inkfs 🦑 devlog 1 (→ wgpu 入門、スプライトバッチ、簡易シェーダ)
Learn Wgpu があまりに良かったので 2D フレームワークを作り直してしまう devlog です。
以下常態です
inkfs = inkfish 🦑
wgpu は raw-window-handle 0.4 を使っているが、 sdl2 35.1 は 0.3 を使っている。 35.2 が出るまではパッチが必要:
35.2 が出たので不要になった 。
# we need this patch until 0.35.2 is bumped
[patch.crates-io]
sdl2 = { git = "https://github.com/Rust-SDL2/rust-sdl2", features = ["raw-window-handle"] }
-
.create_surfaceでエラーが出るため wgpu#1500 を真似る (ちょっと古い)
ECS を使うつもり。ゲームループはこんな感じかな:
pub fn run(world: &mut World, mut f: impl FnMut(&mut World) -> SystemResult) -> SystemResult {
loop {
world.run(self::wait_frame)?;
world.run(self::update_event_queue)?;
if world.res::<AppExit>().is_true() {
break Ok(());
}
world.run(self::tick_context)?;
f(world)?;
world.run(self::end_frame)?;
}
}
思うに toecs (Toy ECS) はプラグインベースにする必要が無い。 One-shot な関数呼び出し (World::run) だけあれば良さそう。
気が早いけれど現状の main:
fn main() -> Result<()> {
App::default()
.run_with_app(it::setup)
.run_with_world(self::init)
.run_with_world(self::game_loop);
Ok(())
}
App も one-shot な関数呼び出しをするのみで、スケジューラは無い。 Event の購読やフレームの終わりは resource 経由でスケジュールしてもいいかもしれない。
wgpu や metal は右手座標系らしく、正射影 (orthographic projection) で写される前の座標系はこんな感じかな:
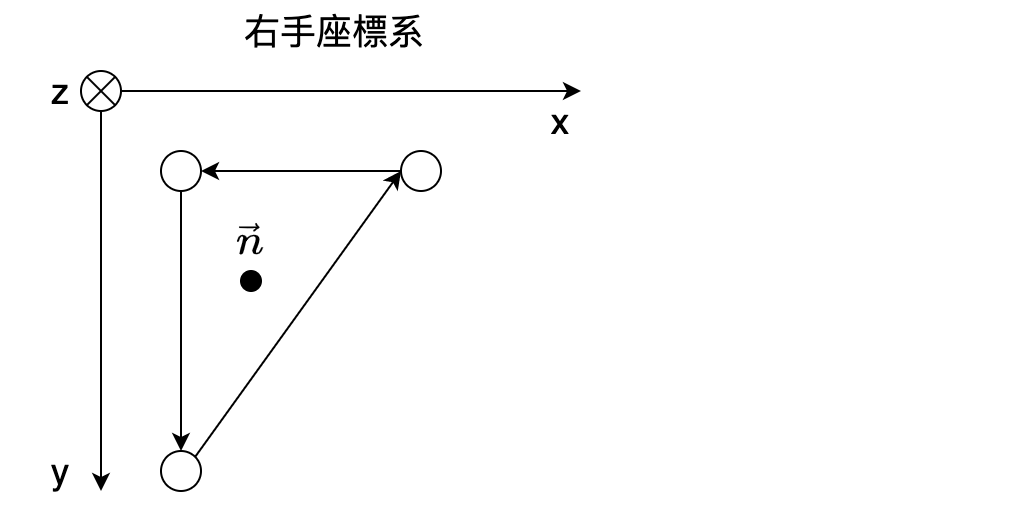
カメラから見て反時計回り (counter clockwise) な巻き? (winding) の頂点で構成される三角形 = 物体表面の三角形 = 『正面向き』 (正面が、法線がカメラ向き)
実際:
使用したバッファ:
fn verts() -> [TexVertex; 4] {
const W: [f32; 4] = [1.0, 1.0, 1.0, 1.0];
[
// (pos, uv, color)
([200.0, 000.0], [0.0, 0.0], W), // left up
([600.0, 000.0], [1.0, 0.0], W), // right up
([200.0, 600.0], [0.0, 1.0], W), // left bottom
([600.0, 600.0], [1.0, 1.0], W), // right bottom
]
.map(TexVertex::from)
}
const INDICES: &[u16] = &[0, 2, 1];
射影行列 (vek の対応関数):
let mat: vek::Mat4<f32> = vek::Mat4::orthographic_rh_zo(vek::FrustumPlanes {
left: 0.0,
right: 1280.0f32,
// 幾何的な上下、ウィンドウの上下 (値の小さい方が bottom だと思うと呪われる)
top: 0.0f32,
bottom: 720.0f32,
near: 0.0f32,
far: 1.0f32,
});
幸いテクスチャの UV もこの向きなので修正は必要無かった。
imgui-wgpu-rs でデモウィンドウ表示:

egui が人気なのは承知だけれど、いずれ imgui-rs にも来る docking を使いたいので、今回も ImGUI で。簡単 GUI アプリを inkfs で作っちゃったりしてね。
igri で
#[derive(Inspect)]ができる予定
sokol ユーザ目線の wgpu 入門 Batcher 作ります編への道
Sokol って実は wgpu よりも簡単じゃん……?
1. submit って何だ
wgpu では、パス終了後、 CommandEncoder をどのように submit すべきか。単発で submit するかまとめるか。
→ まとめて 1 フレームに 1 回だけ submit すべき:
- https://github.com/gfx-rs/wgpu/wiki/Do's-and-Dont's
- https://github.com/gfx-rs/wgpu/wiki/Encapsulating-Graphics-Work
2. CommandEncoder と RenderBundleEncoder はどう違う?
どちらを使うべき?
3. リソースについて
3-1. Texture 変更時の binding 更新法は?
imgui_wgpu は毎回 BindGroup を設定しているので、 texture 毎に BindGroup を作っておくしかなさそう。
→ GPU リソースを Arc に入れる。
3-2. Texture を比較するには?
自動バッチ処理の都合で TextureId が欲しい。 Texture 生成時に ID をつけるべき。
→ GPU リソース生成時に ID を与える (Uuid または AtomicU64)
4. Buffer の使い方
4-1. Buffer 作成
-
今回 index buffer は 1 度作ったら更新しない:
Device::create_buffer_init -
Vertex buffer は動的に更新する:
Device::create_buffer
4-2. Buffer 更新
Uniform buffers and a 3d camera | Learn Wgpu によると3 通りの方法でバッファを更新できる
-
Staging buffer からコピーする
分からない。 https://vulkan-tutorial.com/Vertex_buffers/Staging_buffer を読む? -
"map"
例: Wgpu without a window | Learn Wgpu では画像ファイルの出力に使っていた。また Do's and Dont's · gfx-rs/wgpu Wiki によると Don't: create temporary mapped buffers when updating data. とあるのでこれは違う。 -
Queue::write_buffer
実は遅い?
ひとまず 3. で行けるが 1. が気になる
没案: Interleaved な Queue / Render
伝統的な batcer は、バッファの更新と描画を交互に繰り返す。試してみると wgpu::RenderPass<'a> のライフタイム制限がキツく、 CPU 側の頂点データと GPU 側のバッファで借用の分割が必要になった:
pub fn render(&mut screen: &mut Screen) {
let (gpu, pass) = screen.split();
{
let mut rpass = pass.rpass();
let view_mat = math::Mat4::<f32>::identity();
self.shader.set_view_mat(view_mat, &gpu.queue);
self.shader.apply(&mut rpass);
// CPU 側の頂点データと GPU のバッファに分割
let (verts, bufs) = self.mesh.split();
verts.extend(self::draw());
bufs.upload_verts_slice(&gpu.queue, 0, &verts[0..4]);
bufs.draw(&mut rpass, 0, 0..6);
verts.extend(self::draw());
bufs.upload_verts_slice(&gpu.queue, 4, &verts[4..8]);
bufs.draw(&mut rpass, 4, 0..6);
}
}
wgpu な典型的な使い方を知るため、 Bevy Engine を読んでみよう。
またユニフォームを切り替えたいときは別の Buffer をバインドする (描画しながら適宜更新することはできない) 。
バッチ処理とタイルマップ描画
wgpu
Bevy 0.6 を読んで wgpu 風のレンダリング・パイプラインが分かってきた (Bevy 0.6 を読むメモ) 。
macroquad も流石
Fish Fight のソース を初見であっさり読めたのは Bevy とは全然違うところだなと。
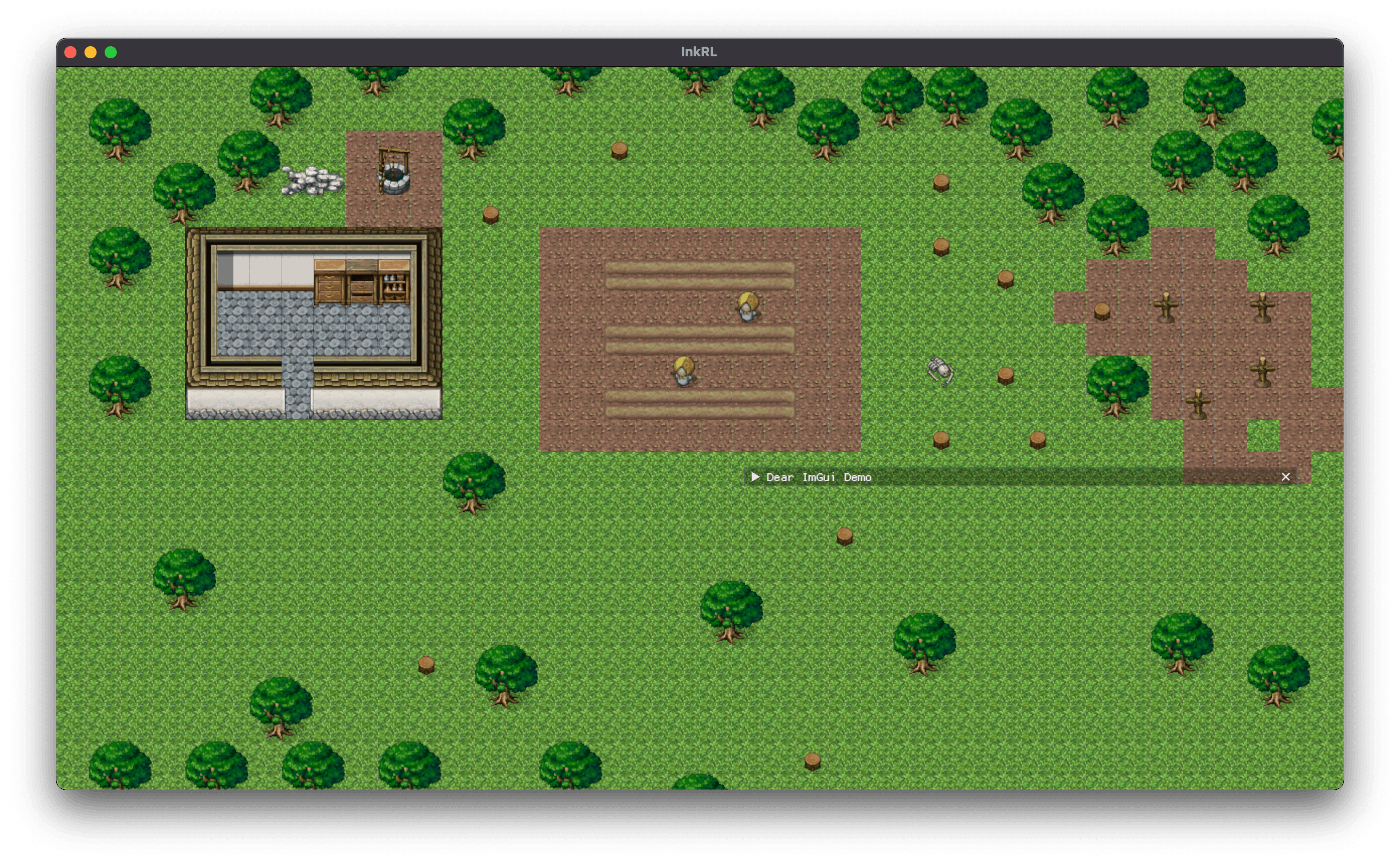
タイルマップ表示
ここまで約三週間か……。 Learn Wgpu で wgpu に入門した後も長く、 wgpu::RenderPass<'a> の影響で完全に設計が変わった。

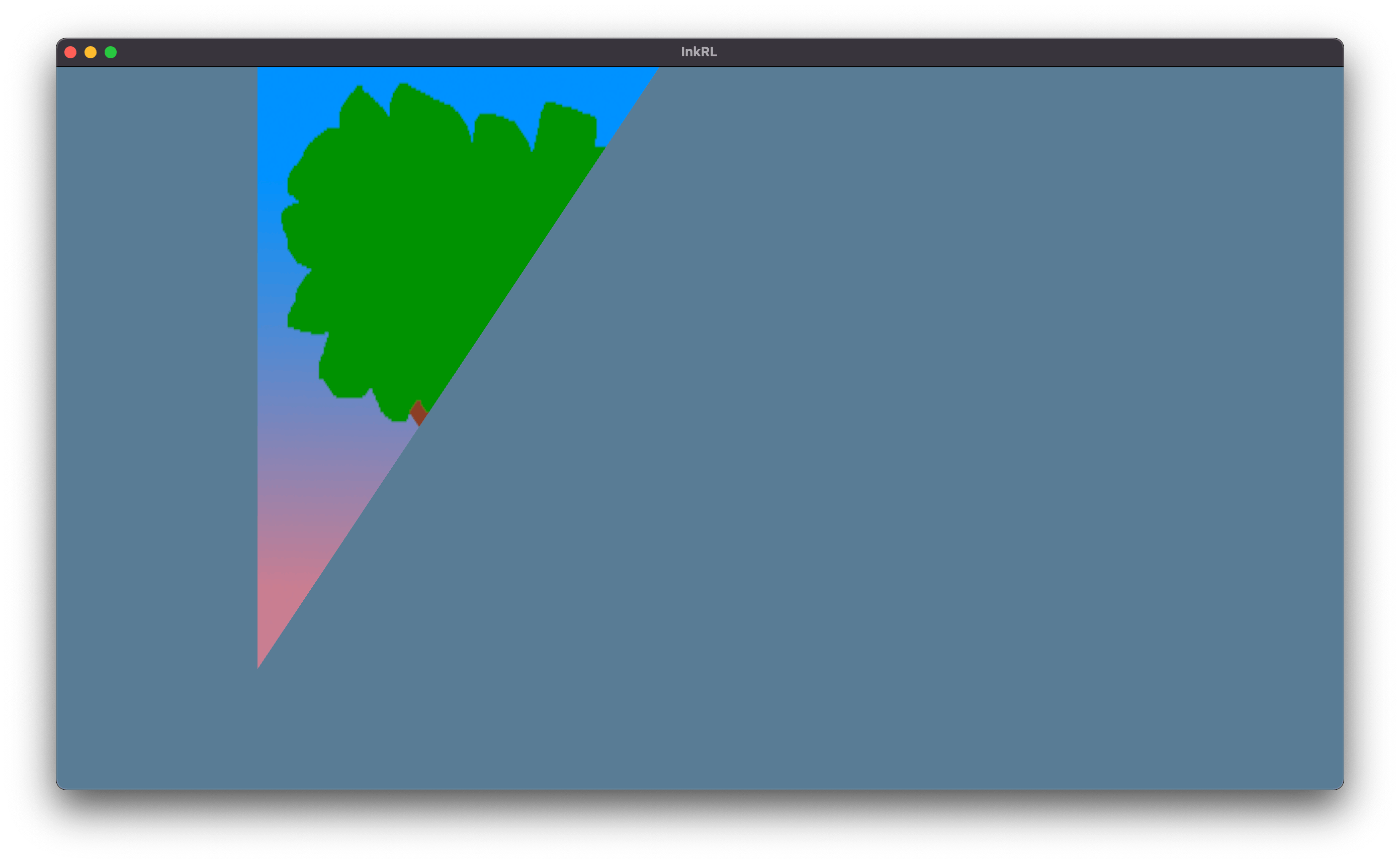
黒い部分は本来は透明なので、次回はアルファブレンドを有効にするところかな。レンダーステージの話もしたい。
アルファブレンドを有効化:
あと少しで元の開発環境と同水準 (以上) に回復できそう。
wgpu を使ったバッチ処理
wgpu::RenderPass<'a> はライフタイムの制限が厳しく、一度引数に取ったデータは自身 (RenderPass) が死ぬまで不変参照を取られる。そのため頂点データを更新しながら描画コマンドを発行するのは難しく、バッファの更新 (Queue) と描画コマンドの発行 (Render) を別フェーズに分けるのが定石となる。
現在の inkfs 🦑 では、 bevy 0.6 を参考に、以下の手順でバッチ処理を行う。
1. 頂点データの作成
動的に作る頂点データは BatchData に書き込む:
pub struct BatchData {
pub verts: Vec<TexturedVertex>,
pub items: Vec<DrawItem>,
// pub vbuf: wgpu::Buffer,
// pub ibuf: wgpu::Buffer,
}
後の手順で描画コマンドを発行するため、 DrawItem を生成する:
pub struct DrawItem {
// 描画する頂点データの範囲 テクスチャの変わり目までをカバーする
pub range: std::ops::Range<u32>,
pub texture_id: TextureId,
}
2. Queue フェーズ
BatchData の頂点データで GPU バッファを更新する。また射影行列をセットする。
新規テクスチャーアセットを見て BindGroup を生成しておく:
#[derive(Debug, Default)]
pub struct TextureBindCache {
map: FxHashMap<TextureId, rgpu::BindGroup>,
// `rgpu` は `wgpu` リソースの参照カウント版を定義する自前のモジュール
}
Bevy は AssetEvent を見て BindGroup を生成/破棄している。 inkfs では、 GPU 画像のカスタムストレージが自動的に BindGroup を作る仕組みにしてみようと思うinkfs でも同じ方法にしてみよう。
3. Render フェーズ
SpritePipeline を適用しつつ DrawItem を元に描画コマンドを発行?する:
let mut last_tex_id = rgpu::Id::dangling();
for item in &batch.items {
let tex_id = item.tex_id;
if tex_id != last_tex_id {
if let Some(bind_group) = tex_bind_cache.get(&tex_id) {
spip.set_texture(&mut rpass, bind_group);
} else {
log::warn!("Render: unable to retrieve texture `BindGroup`");
}
last_tex_id = tex_id;
}
batch.bufs.draw(&mut rpass, 0, item.index_range());
}
4. Submit
最後に、作った CommandBuffer を 1 回だけ wgpu に提出する。 Do's and Dont's · gfx-rs/wgpu Wiki を守ることができた。
今後
BatchData 以外のメッシュや独自のパイプラインに対応したい。
Render フェーズを 1 フレームずらすテクニック (pipelined rendering) は見送るかも。
スクロール:
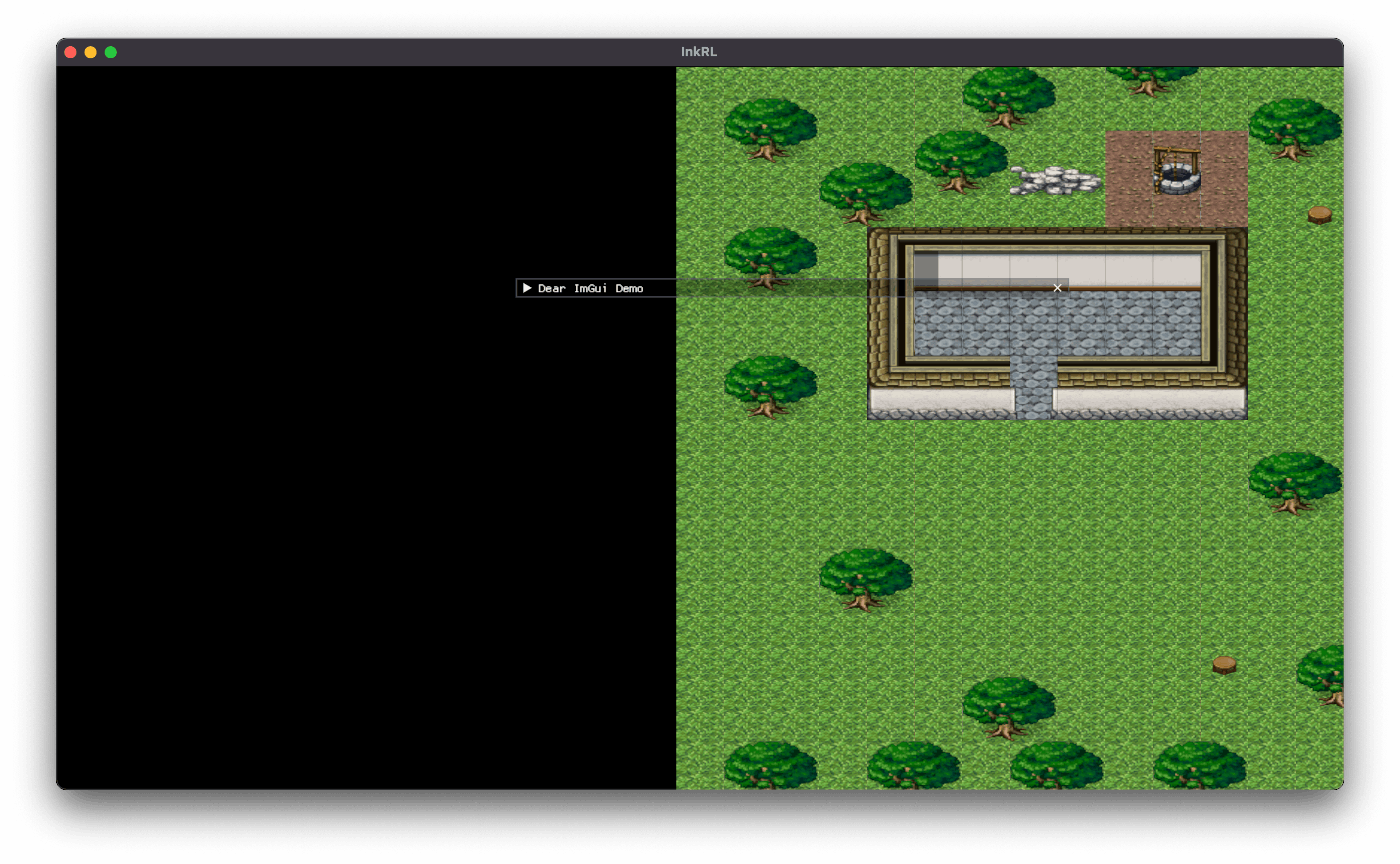
……いや今度こそスクロール:
直行射影行列のパラメータをいまいち理解していない……
突貫工事で off-screen rendering:

スクリーンサイズの 1/4 のテクスチャに影を書き込んでから、そのテクスチャを拡大してスクリーン全体に描画している。
……いろいろ間違っていたのを修正:

- TODO: ガウシアンブラー
- TODO: キャラを歩かせる
- TODO: Pixel-perfect なスクロール
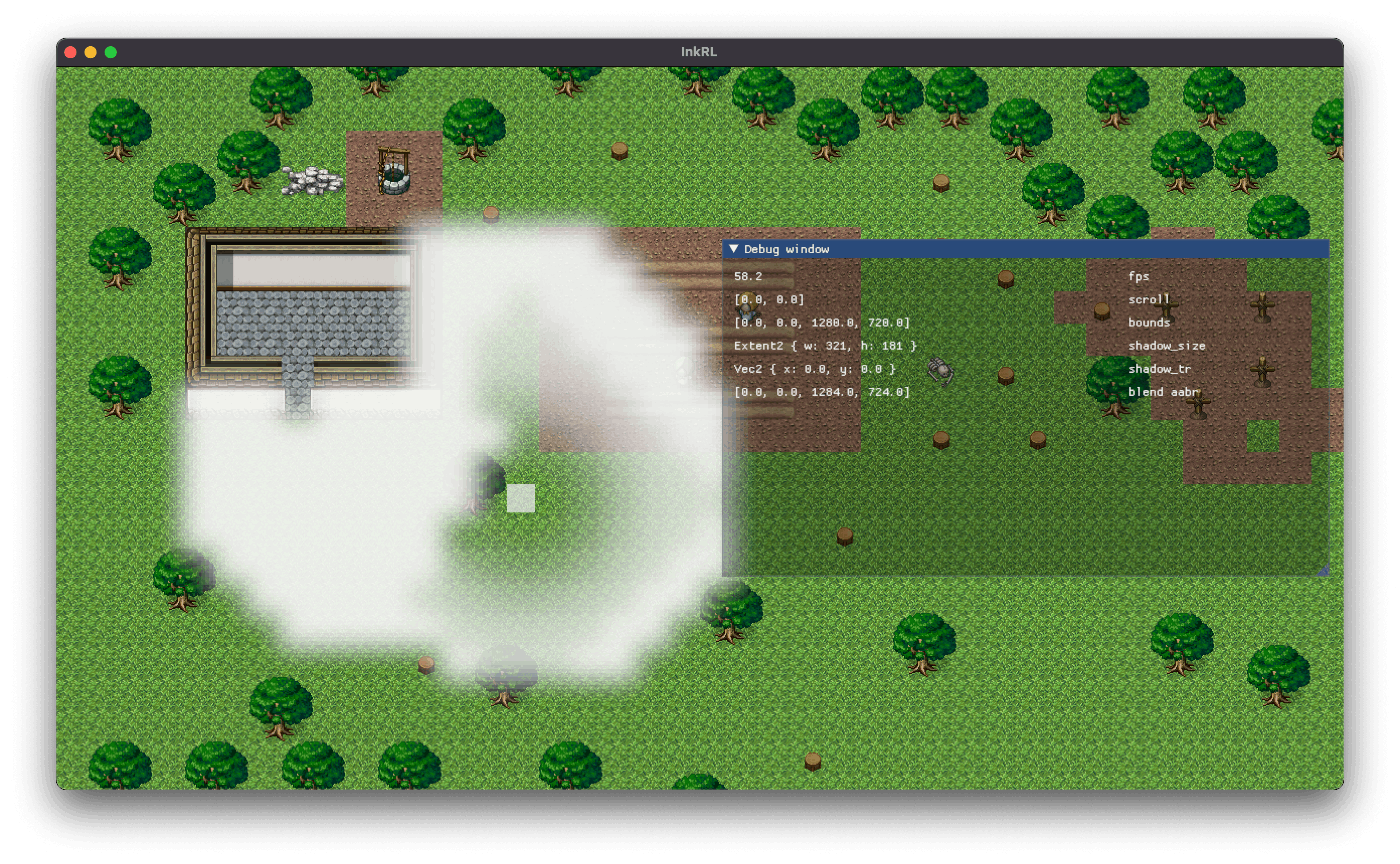
歩いてみた:

ECS が思っていた以上に便利でいい……。ネストしたデータへのアクセスがいかに面倒だったかということの裏返しでもある。。
ブラーがバグっていて原因がさっぱり……
そういえば FilteringMode::Linear を使っていたため、タイルマップの境界に線が見えていた:

FilteringMode::Nearest に修正した。
ブラーが出ない……
パラメータを変えてみると紙吹雪が吹いていた:
うーむ……
平均 FPS を楽に近似する をやってみたら 20 FPS だった。そんな馬鹿な……
計測すると、 wgpu::Surface::get_current_texture が 32 ms (2 フレーム) 取っていた。 macOS におけるこのブロックの原因は VSync を ON にしていたことらしい 。
あの FNA も最近は vsync = off をデフォルトにした。オフにしても問題ない (特に wgpu ではオンにする方が問題の) はず:
let config = wgpu::SurfaceConfiguration {
// ~~~~
// NO vsync by default, or else `Surface::get_current_texture` takes TOO LONG time.
// See: https://github.com/gfx-rs/wgpu/issues/2269
present_mode: wgpu::PresentMode::Immediate,
// vsync:
// present_mode: wgpu::PresentMode::Fifo,
};
無事 60 FPS になった。
キーダウンで FPS が下がるため、 SDL の text_input を無効化した。前に調べた限りでは IME の影響みたい。テストしてくださった人の mac では起きなかった現象なので謎……。
Mac ではこうしたコーナーケースが多い気がする。僕は普段から使っているからいいけれど、他 OS のユーザはサポートしない方が無難な気がする。そして Intel mac は確実に終わりが来ており、僕も M1 mac を買わないとな……
ブラーは置いておき、スクロール中に影がフルフルする問題を解決しよう:

この問題も以前のフレームワークで遭遇済み。影のテクスチャは (画面サイズ / 4) の大きさを持っているのに対し、スクロールは 1px 単位で行われるため、スクロール中は影がセルからずれてしまう。
対策としては、影のテクスチャのサイズを ((画面サイズ + 4) / 4) にすればいい。小数点以下は切り上げ。
修正できない……
詰んだ……
井の中の蛙……? いいえ、ノミです。このノミの脳みそでは丸 1 日かけたって何の進捗も上げられません orz
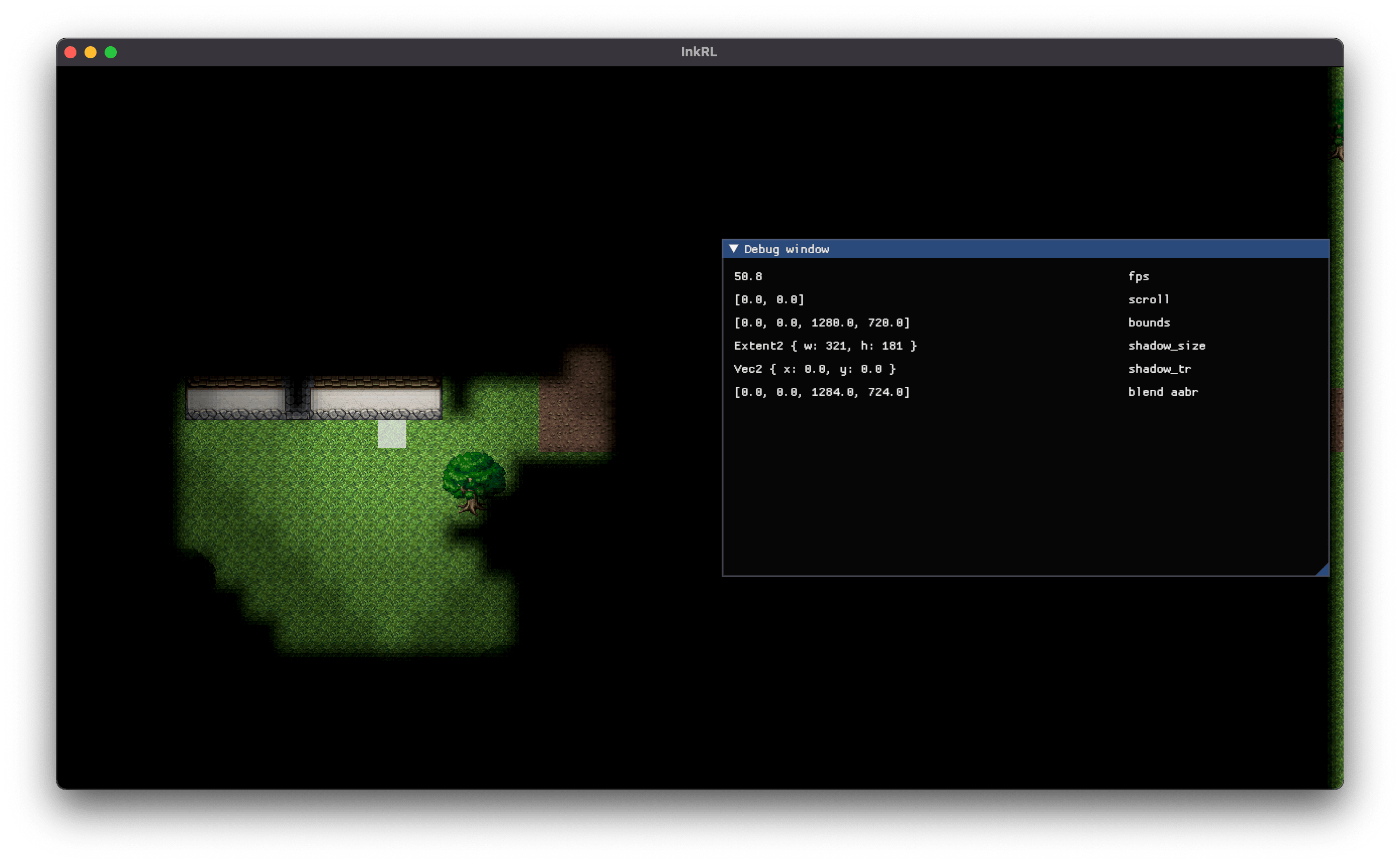
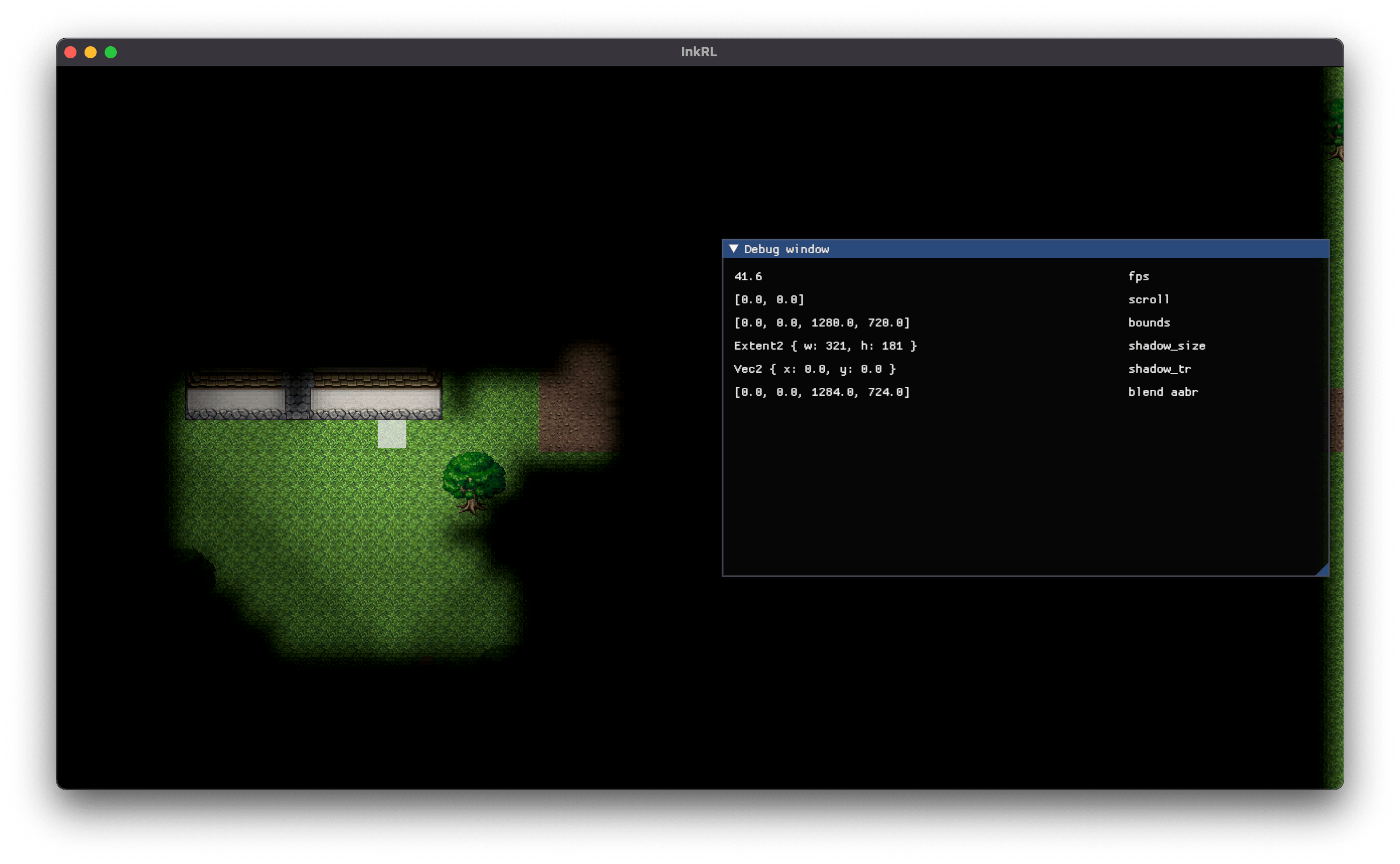
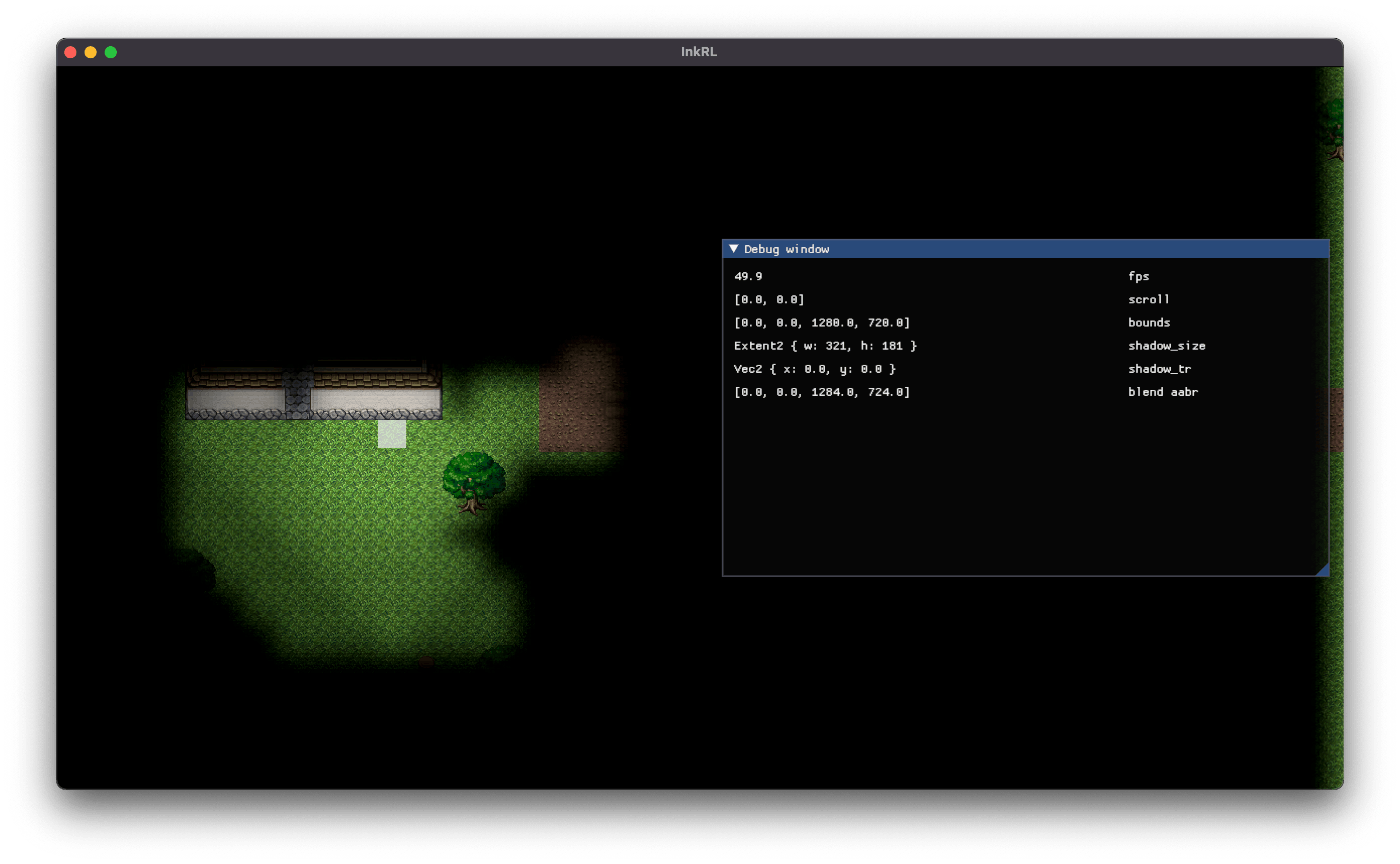
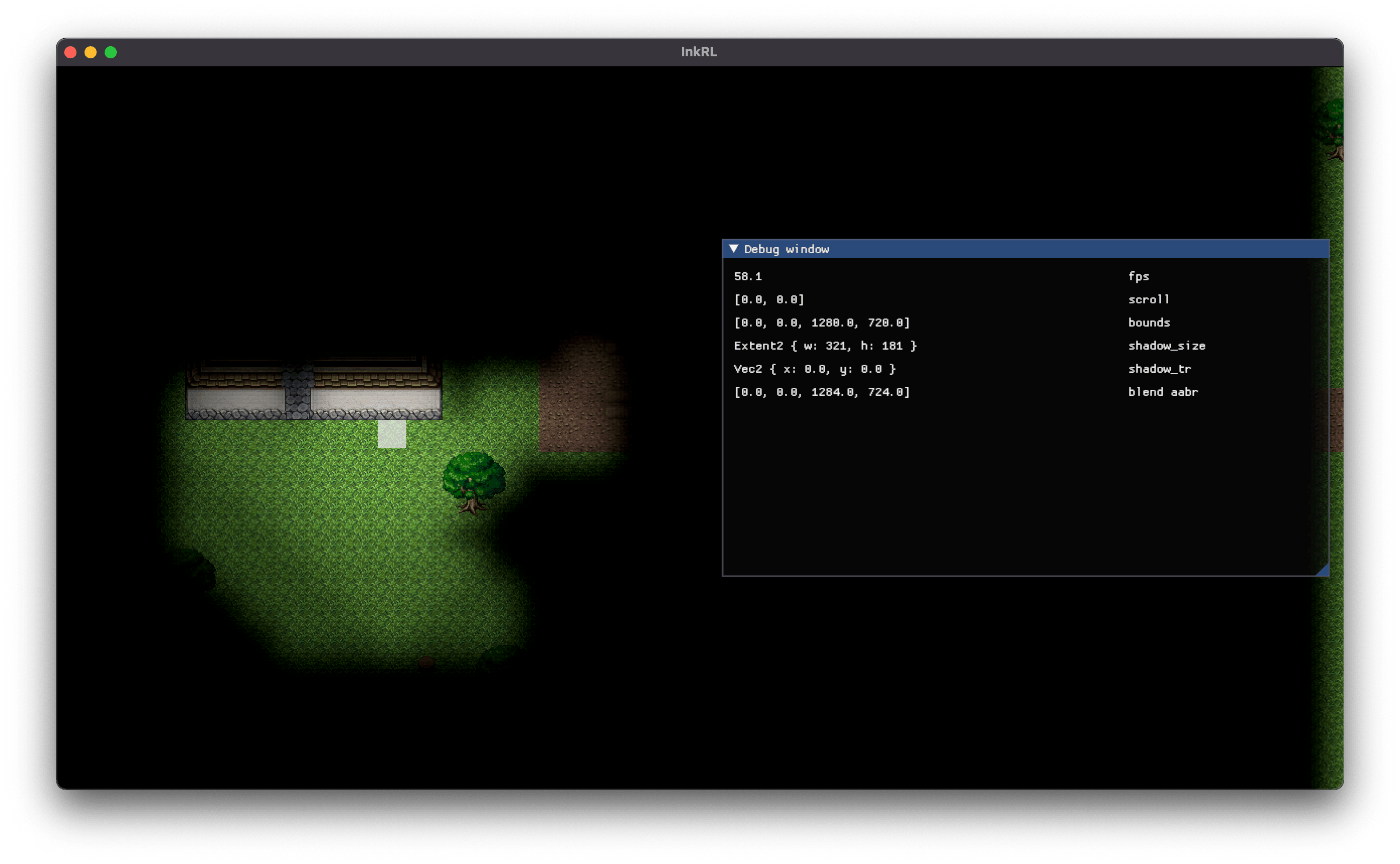
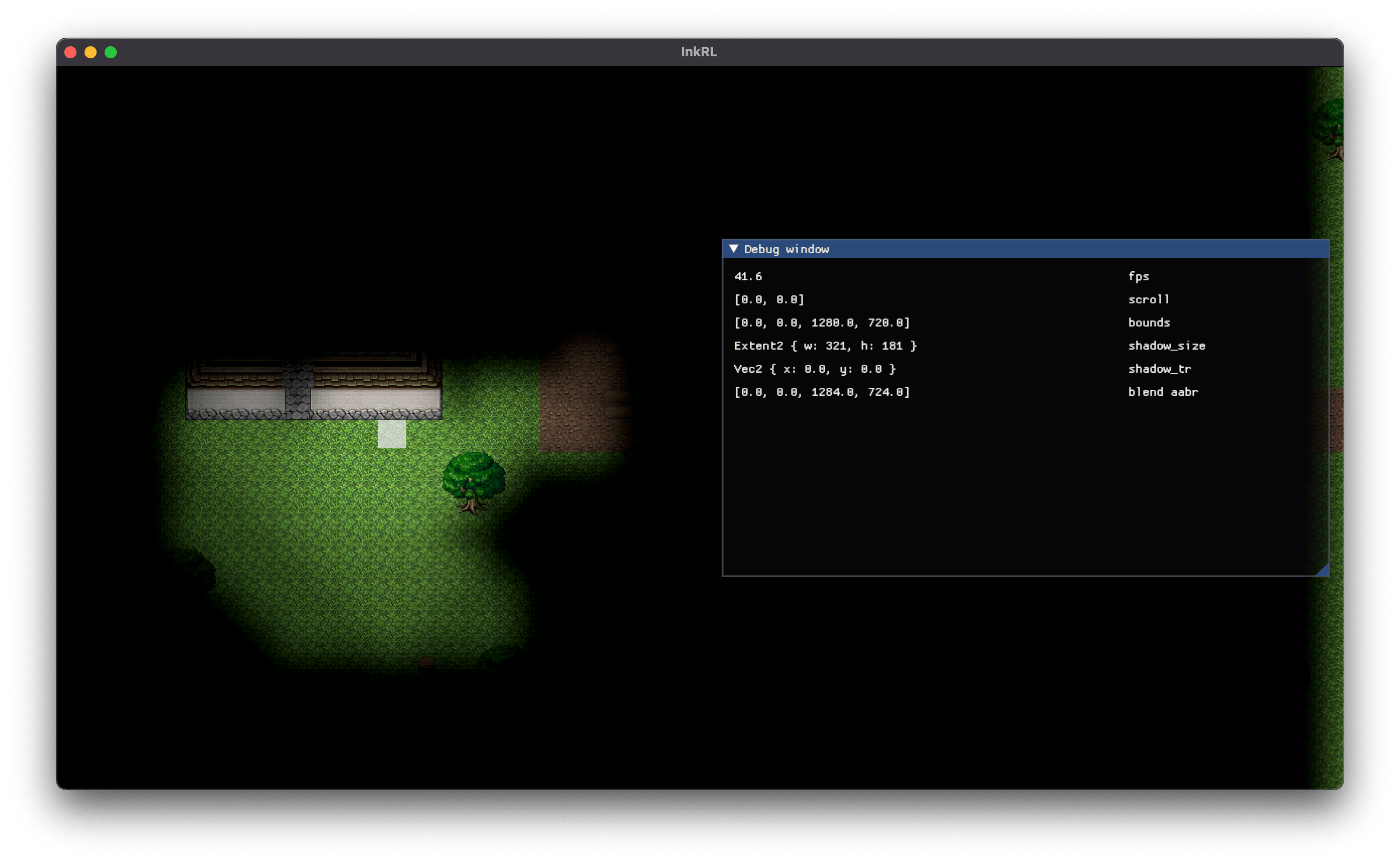
影はズレるよ どこまでも (静止画)
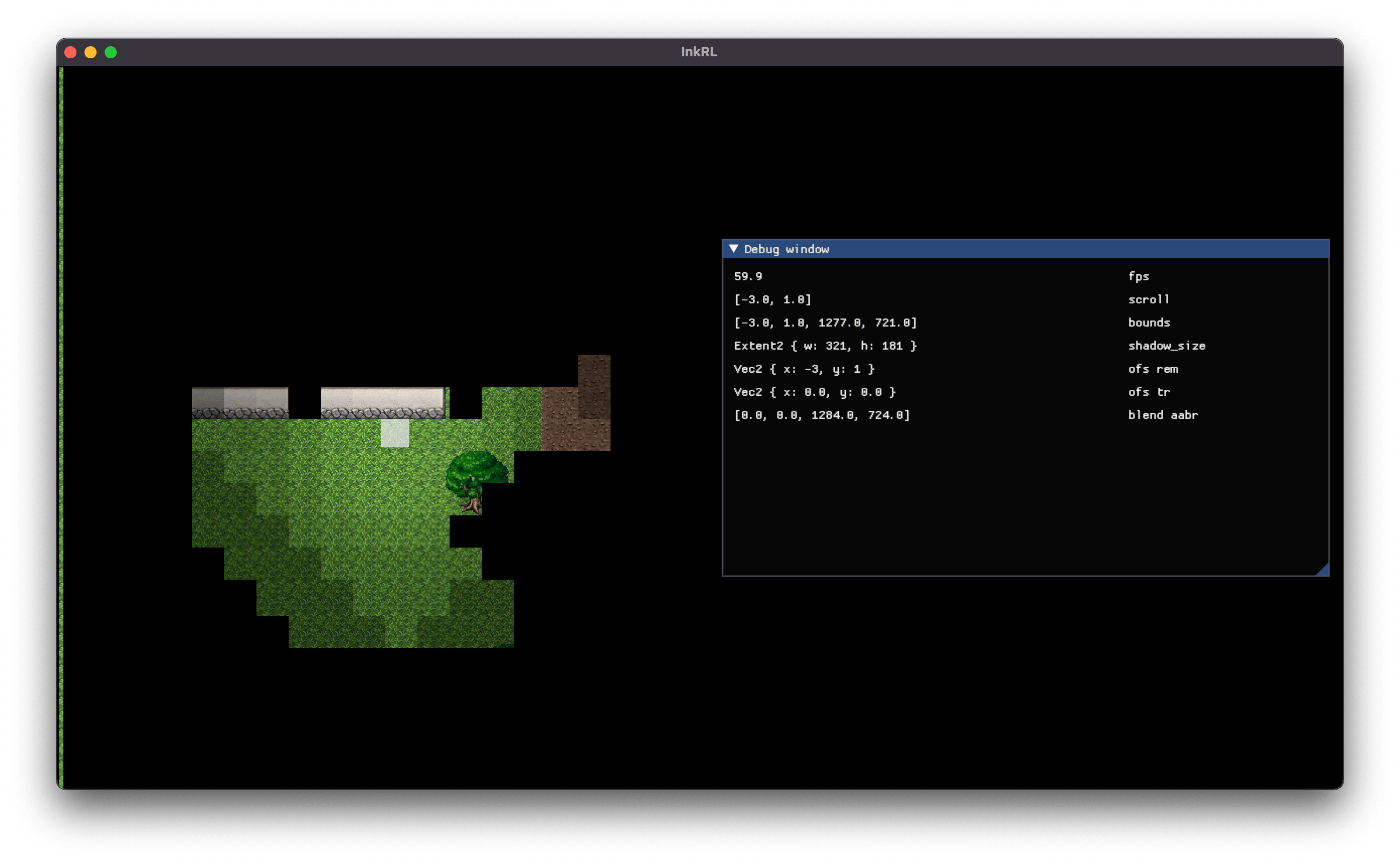
うーむ。ひとまず負のスクロールを考慮して offset = (camera_pos / 4.0).round() * 4.0 に修正した。
原因が分かったかも。
影のオフスクリーン描画で射影行列をセットできていない。スプライト描画のパイプラインを使い回していたところ、後の queue.write_buffer で上書きされてしまうようだ。
Queue::write_buffer がインスタントに RenderPass 経由の描画コマンドに反映されると信じていたけれど、違ったみたい。考えてみると当然で、たぶん Queue の中身はこうなっている?
1. write_buffer(行列)
2. write_buffer(行列) // 後からの書き込みが湯煎
3. `Queue::submit` された描画コマンド
通りで bevy_sprite は描画の最中に変換行列のユニフォームを書き換えない (送る頂点データの方を変換する) わけだ 。専用のユニフォームを作るか、影のオフスクリーン描画用パイプラインを分ければ解決するはず。明日が楽しみ
と言ったが解像度が全然ダメなので情報収集したい。
昔の wgpu の repo にいい issue があった。実用的には、 Render フェーズで BindGroup は不変オブジェクト だと思っておけば良さそう。ユニフォームを切り替えたければ個別の BindGroup を作っておけばいい:
https://github.com/gfx-rs/wgpu-rs/issues/542
この中で タイムライン についてのリンクがあり、見ておいた方がよさそう (見てないけれど):
https://gpuweb.github.io/gpuweb/#programming-model
影の揺らぎ問題解決!
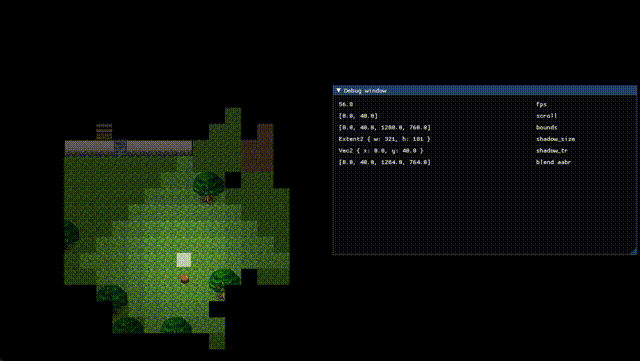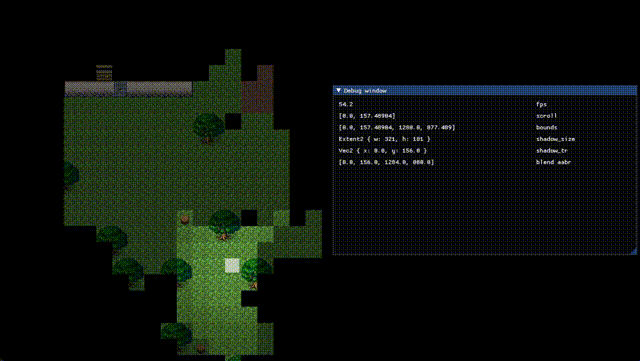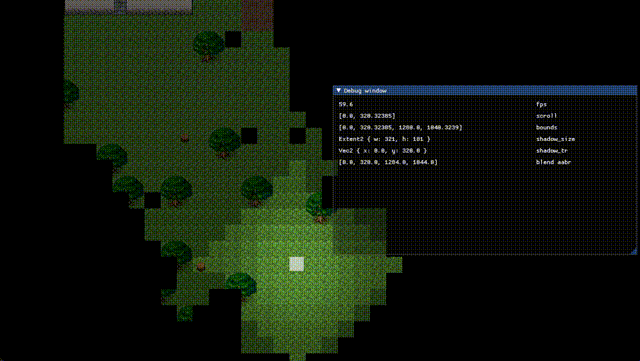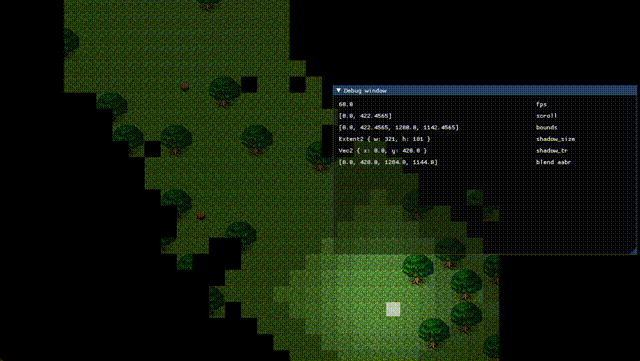
ブラー修正中……色々おかしい

最も不可解なのは WGSL で配列への添字アクセスを使うとデタラメな値が返ってくる ように見えること。ひとまず for ループをハードコーディングの non-ループにしておいたが、何を間違えたのか……。
naga の
追記: ブラー修正
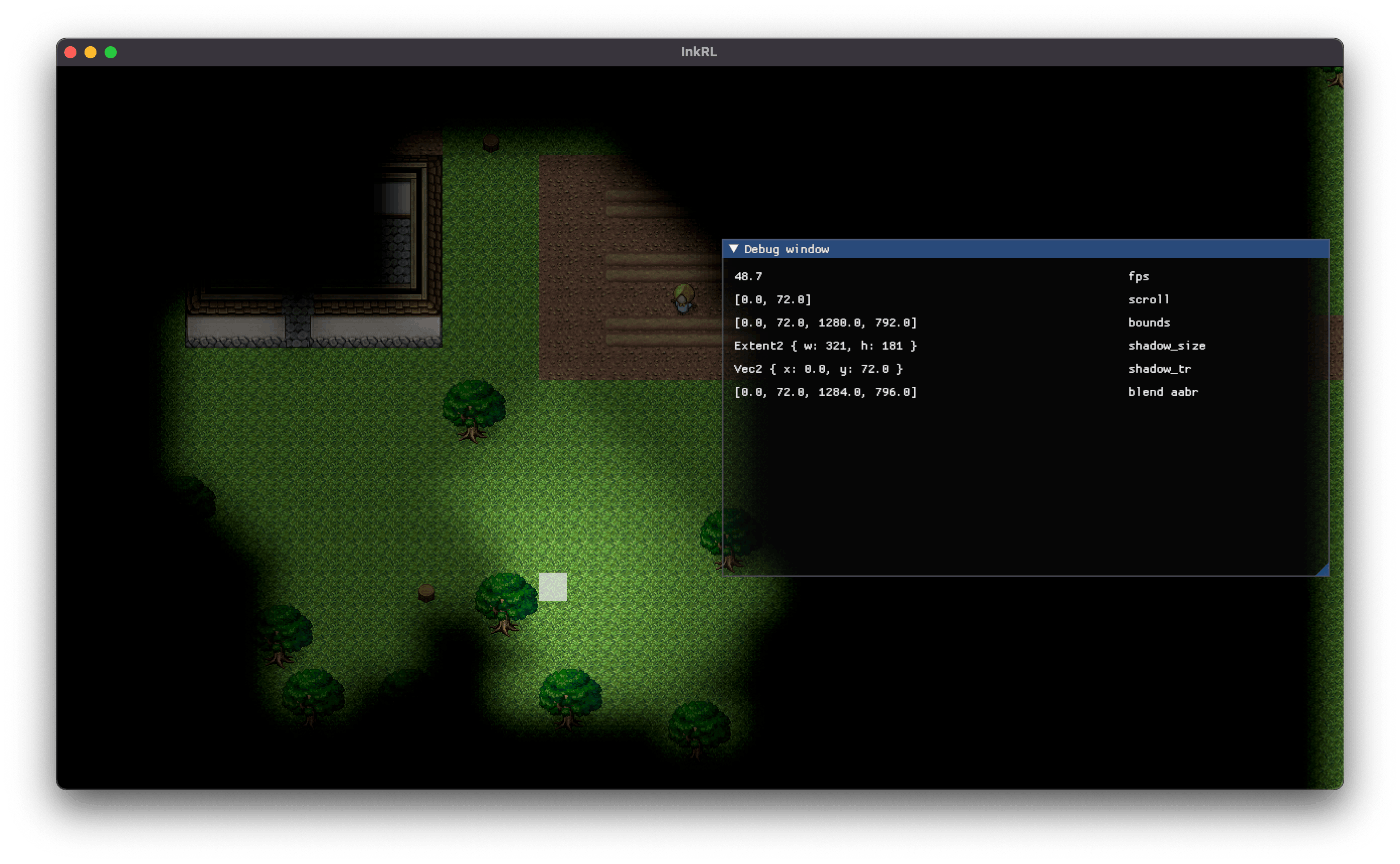
しかし見た目が良くないなぁ……。視野が狭いときは十分カッコいいのだけれど。

まだまだフレームワークの復旧中だけれど、後はゴリゴリ書くだけなので締めます。お疲れ様でした〜