URLからテキストを抽出する自作APIアプリケーションの構築|youtube, PDF
1. はじめに
Webページや動画からテキスト情報を抽出することは、情報収集やデータ分析など、様々なタスクにおいて重要です。この記事では、DockerとFastAPIを用いて、URLからテキストを抽出するアプリケーションを構築する方法について解説します。Dockerは、アプリケーションの実行環境をコンテナ化することで、環境依存の問題を解消し、デプロイを容易にする技術です。FastAPIは、Python製のWebフレームワークであり、高速で効率的なAPI開発を可能にします。
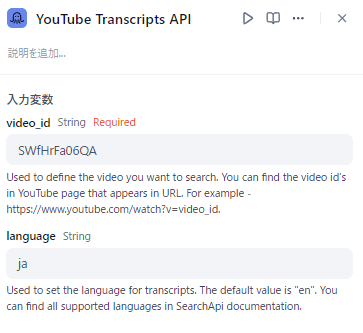
この記事を活用するとできること
- youtubeから字幕(transcript)を取得して、Difyで要約させる
- WebサイトのURLから、テキストを出力して、Difyのワークフローに流し込む
- Web上のPDFからテキストを抽出して、DifyでQAチャットボットを構築する
2. 環境構築
2.1 Dockerfile
以下のDockerfileを用いて、アプリケーションの実行環境を構築します。
FROM python:3.10.9
WORKDIR /app
RUN mkdir /app/downloads
RUN useradd -m appuser
COPY . /app
RUN apt-get update && apt-get install -y \
libgl1-mesa-glx \
libglib2.0-0 \
poppler-utils \
tesseract-ocr
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt
RUN chown -R appuser:appuser /app
USER appuser
ENV NLTK_DATA /app/nltk_data
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "7860"]
-
FROM python:3.10.9: Python 3.10.9をベースイメージとして使用します。 -
WORKDIR /app: コンテナ内の作業ディレクトリを/appに設定します。 -
RUN mkdir /app/downloads: ダウンロードしたPDFファイルを保存するためのディレクトリを作成します。 -
RUN useradd -m appuser: アプリケーションを実行するための非rootユーザーappuserを作成します。 -
COPY . /app: カレントディレクトリのすべてのファイルをコンテナ内の/appディレクトリにコピーします。 -
RUN apt-get update && apt-get install -y ...: システム依存関係をインストールします。 -
RUN pip install --no-cache-dir --upgrade -r /app/requirements.txt:requirements.txtに記載されているPython依存関係をインストールします。 -
RUN chown -R appuser:appuser /app:/appディレクトリの所有権をappuserに変更します。 -
USER appuser: アプリケーションの実行ユーザーをappuserに設定します。 -
ENV NLTK_DATA /app/nltk_data: NLTKデータのパスを環境変数に設定します。 -
CMD ["uvicorn", "app:app", "--host", "0.0.0.0", "--port", "7860"]: コンテナ起動時にuvicornサーバーを起動します。
2.2 システム依存関係のインストール
このアプリケーションでは、PDFファイルの処理やOCRの実行のために、以下のシステム依存関係をインストールする必要があります。
-
libgl1-mesa-glx: OpenGLのライブラリ -
libglib2.0-0: GLibライブラリ -
poppler-utils: PDF処理ユーティリティ -
tesseract-ocr: OCRエンジン
2.3 Python依存関係のインストール
requirements.txtファイルには、以下のPython依存関係が記載されています。
fastapi
langchain
youtube-transcript-api
uvicorn
python-multipart
pytube
unstructured[pdf]
requests
pydantic==1.10.12
langchain_community
-
fastapi: FastAPIフレームワーク -
langchain: LangChainフレームワーク -
youtube-transcript-api: YouTube動画のトランスクリプトを取得するためのライブラリ -
uvicorn: ASGIサーバー -
python-multipart: ファイルアップロードを処理するためのライブラリ -
pytube: YouTube動画をダウンロードするためのライブラリ -
unstructured[pdf]: 非構造化データの処理ライブラリ -
requests: HTTPリクエストライブラリ -
pydantic==1.10.12: データバリデーションライブラリ -
langchain_community: LangChainのコミュニティライブラリ
3. FastAPIアプリケーションの実装
import os
import requests
from fastapi import FastAPI, HTTPException, Depends
from fastapi.security import OAuth2PasswordBearer
from langchain_community.document_loaders import YoutubeLoader, UnstructuredPDFLoader, WebBaseLoader
from langchain_community.document_loaders import OnlinePDFLoader
app = FastAPI()
API_KEY = os.environ["API_KEY"]
oauth2_scheme = OAuth2PasswordBearer(tokenUrl="token")
async def validate_token(token: str = Depends(oauth2_scheme)):
if token != API_KEY:
raise HTTPException(status_code=401, detail="Invalid API Key")
@app.post("/extract_text", tags=["Text Extraction"], dependencies=[Depends(validate_token)])
def extract_text(url: str, language: str = "ja", length: int = 150000):
try:
if "youtube.com" in url or "youtu.be" in url:
# YouTubeの場合
loader = YoutubeLoader.from_youtube_url(
youtube_url=url,
add_video_info=True,
language=[language],
)
docs = loader.load()
text_content = str(docs)
elif url.endswith(".pdf"):
# PDFの場合
loader = OnlinePDFLoader(url)
docs = loader.load()
text_content = docs[0].page_content
else:
# それ以外の場合
loader = WebBaseLoader(url)
docs = loader.load()
text_content = docs[0].page_content
if len(text_content) < length:
return {"text_content": text_content}
else:
return {
"text_content": text_content[: int(length / 2)]
+ text_content[len(text_content) - int(length / 2) :]
}
except Exception as e:
error_msg = str(e)
return {"message": error_msg}
-
API_KEY: 環境変数からAPIキーを取得します。 -
oauth2_scheme: OAuth2PasswordBearerを用いて、APIキーによる認証を設定します。 -
validate_token: APIキーを検証する関数です。 -
extract_text: URLからテキストを抽出するAPIエンドポイントです。-
url: テキストを抽出するURL -
language: テキストの言語(デフォルトは日本語) -
length: テキストの長さ制限(デフォルトは150,000文字)
-
3.1 APIキーによる認証
validate_token関数は、Dependsデコレータを用いてextract_textエンドポイントに依存関係として注入されます。これにより、APIリクエスト時にAPIキーの検証が自動的に実行されます。
3.2 URL入力によるテキスト抽出機能
extract_textエンドポイントは、入力されたURLの種類に応じて適切なローダーを選択し、テキストを抽出します。
3.3 URLの種類に応じたローダーの選択
- YouTube動画の場合:
YoutubeLoaderを用いてテキストを抽出します。 - PDFファイルの場合:
OnlinePDFLoaderを用いてテキストを抽出します。 - その他のWebサイトの場合:
WebBaseLoaderを用いてテキストを抽出します。
4. テキストの長さ制限
lengthパラメータで指定された文字数を超えるテキストは、前半と後半を連結して出力されます。
5. エラー処理
try-except構文を用いて、エラー発生時の処理を実装しています。エラーメッセージは、messageキーで返されます。
APIとして使用する
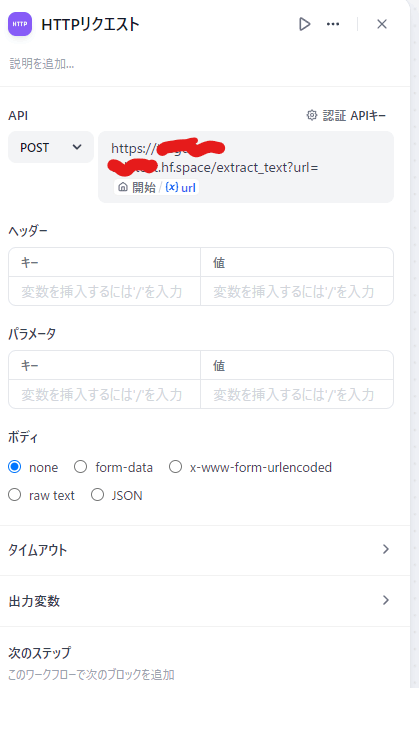
Difyから叩く
6. まとめ
この記事では、DockerとFastAPIを用いて、URLからテキストを抽出するアプリケーションを構築する方法について解説しました。Dockerによる環境構築、FastAPIによるAPI実装、URLの種類に応じたローダーの選択、テキストの長さ制限、エラー処理など、重要な要素を網羅的に解説しました。このアプリケーションは、Webページや動画からテキスト情報を抽出する必要がある様々なタスクにおいて活用することができます。
Discussion