Kubernetes - 2022
- Kubernetes 1.24 以降で追加されるコアリソースは GA になるまでデフォルト無効 (KEP 3136)
- これまでは Beta に昇格した段階でデフォルトで有効になっていて使えていた (e.g. Ingerss, Pod Disruption Budget, CronJob, …)
- Beta リソースはある程度安全に使えるとはいえ本番利用が推奨されていない
- Beta から GA せずに開発が停滞している未完成のリソースにユーザーが依存するのを避けたい
- Beta リソースに依存したユーザーを意識して破壊的変更を避けたり移行パスを考えるのが辛い
- クラスター管理者が起動時のオプションで有効にできるので、使いたい人だけ有効化すれば良い
- アルファ機能を本番環境で有効化しているクラスター管理者が 30% いるので使いたかったら使ってくれるはず
- Beta でユーザーフィードバックを受けて GA に向けて改善するサイクルが壊れるという意見があるが、一般ユーザーが変に依存するよりはコアなユーザーが試してフィードバックをくれれば良い
- 既存の Beta リソース (e.g.
batch.k8s.io/v1beta1/cronjob) はこれまで通りデフォルトで有効 - 既存の Beta リソース (e.g.
batch.k8s.io/v1beta1/coolnewjobtype) で新しいバージョン (batch.k8s.io/v1beta2/coolnewjobtype) がリリースされてもデフォルトで有効 - 新しい機能より安定した機能を求めるユーザーが多いので、Kubernetes にある程度必要な機能が揃ってきた今この舵取りは正しい気がする
- 大きな影響はないですが、GKE でどうなるかは気になる
- Alpha クラスターのように Beta 機能を有効化するオプションを指定できるようにしてくれそうな予感
- 毎年恒例になっている AWS のコンテナ関連のサービス (e.g. EKS, ECS, App Runner, Lambda) のコンテナのスケール時間の年ごとの比較記事 (blog)
- 計測の条件とかセットアップ関連
- 3500 コンテナ起動完了するまでの時間を計測
- Cloud Watch メトリクスだと分単位で精度悪いからスケール時間の計測方法を以下の 2 種類の方法で保証するように変更
- アプリ起動時に時刻をログで吐いて Cloud Watch Logs で集計
- Honeycomb に起動時間のメトリクス送って集計
- インスタンスに今年から ARM (Graviton) を一部使用
- スケール対象のコンテナイメージのサイズ 380 MB (現実のアプリ寄りでそこそこでかい)
- 事前にイメージキャッシュがある AMI 用意したりのイメージレイヤーの最適化などの小細工なし
- EKS on EC2
- 7 分で 3500 コンテナ起動完了
- 2020, 2021 の結果と変わらず
- Karpenter っていう去年末に公開された Cluster Autoscaler の置き換えを使うと Cluster Autoscaler を使うより 1 分程度早くなる
- 今年から IPv6 サポートしていて AWS VPC CNI plugin が IPv6 だと高速化してるらしく IPv4 と比較して 1 分程度早くなる
- EKS on Fargate
- 9 分で 3500 コンテナ起動完了
- 55 分 (2020) -> 20 分 (2021) -> 9 分 (2022) なので順調に早くなっている!
- 9 分で 3500 コンテナ起動完了
- ECS on EC2
- 10 Service に分割で 10 分で 3500 コンテナ起動完了
- 2020 年は計測してなくて、2021 年は計測したけどパフォーマンス悪かったらしく、capacity provider auto-scaling の改善 でかなり良くなったらしい
- ECS on Fargate
- 7 Service 分割で 5 分で 3500 コンテナ起動完了
- 55 分 (2020) -> 12 分 (2021) -> 5 分 (2022) なので順調に早くなっている!
- 5 Service 分割で 10 分で 10000 コンテナ起動できたらしい (すごい)
- ARM と Intel の arch が違うコンテナイメージの比較は 20 秒程度 ARM が早い
- 7 Service 分割で 5 分で 3500 コンテナ起動完了
- AppRunner (Cloud Run みたいなやつ)
- 1 分ちょいで 25 コンテナ起動完了
- まだ 25 コンテナまでしか起動できないらしい
- ECS on Fargate よりは立ち上がり遅いみたい
- 1 分ちょいで 25 コンテナ起動完了
- Lambda
- リミッターあり (瞬間スケール上限が 3000 で、それ以降はスロットリングが掛かって 500 ずつ増える)
- 30 秒掛からず 3500 コンテナ起動完了
- 10000 コンテナ起動は 3500 コンテナでスケール鈍化して最終的に ECS on Fargate に負けてる
- リミッター緩和 (瞬間スケール上限が 15000)
- 10000 コンテナ起動に 20 秒かかってなさそう (やばい)
- 50000 コンテナ起動も 10 分らしい
- Lambda 50000 コンテナで 150 TB of RAM and 90000 vCPUs らしいので規模がおかしい
- リミッターあり (瞬間スケール上限が 3000 で、それ以降はスロットリングが掛かって 500 ずつ増える)
- 計測の条件とかセットアップ関連
-
danielfoehrKn/kubeswitch
- kubectx/kubens と違いターミナルウィンドウ毎に隔離されていてコンテキストが切り替わったりしない
- Kubernetes 1.24 リリース
- OOMKill のメトリクス追加が地味に嬉しい (k/k#108004)
- PHP-FPM のプロセスが OOMKill されても Pod が OOMKill されることがなかったのは、PID 1 のプロセスが OOMKill されない限り OOMKill されることはないかららしい。(k/k#50632)
- このメトリクスでコンテナ内の OOMKill のイベント数が見れるようになるので、そっちでアラート掛けるようにすれば良さそう
- Service.Spec.LoadBalancerIP が非推奨になるのやばい。完全に削除されるのはまだ先らしいけど。Service type LoadBalancer を GKE で作ると L4 の TCP/UDP Load Balancer が作られて特に内部 L4 LB 作るときに .spec.loadBalancerIP は指定しているものがいくつかある。annotation で指定する形に移行って書いてあるけど、今はできないはずだから GKE 側の対応どうなるのかな (k/k#107235)
- アルファ機能だから当分使えないけど CronJob でタイムゾーン指定できるようになるのも地味に嬉しい。UTC で計算しなくて済む (KEP 3140)
- これもやばい、Service Account 作った時に自動的にトークン発行されてたのがされなくなる。Service Account のトークン使ってるケースは少ないけど、Spinnaker とか ArgoCD とかを新規に作るときは注意が必要 (k/k#108309)
- readinessProbe/livenessProbe で grpc プロトコルが指定できるようになるのも嬉しい人多そう (k/k#108522)
- 早速 Service Account を作っても自動的にトークンの Secret が作られないって言ってる人が…。デフォで作られないようになってるけど、やっぱり知らずに使ってる人多いから騒ぎになりそう (k/k#110113)
- OOMKill のメトリクス追加が地味に嬉しい (k/k#108004)
- kube-proxy のイメージを distroless 化して Kubernetes 公式 GCR のダウンロードコストを減らそうとしてる (k/k#109406)
- 前に見た時より増えてる Kubernetes の iceberg (twitter)
- Netflix、ブログで OSS Spinnaker フォークしていじってるとは言ってたけどコントリビュートも完全にやめちゃった

- Helm とか Krustlet (Kubernetes 上でコンテナじゃなくて wasm モジュールを動かす) を DeisLabs (Microsoft Azure) でメインに開発していた人たちがいつの間にかスピンオフして会社を作ってた (site)
- Istio も CNCF に寄贈された (blog, announcement)
- Google さん Knative で商標問題解決できたから同じように Istio も寄贈って流れっぽい
- kubelet ってデフォルトだとコンテナイメージをノード上に 1 つずつシリアルにダウンロードしている
- デフォルトで並列ダウンロードに変えようって Issue (k/k#108405)
- Docker 時代に今は亡き AUFS で並列ダウンロード時にエラーになる問題があった
- containerd でも並列ダウンロードのパフォーマンスに問題があったが最近修正された
- 並列ダウンロードをデフォルトで有効化するとコンテナレジストリへの負荷やネットワーク帯域へ影響がある
- デフォルトの挙動を変えるにしても regression が起きないように慎重になので当分はこの挙動のままっぽい
- やっぱり並列イメージプルだとコンテナレジストリに DDoS する可能性があって怖いから、スロットリングありの並列イメージプルの方向に進むかも (k/k#109956 - comment)
- デフォルトで並列ダウンロードに変えようって Issue (k/k#108405)
- Kubernetes の世界は YAML 1.1 と 1.2 が混在していて厄介 (k/k#34146 - comment)
- YAML 1.1 の仕様だと指数表現をカバーしていないのに YAML 1.2 の仕様を部分的にサポートしているために指数表現として変換されてしまうコミットハッシュの短縮系...
- annotation のキーと値は文字列以外をサポートしていないので、余計な事を考えずに必ず " で囲うのが良さそう (document)
-
yannh/kubeconform
- kubeval 派生のマニフェスト検証ツール
- kubeval の更新が止まっているのでこっち主流になるかも
- kube-dns が EndpointSlice に対応していない (手動で EndpointSlice を作ると認識してくれない) ので、完全に非推奨にする方向に動きそう (k/k#107742 - comment)
- Kubernetes の DNS ベースのサービス検出の実装 (svc.cluster.local. で名前解決できる機能) は kube-dns と CoreDNS がある
- Kubernetes v1.11 から CoreDNS がデフォルトで使われている
- EKS や AKS も CoreDNS を使っていて、kube-dns を使っているの GKE くらい
- EndpointSlice は Endpoints のパフォーマンス改善のためのもので、v1.21 で GA
- Endpoints をシャーディングしたようなイメージ (デフォルトだと 1 EndpointSlice = 100 Endpoints)
- iptables のルールは順序付きリストなので Pod とか Service が多い中で一部を更新する処理が重い
- 互換性のために Endpoints を作ると EndpointSlice にミラーするコントローラーはいるが、逆はない
- Linkerd 2 でマルチクラスターのサービス検出を賢くやるために手動で EndpointSlice を作ってるみたい
- コントローラーを作らない限り、通常のユーザーが EndpointSlice を手動で作るケースはない
- GKE が kube-dns を使っているので非推奨への道のりは長そうですが、やっと CoreDNS への移行を進めてくれそう
- 最近 Kubernetes 関連の Issue/PR でコストの話が出てると思ったら、Kubernetes プロジェクト関連で 年間 3 M$ (約 4 億円) 出てる Google Cloud のクレジットを使い切りそうでやばいみたい (k/k#109938, document, Google Docs)
- Google Cloud のクレジットが年間 3 M$ (約 4 億円) 出るようになったので Google 内部から Kubernetes プロジェクト関連のインフラとかを移行中
- 移行の途中だけどこのまま行くと年末までに 3 M$ 超えそうなので早めに何とかしてしないとコスト削減優先でやらないといけなくなる
- 225,000$/月 (約 3000 万円/月) のうちの 63.7% の 143,000$/月 (約 2000 万円/月) が Kubernetes プロジェクトで使っているコンテナイメージ関連
- その内の 53% が AWS からのトラフィックで Egress 課金 (外向きの通信料) の割合がでかい
- AWS が S3 でイメージのミラーやっても良いよって言ってくれてるから
registry.k8s.ioを爆誕させて裏側に - Cloud Run 上で oci-proxy を動かす
- oci-proxy でリクエストを受けて AWS の IP 範囲から来たリクエストを AWS 側の読み取り専用のミラーのコンテナレジストリにリダイレクトさせる
- GCR の裏側の仕組みも 302 で GCS にリダイレクトさせてるから大規模でも実績がある
- このやり方なら他のクラウドプロバイダも後から簡単に追加できる
- とりあえず各リージョンの S3 に置くようにすれば Cloud Front かませるとかは後から AWS の判断で変えられる
- AWS の IP 範囲どうやって取ってきてるんだろって思ったらめっちゃ泥臭くて、IP 一覧の JSON を引っ張ってきてパースして codegen で Go の変数に突っ込む (source)

-
GKE 1.21 の安定化が遅れたせいで、GKE のコントロールプレーンの今後のマイナー強制更新の予定が凄いことになってる (document)
- GKE 1.21 (2022/4/29) -> GKE 1.22 (2022/6) -> GKE 1.23 (2022/7) なのでほぼ毎月更新しないと
- 普通に考えて現実的じゃないので予定が予定じゃなくなってる
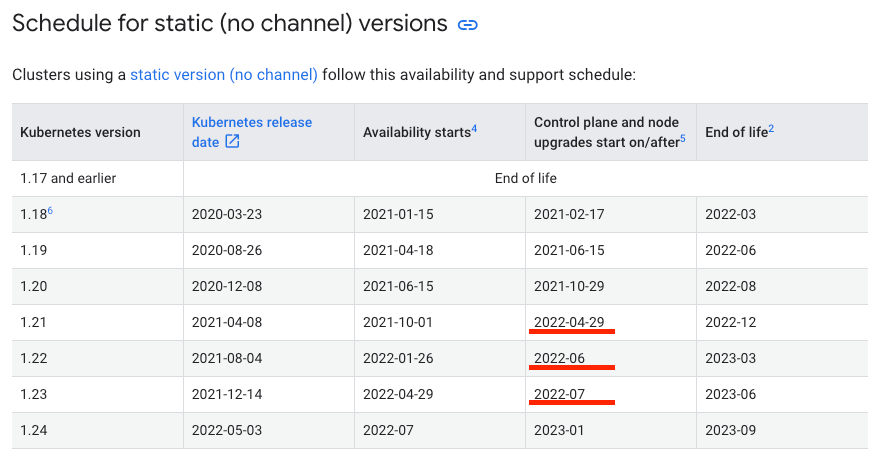
-
GKE 1.22 で報告されてるこのバグ怖い (k/k#109414)
- 特定の Pod の状態 (OutOfmemory, Terminated, …) でしか起きないみたいなので踏むか微妙
- Terminated は Spot VM 使ってる場合だけだから起きないはずだけど、OutOfMemory は起こり得なくはない
- 別の Issue でも似た症状の報告がある (k/k#109718)
- ↑の Issue の原因は別だったみたいで修正されて 1.22 に cherry-pick されているようです。GKE 1.22 に移行する頃には cherry-pick 含んだバージョンに更新されてるかな… (k/k#108749)
- 2 週間後に GKE 1.22 の既知の問題に追加された
- ワークアラウンドがノードプールだけ 1.21 に戻せとか Terminated になった Pod を監視して手動で削除しろとかで辛そう
- アントニオさんが絶賛対応中 (k/k#110115)
- Google の人が今週中に cherry-pick したいからって修正引き継いでマージまで持っていった (k/k#110255)
- cherry-pick の PR も上がってるので、この感じ GKE は Kubernetes 1.22.11 のリリースを待たずに次の -gke.XXX に変更を含めてきそう

-
予定通り Kubernetes
v1.25v1.26 で client-go/kubectl からクラウドプロバイダー固有の認証の実装を削除 (k/k#110013)- GCP と Azure だけ優遇されていたが、みんな仲良く平等にそれぞれのクラウドプロバイダーの auth plugin をインストールして ExecCredentials に指定して認証するようになる
- GKE の移行方法 (blog)
- GKE で
gcloud container clusters get-credentials ${CLUSTER_NAME}を実行すると~/.kube/configに以下の設定が追加されてた - auth-provider の実装が client-go/kubectl に組み込まれていたので、別途 auth plugin をインストールする不要はなかった
-
GKE 1.25GKE 1.26 以降でgke-gcloud-auth-pluginのインストールが必須
❯ cat $HOME/.kube/config (...) users: - name: gke_gcp-sample_asia-northeast1_sample-cluster user: auth-provider: config: access-token: "**redacted**" cmd-args: config config-helper --format=json cmd-path: /usr/lib64/google-cloud-sdk/bin/gcloud expiry: "2022-04-18T08:55:11Z" expiry-key: '{.credential.token_expiry}' token-key: '{.credential.access_token}' name: gcp- メジャーなクラウドプロバイダーの中で EKS だけハブられていたのですが、逆に今回移行する必要がないので混乱は避けられそう
❯ cat $HOME/.kube/config (...) users: - name: arn:aws:eks:ap-northeast-1:${YOUR_ACCOUNT_ID}:cluster/${YOUR_CLUSTERNAME} user: exec: apiVersion: client.authentication.k8s.io/v1alpha1 args: - eks - get-token - --cluster-name - ${YOUR_CLUSTERNAME} command: aws
-
Gardener (GKE/EKS みたいなマネージドな Kubernetes as a Service を作るためのツール) が GCP 上の Kubernetes を 1.20 -> 1.21 に更新した後に、ノードから GCE の永続化ディスク (PV) が外れ、ノードが Unhealthy になり、ノード上で動作していた Pod がディスク外れた影響で I/O エラーになり死亡するバグを踏み抜いた (k/k#109354)
- GCE PD CSI migration が有効になっていてかつ external-provisioner >= v2.1.1 の組み合わせで発生するバグで、最終的に external-provisioner のバージョンを v2.1.0 で固定かつ手動作業で回避
- GKE でもバグを踏むことはあるんですが、ここまでやばいバグは安定化する前に事前に報告が上がって修正されるから GKE さんいつもありがとう
- Gardener の人、前にも同じようにやばいバグを報告したときに無視されたらしく、今回も無視するつもりかって途中でブチギレてたんですが、流石に Google 側もやばいと思ったのか対応策を 5 つも考えて返していたので Gardener の人も機嫌が直ってホッとした (Google Docs)
- 1.20 -> 1.21 で完全に削除されたラベルの影響で GCE ディスクの zone の情報が UNSPECIFIED となって壊れたみたい
- external-provisioner v2.1.1 の依存していたライブラリが 1.21 以降でしか動かない前提だったっぽい?
- Envoy Proxy を Kubernetes Gateway API をベースに抽象化した North-Source に特化した Envoy Gateway がアナウンスされた (blog)
- Contour と Emissary (旧 Ambassador) の共通機能をベースに作るだけじゃなくて最終的に Envoy Gateway にマージされるっぽい
- Envoy Proxy が低レイヤー過ぎて Nginx, HAProxy の天下が揺るがないので、抽象化したシンプルな API で対抗するみたい
- Cilium を開発してる Isovalent が Cilium Enterprise の一部として提供していたセキュリティ機能を OSS 化した Tetragon (blog)
- GCP のマネージド Prometheus、リリースから 2 ヶ月で値下げ (blog)
- VictoriaMetrics 社のマネージド Prometheus サービスのコスト比較記事 (blog)
- Kubernetes の E2E テストの一部が壊れていた原因が GCP サービスアカウントキーの有効期限切れだったが、何で 3 ヶ月毎に手動でローテーションしてるの?自動化しないの?って突っ込まれてた。
- 実際は自動ローテーションできる仕組み (Workload Identity) に移行したいんだけど、ずーっと前に非推奨にしたスクリプトをまだ使ってる人たちがいて移行できないらしく…わかりみが深い
-
nobody is staffing any effort to migrate despite creating the new thing and deprecating the old thing :逆立ちでにこっ: (k/k#110060 - comment)
- kube-apiserver が安全に停止するまでのフロー図分かりやすくて良い (hackmd)
- 実際のコードだと channel 多用してて混沌としてますね。最近、図が追加されたので追いやすくはなってるけど、それでもよく分からん (source)
- HackMD の図でシグナル受けてもすぐに死なずに 70 秒間 sleep してるのは僕らも PreStop hook でやってるやつですね。Graceful Shutdown = 新規のリクエストの受け付けをやめて処理中のリクエスト捌いて停止するだけじゃだめで、LB から外れるまでは当然リクエストを受けることはあるのですぐに Graceful Shutdown に入ると 5xx 系出ちゃいますね
- Datadog 先生の DNS 障害かと思ったら原因違ったわの記事めちゃくちゃ良かった (blog)
- KubeCon 2022 Valencia でも発表したみたいなので録画公開が楽しみ (event)
- アプリケーションを展開中に DNS 障害が発生
- リトライが走ったので大きな障害にはならなかったけどレイテンシ影響がでかかった
- NodeLocal DNSCache が OOMKill されてたからスペック上げたけど OOMkill される
- ノード上の conntrack に余裕はあるけど、Elastic Network Adapter のメトリクスを見たら VPC conntrack が溢れてパケットが drop されているように見える
- AWS に問い合わせたら VPC conntrack のサイズはインスタンスサイズによるからスペック上げれば直るんじゃない?スペック上げたら直ったけどもっと調べる
- スペック上げて直ったからいっかで終わらせないの本当に偉い
- 後日別の展開中に VPC Flow Log を有効化して見てみた
- クライアントが展開前の古い Pod に接続しようとしている
- 古い Pod への接続に対して RST パケットが大量に発生しているだろうと思ったら、何故か SYN パケットが大量に発生している
- AWS のネットワークのおさらい
- ホストネットワークが有効かどうかで primary ENI と secondary ENI どっちで通信するかが変わる
- 古い Pod が消えると secondary ENI を通る経路のルートテーブルは消えるが、primary ENI を通る経路のデフォルトのルートテーブルは残ってるからフォールバックするはず
- primary ENI を通って外に出ようとしたら Linux の Reverse Path Filtering の機能でパケットがドロップされ、ノード上の conntrack に記録が残らない
- クライアントも SYN-ACK とか RST とかが返ってきていないので接続先がどうなってるか知る由もなく再送を繰り返している
- Linux カーネルのソースコードで動作を確認 (割愛)
- Cilium に PR を投げた話
- Cilium が古い Pod IP 用のルートテーブルを削除する際に一緒に ICMP エラーを返すように unreachable なルートテーブルを作ることで回避
- やっと本題
- Cilium のバグで Reverse Path Filtering に引っ掛かって問題が見えづらくなっていた
- なんでクライアントは古い Pod IP に SYN パケット送りまくっているのか調べていく
- Datadog はマルチクラスタ間のサービス検出に Route53 + External DNS を使っている
- External DNS で Pod IP 登録しているらしいけど、どうやってるかの詳細は分からず... (Headless Service?)
- External DNS の TTL が 15 秒で External DNS のレコード同期の間隔が 15 秒
- 15 秒の TTL, 15 秒間隔でのレコード更新、クライアント側のタイムアウト 10 秒なのでワーストケースで 40 秒後にクライアントが正しく名前解決できるようになる
- gRPC クライアントがサーバーから切断されて再接続を繰り返す中で再度名前解決する間隔がデフォルトで 30 秒
- これまでの情報だと SYN パケットの大量発生に繋がりそうな要素がない
- ここまで来てやっと gRPC クライアントの設定を疑う
- クライアントサイドの負荷分散ポリシーを
pick_firstからround_robinに変えたタイミングで問題が発生していた -
round_robinだと全てのバックエンドに順番に繋ぎに行くので大量の SYN パケットの説明がつきそう
と思ったけど、アプリ の実装よく見たらバックエンド毎に gRPC channel を作ってるだけだから、pick_firstだろうがround_robinだろうが変わらない
- クライアントサイドの負荷分散ポリシーを
- gRPC の再接続の挙動が怪しそう
-
pick_firstだとクライアントが再度サーバーに接続しようとするまで自動的に再接続しない -
round_robinだと自動的に再接続する、で再接続の間隔は backoff の設定で変えられる - backoff の設定はデフォルトが最大 20 秒だけどそれだと長いから短くしようぜって軽い気持ちで最大 300 ms で再接続するようになっていた
- サービス全体で 9000 クライアント (600 Pod * 15 container) あって、300 ms 毎に再接続したとしても SYN パケットが 30,000 rps で発生する計算
- 観測した SYN パケットの規模と一致!
- backoff の設定戻して問題解決、ここまで数ヶ月かかった
-
- 読んだ感想
- 上流で問題が隠匿されている可能性もあるので、Elastic Network Adapter (AWS) とか VPC Flow Log (AWS, GCP) 的なメトリクスもちゃんと見た方が良い
- 既に知っていることでも内部の仕組み (今回はネットワークの流れ) を改めて整理してから仮説を立てて再現手順を見つける
- 一番難しいし、大体思い込んじゃう
- この人たち当たり前のように Linux カーネルのソースコード追いかけてるけどなんなん
- テストに想定した挙動が書いてあるからそっち見るとヒントが得られるってのは最近身についてきてる気がする (テストが正しいこと前提)
- gRPC のクライアントサイドの負荷分散の設定、ポリシーによって挙動が微妙に違うのでちゃんと理解して使わないとヤバそう
- 復旧優先したくて再接続の間隔を短くするのありがちだけど、再接続の間隔を短くしたってストッパーが他にある (今回のケースだと DNS の更新間隔) と意味がないし、その分余計に他の部分を壊すことに繋がるから注意
- この前の Gardener が見つけたバグとは全く別の PV 関連の GKE のバグが見つかってた (kubernetes-sigs/gcp-compute-persistent-disk-csi-driver#987)
- GKE 1.22 で PV 使っている Pod が別のノードにスケジュールできなくてスタックすることがあるらしい
- Spot VMs とか Cluster Autoscaler の shrink でノードが停止して Pod がスケジュールする時にも発生しうるので影響範囲でかい
- GKE 1.22 だから Rapid チャンネルか Regular/No channel で最近 GKE 1.21 -> 1.22 に上げたユーザーが踏んでそう
- component version って
pdcsi-nodeのラベルに付いてる GKE が内部的に採番しているバージョンのことだろうけど分かりづらい - こっちで結構前から報告あったっぽい (comment - kubernetes-sigs/gcp-compute-persistent-disk-csi-driver#608)

- TLS 証明書と認証トークンがないと何もできないとはいえ、ノーガード戦法凄い (blog)
- IoT とか Edge で Kubernetes 動かしてる人たちとかなのかな
- Kubernetes のバージョン分布がリアルな感じでいいですね。1.21 がやっぱり一番多い
- GKE のパブリッククラスタとかプライベートクラスタでもコントロールプレーンのグローバル IP を有効にしてると GCP 内部からアクセスできちゃう謎仕様なんですが、さすがに GCP 内部からスキャンされてないよね…?
-
https://cloud.google.com/kubernetes-engine/docs/how-to/authorized-networks?hl=ja
承認済みネットワークは、Google Cloud の外部にある信頼できない IP アドレスをブロックします。必要な Kubernetes 認証情報があれば、Google Cloud 内部のアドレス(Compute Engine 仮想マシン(VM)、Cloud Functions、Cloud Run からのトラフィックなど)から HTTPS を使用してコントロール プレーンにアクセスできます。 - Private Service Connect 使って通信するようになると解決しそう (release notes)
-
- Z Lab (Yahoo) の人が報告している 1.22 + Dockershim のこのバグ気になりますね。ノードに Pod を詰め込みすぎたり、長期間起動し続けているノードだと問題になるかも?1.22.8 以降の containerd なら起こらないってあるからたぶん大丈夫だろうけど (k/k#110181)
- containerd の修正のバックポート (k/k#108189)
- 1.22.8 に入ってる (release notes)
- もともと static pods の話なのがまた
- static pods の問題は 1.22.8 でも直ってない報告があるけど、これはまた別の問題か。ややこしい (comment - k/k#107483)
- GKE 更新を塩漬けにしているとこうなる (release notes)
- 一度乗ったら降りられない
-
GKE clusters that run control plane versions 1.21 or later and node versions 1.16 or earlier might experience:
- Readiness check failures.
- Network endpoint groups (NEGs) and load balancers (LBs) not created or synced.
This occurs because the Ingress controllers running in GKE cluster control plane versions 1.21 or later are not compatible with node versions 1.16 and earlier. To resolve this issue, upgrade your node pools.
- EKS だと選べる Kubernetes のバージョンが少なくて、追従も遅いので upstream の修正が cherry-pick されても EKS で使えるようになるまで待たないといけないから辛い (comment - k/k#105204)
- EKS は Kubernetes に当てたパッチ公開してるの羨ましいですね (source)
- GKE もノード上に zip で固められたKubernetes のソースコードが置かれているんですが、Git の情報とか当然消されているので、upstream のバージョンとの差分を見てああこの修正ねって分からないと厳しいですね
- GKE 1.22 から COS だと COS 93 にノードのイメージが変更になります。カーネルのバージョンが 5.4 系から 5.10 系に変わるので少し心配 (release notes)
- Ubuntu のノードイメージの詳細どこにも書いてないからあげてみないと分からないですね。そういう意味でも早く COS に移行しちゃいたい
- 同一ノード上で IPv4 だけ、IPv6 だけ、IPv4/IPv6 dual stack の Pod が混在して動いてるのかっこいい。ただ、これは無理やり動くように修正した奴なので、今の Kubernetes だと無理ですね (comment - k/k#109814)
- Pod とホストの user namespace を分離するオプションを追加する KEP です。
Pod の User ID と Group ID をホスト上の別の ID に紐付けるので、Pod 内で root ユーザーでもホスト上は root ユーザーではなくなり、ホストの特権が掌握され辛くなります (KEP 3317)- 実際、Kubernetes 関連の脆弱性でコンテナ内からホストの特権を取られることが多かったので効果ありそう。コンテナランタイム側のメンテナーが揃ってたり、PoC が既にあったりで、今一番熱量を感じます。
- Pod 同士でノード上にマウントした Volume を共有する系が面倒で、Pod レベルだと別の User ID と Group ID だけど、ホスト上は同じ User ID と Group ID に紐づけるみたいです。あとは、ホスト上の ID 範囲どれくらい確保するかとかアルファで様子見て決める予定のものがありますね
- 起動中の Pod がいる状態で containerd を再起動すると Pod が ContainerCreating の状態でスタックするそう (containerd/containerd#7010)
- 再起動後に同じコンテナ ID に対してネットワークの初期化処理が再度実行されて既にネットワークの初期化が終わってるよエラーになるみたい
- containerd を意図的に再起動したりはしないので影響はない
- 何で containerd を再起動してるんだろうって思ったら悪いこと考えてる人たちがいるみたいで。Google の人が報告しているので、GKE 上で DaemonSet とかで containerd の設定ファイル書き換えて再起動してる人たちがいそう。何を変えてるのかまでは分からないですが
-
Note that even though not documented officially, restarting containerd seems to be the go-to way for a few customers we know so far for containerd configuration changes to take effect.
-
- GKE の CNI 実装について言及してくれていて助かる。OSS 版と作成する veth の名前だけが違うの何でだろうって思ったらネットワークポリシーのためなのか。で、コンテナ ID を veth の名前に付けてるから見た感じコンテナ ID を直接使っている訳じゃないけど再起動時に作成しようとする veth の名前が同じになる何かしらのロジックがあって、既にその名前で veth あるよエラーになった感じですね。
-
The veth name is consistently generated. While the OSS PTP CNI uses randomly-generated name hence tolerates this issue better, there are downstream versions of PTP CNI that requires consistent veth naming for e.g. network policy purpose.
-
- GKE CNI 実装については去年調べていて、予想通りでした。自分えらい (blog)
-
ホスト上に作成された仮想ネットワークインターフェイスの命名規則 (prefix とランダム文字列の生成方法) 以外に大きな違いはないように見えます。
-
- bitnami の Helm リポジトリが 6 ヶ月以上経過した chart を index.yaml から削除するようになって大惨事になっていたみたい (bitnami/charts#10539)
- Helm リポジトリが巨大になりすぎて (index.yaml が肥大化しすぎて)、利用者も多くて CloudFront が耐えられなくなったらしい
- 毎月数千 TB の下りトラフィックはえぐいですね
- chart の .tgz 自体は残っていて index.yaml をダイエットしただけだから Helm リポジトリを追加するときに過去のコミット指定すれば動くみたいです。それならまだ救いはあるけど、急に動かなくなったら焦りますね
- コンテナイメージと一緒で Artifact Registry に同期した方が良いかも
- そういえば OpenMatch が使ってたなって思ったら案の定壊れてた (googleforgames/open-match#1463)
- Kubernetes 1.22 からのリグレッションで停止中の Pod に対して readinessProbe が実行されず Pod の状態が unready に遷移しないよう (k/k#110191)
- Ingress (GKE だと container-native Load Balancer) は Load Balancer 側で NEG に対してヘルスチェックを実行しているので影響ないはず。
- Service (ClusterIP, Load Balancer) は影響ありそうですが、アプリ側の停止処理が重くないなら unready に遷移しなくてもすぐに Pod 自体が消えれば影響は気にならないレベル?
- Service を使っていると preStop hook で readinessProbe が失敗して接続先がなくなるであろう時間固定で sleep するようにしてますが、readinessProbe が実行されていないなら sleep 後に Graceful に停止している (新規接続を受け付けなくして既存の処理中のリクエストを捌いて停止) のにリクエストが来ちゃって 5xx 返すことはあるかも
- 1.22 に cherry-pick (k/k#110418)
- Kubernetes SIG 関連のツールが registry.k8s.io に移行を始めてるんですが、GKE の private クラスターかつ Cloud NAT がないとイメージを落とせず起動できなくなるので注意
-
registry.k8s.ioの前段が Cloud Run で動いているのでインターネットに出れずに失敗してそう。(嫌な予感はしてた) - kube-state-metrics が移行していて、private クラスターかつ Cloud NAT がない場合は一時的に
k8s.gcr.ioに変更してあげないといけない (k/k#1750) - サポートに問い合わせていた件、Google の人が upstream で質問してくれてました。1.25 で
registry.k8s.ioに切り替わるのを待っていると $3M/年のインフラコストを年内に使い切っちゃうから、それを待たずにk8s.gcr.ioをregistry.k8s.ioにリダイレクトすることも視野に入れて GCR チームと相談中らしいです。どちらにしろ事前にアナウンスは必要だし、#sig-k8s-infra とも議論が必要だからすぐにどうこうはなさそうだけど、かなり切羽詰まってることは分かりました (comment - k/k#109938)
-
- GKE の private クラスターの control plane へのアクセス制限が Google Cloud 内だとガバガバだったのが少し改善されるよう (blog)
- Firewall のルール的にアクセスできるだけで権限と証明書などの情報がないと何もできないけどセキュリティ強化する
- GKE に関連するプロダクトはこれまで通りアクセスできる
- GKE に関連しない Cloud Run や Cloud Functions が今回の対象で叩けなくなる
- public クラスターはノードが Global IP を持っていて control plane と通信できないといけないから今回の制限強化の対象じゃない
- ExterernalTrafficPolicy が Local の場合にノード (kube-proxy) を 1.20 -> 1.22 に一気に上げると LB 経由で繋がらなくなる問題の修正です。やっぱりノードプールだからって飛ばしてあげるのそれなりにリスクがありますね (k/k#110245)
- 1.20 -> 1.21 -> 1.22 の順番に上げても EndpointSlice が追加 or 変更されないケースだと同じ問題が起きるらしいです。ノードを再作成したら EndpointSlice が変わるはずなので、ノードを作り直さずに kublet/kube-proxy とかを再起動してるだけとかなのかな (comment - k/k#110208)
- kubectl で複数のリソースを特定のフィールドで降順ソートしたい時は JSONPath で再帰的に指定しないとダメって話なんですが、そもそも
--sort-byが便利 (comment - k/k#104318) - CRD のフィールド毎に feature gate を設定できるようにする KEP です。複雑化するとかリリース毎に CRD のマニフェストを分けて提供するだけで良いじゃんとか否定的なのでそのままは入らなそうです。非推奨になったフィールドを使ってる場合に warning ログを吐く仕組みは有用って意見が多いのでそこに特化するかも (KEP 3340)
- EndpointSlices を手動で作ると ingress-gce (GCP HLB 用の Ingress controller) を異常終了させることができたようです。基本 EndpointSlices は Service 経由で作られるので、Service のラベルが EndpointSlices に付いてます。それ前提でフィルター掛けてたからみたい (kubernetes/ingress-gce#1733)
- IndexFunc でエラー返すと client-go 側の実装で panic になって異常終了するの怖すぎ。何でそうなってるのかは注意書きもないので分からないですね
- 1 ヶ月後に GKE のリリースノートに記載された (release notes)
- いまいち何基準で既知の問題を GKE リリースノートに載せるか載せないか判断しているのか分からないですね…。問い合わせの数ベースなのかな
- イメージタグと digest を一緒に指定した場合に、イメージタグが別の digest に紐づいていてもエラーにならずに digest が優先されてプルされるのを改善する PR だそうです (containerd/containerd#7074)
- 個人的に
-immutableとか付けたくないし微妙な感じがします。そもそもタグは変わりうるものなので、不変にしたいなら digest だけ指定したら良いような。不変なタグにしたいなら、プッシュするときの処理で既にタグがあったらプッシュしなくするとかできますし。 - OCI distribution の仕様も変えようとしていてそっちの議論が面白かったです。タグの命名規則で慣習を作るよりは現状使えないタグの指定方法使う方が良いのではとか
- 新しくできる WG でタグの慣習を形式化して、今後の拡張 (e.g. immutable tag) とかにも対応できるようにするらしい (opencontainers/tob#114)
- 個人的に
- 既存の GKE クラスターでも Dataplane v2 を有効にできるようになるかも? (GoogleCloudPlatform/netd#135)
- 既存の GKE クラスターでも Dataplane v2 を有効にするの ETA いつかって Issue が上がってた (IssueTracker)
- こんな内部情報を IssueTracker に書いちゃうのか…
-
Issue summary: The customer was previously informed that in-place dataplane upgrades to V2 is WIP and might go live during the second half of 2021.
- GKE 1.24 から preview で IPv4/IPv6 Dual-stack network の機能が来ます。Dataplane v2 が必須 (document)
- EKS は Kubernetes の Dual-stack network の機能だと IPv4 必要になるから IPv4 枯渇問題は解決できないじゃんってことで独自に CNI 側の実装で頑張ってる (comment - aws/containers-roadmap#835)
- 今まではノードプールの in-place でのローリングアップデートしか無理だったんですが、Blue/Green でノードプールノードを切り替えて更新する機能が出ました。(document)
- 何か問題が起きた時のロールバックがやりやすくなりますが、ノードを両系統 (Blue/Green) で動かす時間があるのでコストは掛かります。
- Cluster Autoscaler と併用できるようになるのが GKE 1.23 以降なのでまだ使えないです。
- Gateway API をベースにしたサービスメッシュの設計を進めるための WG が sig-network にできるみたいです (Google Docs)
- Service Mesh Interface (SMI) のメンバーで構成されてますね
- 前々から SMI と Gateway API で被ってる部分が結構あるくない?って感じだったので、共生の道を模索するみたいです。外から見てるとお互いの立ち位置も微妙な感じだったので、良い流れな気がします。
-
Gateway API は Ingress の置き換えを目指したものです。
- 僕たちが Kubernetes の世界で外部にサービスを公開しようと思うと Ingress を使うのが主流です。(L4 で良いなら Service type LoadBalancer を使う場合もあります。)
- Ingress は色々な L7 の Load Balancer サービス (e.g. Nginx, Envoy, GCP HLB, ALB, …) に対応しようとしましたが、実装がそれぞれ異なるので要件が様々でそれらを満たす API 設計になっていなかったですし、拡張性もありませんでした。そのため、それぞれの実装者が annotation を使って独自に機能を実装するようになり混沌としました。例えば、Nginx の Ingress の実装だと annotation の数がこれだけあります。 (document)
- annotation だと表現力やバリデーションが弱いのと Ingress は全部入りでモノリシックなのでクラスタ管理者・インフラ・開発者など役割が分かれているような組織で同じリソースを管理する必要があり、責務を分離できませんでした。
- Gateway API はマイクロサービスの考え方と同じで、役割毎にリソースを分離しました。そのおかげで、組織のそれぞれの担当者が自分たちで管理しているリソースに変更を気軽に加えられるようになりました。
- GatewayClass
- Gateway
- HTTPRoute
- (….)
- また、今の Ingress には同じ namespace にある Service にしかリクエストを流せないという制限があるのですが、その制限もなくなり namespace を横断して Service を紐付けられるようになります。マイクロサービス構成にしているところでは namespace 毎に組織を分離しているパターンが多いので、共有の Gateway に複数の組織の HTTPRoute を紐付けたりができるようになります。
- Ingress は機能的に弱くてホスト名やパスベースのルーティングくらいしかできませんでしたが、Gateway APIs は機能が豊富です。
- トラフィック分割
- ヘッダー書き換え
- リダイレクト
- (…)
- 機能が豊富なせいで、SMI (Service Mesh Interface) と被る機能がたくさんあります。そもそも、SMI も Gateway API も有名なサービスメッシュである Istio に影響を受けている部分が大きいので似たような機能がありました。
- Gateway APIs は Ingress を作っていた人たちがそのまま Ingress v2 の意味合いで作っています。Ingress のように Kubernetes のコア機能として開発せずに CRD (カスタムリソース) として提供することで、Kubernetes のリリースサイクルに影響されずに開発のイテレーションを回していました。
- Gateway API は絶賛 beta に移行する準備中で、GatewayClass / Gateway / HTTPRoute の 3 つのメインのリソースだけが v1beta1 に進みます。それ以外のリソースはまだまだ絶賛 API 設計の議論をしたりリソース名を変えたり派手に色々とやっています。それくらい共通化が難しい問題なので、議論を見ているだけで面白かったりします。(議論が白熱するので長文合戦で全然追えないですが)
- SMI は Kubernetes のコアから離れた部分で色々とやっていたので、やっぱり難しい部分があったのかもしれません。Gateway API が beta に進んで安定化する中でその上で設計できるならそれに越したことはないので、SMI の合流は自然な流れな気がします。
- Gateway APIs は Google さんも推しまくっているので、Kubernetes 関係ない部分でも API 設計がそのまま使われていたりします。Traffic Director というサービスメッシュのコントロールプレーンを提供するプロダクトで採用されています。GKE 上の Pod 以外にも VM 含めてサービスメッシュを構成できます。(document)
- Gateway API はあくまで API 設計だけなので、GKE での実装は別でやっています。まだ、オープンソースでは公開されていないので早く公開して欲しいです。(Gateway API が正式にベータになったら公開されると信じています。) (document)
- Gateway API for Service Mesh の proposal (Google Docs)
- Pod/コンテナのメトリクスがない状態で kubelet の /metrics/resource を叩くと異常終了する問題の修正です。マージも cherry-pick も早いので実害あるのかも (k/k#111141)
- どういう状況で発生するのかよく分からないですが、metrics-server が HPA のスケールの指標として叩いてるのでそれ関連っぽいです。修正投げてるのも metrics-server のメンテナーだし
- Kubernetes 関連のイメージの GCR から Artifact Registry への移行も本格的に動き始めてるようです (kubernetes/k8s.io#3976)
- etcd も大変なんだなって… (comment - kubernetes-sigs/kind#2836)
- Kubernetes 1.19 -> 1.22 に更新後に大量の Pod に対する数秒間隔のヘルスチェック (execProbe) がタイムアウトになる問題が報告されていたので様子を見ていましたが、1.21 で入った変更によるリグレッションのようです。全てのプロジェクトでもう 1.21 以上を使っているので、影響あるならもう問題になってますね。(k/k#110996)
- ヘルスチェックの実行側の負荷って意外と問題になってます。LINE の L4 / L7 LB のヘルスチェック実行環境が負荷に耐えられなくなって改善したって話も面白かったです。ヘルスチェックって間隔狭めがちなんですが、実行側も受ける側も意外とコストあるのでちゃんと考えて使わないとですね。(blog)
- EKS も GKE Dataplane v2 と同じように Pod 間通信でさよなら kube-proxy (iptables) しそうです。ネットワークポリシー (この Pod はこの Pod と通信しちゃダメみたいなルール) を Kubernetes ネイティブの機能としてサポートしたいから eBPF ベースの kube-proxy 置き換えを試してるらしいです。(comment - aws/containers-roadmap#1478)
- GKE みたいにサードパーティの CNI (Cilium) と連携させる形にはしたくないらしいので自作かな?
- EKS は AWS ENI と自作の CNI plugin の力により既に Pod 単位でセキュリティグループを設定できるんですが、EKS 独自機能なので Kubernetes の Security Policy の機能を使わせろって声が大きかったのかな… (blog)
- ENI 強力だけどそのせいで自作の道に追いやられてる感ありますね。そもそも ENI のせいでシンプルな IPAM (IP Address Management) plugin や他のリファレンス実装の CNI plugin が使えなくて Amazon VPC CNI plugin 自作してて、何で?って GKE の人に質問されてるくらいなので… (aws/amazon-vpc-cni-k8s#5)
- EKS と言えば Kubernetes 玄人向けとか GKE と違って設定をユーザー側で変えられる部分が多いって言われてましたが、Amazon VPC CNI plugin の設定もここに書かれてるやつは全部変えられますね。久しぶりに見たら自分が触ってた頃より更に増えてました。何割のユーザーが正しく理解してカスタマイズしているんだろう (document)
- GKE は設定できる部分多くはないけど大多数にとっては最適な設定ってスタンスなので真逆で面白いですね。どっちも善し悪しあります。GKE は設定変えても元の値に戻されるものが多いです。Kubernetes の reconciliation の概念に忠実です。
- CPU throttling を緩和するためのフラグのデフォルト値の単位が間違っていたらしいです。μs (us) と ms の違いに 4 年間誰も気付かなかった…! (k/k#111520)
- 未だにアルファな機能なのでデフォルトで無効にされているのと、手動で有効にしたのに値を指定しなかったっていう特殊なケースにしか影響がないのでデフォルト値を変えそうです。
- Kubernetes 界のサクラダ・ファミリアの一つである Pod の CPU / メモリリソースの割り当てを再起動なしにオンラインで変える機能が Kubernetes 1.26 以降に持ち越しになりました。ただ、今回は一部の変更がマージされて Kubernetes 外での実装が進められるようになるので大きく前進しました。(comment - k/k#102884)
- 留年しすぎた影響で cgroup v2 の機能が GA してしまい、E2E テスト用のノードもつい最近 cgroup v2 が有効なものに置き換わり、テストを通せなくなりました。当初アルファの段階で cgroup v2 対応予定じゃなかったんですが、対応しないといけなくなったので間に合わずです。かわいそう
- そもそもコンテナランタイム (containerd とか crio とか) が対応しないことにはフルで機能がテストできない状態になっていたので、コンテナランタイムが先に対応できるようにインターフェイスの変更だけマージされました。
- 今朝日本時間の 10:00 で Kubernetes 1.25 の機能追加のコードフリーズでした。例外的に期間延ばしてくれっていうリクエストを投げていましたが、拒否されたので留年確定です (message)
-
Reason this enhancement is critical for this milestone: GKE wants to land this in Q3
Risks from cutting enhancement: (partial implementation, critical customer usecase, etc.) Many use cases are blocked, criticality is unknown. - GKE が Q3 で入れたがっていたみたいですが、GKE 以外に影響ないなら影響も限定的ってことでバッサリ切り捨てられてました。
-
Plus the code pending to merge is huge and the impact is limited to GKE only. Thank you for raising the exception and hope you could understand the decision:しゅん:
- これまで Cluster Autoscaling は各 zone 毎に最小・最大の台数を指定 (e.g. 3 zone で min: 1, max: 4 なら 3 -12 台) できたんですが、GKE 1.24 から最小・最大のサイズを zone に関わらずクラスター全体の台数として設定できるようになります。(document)
- 昨日の夜に GCP の Terraform provider でこんな機能あったっけって機能を設定できるようにしようとしてたので何だろうって思ってたらこれでした (GoogleCloudPlatform/magic-modules#6370)
- GKE 1.23.5-gke.1300 から 1 node 当たりに載せられる Pod の上限が 110 -> 256 台に増えます (release notes)
- Kubernetes の大規模クラスター用の推奨だと 1 node 100 Pods です (document)
-
No more than 110 pods per node
- ただ、オンプレなんかで 1 node に 600 Pods 載せてるって猛者も出てきていたりで、そもそも 110 って制限どこから来たのって議論になることがありました。(最近もどこかの Issue か Slack のスレッドで話題に出てた気がしたけど忘れちゃいました。)(comment - k/k#23349)
- 新規に作った GKE 1.24 以降のクラスタで Service を .spec.ports 指定なしで作ると ingress-gce controller が壊れるバグ (release notes)
- 回避方法がクラスタ作り直して .spec.ports 指定した Service を作れってあるけど、ingress-gce の方に修正は入っているのでこのロールアウト待ちっぽい (kubernetes/ingress-gce#1774)
- 確かにこれだと L4 Network LoadBalancer (Regional Backend Services) の場合の修正だけか (comment - kubernetes/ingress-gce#1775)
- k8s.gcr.io から registry.k8s.io へのリダイレクトは 10/1 以降に予定していて実施の 30 日前にはまた通知があるらしいです。前回のサポートのやり取り的に GCP 内からの通信はリダイレクトしないようにするようなので特に影響ないはずですが注意ですね。

- Kubernetes 1.25 に入る予定の変更のおかげで 5000+ ノードのクラスタの負荷テストで kube-proxy のネットワークプログラミングのレイテンシが 99p で 10% 程度改善したらしいです (comment - k/k#110268)
- 今回入った変更は 1000+ endpoint (≒ Pod) を超えるともう使っていない iptables のルールをすぐに削除せず 1 分毎の強制同期のタイミングでまとめてやるようにしただけみたいです
- GKE Dataplane v2 に移行すると kube-proxy いなくなるので恩恵受けられるかは微妙なとこですね。
- 次世代の kube-proxy (kpng) もあったりするんですが、これはライブラリとして使えるようになっていて特殊な要件とかで自作したい人向けでもあるらしいから主流にはならなそうな雰囲気がしてます (kubernetes-sigs/kpng)
- 予定通り Kubernetes 1.25.0 がリリースされました
- やばいのは既出のものくらい
- v1.25.0 で削除された API バージョン (document)
-
registry.k8s.ioへの移行 (release notes) -
gcp と azure の認証 plugin を in-tree から削除 (k/k#110013)1.26 に延期 - cgroups v2 が GA していて、GKE の場合は 1.24.2-gke.300 から COS 97 以降のノードイメージで対応されているので GKE 1.24 以降で移行を始めた方が良さそう (document)
- user namespace もアルファ機能で入った
- 実行中のコンテナの状態 (メモリページなど) をスナップショットとしてディスク上に保存できる ckeckpoint の機能もアルファで入りました。crictl とか使えばリストアもできます。ノード間でスナップショットを移動させるのは自分でやらないといけないとか Pod 内の 1 コンテナが対象とか機能はまだまだ限定されています。スナップショットを OCI レジストリに保存して配布できるようにするとかも考えられています。元々はデバッグ目的の機能ですが、live migration で使えるかも (k/k#104907)
- やばいのは既出のものくらい
- Kubernetes 1.25 で musl ベースの DNS リゾルバが search path に追加されたドットにより壊れるらしいです。何かを解決しようとすると何かが壊れる世界 (k/k#112135)
- コンテナのリゾルバの設定にドットの search path を渡さないように揉み消す対応で早くもマージされました。1.25.1 のパッチリリースに間に合わせることで、Alpine ユーザーがバグ報告でなだれ込んで来る前に片付けたかったみたいです (k/k#112157)
- cgroup v1 と v2 の挙動の違いで、v1 のと時はメモリ割り当てを現在使っている使用量よりも下げようとするとエラーになっていたのが、v2 だとエラーにならずにサイレント OOMKill されるらしいです (opencontainers/runc#3509)
- v1 と同じ挙動に戻そうと runc 側で best effort でチェックして使用量よりも低い変更を弾こうとしてます (opencontainers/runc#3579)
- Kubernetes v1.25 で client-go/kubectl からクラウドプロバイダー固有の認証の実装が削除されるの 1.26 に持ち越しになりました (k/k#111911)
- in-tree の credential plugin の場合は、kubectl apply とか describe とかで大量のリソースを適用する場合に 1 つのコネクションでやってたのが、コネクション per リソースになってしまったらしい
- 昔からある問題で fix の PR はあるのでこれ 1.26 までにマージする方向です (k/k#108459)
- 1.26 で in-tree の gcp/azure credential plugin を再度削除するための revert (comment - k/k#112341)
- サービスメッシュは sidecar proxyless な流れですね (blog)
- CVE の修正で Aggregated API サーバが壊れたらしいので今日緊急でパッチリリースがあるようです。珍しい (mail)
- GKE 1.22.14 は欠番になりそうだけど、一応上げないように注意した方がよさそう
- metrics-server が正常に動かなくなるから HPA 上手く機能しなくなるかも
- Spot VM でノードが停止すると Error とか Completed で Pod が残ってしまうことがあったのこれで直りそうです (kubernetes/cloud-provider-gcp#368)
- Dataplane v2 の IP 枯渇問題の根本原因の修正がついにマージされました。Dataplane v2 は workaround で回避していた奴です (containerd/containerd#5904)
- そもそも作った順と逆順でリソースを消せていないのが問題で、IP 以外にもリークしてるのありそうなのでちゃんとしようぜの Issue です (containerd/containerd#7440)
- 10/3 から k8s.gcr.io -> registry.k8s.io のリダイレクトを徐々にやっていくらしいです (twitter)
- Service の spec.loadBalancerIP が非推奨になったので GCP も annotation に移行予定。EKS と Azure は annotation で指定できるようになってるようで、GKE だけ珍しく遅れてます (kubernetes/cloud-provider-gcp#371)
- GKE の public cluster の場合、master authorized network で IP 制限掛けても、GCP の public ip から接続できちゃってたの改善しそうです (GoogleCloudPlatform/magic-modules#6780)
全部見た訳ではないですが、今回の KubeCon NA で個人的に面白かった発表です。(ネットワーク系多め)
- Cgroupv2 Is Coming Soon To a Cluster Near You - David Porter, Google & Mrunal Patel, RedHat (youtube)
- GKE/sig-node な人と Red Hat/CRI な人の発表なので濃い
- Memory QoS はワークロードによって使い分け難しいので紆余曲折しそう
- PSI メトリクス楽しみ (opencontainers/runc#3358)
- SIGs Aren’t Silos: A Case Study Into Solving Inter-Domain... Swetha Repakula & Antonio Ojea Garcia (youtube)
- k/k#109414 の件をどうやってみんなで協力して解決したかの推しの発表
- リファクタリングの後は危険なのとテストが大事ってことが改めて分かる
- SIG-Network: Intro & Deep-Dive - Rob Scott & Bowei Du, Google; Surya Seetharaman & Andrew Stoycos (youtube)
- ネットワーク周りの現状と今後の良いまとめ
- Admin Network Policy (ANP) の補助ツールを作る気あるみたいで期待
- Lightning Talk: Paying Down Debt: Converting Kubernetes To Use Go “Workspaces” - Tim Hockin, Google (youtube)
- Go の Workspace 機能は Kubernetes の依存ライブラリ問題助けてって Go 開発チームに泣きついたら作ってくれた機能らしい
- Lightning Talk: Where Did All My IPs Go? - Cynthia Thomas, Google (youtube)
- IPv6 移行をスムーズに行うためにどういうことやってるかの話
- How To Handle Node Shutdown In Kubernetes - Xing Yang & Ashutosh Kumar, VMware (youtube)
- Graceful Node Shutdown (sig-node) と Non-graceful Node Shutdown (sig-storage) の話
- そもそも Non-graceful Node Shutdown が必要かの背景が分かりやすい
- How Adobe Planned For Scale With Argo CD, Cluster API, And VCluster - Joseph Sandoval & Dan Garfield (youtube)
- VCluster でマルチテナント安全にやる話
- Argo CD のパフォーマンスの話とかも出てくる
- Run As “Root”, Not Root: User Namespaces In K8s- Marga Manterola, Isovalent & Rodrigo Campos Catelin (youtube)
- 1.25 で alpha 機能として入ったまだまだ未完成な User Namespace の解説
- デモもあるし KEP 読むより分かりやすい
- Keynote: AWS :ハート: K8s - Nathan Taber, Head of Product for Kubernetes, AWS (youtube)
- AWS が Kubernetes の周辺エコシステムに貢献してます!と必死にアピールしていて面白かった
- Kubernetes コアへの貢献で紹介されている K8s クライアントの gzip 最適化(k/k#112299)
- 大きさじゃないのは分かってるけど、各ベンダーが KEP 作って協力して機能を実装している中で存在感がやっぱりないのが AWS
- GKE 関連のリポジトリに現れていたので薄々勘付いていたんですが、推しのアントニオさんが Red Hat から Google に移動確定したのが一番の驚きでした。GKE の IPv6 周りの移行が早まる気がします。
- Argo (Argo Workflows, Argo CD, …) が CNCF の Graduated プロジェクトに昇格しました。(blog)
- コミュニティとして成熟して安定していると認められた形です。
- Argo CD でいうと競合の Flux が 11/30 に Graduated になってて仲良く一緒にって感じかな