RSSフィードを活用した丸ごと全部情報収集|dify,jinaReader
Gemini,NotebookLMの登場により、従来は部分的に利用されることが多かったWebコンテンツを、丸ごと取得して活用したいというニーズが高まっています。
Web上には膨大な情報が日々更新されています。その中で、最新の情報を効率的に収集することは、ビジネスや研究活動において非常に重要です。RSSフィードは、ウェブサイトの更新情報を配信するための仕組みであり、このフィードを利用することで、効率的な情報収集が可能となります。
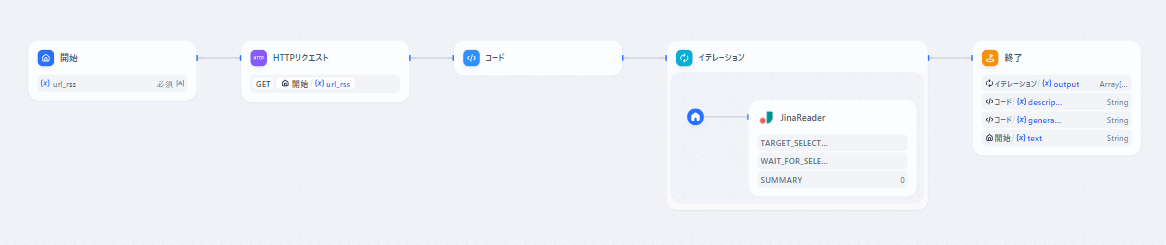
この記事では、Pythonを用いてRSSフィードから特定の情報を抽出し、リンク先のコンテンツを取得(クローリング)する方法について解説します。さらに、取得したコンテンツをjinaReaderを用いて収集する方法についても紹介します。
1. RSSフィードとは
RSSフィードとは、ウェブサイトの更新情報をXML形式で配信する仕組みです。ブログやニュースサイトなどで広く利用されており、ユーザーはRSSリーダーと呼ばれるアプリケーションを使用することで、複数のウェブサイトの更新情報を一元的に確認することができます。
RSSフィードを利用するメリットは以下の点が挙げられます。
- 効率的な情報収集: 興味のあるウェブサイトの更新情報を自動的に取得できるため、効率的に情報を収集できます。
- リアルタイムな情報取得: ウェブサイトの更新と同時に情報が配信されるため、常に最新の情報を入手できます。
- 情報過多の抑制: 興味のある情報だけを取得できるため、情報過多を防ぐことができます。
2. RSSフィードからのデータ抽出
Pythonを使用すると、RSSフィードを簡単に解析し、必要な情報を抽出できます。
2.3 特定の情報 (リンク、概要) の抽出
<link> タグや <description> タグなど、特定のタグ内の情報を簡単に抽出できます。
このコードでは、各記事のリンクと概要を抽出し、表示しています。
3. リンク先コンテンツの取得 (クローリング)
RSSフィードから抽出したリンクを元に、リンク先のコンテンツを取得 (クローリング) することができます。クローリングには、jinaReader ライブラリを使用します。
3.1 クローリングの注意点
クローリングを行う際には、以下の点に注意する必要があります。
- 著作権: ウェブサイトのコンテンツには著作権があります。クローリングを行う前に、対象のウェブサイトの利用規約を確認し、著作権に配慮する必要があります。
- アクセス負荷: 短時間に大量のリクエストを送信すると、対象のウェブサイトに負荷をかける可能性があります。クローリングを行う際は、アクセス頻度を適切に制御する必要があります。
4. jinaReaderを用いたコンテンツの分析
jinaReaderは、自然言語処理を用いて、テキストコンテンツを分析するためのツールです。RSSフィードから取得した記事コンテンツをjinaReaderに渡すことで、キーワード抽出や類似文書検索など、高度な分析を行うことができます。
4.1 jinaReaderの概要
jinaReaderは、高性能なドキュメントリーダーです。テキストコンテンツから重要な情報を抽出し、検索や分析に適した形式に変換することができます。
活用例
- 指定した著者のnote記事抽出
- 指定した著者のzenn記事抽出
- 指定したYoutubeチャンネルの投稿動画を一括取得: Iterationの生身を工夫する
5. まとめ
この記事では、RSSフィードを用いた効率的な情報収集の方法と、取得したコンテンツをjinaReaderを用いて分析する方法について解説しました。
RSSフィードとjinaReaderを組み合わせることで、Web上の膨大な情報から必要な情報を効率的に収集し、分析することができます。
Discussion