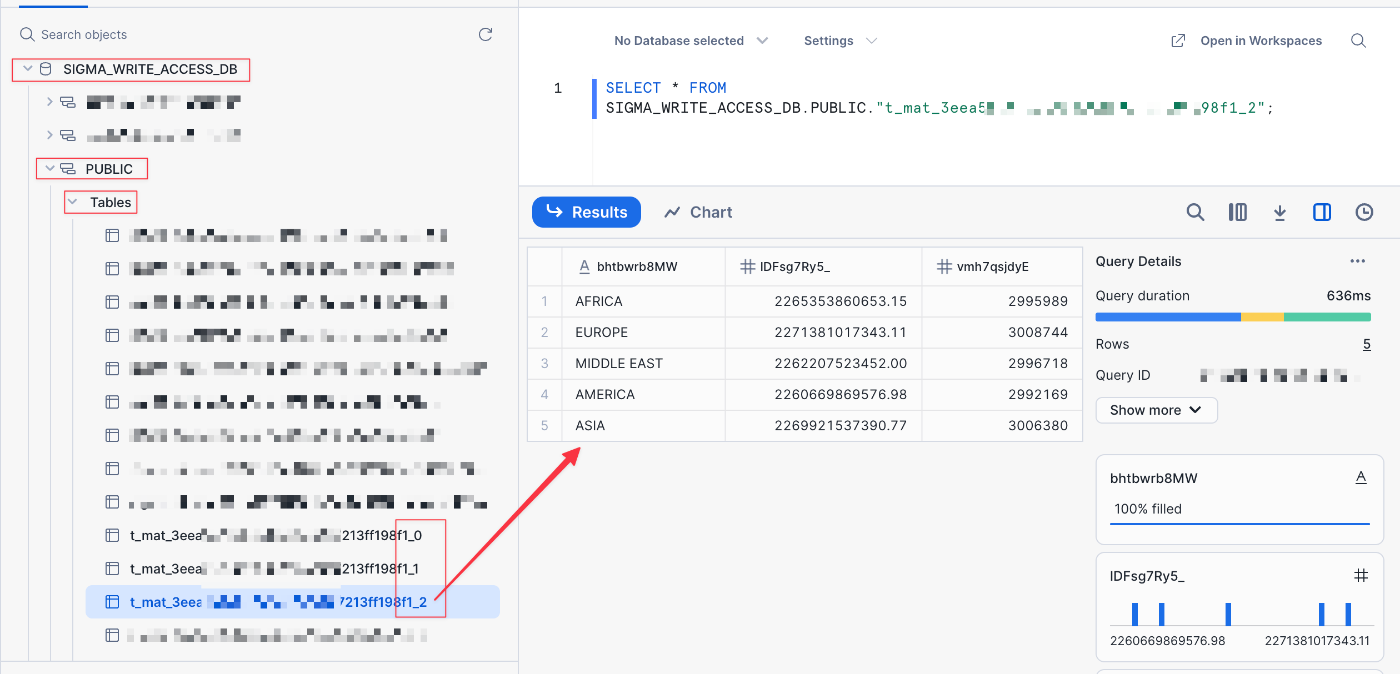
Sigma のデータセット・ウェアハウス・ビュー機能を使用すれば、他のアプリケーションからこのデータにアクセスできます。詳細は下記ドキュメントをご参照ください。
マテリアライズドテーブルへのアクセスが完了すると、Snowflake のキャッシュルールに基づいてウェアハウスキャッシュに保存されるため、パフォーマンスも向上します。Sigmaのクエリ履歴を確認すると、Sigma がウェアハウスキャッシュから自動的にデータを読み込んでいることがわかります。


SnowflakeとSigmaの連携については下記ドキュメント『Sigma On Snowflake Best Practices』も参考になります。興味のある方は是非目を通してみてください。
まとめ
という訳で、Sigma(SigmaComputing)におけるマテリアライゼーション(Materialization)のチュートリアル『Materialization with Sigma』の実践内容紹介でした。その他のサービス同様にSigmaでもこの機能は非常に重宝されるものとなりますが、実際の設定自体はそこまで手間の掛かるものでも無く、非常にわかりやすく、且つきめ細やかな設定が行えるので是非使わない手はない機能だなと思いました!
先日公開されていたエントリ『Sigma vs Tableau:Snowflakeに10億規模のデータ接続で見えたユーザ体験の違い』でも言及されていたようにSigmaは大規模データに対する取り扱いも非常にスムーズな反応を提供しています。そこに本エントリで紹介したマテリアライゼーションの機能を組み合わせることでより良いデータ体験をユーザーに提供することが期待出来るのではないでしょうか。
