[代替]YouTubeのtranscriptを取得する方法|Colab, youtube-transcript-api
自分の好きなAIモデル、プロンプトでYouTube要約したい|Colab, youtube-transcript-api,dify
近年の情報爆発により、YouTubeなどの動画コンテンツが急増しています。Youtube要約のサービスがあるがどれもプロンプトいじることができなかったりAIモデルを指定することができなかったりします。そこで本稿では、AIモデルとGoogle Colabを活用したYouTube動画のtranscript取得について解説します。
なぜYouTube動画の書き起こしを取得するのか?
YouTube動画の視聴には時間がかかります。transcript(書きおこし)があれば、好きなAIモデルに投げることができます。動画全体を視聴せずとも主要な内容を効率よく把握でき、大幅な時間節約につながります。また、英語の字幕を要約することで、言語の壁を越えた情報アクセスが可能になります。
youtubeのtranscriptを取得する方法と課題
YoutubeLoder
以前は、youtube-transcript-api や langchain の YoutubeLoader を用いてYouTube動画の字幕データを取得し、Hugging Face Spaceなどで公開されている要約モデルに渡すことで要約を生成できました。しかし、現在Hugging Face上から利用できていないです(利用できる方法知ってる人がいたら教えてください)
!pip install youtube-transcript-api
!pip install langchain_community
from langchain_community.document_loaders import YoutubeLoader
loader = YoutubeLoader.from_youtube_url(
"https://youtu.be/B2zCWJBnfuE?si=NTHcCF3YUUtE-wjd", language = "ja",add_video_info=False
)
loader.load()
youtube公式API
YouTubeの公式APIでは直接トランスクリプトを取得する機能は提供されていません。
https://www.genspark.ai/spark/youtubeのapiでトランスクリプトを取得する方法/e455f53b-6cdf-4170-be1e-6d6887b4c3c1
searchapi
有償ですが、APIからyoutubeのtranscriptを取得する方法もあります。(無料枠あり)
Google Colabの選定理由
Google Colabは、無料でpythonを利用できるため、ちょっとしたプログラミングに最適な環境です。Python環境がプリインストールされており、必要なライブラリも簡単にインストールできます。さらに、ノートブック形式でコードや実行結果を共有しやすい点、マルチプラットフォームである点もメリットです。
今回は特殊な例としてColabをアプリのように使用して行きたいと思います。
具体的な実装方法
- Google Colabにアクセスし、新規ノートブックを作成します。
- 必要なライブラリをインストールしながら、
youtube-transcript-apiを用いて動画の字幕データを取得します。
# @title Click `Show code` in the code cell. { display-mode: "form" }
!pip install youtube-transcript-api
from youtube_transcript_api import (
YouTubeTranscriptApi,
NoTranscriptFound,
TranscriptsDisabled,
VideoUnavailable
)
from typing import List, Dict, Optional
import re
from IPython.display import HTML
class YoutubeTranscript:
@staticmethod
def get_video_id(url: str) -> str:
"""URLからVideo IDを抽出"""
# Use regular expression for more robust ID extraction
match = re.search(r"(?<=v=)[^&#]+|(?<=be/)[^&#]+", url)
return match.group(0) if match else None
@staticmethod
def get_transcript(url: str, language: str = 'ja') -> Optional[List[Dict]]:
"""
YouTubeの書き起こしを取得
Args:
url: YouTube動画のURL
language: 字幕の言語 (ja, en, en-US)
Returns:
字幕データのリスト。取得失敗時はNone
Raises:
NoTranscriptFound: 指定された言語の字幕が見つからない場合
"""
try:
video_id = YoutubeTranscript.get_video_id(url)
if video_id is None:
print(f"無効なURLです: {url}")
return None
transcript = YouTubeTranscriptApi.get_transcript(
video_id,
languages=[language] # 指定された言語を使用
)
return transcript
except TranscriptsDisabled:
print(f"この動画では字幕が無効になっています: {url}")
return None
except VideoUnavailable:
print(f"動画が利用できません: {url}")
return None
except Exception as e:
# Check if the exception is related to language not found
if "does not have any transcripts" in str(e) or \
"Could not retrieve a transcript for the video" in str(e):
raise NoTranscriptFound(f"指定した言語 ({language}) の字幕が見つかりません: {url}") from e
else:
print(f"予期せぬエラーが発生しました: {str(e)}")
return None
# The function 'get_transcript_for_gradio' should be outside the class
def get_transcript_for_gradio(url: str, language: str) -> str:
"""Gradio UI 用の書き起こし取得関数"""
try:
transcript = YoutubeTranscript.get_transcript(url, language)
if transcript:
# formatted_transcript = "\n".join(
# [f"[{entry['start']:.1f}s] {entry['text']}" for entry in transcript]
# )
formatted_transcript = "".join(
[f"{entry['text']}" for entry in transcript]
)
return formatted_transcript,str(len(formatted_transcript))
else:
return "字幕の取得に失敗しました。","字幕の取得に失敗しました。"
except NoTranscriptFound as e:
return str(e),str(len(e)) # Return the error message from the exception
if __name__ == "__main__":
url = "https://youtu.be/B2zCWJBnfuE?si=NTHcCF3YUUtE-wjd" # @param {type:"string", placeholder:"enter a YouTube URL"}
lang = "en" # @param ["ja","en","en-US"]{type:"string", placeholder:"enter a language"}
result,length = get_transcript_for_gradio(url,lang)
print(result[:64])
print("len:"+length)
# your_text = "コピーしたいテキスト"
html_text = f'''
<button onclick="copyText()">テキストをコピー</button>
<div id="message" style="display:none; color:green; margin-top:10px;">コピーしました!</div>
<a href="your_ai_summarizer_url" target="_blank"><button>Difyを開く</button></a>
<script>
function copyText() {{
const text = `{result}`;
navigator.clipboard.writeText(text).then(function() {{
const messageDiv = document.getElementById("message");
messageDiv.style.display = "block";
setTimeout(function() {{
messageDiv.style.display = "none";
}}, 2000);
}}).catch(function(err) {{
console.error("テキストのコピーに失敗しました:", err);
alert("テキストのコピーに失敗しました。");
}});
}}
</script>
'''
display(HTML(html_text))
pass
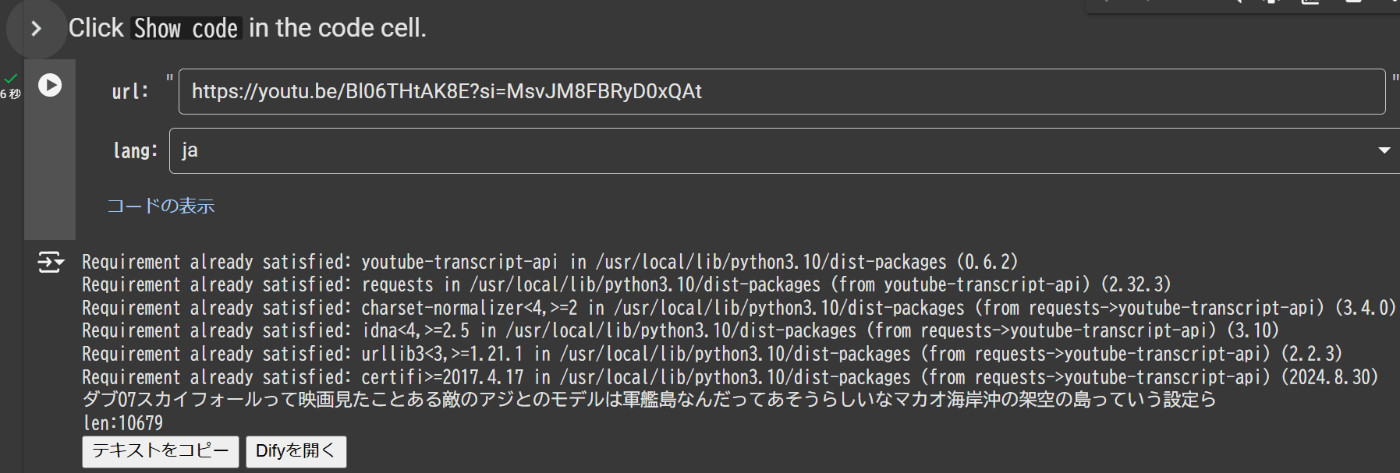
- コードを隠すことでアプリっぽさがでます。
# @title Click `Show code` in the code cell. { display-mode: "form" }
- フォーム機能でアプリっぽく使えます。
url = "https://youtu.be/B2zCWJBnfuE?si=NTHcCF3YUUtE-wjd" # @param {type:"string", placeholder:"enter a YouTube URL"}
lang = "en" # @param ["ja","en","en-US"]{type:"string", placeholder:"enter a language"}
- 出力されたテキストがtranscriptです。
htmlを活用することで、transcriptをクリップボードにコピーできます。コピーボタンですね。
また、要約アプリには、自作のDifyアプリを開くようにしています。やっぱり、特定のAIに投げれるのがいいですね!
課題と展望
huggingface上でYoutubeLoaderが復活してほしいですね。。。閉じると、再開時にライブラリをインストールしなおさないといけないのが欠点ですね。
使い勝手は思っていたよりいい感じです。
おわりに
colabをあたかもアプリのように使うことができることがよかったです。
各規約を確認して自己責任でお願いします。
Discussion