LookML開発でドメイン別にフォルダを分けてみた
はじめに
弊社でLookerを導入してはや2年が経ち、初期設計で書き進めてきたLookML開発がだんだん辛くなってきたので、一度全てぶっ壊そう大作戦を実施しました。
今回は実際に行ったことや、その際に気をつけたことをまとめていきたいと思います。
背景
Looker導入時は当然のようにLookMLなんて書いたことないし、そもそもどう実装すればどう使えるようになるかが手探り状態でした。初期設計自体は前任が担当し、自分は2人目のDeveloperとして見よう見まねで開発を進めてきました。
しかし、前任が退職し、新たにDeveloperになったメンバーを加えて新体制で取り組んでいく中で、いくつかの課題が見えてきました。
課題1:modelファイルの中身がめちゃくちゃ長くなる問題
弊社は今現在、単一プロダクトを提供しているため、modelファイルは1つだけで運用してきました。当時はそれで十分でしたし、マルチプロダクト化した際にmodelファイルを増やしていくのが良いと考えていました。しかし、単一プロダクトと言えど取得できるデータの種類は多分にあり、それらを全て実装していくと段々とmodelファイルの行数がえげつない量に成長してました。最終的には1000行近くのファイルが出来上がり、もはやどこに何を書いていたかを探すのが大変な状況になっていました。この課題が大きくて、本記事のテーマでもあるドメイン別にフォルダを分け、それに合わせてmodelファイルも分ける決断をしました。
課題2:使われていないexploreが放置されてる問題
これは問題というよりわかってるなら消せよって話ですが、開発人数が限られている中、新規で依頼がくる案件を実装していくとどうしても管理が疎かになっており、使われているのかどうかすら追えていない状態でした。また、目的によってはこっちのExploreを使った方が簡単に出せるけど知らないが故に使われないものも存在していたため、その辺の浸透もまだまだできていませんでした。Lookerには各Exploreの利用状況を見ることができるので、使われていないかつ明らかに今後も使わないであろうExploreは積極的に消すようにしました。
課題3:型や命名規則が統一されていない問題
この課題も最初からきちんと整備して取り組めば問題なかった話なのですが、当初はとにかく運用に乗せることに集中していたためそこまで手が回っていませんでした。しかし、Exploreが増えていくに連れて、型が異なっていたり命名規則がバラバラだとそのままダイレクトにLookerを使う人たちに影響が出てしまいます。そこで今回の取り組みに乗じてここらへんも全て整備することにしました。
フォルダ構造
本題に入ります。今回採用したフォルダ構造は以下になります。
├── documents
│ ├── domain_1.md
│ ├── domain_2.md
│ ├── ...
├── explores
│ ├── master_1.explore.lkml
│ ├── master_2.explore.lkml
│ ├── ...
├── models
│ ├── domain_1.model.lkml
│ ├── domain_2.model.lkml
│ ├── ...
└── views
├── domain_1
│ ├── view_1.view.lkml
│ ├── view_2.view.lkml
│ ├── ...
├── domain_2
│ ├── ...
└── ...
それぞれのフォルダについて説明していきます。
documents
├── documents
│ ├── domain_1.md
│ ├── domain_2.md
│ ├── ...
ドメインごとの説明や、各Exploreの使い方など、descriptionでは書ききれない情報をmdファイルとしてここに保管します。ファイルはGitHub Flavored Markdownを使用して書くことができます。これまでは社内ドキュメント(ex. Notion)で管理してたところを、全てLooker内で管理できるようにしました。
explores
├── explores
│ ├── master_1.explore.lkml
│ ├── master_2.explore.lkml
│ ├── ...
いくつかのViewを結合させた汎用的なExploreをここで定義します。これまではmodelファイル内で定義してましたが、複数のmodelファイルに跨いで使いたいケースが出てきたので汎用的なものはここで管理するようにしました。
models
├── models
│ ├── domain_1.model.lkml
│ ├── domain_2.model.lkml
│ ├── ...
ドメイン別のmodelファイルをここに保管します。1ファイルあたり100~300行程度になったのでだいぶ見やすくなりました。また、これまでは1つのファイル内でバラバラにExploreを定義していたため、新しく定義する際にどこに書けばいいのかわからず結局一番下に追加することが多かったのですが、ドメイン別にしてアルファベット順に統一したことで迷わず定義することができるようになりました。
views
└── views
├── domain_1
│ ├── view_1.view.lkml
│ ├── view_2.view.lkml
│ ├── ...
├── domain_2
│ ├── ...
└── ...
ここではさらにドメイン別のフォルダを作成し、viewファイルを分けて保管します。viewファイルが一番数が多くなるファイルだったので、階層を増やすことで管理しやすくしました。また、弊社のデータ基盤ではDimensional Modelingを採用してるため、データ基盤を直接参照して作成したviewファイルの接頭辞にdim_とfct_を、Looker側でDerived Tablesを用いて作成したviewファイルの接頭辞にlk_を付けることで、メンテナンス時の影響範囲をわかりやすくしました。
デプロイ前の大仕事
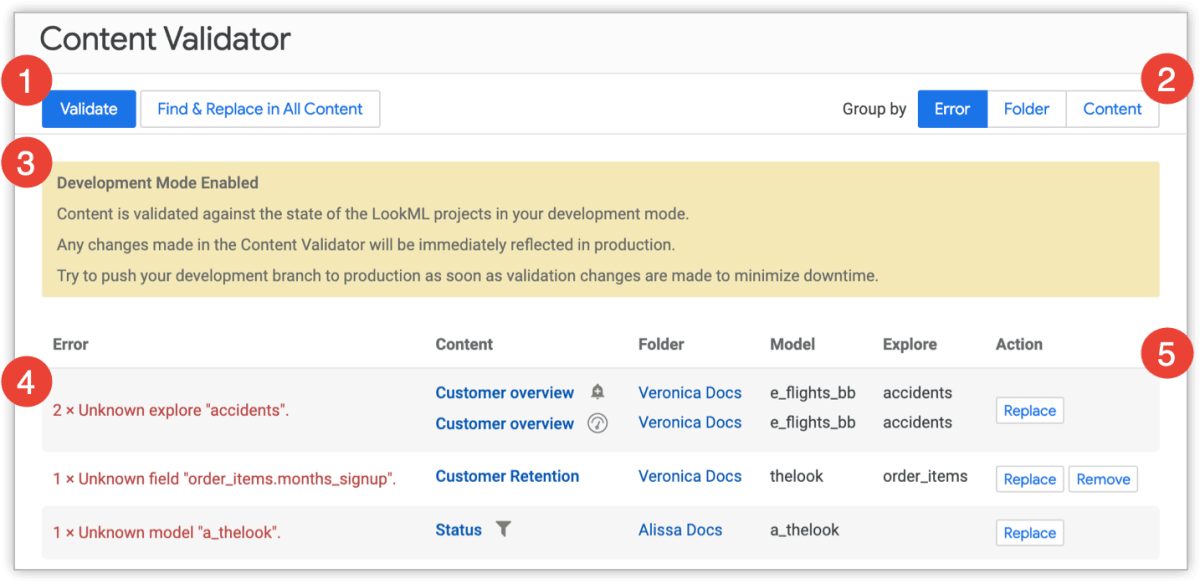
参照元:https://cloud.google.com/looker/docs/content-validation
今回の変更はModel自体を変更するため、作成したダッシュボードやLookの影響範囲でいうと全てになります。当然ですが、デプロイをした途端に全てのデータが見れなくなるため、Content Validatorの結果を確認したのち、適切な対応をする必要があります。事前にデプロイ作業が入る旨を関係者へアナウンスし、2人体制で修復作業にあたりました。修復自体は参照先のModelを一括変更するだけなのでそこまで大変ではなかったですが、何かあった時の対応を事前に確認しながら作業することを意識しました。
また、不要になったExploreを個人フォルダ内で使ってた人もいたため、今も使用してるのか、使っているなら目的は何かなどを聞いた上で代替案や削除依頼をしました。個人フォルダは自由な分、使われなくなったダッシュボードやLookが不要に溜まってしまうため、定期的な削除依頼を運用に乗せるのが大事だと感じました。
今後の展望
弊社ではExploreを自由に触れるStandard Userが10名ほどいます。しかし、まだ全員がLookerを自由自在に使えてるわけではありません。各人が各チーム内の意思決定のためにデータを適切に使ってもらうためにも、今後はStandard User向けにLooker研修を実施していきたいと思います。また、自分を含めDeveloperが気持ちよく開発できる環境を今後も整えつつ、残りの課題にも取り組んでいければと思います。
おわりに
今回の取り組みを通じて、改めてLookerの使いやすさを感じることができました。全てをぶっ壊しても業務に支障が出ることがほぼなく終えられたのもそうですし、エンジニア目線で直感的に構造を考えられるのもストレスフリーだなと感じてます。今後もLookerを運用してみた中で発見したことや、工夫したことを記録していければと思います。
最後まで読んでいただきありがとうございまいた。
Discussion