Cortex Analystでセマンティックモデルを作成する
Cortex Analystの概要
Cortex AnalystはSnowflakeで生成AIが使えるサービスSnowflake Cortexの中の機能の一つで、構造化データに対してユーザーが自然言語で質問すると、内部でSQLクエリが実行され、データについての回答が返ってくるようなアプリケーションを構築できます。Cortex Analystのコアとなる機能は、LLMを用いて自然言語の入力からSQLのクエリを出力するText to SQLの部分で、この部分がREST APIとして提供されています。
Cortex Analystには以下のような特徴があります。
(2024年9月現在)
- フルマネージドなのでSnowflakeエンジンのコスパで実現できる
- データはSnowflakeのガバナンス境界内に留まる
- Azure OpenAIを使う場合はメタデータとプロンプトのみSnowflake外部に出る
- 利用できるモデル
- Mistral Large, Llama3
- Azure OpenAI:GPT-4o (オプションから追加可能)
- 利用可能なリージョン:東京もある!
- AWS ap-northeast-1 (東京)
- AWS us-east-1 (バージニア)
- AWS us-west-2 (オレゴン)
- AWS eu-central-1 (フランクフルト)
- Azure 東部 US 2 (バージニア)
- Azure 西ヨーロッパ (オランダ)
- コスト
- 2024年11月15日まで無料
- 価格と課金の詳細は近日中に公開
Cortex Analystを使ったアプリの実装は以下のステップで行えます。
- セマンティックモデルを作成する
- セマンティックモデルをステージにアップロードする
- スタンドアロンのStreamlitアプリを作成して実行する
- Streamlitアプリを操作する
以下のチュートリアルから実装を試すことができます。
今回はこの中でセマンティックモデル作成の部分に焦点を当てていきます。セマンティックモデルの作り込みがText to SQLの精度に影響するので、かなり大事なパート&結構泥臭いパートだと思います。あと、おそらくLLMのパラメーターをいじったり特定のモデルだけ使うように設定したりはできないので、このセマンティックモデル作成の部分が主な試行錯誤ポイントになります。(英弱なのでドキュメントの読み解きが間違っていたら教えてください…)
セマンティックモデル作成
セマンティックモデルはデータのメタデータに該当する情報で、yaml形式で記載します。データの概要や各カラムの情報、サンプルクエリなどを記載することができます。
準備
あらかじめ、セマンティックモデルを置くためのデータベース、スキーマを作成し、テーブルにデータを格納します。
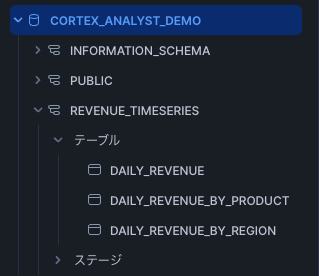
Cortex Analystのチュートリアルの場合
公式が提供しているセマンティックモデルジェネレーターを使って、ある程度自動的にyamlファイルを作成しました。
↓が公式のリポジトリです。
このリポジトリを使うとセマンティックモデルの作成補助アプリをStreamlitで起動できるのですが、このままだとローカル環境にライブラリをインストールすることになってしまうので、Dockerコンテナを作成し、コンテナ内部でアプリを起動できるように編集しました。
フォークしてDocker周りを追記したリポジトリを作ったので、参考にしてもらえればと思います。
コンテナ作成後、READMEに書いてある通りにMakefileの内容を実行してStreamlitアプリを起動すると、以下のような画面が現れます。

次のような機能があります。
- Create a new semantic model:新たにyamlファイルを作成
- Edit an existing semantic model:Snowflakeのステージ上にあるyamlファイルを編集
- Start with partner semantic model:dbt, lookerと連携してセマンティックモデルを作成
アプリ起動後にSnowflake側を更新しても反映されないので注意が必要です。(アプリを再起動する必要がある)
セマンティックモデルジェネレーターを使う
今回はCreate a new semantic modelを選択し、新たにセマンティックモデルを作っていきます。
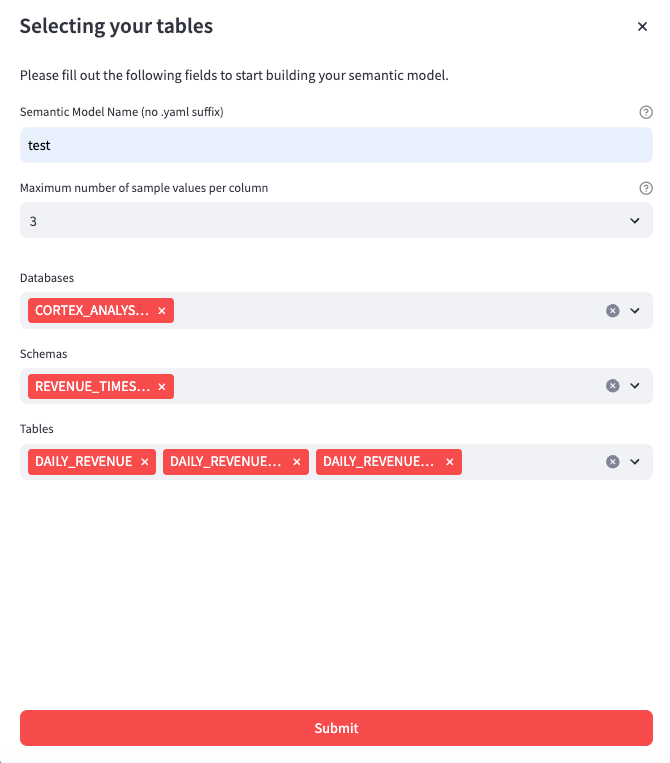
各項目を埋めていきます。
- Semantic Model Name: yamlファイルの名前
- Maximum number of sample values per column: 深い意味はないがとりあえず3にした
- Databases: 複数選択もできる
- Schemas: 〃
- Tables: 〃
Submitを押すと自動でモデルを記述してくれます。
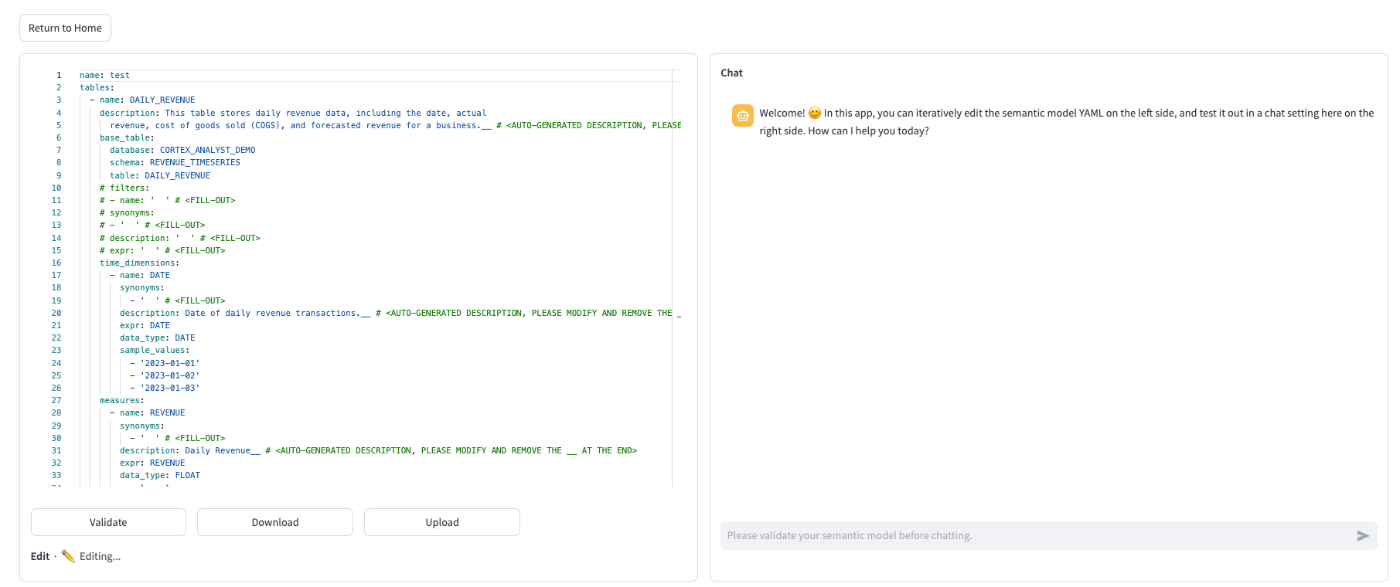
チュートリアルのデータを使った例。左側にyamlファイル、右側にチャットボットが出てくる
チャットボットで実際にText to SQLを試し、Cortex Analystの性能を確認しながらyamlファイルを編集できます。編集したファイルはValidateを押すと右のアプリにも反映されます。
この時点で以下の情報はすでに記載されています(すごい!)
- データ名、データ全体の説明
- データベース、スキーマ、テーブル
- 各カラムの情報:dimensions、times_dimensions、measuresに分かれる
- dimensions:参照や分類に使われるデータの属性・カテゴリー
- times_dimensions:時系列のディメンション
- measures:考察対象となる数値
- カラムの詳細
- name:公式ドキュメントにdescriptive nameと書いてあるので、カラムを一言で表す意味的な名前を指すと思われる。列名そのままじゃなくても良い
- expr:SQL表現。列名と同じ名前を記載する
- description:そのカラムの説明
- data_type:データ型
- sample_values:カラムに入っているサンプル値が複数記載されている
以下の情報は編集したほうが良さそうでした。
- name、description:基本的にデータから読み取れることしか書いてないので、適宜修正していく
- synonyms:参照するために使用される他の用語/フレーズのリスト。全部空白になっている。このセマンティックモデル内のすべての同義語で一意である必要があり、自然言語で問い合わせされそうなフレーズをうまくsynonymsに入れ込んであげるのが大事そう
また、ドキュメントにも記載があるのですが不要な列情報は削除した方がいいみたいです。問い合わせに使われないような列(ID列や何らかのコード列など)は適宜削除する方が良さそうですね。
また、チャットでの試行結果を用いてVerifid queryを追加できます。Verified queryは質問とSQLクエリのセットで、あらかじめ質問と対応するクエリを記述できます。これによってただ問い合わせただけでは生成できなさそうな複雑なクエリや、雑な質問に対するクエリなどを補強できます。

Editを押すとクエリの参照するテーブルやSQLクエリを編集できる

Save as verified queryを押すとクエリが保存され、yamlファイルに追加される
編集をした後、Downloadを押すとローカルにファイルが保存され、Uploadを押すとステージにアップロードできます。

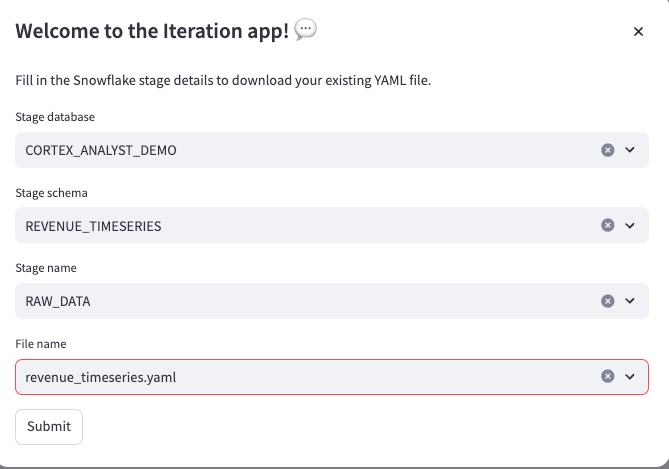
ステージにあるセマンティックモデルを編集したい時は、最初のメニューからEdit an existing semantic modelを押すと編集できます。
おわりに
Cortex Analystは最近Snowflakeから出たばかりで、個人的に割と簡単にText to SQLが作成できるサービスとして注目していました。
メタデータの知識もほとんどない状態でしたが、セマンティックモデルジェネレーターをうまく使うことで結構簡単にセマンティックモデルを作ることができたので良かったです。特にチャットをして結果を確認しながらyamlファイルを編集できるのは体験としてとてもスムーズでした。ファイルのアップロードダウンロード機能も便利ですし、ジェネレーターツール便利ですね。逆にこれがないとセマンティックモデル作成はかなりめんどいなと思いました。
Discussion