Kubernetes - 2023
- sidecar container の起動停止順に関する本命の KEP 来ました。initContainer にフィールドを追加して起動しっぱなしにできるだけで、変更は最小限に (KEP 3761)
- Pod の TCP/HTTP probe でソケット解放できずに conntrack table を占有する話 (k/k#115143, video, blog)
- Pod 内の loopback interface の必要性 (containerd/containerd#8006)
- KEP 3759 の流れで initContainer と Container で type を共有するの辞めたい話(k/k#115362)
- Kubernetes の開発に関わりたいならアントニオさんに余計な負荷 (メンタリング) を掛けずに壊れたテストを修正できる人になるのが良さそう (comment - kubernetes/enhancements#3788)
- 大規模クラスタでパフォーマンスが改善したと話題の iptables のリストア周りの最適化が 1.27 で β に昇格してデフォルト有効化 (k/k#115138)
- EKS もGKE の Deprecation insight に似た機能を追加しようとしてる (aws/containers-roadmap#1946)
- kubelet の並列イメージプルの制限が containerd の API の QPS しか考慮してない問題 (k/k#112044)
- k8s.gcr.io でのイメージの公開が 2023/4/1 から停止される KEP がマージ、まだ移行してない人は registry.k8s.io に移行が必要 (kubernetes/enhancent#3723, blog)
- kubectl get/describe でタイムゾーンが異なる理由 (comment - k/k#102316)
- kubelet やコンテナランタイムのログを kubectl で見たい要望が EKS / AKS からあるのが不思議。GKE だと Fluent Bit がデフォで転送するから不要?(comment - k/k#96120)
- リージョンを跨いだコントロールプレーンと etcd の立地の近い 2 リージョンクラスタ化の事例 (comment - k/k#3765)
- Kubernetes コミュニティのイメージを registry.k8s.io 経由で ECR からも提供するために rclone で GCS -> S3 に同期してるらしい (kubernetes/enhancement#3723)
- OCI 準拠で GAR -> ECR に同期できるツールを作るまでは GCR 消せない
- Job などから Pod を生成する際に、リソース名の一部をサーバー側でランダム生成させると同名で衝突してしまうことがある (k/k#115489)
- クラウドプロバイダー毎の Service type LoadBalancer のヘルスチェックの違いとそれぞれに欠点がある話 (comment - KEP 3458)
- 最新の iptables の改善により大規模環境で eBPF 実装より高速化している?(comment - kubernetes/enhancement#3824)
- seccomp をデフォルト有効化する議論の中で、ワークロードのパフォーマンス悪化の可能性が問題に (comment - KEP-2413)
- kernel 5.16 でデフォルトの挙動が変わっているが、パッチが入っていないと Spectre の脆弱性回避でパフォーマンスが 1.5 倍程度悪化する可能性がある (comment - KEP-2413)
- Go で特定の network namespace 内で HTTP リクエストを送る方法 (blog)
- Kubernetes の flaky テストの調査方法 (gist)
- EKS クラスタ内の証明書管理のコントローラー (eks-certificate-controller) を OSS 化予定 (comment- aws/container-roadmap#1947)
- 昔は NodePort のポート番号でソケットを開くことでユーザーの誤用を避けていた (k/k#108496)
- 削除されたノードの情報を使って処理を追加したい場合は、ノードに finalizer 付けられず informer キャッシュが使えないので、workqueue を別に用意してあげれば良い (slack, k/k#115529)
- リソースのフィールドの指定が必須で無い場合の選択肢 (comment - k/k#115553)
- ノード上のカーネルパラメータの調整など oneshot な処理を DaemonSet + affinity + ラベル操作で実現すると思わぬ副作用をもたらすことがある (comment - k/k#64623)
- EKS の人が顧客に頼まれて Argo CD の負荷の指標を知るためのベンチマークを作りたいって話 (slack)
- nimakaviani は以前 Knative にも関わっていて、AWS に移って Spinnaker とか CI/CD 周りを見てたはずだけど Argo CD を見るようになったっぽい? (blog)
- Web 上でコンテナイメージのマニフェストを調べるツール (site)
- Cloud Run 上で crane のコマンド実行して結果を表示しているだけ
- KEP-127 user namespace で使われようとしている idmapped mounts の話 (video, kubernetes/enhancements#3811)
- Karpenter はノードに finalizer 付けてるからノードを消すと VM が消えることが保証されている (comment - kk#115139)
- 起動時にノードに taints を付与する機能もあって、Pod がスケジュールされる前に事前処理が必要なケース (e.g. Cilium のネットワーク周りのセットアップ) に対応できるようにしている (aws/karpenter#1727)
- 作成してすぐにオブジェクトを消した場合にエッジケース (e.g. watch し直し) で DELETE のイベントを検知できないことがある (k/k#115620)
- CREATE の処理が終わっていないオブジェクトは informer のキャッシュに含められない (comment - k/k#115658)
- 存在しない ConfigMap/Secret をマウントした Pod を削除すると消すのに時間が掛かるバグ (k/k#115459)
- Pod の probe 失敗のログにレスポンスボディを含められない (comment - k/k#99425, k/k#115670)
- Pod の probe が NetworkPolicy をバイパスできるため、同一ノード上の別の namespace の Pod に対してリクエストを投げられてしまう
- Go 1.20 に上げて Kubernetes の ARM ビルドが失敗する問題の調査 (slack, golang/go#58425)
-
CRIU でメモリマップを含めたコンテナの状態のチェックポイント (スナップショット) を取得してリストアする機能を containerd に入れたい話 (comment - containerd/containerd#6965, KEP - 2008)
- Podman <-> CRI-O の相互運用は可能だけど、containerd の独自フォーマットがコンテナイメージ内に含まれているらしく containerd 以外でリストアできないらしい
- opencontainers/image-spec#962 で CRIU のチェックポイント用の OCI イメージの仕様の議論を進めているが、結論が出ていない
- OCI で仕様化されていない実装を containerd に入れたくないけど、Podman / CRI-O / containerd で実装すれば仕様の議論が進めやすいのはあるので悩みどころ
- Kubernetes コミュニティが所有する GCR / Artifact Registry から S3 にイメージをコピーするための rclone の置き換えツール (kubernetes/registry.k8s.io#151)
-
KEP- 2008 の FOSDEM 2023 での発表 (video)
- CRIU 自体は本番利用が既にあって、Google の Borg だと優先度の低いジョブ (e.g. Youtube の録画) を他のノードに移動させている
- CRIU は ptrace で対象のプロセスを捕まえてパラサイトコードと呼ばれるものに置き換えてメモリページをダンプして終わったらパラサイトコードを消す (site)
- GPU とか外部のハードウェアにある状態まではチェックポイントに含められないのが欠点だが、CRIU 対応した GPGCPU の plugin が提供されてたりする
- 理論的には ESTABLISHED な TCP コネクションも復元できなくはないけど、5-tuple が同じ必要があったり、マイグレーション中にコネクションがタイムアウトして切れるだろうし、需要があるかは微妙な感じらしい
- kubectl に統合するときは kubectl checkpoint/migration も良いけど、kubectl drain に組み込んだらどうか
- iptables の設定変更の反映時間 (a.k.a. network latency) が減った (k/k#114181) ことで、recync の間隔を狭めた (k/k#114229) ら逆にノード全体の CPU 使用率が上がって他のワークロードに影響が出ちゃったケース (k/k#115720)
- resync の間隔は Service、ノード、Endpoint、iptables のルールの数から動的に計算できた方が良いってのはきっとそう
- Kubernetes のノードイメージ内に必要なコンテナイメージを事前キャッシュする場合は、
ctr image pullじゃなくてctr image fetchで unpack しない方がディスク容量を圧迫せずに済む (awslabs/amazon-eks-ami#1144)- ノードがディスク容量 85% を超えた状態で起動するので、Kublet のイメージ GC が発動して未使用のイメージの削除処理が走り、ノードの状態が Ready になるのが遅れる (comment - awslabs/amazon-eks-ami#1142)
- Unhealthy なノードがある場合に、
NoExecuteの taint を付ける controller と処理する controller を分けたいらしい (k/k#115779)- scheduler みたいに taint を処理するカスタム controller を挟み込めるようにしたいらしい
- Apple でこれまでは taint manager を無効化して自作の eviction 処理をするコントローラーを入れていたっぽいけど、Kubernetes 1.27 から taint manager を無効化できなくなる (無効化するフラグがなくなる) ので困っている
- CRI に準拠したランタイムは、
--grace-periodの値を変更して連続で反映しても最初に反映したときの値が優先される (comment - k/k#113717) - Seccomp が GA するけど、デフォルトで有効化すると、1.27 にアップグレードした後で起動できない Pod が出てきそうだから、デフォルト無効に戻す話 (k/k#115719)
- ECS のタスクが ELB から外れてから停止処理に入るようになった (blog)
- リファレンス実装だからって konnectivity の名前をリポジトリに含めずに細々やるよりは、含めて SEO 対策した方が困惑しないって話 (kubernetes-sigs/apiserver-network-proxy#461)
- Checkpoint で生成されたイメージはベースイメージ以外の差分で、リストアする時にノード上にベースイメージが存在しなければダウンロード必要。それをスマートにやる方法はない (comment - kubernetes/enhancements#2008)
- gRPC probe を使う場合は、liveness/readiness で指定する
serviceを変えるかポート番号を変える想定 (comment - k/k#115651, video) - static Pod と通常の Pod の見落としやすい違いは UID を再利用できるかどうか (comment - k/k#113145)
- NEG コントローラーが Pod の
deletionTimestsampしか考慮しておらず、フェーズの確認が漏れているので NotReady な Pod が含まれてしまう可能性がある? (kubernetes/ingress-gce#1957) - Pod の eviction で
terminationGracePeriodSecondsが守られてしまっているバグ? (k/k#115819)-
terminationGracePeriodSecondsを 0 に上書きする処理の中でバグがあり、SIGKILL が送られるずterminationGracePeriodSeconds経ってから終了してしまう
-
- preStop hook に問題がある場合に
terminationGracePeriodSeconds* 2 秒後にしか Pod が SIGKILL されない問題 (k/k#115817, k/k#115835)- SIGTERM が飛ばない影響で、preStop hook の実行時間が SIGKILL までの時間として考慮されておらず、
terminationGracePeriodSecondsを超えてから更にterminationGracePeriodSeconds秒待ってから Pod が SIGKILL されている
- SIGTERM が飛ばない影響で、preStop hook の実行時間が SIGKILL までの時間として考慮されておらず、
- proxy-mode=ipvs の諸悪の根源は仮想インターフェイスに VIP 割り振らないといけないこと (comment - kubernetes/enhancements#3824)
- ノード名を直接指定すると最悪起動に失敗した Pod が再起動を繰り返すので非推奨 (kubernetes/website#39452)
- デバッグ目的でスケジュールさせることはあるけど、通常のワークロードで使うケースは稀なはず
-
nodeNameのように意図した使われ方をしていないフィールドが残っている背景 (comment - k/k#113907)
-
kong/blixt
- Gateway API の eBPF ベースの L4 リファレンス実装 (kubernetes-sigs/gateway-api#1706)
- Fargate で BPF CO-RE サポート予定らしい (aws/containers-roadmap#1027)
- GKE の Ingress の問題を診断するための CLI ツール作ろうとしている (kubernetes/ingress-gce#1960)
- AWS の Gateway controller の実装は AWS Lattice ベースで gRPC route サポート予定 (slack)
- Kind 上で動かしてクラウドプロバイダの挙動をチェック可能なダミーの controller 実装 (aojea/cloud-provider-kind)
- kubernetes/cloud-provider で定義したインターフェイスを実装
- HAProxy ベースの LB 実装付き (source)
- Kind への取り込み (kubernetes-sigs/kind#3103)
- 何らかの問題で kube-apiserver が再起動して全断しても、クラスタ内から kube-apiserver と通信するための Service から kube-apiserver の IP が削除されない問題 (k/k#115804)
- クラスタ内のクライアントから kube-apiserver に接続して失敗したときのエラーが分かりづらい
- 一時的な再起動で初期化中など不完全な状態でクライアントから接続してしまう可能性がある
2023/2/23
- GKE 1.22 + Preemptible node の組み合わせで evict 周りでまだバグってるらしい (comment - kubernetes/ingress-gce#1963)
- GKE の Service LB で複数のプロトコルを喋る KEP- 1435 をサポートしていないので注意 (kubernetes/cloud-provider-gcp#475)
- 今も出来るか分からないけど、IP 予約しておいて 2 つ Service を作ると良いらしい (comment - k/k#23880)
- 永続コネクションの場合、Service の名前解決を DNS ラウンドロビン + シャッフルしても、バックエンドのローリングアップデート後にコネクションが偏る (comment - k/k#37932)
- 永続コネクションはちゃんと idle タイムアウト時間を調整して、定期的に再接続し直す必要がある
- 重複した Pod IP を EndpointSlice controller で公開するか (k/k#115907, slack)
- Pod が正常もしくは異常終了 (
CompletedorError) して再起動した場合に、Pod IP が再利用されることはある - 同一 IP の Endpoint の重複を許容するか
Readyな Endpoint だけを公開するようにするか議論中
- Pod が正常もしくは異常終了 (
- annotation は Event API の一部ではないため、同一の Event で annotation の値を変えても最初の値が返ってくるはず (comment - k/k#115963)
- KEP-3488 CEL for Admission Control で複数の validation を定義した場合に最初に失敗した validation のエラーしか返ってこないのは仕様 (comment - k/k#115920)
- 外部サービスの正常性を readinessProbe に含めたときにカスケード障害で全ての Pod がサービスアウトしてしまうのを防ぐ方法がないかの議論 (k/k#115917)
-
aws/zone-aware-controllers-for-k8s
- PDB で同一ゾーンの Pod 障害は許容する Admission Webhook
-
jetstack/knet-stress
- クラスタ内の各種通信をチェックするためのツール (slack)
2023/2/24
- ノード上で動作している Pod 一覧を kubelet から直接知るには kubelet が公開している readonly ポートから
/podsを叩けば良い (slack) - DaemonSet 内で informer の LIST 呼び出しすると etcd 内のオブジェクト数 * 呼び出し数 (= ノードの数) で負荷が掛かるので注意。How should we code client applications to improve scalability? を読むこと (comment - kubernetes/enhancements#3157)
2023/2/25
- k/k の
tests/e2e/frameworkを staging に外出しする予定は今のところない (slack)- kubernetes-sigs/e2e-framework は外出ししたことでパッチが定期的に来ていて羨ましそう
-
tests/e2e/frameworkの方が使い易かったので外出ししてくれると嬉しい
2023/2/26
- コンテナのログファイルをローテーションする処理を並列化する PR を AWS の人が早くマージしたがっている (k/k#114301)
2023/2/27
- aws/amazon-eks-pod-identity-webhook
- ResourceQuota が Pod の resource request/limits じゃなくて実際の使用量で制限をかけたい要望 (k/k#116063)
- ノード毎に使用量を API サーバに高頻度に報告してたらスケールしないよね
2023/2/28
- GKE で Cilium + WireGuard でノード間通信を暗号化できるようにしようとしている? (GoogleCloudPlatform/netd#199, GoogleCloudPlatform/netd#202)
- WireGuard によるノード間通信の制約は 1 つを除いて解消されている (cilium/cilium#15462)
- NEG の Pod IP の管理を EndpointSlice のみで行う変更の中に、kubernetes/ingress-gce#1957 を打ち消す commit が含まれている (kubernetes/ingress-gce#1973)
-
kubernetes/ingress-gce#1957 の処理があったのは、Endpoints が Terminating の情報を公開しておらず、EndpointsDataFromEndpoints で Terminating な Endpoint を綺麗に排除できていなかったから
- EndpointsDataFromEndpointSlices では、Endpoint Condition の Ready/Terminating でフィルターを掛けている
- Endpoints の処理を完全に削除できたから分岐も消せるようになっただけで間違っていない
-
kubernetes/ingress-gce#1957 の処理があったのは、Endpoints が Terminating の情報を公開しておらず、EndpointsDataFromEndpoints で Terminating な Endpoint を綺麗に排除できていなかったから
-
KEP 1287 - In-place Update of Pod Resources の最初の実装がついにマージされた (k/k#102884)
- alpha の段階でやることがまだある(comment - k/k#102884
- VPA との連携は beta の段階 (KEP, kubernetes/autoscaler#4016)
- ECR でプッシュ時にリポジトリが作成できないのは、ECR のリポジトリのセキュリティに関する設定 (e.g. アクセス制御、不変なタグ) がデフォルトで none だからユースケースに合ったリポジトリが作られないかららしい (comment - aws/containers-roadmap#853)
- aws/containers-roadmap#799 にあるようにリポジトリのプロファイルを作れるようにしてデフォルト値を埋める形にする予定
- 何回目かのヘルスチェックに外部サービスの正常性を含めるな (comment - k/k#115917)
- マイナーバージョン更新時に Pod が動いている状態で kubelet を in-place 更新すると、ディスクの互換性の観点から static Pods 用のマニフェストは消える (comment - k/k#116080)
- ノードがパブリック IP を持っている場合、kubelet が公開している 10250 番ポートで外部から叩ける可能性がある (k/k#115896)
- 基本認証認可があるから大丈夫だけど、kubelet をコマンドラインフラグで起動するか、設定ファイルで起動するかでデフォルト値が変わるから間違えやすい
2023/3/1
- iptables と ipvs の conntrack table 処理のまとめ (k/k#116104)
- でっかい KEP の実装の進め方 by Tim Hockin (comment - k/k#115934)
- Deployment の replicas を手動で変えても
rollingUpdate.maxSurgeとrollingUpdate.maxUnavailableを考慮しながら徐々に Pod の数を変えたいらしい (k/k#116132)- ローリングアップデートの際は考慮されるのに replicas を手動で変えた場合は、一気に台数が増減したりするの変えるオプションを追加したいって話だけど、そんなに Deployment の replicas を直接変えることある?
- Deployment の replicas を直接いじってるってことは HPA 使ってなさそう
- HPA の minReplicas/maxReplicas の変更時の挙動は behavior で制御できるので、それ使えば良いのにユースケースがよく分からない
-
SOCI と Fargate を連携させてコンテナイメージのプル時間を短縮しようとしているらしい (comment - aws/containers-roadmap#696)
- SOCI は stargz-snapshotter からコードを拝借改良して、stargz/eStargz に変換しなくても使えるようにした感じかな
- OCI の Reference Types を使って実現したらしい
- CPU 割り当てを
1.2と書いて kubectl apply すると毎回変更された扱いになる (k/k#116135)-
1.2とか1200mとか色々指定できるのが根本原因で、サーバー側で正規化されて最終的に etcd に保存された値が apply する値と違うから起きる問題。少なくとも現状はどうしようもない (comment - k/k#116135)
-
2023/3/2
- kubelet がコンテナイメージを並列プルする際に、レート制限を掛ける機能がマージされた (k/k#115220)
- kubelet はデフォルトで直列にイメージを落とすので、重いイメージがあるとブロックされる
- 並列プルに変更するオプションはあったが、並列プルするイメージの数を制限できなかったので、帯域やノードの CPU リソースの消費が激しくて安定しなかった
- FeatureGate もないので、GKE 1.27 以降で並列プルに置き換わったりするかも
- kubectl delete にインタラクティブモードを追加する機能は KEP が必要ということで 1.28 以降に (comment - k/k#114530)
- kubectl にインタラクティブモードが入るの初めてだし、過去に色々議論あったから KEP に整理してからやろうってことらしい
- KEP 3895 - kubectl delete: Add interactive(-i) flag
- Service の責務が重く (セレクタだけじゃなく、ポートマッピングの機能もある) 今更簡単に変更もできないので、PodSelector 的なリソースを新しく作って Gateway API や Issue の要件などなどに対応できるようにすれば良くない議論 (k/k#56440)
- こういうの実装できたらカッコ良いけど、ステークホルダー大量にいる案件なので素人には手が出せません
- 1.26 で StatefulSet の
volumeClaimTemplatesに非推奨となった StorageClass の annotation を設定すると無視される問題を修正 (k/k#116089)- 非推奨でも無視されるのは間違ってるけど、流石にもうこの annotation 使ってる人いなさそうなのと、1.26 行く頃には cherry-pick 済みのバージョンになってそう
2023/3/4
- コミュニティのコンテナイメージがまだ
k8s.gcr.ioからプルされまくっていて GCP のバジェット使い切りそうだから、どうにかユーザーをregistry.k8s.ioのコンテナイメージに移行させられないかの悪巧みスレッド (slack)- CVE スキャンの開発者に協力して貰って重大なセキュリティバグがあるって表示して貰って移行させる案が優勝 😈
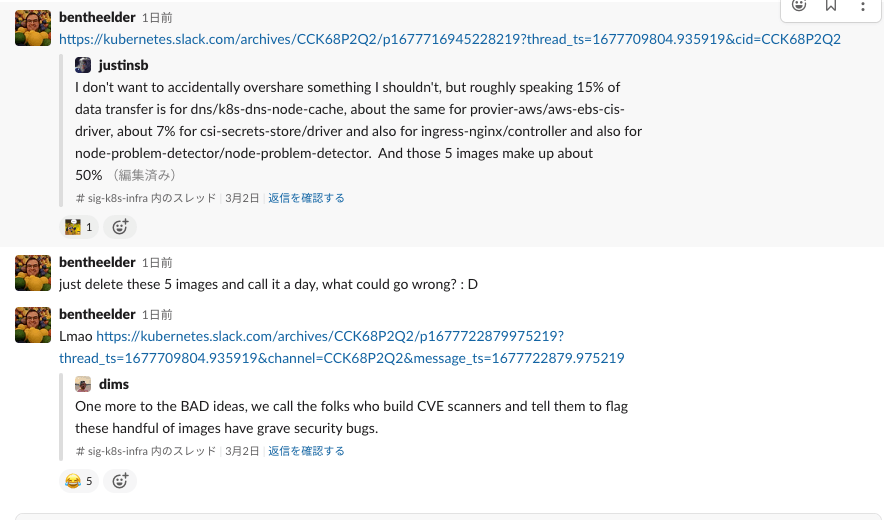
- CVE スキャンの開発者に協力して貰って重大なセキュリティバグがあるって表示して貰って移行させる案が優勝 😈
- 結局、去年 Google から追加でお金貰ってた (slack)
- レイオフを見ても分かる通り、Google のお財布の引き締めがきついので、今年は援助期待できない
- けど、Kubernetes プロジェクトが去年よりインフラコストが高くなっててやばいから、BigQuery のコストを見直したり、負荷テストなどの実行頻度を見直さないといけなくなっている。で、やりたくないけど k8s.gcr.io -> registry.k8s.io へのリダイレクトも検討している。
- 2:20-11:33 まで cloud-provider-kind のデモ (youtube)
- E2E テストで GCLB を作ってテスト実行するの時間が掛かるので、Kind 上で HAProxy を使ったクラウドプロバイダーのダミー実装で時間を減らす作戦
- 1 つの GCP アカウントで複数のテスト実行しているからか、CI で LB ができるの待つのに 45 分掛かるらしいけど、それが数十秒で立ち上がるようになる
- kubernetes-sigs/cloud-provider-kind
- EKS も containerd のミラー設定で k8s.gcr.io -> registry.k8s.io にリダイレクト予定 (awslabs/amazon-eks-ami#1211)
- k8s.gcr.io の古いイメージが削除される可能性がある (議論中) ので、コンテナイメージが急に落とせなくなったりしないための措置
- ユーザー影響ある可能性あるので事前にユーザーに知らせて話し合う予定
- Kubernetes はリソース毎に etcd のコネクションを使い回していて、TLS 有効の場合のみ大量のリソース (e.g. 10k+ Pods) を複数のコントローラーが同時に LIST すると詰まって世界が止まる問題 (etcd-io/etcd#15402, comment - k/k#114458)
- 根本原因は Go の http2 の PriorityWriteScheduler の実装の問題らしい (golang/go#58804)
- runc である CVE を修正したら以前直した CVE がまた再発しちゃって、それがまた新しい CVE として登録された (opencontainers/runc#3751, link)
2023/3/5
- wasi-http が本格的に動き出してた (WebAssembly/wasi-http#3)
- Kubernetes の生みの親の一人である Brendan Burns (現 Microsoft で Azure の CVP) がランタイム側の対応やってて本気でコンテナを置き換えようとしてる感がある (bytecodealliance/wasmtime#5929)
- Brendan Burns は想像力豊かな天才で 2 日一緒にいると 10 個の世界を変えるアイデアが降ってくるって他の Kubernetes 共同創始者からも言われている人なので、何か起こりそうな感じがする (youtube)
2023/3/6
- user namespaces が idmapped mounts による実装に変わり、CRI を拡張中。これまで、kubelet がやってたことを kernel がやることになった。問題は user namespaces が stateful Pods (ConfigMap / Secret / PV...) をサポートしたときで、既存の Pod が再スケジュールされるまでファイルの所有者が変わって読めなくなるかも (containerd/containerd#8209)
- GKE には standalone モード (kube-apiserver に登録されていない) の kubelet を使ったテストがある (comment - k/k#116271)
2023/3/7
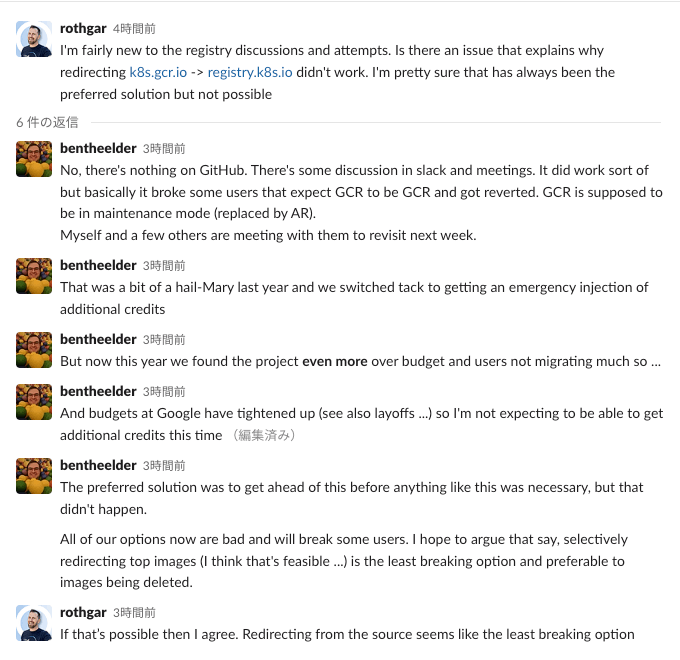
- このままだと今年のどこかで GCP から貰っている予算を使い切って Kubernetes の開発が止まる (CI 動かせなくなる) 可能性があるので、Google / AWS / RedHat / Microsoft / CNCF の人たちで作戦会議スレッド (slack)

-
k8s.gcr.ioからregistry.k8s.ioにリダイレクトできないのは、古いバージョンを使い続けている (放置している) ユーザーの環境を壊したくないからと、去年は緊急で $700k 追加で予算を貰えたからリダイレクトの検証を止めた (registry.k8s.ioに移したのに思ったよりコスト減らなかった) - GCR チームがリダイレクトの処理を入れたくないのは、
k8s.gcr.ioに問題が起きると顧客から問い合わせが来るから - 完全に
k8s.gcr.ioのイメージを消さずに一部のよく使われているけど、クラスタの運用に致命的ではないイメージを消すかリダイレクトするかのどちらかで、3/7 辺りに再度リダイレクトに関しては GCR チームと話し合う予定

- リダイレクトするにしても期間で ON/OFF を繰り返すやり方が良さそう案

- 今後オンプレとかで自前運用しているならこれを胸に刻んだ方が良さそう

-
opencontainers/image-spec、opencontainers/distribution-spec の策定や google/go-containerregistry のメンテナでも有名な jonjohnsonjr が Google を辞めて Chainguard に連れて行かれたせいで、ご立腹。本当に最近辞めてた。(twitter)

-
2023/3/8
- APF によりリクエストの優先順位に従ってサーバー側で安定して処理できるようになったので、クライアント側でのレート制限を緩和する PR がマージ (k/k#116121)
2023/3/9
- GCR のチームと相談して、
k8s.gcr.ioからregistry.k8s.ioにリダイレクトすることになった (slack)

- リダイレクトする場合、ネットワークの設定によってはコンテナイメージをプルできなくなるので、リダイレクトされる前に自分たちのタイミングで移行しておいた方が良い

-
k8s.gcr.ioのイメージを使っているかは公式ブログに記載されたコマンドか、AWS の人が開発した kubectl plugin を使用する - Gatekeeper や Kyverno を使っていて、ユーザーが
registry.k8s.ioのイメージを使えなくしたいなら、これもまた AWS の人たちが作ったポリシーがある (source)
- リダイレクトする場合、ネットワークの設定によってはコンテナイメージをプルできなくなるので、リダイレクトされる前に自分たちのタイミングで移行しておいた方が良い
-
k8s.gcr.ioのトラフィックは平均で 2,500 RPS (150,000 RPM) (slack)

- Bottelerocket は 1.13.0 (EKS 1.26) から cgroup v2 に移行(bottlerocket-os/bottlerocket#2874)
2023/3/11
- 3/20 (月) に k8s.gcr.io -> registry.k8s.io のリダイレクトを開始 (blog)
- 別ブランチで作業中だった sidecar containers の実装が準備できて API レビュー中 (k/k#116429)
2023/3/12
- preStop hook 内でサービスアカウントトークンを使用した処理を行っている場合に、
terminationGracePeriodSecondsとサービスアカウントトークンの有効期限の設定によっては、トークンの有効期限が切れて preStop hook がエラー終了する問題(comment - k/k#116481)- Pod が Terminating 状態に入ると Volume の更新が止まっているっぽく、サービスアカウントがローテーションされた後の変更が反映されていないっぽい
- Pod などで使用する自動生成されたランダム文字列は 5 文字であることを保証していないが、依存した実装がいくつかある (comment - k/k#116430)
- ランダム文字列が衝突している可能性があり、ランダム文字列を 10 文字に増やして衝突しにくくしようとした時に発覚した問題
- containerd v1.7.0 がリリース (containerd/containerd#v1.7.0)
- v2.0.0 に向けて実験的な機能がいくつか入った
2023/3/13
- KubeCon 2023 Europe で Playstation がワールド共有型のマルチプレイに Agones (Kubernetes 上でリアルタイム通信用の Dedicated Game Server を立てるための Google と Ubisoft で最初共同開発したオープンソースのツール) を使ってる話をする (link)
- 最近別のイベントで発表していたようです。マルチリージョンの話が出てくるのと、OpenMatch (Google と Unity で始めたプロジェクトでコロプラでも問題児だった子) は使っていなさそうなのと、Kubernetes の更新は新規クラスタを作って DNS 切り替えしてユーザーがいなくなるのを待つ戦略なのと、AWS を使っているみたい (youtube)
- KubeCon Europe 2023 で個人的に気になるセッション
-
Improving the Reliability of Kubernetes Load Balancers - Swetha Repakula, Google & Alexander Constantinescu, Confluent
- 1.27 で改善が入っている Service type LoadBalancer のヘルスチェック周りの改善の話
-
1M Lines of YAML: Wrangling Kubernetes Configuration for Hundreds of Teams - Katrina Verey, Shopify
- Shopify の事例で YAML の管理を Kubernete Resource Model に基づいてモジュラーシステムにしたら開発者にシンプルでスケールする仕組みができた話
-
Breakpoints in Your Pod: Interactively Debugging Kubernetes Applications - Daniel Lipovetsky, D2IQ
- エフェメラルコンテナの機能を使ってデバッグシンボルのないバイナリなどを調査する方法
-
Availability and Storage Autoscaling of Stateful Workloads on Kubernetes - Leila Abdollahi Vayghan, Shopify
- Shopify の事例で大規模な Elasticsearch クラスタを Kubernetes 上でどう運用するかの話
- データ欠損なしで PV の容量を減らしたり、クライアントから Elasticsearch クラスタへの接続に Envoy を挟んでいるらしい
-
Highly Available Routing with Multi Cluster Gateways - Rob Scott, Google & Liwen Wu, AWS
- Multi-cluster Services と Gateway API を使ってマルチクラウド間 (GKE と EKS?) でルーティングするデモをやるらしい
-
The Day We Delete(d) Production - Ricardo Rocha & Spyridon Trigazis, CERN
- 大規模クラスタでお馴染みの CERN でツールの誤作動で数分で 1/3 のクラスタを消し飛ばしたけど、サービスが不安定になっただけですぐに復旧できた話
-
Tips from the Trenches: GitOps at Adobe - Larisa Andreea Danaila & Ionut-Maxim Margelatu, Adobe
- Adobe が脱 Spinnaker して、Argo 系のツールを組み合わせて良い感じに GitOps の仕組みを作った話
-
Building a Platform Engineering Fabric with the Kube API at Autodesk - Jesse Sanford & Greg Haynes, Autodesk
- たぶん Crossplane の XRD とか Kubevela で Kubernetes のコアの API を抽象化した話
-
Disaster Recovery: Bringing Back Production from Scratch in Under 1 Hour Using KOps, ArgoCD and Velero - Andre Jay Marcelo-Tanner, Ada Support
- etcd にも繋がらないレベルでクラスタがおかしくなったので最後の切り札として 51 分でクラスタを作り直して復旧した話と学んだこと
-
Patterns in Plain Sight: How TestGrid Demystifies Noise in Test Signals - Michelle Shepardson & Sean Chase, Google
- Kubernetes のテストの可視化で使われている TestGrid をオープンソースで公開しているから良い感じに拡張して使ってねって話
-
:zap: Lightning Talk: Power-Aware Scheduling in Kubernetes - Yuan Chen, Apple Inc.
- サーバーやラックレベルで電力消費量を最適化するようにワークロードをスケジューリングできるように Scoring の機能を scheduler に入れた話
-
Improving the Reliability of Kubernetes Load Balancers - Swetha Repakula, Google & Alexander Constantinescu, Confluent
2023/3/16
- GKE 上の kubelet の並列イメージプルの機能要求が IssueTracker に上がっていた (link)
- 1.28 で kubectl だけが含まれたイメージが registry.k8s.io から提供されそう (k/k#116672, k/k#116667)
- Cilium agent が停止したときにノードに NoSchedule の taints を付け直す PR (k/k#23486)
2023/3/18
- 既存の VM、microVM、コンテナをベースとした Serverless v1 から wasm ベースの Serverless v2 時代に変えるのが Fermyon の狙い。起動時間が数百 ms から 1 ms に変わる (blog)
2023/3/20
- Kubernetes 同様に 299 ステータスコード + Warning ヘッダーでユーザーに対して非推奨情報を渡す仕組みが仕様として入った (opencontainers/distribution-spec#393)
- conntrack table の部分的な dump と修正を可能にするパッチが netfilter に入っている (comment - k/k#115299)
2023/3/22
-
sozercan/kubectl-ai
- GPT を使ってデバッグとかテスト目的で適当なマニフェストを生成する kubectl plugin
-
k8s.gcr.io->registry.k8s.ioのリダイレクト実況してたみたい-
https://kubernetes.slack.com/archives/CCK68P2Q2/p1679420278418599

- GCR のロールアウトの裏側話していて面白い
- 4 日で 50% の IP のバックエンドに設定を反映して、来週また 4 日間で残りの 50% にロールアウトする
- 最初はコストの掛かっていたイメージだけ対象
- ユーザーが文句言われるから GCP 内からの通信はリダイレクト対象から外すようにしたっぽい

- 途中で設定ミスがあったらしい。僕らは GCL/borgcfg を触る必要がなくて、YAML だけ触っていれば良いから良いねって

-
https://kubernetes.slack.com/archives/CCK68P2Q2/p1679420278418599
2023/3/23
- Docker + Wasm で WasmEdge 以外の spin (Fermyon), slight (Microsoft), wasmtime (Bytecode Aliance) のランタイムもサポート (blog)
- Wasm でサーバーレスなアプリケーションを書くためのフレームワークの Spin 1.0 がリリース (blog)
- Go, Rust 以外の言語も SDK でサポートしたのと、一通りの開発フローが安定化
- 今後数ヶ月で WASI preview 2 や WebAssembly の component model に対応して更に良い感じになっていくそう
- Cilium が動いていない時に、Cilium Operator がそのノードに Pod がスケジュールされないように taint を付け直してくれるように、次のバージョンからなりそう (cilium/cilium#23486)
- GKE + Spot インスタンスだと VM は裏側で再起動するけど、Kubernetes の node オブジェクトは再利用するらしく、Cilium が止まるとノード起動時に付けてる (Pod がスケジュールされないようにする) taint を付け直さないから問題になっていた (cilium/cilium#21594, kubernetes/cloud-provider-gcp#404)
2023/3/24
- Reddit で 3/14 (円周率の日) に 314 分 (偶然?) サービスが止まる繋がりにくくなる障害があったようでそのポストモーテム (blog)
- kubeadm で管理している Kubernetes クラスタを 1.23 -> 1.24 に上げた時に問題が起きた
- 1.20 で非推奨になっていたノードラベルが 1.24 で完全に消えて、Calico の設定のラベルセレクタで参照していて...
2023/3/25
-
k8s.gcr.io->registry.k8s.ioのリダイレクトは予定通り全リージョンの IP の 50% に反映が終わった

- 来週また 4 日間掛けて全リージョンの 50% -> 100% の IP に反映して終了予定
- Docker は Free Team Plan を辞めるのを辞めました (blog)
2023/3/28
- Argo CD v2.7 Release Candidate (blog)
2023/3/30
- EKS に Kubernetes のユニットテストの一部を移行したらパフォーマンスの問題が発生 (k/k#116990, slack)
- Go のランタイム (
GOMAXPROCS) が cgroup 内の割り当て情報を正確に取れず、ホスト上の CPU コア数が自動的に設定されてしまったのが原因 - EKS ノード (ホスト) が 16 CPU でテスト実行のコンテナが resources.limits.cpu 4 CPU (CFS quota 有効) 割り当てで、
GOMAXPROCS: 16になっていたので、明示的にGOMAXPROCS: 4を環境変数で指定 (kubernetes/test-infra#29181) - Kubernetes のメンテナも uber-go/automaxprocs があるのは知ってるが、Go ランタイム側で対応した方が無駄に依存関係を持たなくて良いという判断 (slack, golang/go#33803)
- Go のランタイム (
2023/3/31
- CronJob が短期間かつエラー終了するせいで Pod が増殖し再起動を繰り返すと、シングルクラスタ構成の場合は普通に Pod がスケジュールされなくなる危険性がある (k/k#76570)
- 短い間隔で実行するなら concurrencyPolicy か activeDeadlineSeconds は必ず設定しましょう (comment - k/k#76570)
- KubeCon EU 2023 で 1 万人のオフラインチケットが完売した話 (twitter)
- EKS に Kubernetes のユニットテストの一部を移行したら、
GOMAXPROCSの設定によりパフォーマンスの問題が発生 (k/k#116990)- EKS のノード (ホストマシン) は 16 コア CPU で、ユニットテストを実行しているコンテナの
resources.limits.cpuが 4 だった - limits を設定しているので CPU CFS Quota による制限が適用されている状態
- Go のランタイムは CPU CFS-aware ではないので、
GOMAXPROCS: 16が自動的に設定されていた - 明示的に環境変数で
GOMAXPROCS: 4を指定して解決 - 定期的にこの話を見る気がするので Go で書かれている計算量高めなサービスかつコンテナ上で動かす場合はこれ入れておく方が良さそう (uber-go/automaxprocs)
- あと、CPUつよつよのホストマシン上でいっぱいマイクロサービスを動かしている場合
- Go のランタイム側の対応はまだなので、今は明示的に環境変数を指定するか uber-go/automaxprocs を入れるかしかない (golang/go#33803)
- EKS のノード (ホストマシン) は 16 コア CPU で、ユニットテストを実行しているコンテナの
2023/4/1
- 4/20 の KubeCon 2023 Europe で Envoy のドキュメンタリーが初公開されるらしい (twitter)
- AWS の Gateway API controller for VPC Lattice が OSS として公開された (aws/aws-application-networking-k8s, blog)
- Multi-cluster Services API を使ってマルチクラスタ対応してる
- GKE Hub みたいな面倒な概念がないのは良さそう
- Gateway を default namespace に作らないといけない縛りがあるの辛そう (aws/aws-application-networking-k8s#130)
- AI/ML や HPC の世界の Deployment/Statefulaset を目指した JobSet を wg-batch が作ろうとしている (docs)
- kubernetes-sigs/jobset
- 複数の Job のテンプレートを指定可能で、リストの最初から順番に Job を実行
-
spec.completionsをreplicasみたいに使ってスケール可能 - Job に繋がる Headless Service が自動で作られる
- JobSetConfig も作って Job で共通の設定を良い感じにテンプレートエンジンをつかって埋め込める仕組みを作る
- failurePolicy とか successPolicy を指定可能
2023/4/3
- TEMPLE: Six Pillars of Observability (blog)
2023/4/4
- bash で再実装する Kubernetes v2 の KEP powered by ChatGPT (kubernetes/enhancements#3934)
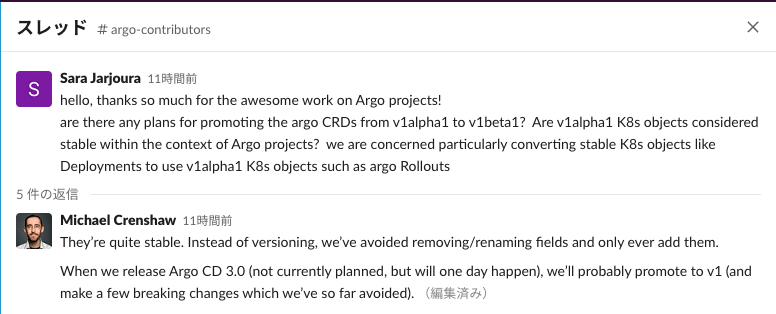
- Argo CD の CRD のバージョンは未定だけどいつか Argo CD 3.0 が来たら
v1に上げるかも (slack)-
v1alpha1の間はフィールドの追加だけで、名前を変えたり、消したりせずに互換性を保つポリシー - Argo CD 3.0 が来て
v1に上げる時は、破壊的変更を加えていろいろ整理するかも
-
2023/4/5
- HashiCorp の共同創業者の Mitchell Hashimoto の AI がプラットフォームを転換するかの洞察記事 (blog)
- fork したプロセスが OOMKill した場合にコンテナ内の全ての PID を kill するように変更しそう?(k/k#117070)
- DaemonSet コントローラーが
Succeeded状態を処理するようになっていなかったバグの対応 (k/k#117073)-
k/k#115331 で
RestartPolicy=Alwaysな Pod が Graceful Node Shutdown で終了した時にSucceeded状態になった影響でバグが顕在化
-
k/k#115331 で
2023/4/7
- initContainer でファイルに書き込んだものを main container の環境変数として自動的に読み込んでくれると source せずに済むから嬉しい (e.g. TensorFlow の TF_CONFIG) 話が意外と賛成多いから KEP になるかも (k/k#116993)
2023/4/8
- Google Cloud のサプライチェーンセキュリティの紹介動画 (twitter)
2023/4/11
- Nvidia GPU の Multi-instance GPUs (MIGs) のパーティションを Dynamic Resource Allocation で動的に生成するための Kubernetes Device Plugin (k8s-dra-driver)
- CDI (Container Device Interface) が実装された containerd じゃないと動かない (containerd/containerd#6654)
2023/4/12
- 予定通り Kubernetes 1.27 がリリース (CHANGELOG-1.27)
- Kubernetes のトラブルシューティングの流れが細かく書かれていて凄く良い (blog)
2023/4/13
- CNCF から Platform Engineering に関するホワイトペーパーが公開 (paper)
2023/4/14
- Go のサプライチェーンセキュリティへの取り組み (blog)
- Go のパッケージのドキュメントサイトに Open Source Insights のリンク貼るようにした
- Go の脆弱性情報データベースのレビューに Go のセキュリティチームが関わるようになって脆弱性診断の精度が上がった
- govulncheck を新しく作ったことで偽陽性が減った
2023/4/15
- Argo CD に Flux を組み込んで足りない機能を補った Flamingo (blog)
2023/4/16
- Kubernetes 1.20 -> 1.24 への更新でランダムで StatefulSet の Pod に接続できなくなる問題 (k/k#117193)
- PostgreSQL のコントローラーが Endpoints にパッチを当てていて、1.20 -> 1.24 に一気に更新した影響か他の原因で Endpoints <-> EndpointSlices の同期が壊れている?
2023/4/17
- Spot VM のノードが強制停止した時に Pod が Error や Completed で残ることがある問題の修正がやっと入った (release note)
- Spot VM が再作成される時に同一のノード名で起動してくる。Kubernetes の Node オブジェクトを使い回しているので、Pod GC のタイミングによっては stale な Pod が残ったままになることがある。ノードをクラスタに登録する時に残っている Pod を全部削除したれ (kubernetes/cloud-provider-gcp#368)
2023/4/18
- EKS 1.26 で Service type LoadBalancer (ELB, NLB どちらも) を eTP=Local で作成した場合に、LB のターゲットグループにノードが正しく登録されないことがある問題の修正 (k/k#117388)
- タイミングによっては、Cloud Controller Manager (KCCM) が
providerIDの設定されていないノードを cloud-provider-aws に渡すことがあって、cloud-provider-aws がproviderIDのないノードは同期しないようになってるから Service type LoadBalancer に変更があるまで同期されなくなるらしい (kubernetes/cloud-provider-aws#585) - KCCM が
prividerIDのあるノードだけを cloud-provider-aws に渡すように修正 - cloud-provider-aws の Issue だと Kubernetes 1.25.1 で報告があるけど、この変更の元になった修正が 1.25.3 で revert されているので Kubernetes 1.26 以降で発生している
- タイミングによっては、Cloud Controller Manager (KCCM) が
- Cilium Mesh - One Mesh to Connect Them All - Isovalent
2023/4/19
- 10 月に Gateway API が GA するかも (twitter)
- Kubernetes の LTS については KubeCon で議論してたみたい (docs)
- 新しいバージョンの承認に 18-24 ヶ月かかる規制業界で、今の 12 + 2 ヶ月サポートだと厳しいがきっかけらしく、2 年 (可能なら 3 年) の LTS を目指すらしい
- やっぱり問題になるのは LTS -> LTS の更新経路をどうするか。一気に更新できるようにするには開発者が互換性壊れないようにもっと気をつけたり、労力が凄い掛かる
- Azure が LTS サポートを発表して一人ではやりたくないみたいだから、WG-LTS を復活させるかみたいな流れっぽい
- 何を基準に LTS を決めるかとか、サポートバージョンを増やすと CI のコストが増えるから各ベンダーが入らないと厳しいとか、脆弱性やバグ修正の cherry-pick の責任誰が持つんだよとかいろいろ問題はあるから、どうなるかまだ分かんない
2023/4/20
- mmap でファイルの中身をメモリ上に載せたときの RssFile の話 (comment - k/k#116895)
- メモリ逼迫すると回収可能なメモリマップが自動的に破棄されるだけなので、RssFile の使用量は cgroup で制限されない
-
kubectl top podsで表示されるメモリ使用量に含まれてないのも同じ理由なはず
2023/4/21
- Envoy Proxy のドキュメンタリ (youtube)
- Twitter 時代に前身の Twitter Streaming Aggregator (TSA) を開発して、ある時に日付処理のバグで障害を起こし、それが原因で Lyft に移って、モノリス -> マイクロサービス移行やっていたけど余り上手く行っておらず、ALB 含め既存の Nginx や HAProxy も当時は Observability が弱くて Envoy を作った。成功に火を付けたのは Google との協調 (gRPC の開発チームと密に連携したり、Google 社内で Envoy の採用が始まったり) と CNCF への寄贈
- 「Envoyを革命的なものではなく、進化的なものと捉えている」で締めるのかっこいい
- ブログの内容を良い感じにまとめてる (blog
2023/4/22
- preStop hook に httpGet と exec の他に新しく sleep を追加する KEP (KEP-3960)
- みんな大好き preStop hook の exec で sleep して SIGTERM を受けるのを遅らせるのはコンテナイメージ内に sleep のバイナリが必要なのでそれを楽にしたい
- もともと Tim Hockin が挙げてる要望で sig-node からも賛同は受けているのと、実装方法も明確なので機能としては入りそう (実装者の根気次第なところはあるけど、これなら最悪引き継げそう)
2023/4/25
- Ephemeral Container も Pod Security Admission の制約を受けるので、デバッグで強い権限が必要な場合は、apiserver の設定で exemptions を追加して特定のユーザーを除外する必要がある (comment - k/k#117130)
- GKE だと無理なので諦めるしかなさそう
- EKS の CoreDNS Addon v1.9.3-eksbuild.3 から affinity や tolerations などが設定できるようになってるらしい (comment - aws/containers-roadmap#1930)
- まだ利用できないバージョンらしい (comment - aws/containers-roadmap#1930)
2023/4/27
- Google Cloud のフランスリージョンの大規模障害の影響で registry.k8s.io が不安定になっているらしい (kubernetes/registry.k8s.io#234)
- フランス周辺の地域で registry.k8s.io に繋がらなくなった問題のポストモーテムがもう書かれてた (comment - kubernetes/registry.k8s.io#23)
2023/4/28
- Kubernetes で LTS をやるのやっぱり厳しそう (twitter)
2023/4/29
- Brendan Gregg 先生の新作 (blog)
- 単に既存の eBPF ベースの Observability ツールを組み合わせて、セキュリティ監視製品が作れるとは思うなよって話だった
- セキュリティ監視製品を作る上で eBPF にポテンシャルはあるけど、オーバーヘッドの問題とかいろいろ大変だから、ペネトレーションテストの経験のある良いセキュリティエンジニアを雇ってね
- Kubernetes 1.26 + kube-proxy の mode=ipvs でリグレッションがあり、ノード IP を loadBalancer IP として使っている場合に動作しなくなる問題の修正 (k/k#115019)
- Kubernetes 1.26 + kube-proxy の mode=ipvs でバグがもう一つ (k/k#117621)
2023/5/3
- Kubernetes 1.23 と 1.26 で確認されている (1.27 では再現しないらしい) 変なバグで、RestartPolicy=Never の Pod の initContainer の子プロセスが OOMKill されると、プロセスが exit code 0 (通常は 137) で終了して、Pod の状態が Pending になって Pod GC でお掃除されない (k/k#116676)
- k/k#115331 で修正されていて 1.27 で再現できなかった模様
- Kubernetes 1.26 に k/k#115331 を cherry-pick 予定 (k/k#117788)
2023/5/4
- wg-lts の復活に向けた動きが粛々と (twitter)
- eBPF の fuzzer (google/buzzer)
2023/5/6
- Kubernetes 1.28 から MutatingWebhookConfiguration と ValidatingWebhookConfiguration を kubectl で扱い時に mwc と vwc の短縮名が使えるようになる (k/k#117535)
- 後日 revert されて使えなくなった
2023/5/10
- Helm の values ファイルって昔は TOML 形式だった (helm/helm#768)
- 未だに TOML に戻してくれってコメントあるけど、あんなネストした values ファイルを TOML で書きたいのか...?
2023/5/11
- DNSWatch is a DNS snooping utility (facebookincubator/dnswatch)
- Argo CD でソースに Git と Helm repo 以外に OCI registry を追加する提案。Kustomize や Jsonnet、Helm に生の YAML もサポートする予定らしい (argoproj/argo-cd#13516)
- Flux の後追いっぽい
- Media Types が独自なのでいろんなツールで使えないだろうし、その辺りも標準化して欲しい
- Kubernetes の wg-lts は賛成多数で復活する模様 (kubernetes/community#7287)
- MS / AWS / Google からそれぞれリードが出ている
- liggitt さんがリードになってるの意外だったけど、こういうお気持ちらしい
While I'm personally skeptical that the community can afford to support additional versions, and I think a "same thing but for longer" approach mostly just time-shifts issues people currently have N months into the future, I'm on board with identifying/driving efforts that provide broad benefit to users, specifically improve the lives of users/vendors that need to support Kubernetes longer than OSS currently does, and can be afforded by the community.
- 最初はエンドユーザーへの調査から始める
- 現在使っているバージョンは?
- デプロイとアップグレードの方法や流れに対する各業界の制約は?
- ユーザーとベンダーそれぞれどれくらいサポート延長して欲しい?
- Kubernetes のコアな依存関係をサポートする期間は?
- Kubernetes クラスタを動かすための OS やネットワーク、ストレージなどをサポートする期間は?
OSS の EoL を過ぎたバージョンをサポートするために、ユーザーとベンダーそれぞれがやってることは何?
現在、ユーザーとベンダーそれぞれが EoL を過ぎたクラスタをどう扱っている?EoL が N ヶ月延長されるとどうするのか?
- 上記の情報をもとに、Kubernetes プロジェクトとして取り組めることを調査する
- 全てのマイナーバージョンのサポート期間の延長
- 特定のマイナーバージョンのサポート期間の延長
- 現在の EoL を過ぎたリリースブランチに対して、パッチバージョンを切らずにセキュリティ修正を適用する
- 現在の EoL を過ぎたリリースブランチに対して、パッチバージョンを切らずにセキュリティ修正と影響範囲のデカい修正を適用する
- バージョンスキューのポリシーを広げる
- EoL になったクラスタのアップグレード方法の改善
- なので、LTS バージョンが登場するかはまだ分からないし、LTS バージョンをやるにしてもベンダー側でやれるように整備していく感じになりそう
- control plane な RedHat の Stefan さん、Crossplane な Upbound に行っちゃうらしい (blog)
2023/5/12
- RedHat の Stefan さん、Crossplane な Upbound に行っちゃうのか (blog)
2023/5/13
- kubelet が Pod を起動する時にコンテナイメージを並列でプルする機能があったのですが、並列で処理する数を制限できず、ネットワーク帯域を圧迫する可能性があったので使えず、直列で一つずつダウンロードしていました。並列処理数の制限を指定できる機能が 1.27 からアルファ機能として入っていて、GKE は 1.27 から有効化する予定らしい (comment- kubernetes/enhancements#3673)
- 新しくノードが追加されて、重めのコンテナイメージで Pod がたくさん起動するときなどに起動時間が早くなるはず
- アルファ機能ではあるけど、新しい API リソースの追加とかではなく etcd にも影響ないのと、何かあっても設定なくせば元の挙動に戻るから安全と判断してそう
- 最大並列数をどう決めるのかは気になるけど、ノードあたりの Pod の最大数とかノードのスペックで動的に変えるのか、ディスクスロットリングが起き辛い小さな数から始めるのか
-
registry.k8s.ioで存在しない S3 バケットを参照しているリージョンがあった問題 (kubernetes/registry.k8s.io#247)- 悪意のある第三者が同名で S3 バケットを作成し、適当な blob をアップロードすることで、コンテナレジストリのクライアントのダイジェスト検証に失敗して、リトライを繰り返すことで DoS 攻撃になってしまう可能性があった
- この問題に気付いた報告者が S3 バケットをすぐに作成して、悪意のある第三者が作れない状況にしてくれていたので実害はなかった
- 存在しない S3 バケットの参照を外して、自動テストの中で少なくとも 1 つは S3 バケットから取得できるかチェックするようにした
2023/5/14
- Sidecar container の機能は順調に実装が進んでいて、実装済みの機能を Istio で検証してみたら想定通りに動いてそうとのこと (comment - k/k#116429)
- Alpine (musl libc) で名前解決時に A / AAAA の DNS クエリが並列実行されますが、
負荷などの影響で DNS クエリがタイムアウトすると、5 秒程度待ってからリトライされるので詰まる問題がありました。Alpine 3.18 (musl 1.2.4) から UDP でタイムアウトすると、TCP にフォールバックするようになったので直ったかもらしい (comment - k/k#56903)
2023/5/16
- SIG Scheduling による Scheduler の WASM 拡張のプロジェクトが開始 (twitter)
2023/5/21
-
Russ Cox が Kubernetes に Issue を上げていて何かと思ったら、Go の proposal: spec: less error-prone loop variable scoping で紹介しているツールで発見した感じっぽい
- for loop のスコープが期待通りに動かないやつで、以下のコードだと items の最後の要素が loop の回数追加されちゃうので、
var all []*Item for _, item := range items { all = append(all, &item) }- こうしないといけないやつ
var all []*Item for _, item := range items { item := item all = append(all, &item) }- 大規模な Go のコードで proposal の変更がバグの発見には役に立つけど、悪い影響を与えないことを確認していて発見したらしい (comment - golang/go#60078)
2023/5/25
- EKS にも Kubernetes 1.27 が来てた (blog)
- GKE から 1 週間ちょっと遅れ
- GKE や AKS に比べて追従遅れてるイメージあったけど、巻き返しててすごい
2023/5/26
- GKE 1.27 から private cluster でもコントロールプレーンとノード間の通信に Konnectivity Service を使い始めるみたいなので、Firewall ルールで Egress 全遮断して必要なポートだけ許可してる場合は注意です (release note)
- public cluster はもう Konnectivity Service を使うようになってます。Egress 遮断してたので、その時に kubectl logs/exec や API Aggregation Layer を使ったサービス (e.g. metrics-server, Agones) がタイムアウトして正常に動作しなくなる問題が起きました
- 8132 番ポートでノードのネットワークタグからコントロールプレーンの IP 範囲に外向きで繋がるようにすれば良い (doc)
2023/5/27
- gke-gcloud-auth-plugin のシングルバイナリ提供が順調に進んでいるようなので、パッケージマネージャや gcloud components install でインストールしなくてもよい世界になりそう (comment - kubernetes/cloud-provider-gcp#433)
2023/5/30
- VictoriaMetrics の vmui の Cardinality Explore 良さそう。指定した日付とメトリクスの量比較してくれる (playground)
- HPC のワークロードのコンテナイメージ大きくなりがちなので、CRI 経由でコンテナランタイムからイメージプルの経過を教えて貰えるようにする KEP-3542 の PoC (k/k#118326)
- 今は streaming で途中経過をもらう実装だけど、Pod の数に比例して kubelet の負荷が高くなったり stream の管理コストもあるので polling に変わるかも
- 途中経過は N 秒毎、イメージサイズの N バイト数毎 (デフォルト)、イメージサイズの N% 毎から選べる
- Event に書き込んで kubectl describe とかで見れるようになるはず。コンテナランタイム側の API 決めるための PoC なのと、KEP-3542 はその情報をどう表示するか範囲外 (レビューで指摘はされてるので後々入る?) なので、まだまだ掛かりそう。
- eBPF を使ったプロダクトが GPL + 何かのデュアルライセンスになっちゃうけど、CNCF のポリシーだと GPL 系は許可されていないので CNCF プロジェクトに影響が出ているらしい (docs)
- カーネル側でロードする時に eBPF module のライセンス検証があって GPL 互換なライセンスじゃないといけないので、GPL + 何かのデュアルライセンスにするしかないので、eBPF の場合は特別に許してねって相談に行く予定
- Cilium の CNCF Graduation のストッパーにもなっているらしい
- Istio の CNCF Graduation は試験的に入っている eBPF 関連のコードを外に出して通すっぽい (comment cncf/toc#1000)
- EKS の API で aws-auth の ConfigMap に権限を追加する機能がほんとのほんとにそろそろ来るらしい (comment - aws/containers-roadmap#185)
2023/6/1
-
Karpenter のコア部分を Kubernetes のサブプロジェクトに移して、他のクラウドプロバイダーが実装できるように働きかけていくらしい (kubernetes/org#4258)
- Karpenter が生まれた理由がこれなので、今後 Cluster Autoscaler が Karpenter に切り替わっていくのかいかないのかは気になる
AWS approached SIG Autoscaling in 2019 and later in 2020, described the challenges our customers were facing with the Cluster Autoscaler, and proposed changes to better meet their needs. The SIG expressed reasonable concerns about how to prove out these ideas while maintaining backwards compatibility with the broadly adopted Kubernetes Cluster Autoscaler, and recommended we explore the ideas in a separate project, so we made github.com/aws/karpenter.
- Karpenter と Cluster Autoscaler の思想の違い (twitter)
- Karpenter の GKE プロバイダーを昔作ろうとしたけどできなかったのは、GKE は単体のノード (GCE インスタンス) をクラスタに追加できず、ノードプールとして追加する必要があったかららしい (comment - kubernetes/autoscaler#5394)
2023/6/2
- ECR のプルスルーキャッシュで registry.k8s.io をサポート開始 (blog)
- Kubernetes コミュニティの援助資金の大部分がコンテナイメージの配布で使われているので、プルスルーキャッシュを使って配布のコストを減らしたい思惑
2023/6/4
- Kubernetes 上で複数の Kubernetes コントロールプレーンを動かして、どこで動いているかに関わらず k0s のノードを追加できるツール。エッジ用途でエッジ側にコントロールプレーンを動かさなくていいとか、CI/CD や開発環境でコントロールプレーンを動かさなくて良いとかの用途らしい (blog)
- Cluster API と違ってコントロールプレーンを Kubernetes (管理用の Kubernetes) 内で動かしているのと、vcluster と違ってノードは管理用の Kubernetes のを使うのではなく別の場所にあるのをトークン食わせて参加させて Konnectivity サービス経由で繋げる
2023/6/6
- Kubernetes 1.26 以降で重複したエントリのある env や containerPorts を指定した Pod が ClusterAutoscaler によって evict されて別のノードに移ったのに古い Pod が GC されずに残っちゃう問題 (k/k#118261)
- ややこしい問題で、Pod を作成するときの重複チェックが甘く、Server Side Apply の重複チェックがキツすぎるのが原因。Kubernetes 1.26 で KEP-3329 の Pod Disruption Condition がベータになりデフォルト有効になったことで、Pod を GC するときに Server Side Apply で Pod の condition を更新しようとする時に重複エラーになって処理が進まなくなっている
- SSA の重複エラーの場合に処理を進める PR だけど、SSA のエラーコードが 500 で reason フィールドも使えそうな情報がないからエラーメッセージで判別しようとしてるけど、さすがにメッセージに依存するのはまずいから、SSA 側でステータスコードを変えようとしてそう (k/k#118398)
- SSA の重複チェックを緩めて、変更内容に重複したキーに関わる変更がないのと、SSA で 反映した形跡 (Field Manager) がない場合はエラーにしないようにすれば良いという話。SSA でリソースを作るときは重複したエントリを許さないので解決できそう (comment - k/k#118261, kubernetes-sigs/structured-merge-diff#234)
- env や containerPorts を重複したキーを許さない map として扱うのをやめて、マージ時に全部置き換えちゃう atomic に変えちゃえパターン (k/k#118475)
2023/6/10
- etcd に変更を加えて、Kubernetes 公式でクラスタのバックアップとリストアをサポートする動きがある。各ベンダーや Kubernetes の管理者がそれぞれ違ったやり方で etcd をリストアしていて、壊れていたり間違っていたりするかららしい (k/k#118501)
- etcd はオブジェクトを更新する時に古いデータを残しつつ新しいデータを作成し、revision を割り振る
リストアすると etcd を過去の状態に戻すことになり、保存されているオブジェクトの revision が現在の仕様だと戻される - Kubernetes との間のお約束を破ることになるので、etcd 側に修正を入れて revision を増やしながらリストアできるようにする
- Kubernetes のコントローラーがキャッシュからオブジェクトの古い revision にアクセスできないようにしないといけない
- etcd 側に修正を入れて、オブジェクトの古い revision を compaction で削除する案がある
- etcd はオブジェクトを更新する時に古いデータを残しつつ新しいデータを作成し、revision を割り振る
2023/6/13
- Kubernetes 1.28 から cgroup v2 が有効な場合に、fork した子プロセスが OOM になると、そのプロセスだけじゃなくて cgroup 内の全てのプロセスが kill されるように
memory.oom.groupを有効化 (k/k#117793) - Envoy Proxy の作者の Matt Klein さんが Lyft をやめて新しく会社を作ったらしい (twitter)
-
bitdrift
- 既存のオブザーバビリティ基盤を動的でリアルタイムの Observability Mesh に変える
- わずかなコストでログやメトリクスをもっと出せるようになる
- 使っていないデータでコストが急増することはなくなる
-
bitdrift
2023/6/14
-
Topology Aware Routing は 1.28 で PreferZone の実装が入るかも?KEP の変更はマージされた (comment - kubernetes/enhancements#4003)
-
Gateway API は Ingress を置き換えるものではないので、API が非推奨になる予定はない。既存のコントローラーのほとんどがこれからもずっと使えるはず (機能追加は減りそう)
https://gateway-api.sigs.k8s.io/faq/
Q: Will Gateway API replace the Ingress API?
A: No. The Ingress API is GA since Kubernetes 1.19. There are no plans to deprecate this API and we expect most Ingress controllers to support it indefinitely.
2023/6/15
- Kubernetes は Go >= 1.17 の標準ライブラリの挙動の破壊的変更 (10.030.0.10 みたいに 0 を先頭に付けると解釈されなくなる) と etcd の中身の互換性を保つために、わざわざ Go <= 1.16 の net.ParseIP の実装をフォークして使ってるけど、etcd の中にあるデータは仕方ないとして他の部分では徐々に使えなくしないとマズくない?ってコメントの中で、IP アドレスのパースのエッジケースの話が書いてあって、大変そう。IPv4 Mapped IPv6 なんてのがあるんですね (comment - k/k#108074)
2023/6/18
- Spot インスタンスでノードのメンテナンスが発生すると、Node Graceful Shutdown の機能で Pod が移動されるんですが、古い Pod が
NodeAffinity状態で残っちゃう問題が報告されています。ノートセレクタを指定している場合 (e.g. NAP) だけっぽいです。GKE 1.27.2 でも再現しました。(comment - k/k#112333)
2023/6/20
- 11月の KubeCon NA の CFP の応募が1900近くあるらしい (twitter)
2023/6/21
- Kubernetes 関連のライブラリ更新がシグネチャに context を渡すように変わったとき以来の壊れ方をしているらしい (comment - kubernetes/kube-openapi#402)
- ライブラリの依存関係を減らすために、google/gnostic から切り出した google/gnostic-modes に一部切り替えたところ、まだ切り替え終わっていないライブラリを一緒に import しようとすると死ぬらしい
2023/6/23
- VictoriaMetrics 一家にログバックエンド (VictoriaLogs) が追加されてる。Elasticsearch や Loki よりも運用が楽らしい。Grafana Labs と殴り合ってるな (v0.1.0-victorialogs)
- Argo CD 2.8 で UI から
kubectl create job --from=cronjob/foo foo相当の CronJob から Job を生成してその場で実行する機能が入るみたい (commit - argoproj/argo-cd#4116)
2023/6/24
- Cilium と kube-proxy で平等にトラフィックを分散するための実装は違うけど、クライアント側で keepalive 外してある程度負荷をかけても偏りが出てくる。擬似乱数生成の部分が影響してそうだけど、どうしようって話 (gist)
2023/6/26
- Kind + NVIDIA Container Toolkit で GPU を利用する方法。NVIDIA のコンテナランタイムがどの GPU をコンテナに割り当てるかを環境変数で渡すのが基本だけど、Kind だと無理なのでファイルマウントで知らせるハックが必要。Kind は特権でノード (Docker コンテナ) を起動するので、刺さってる GPU 全部見えちゃうから all しか選べない (comment - kubernetes-sigs/kind#3257)
- Kind に GPU 専用の設定を入れようとしている人がいたけど、メンテナから拒否されてた。Docker Docker 25 で CDI がサポートされて、GPU 以外のデバイスも使えるようになるので、Kind 的にはそれを待ちたい。それまでのワークアラウンド
- CEL の Playground (site)
2023/6/28
- Cloud Native とか Kubernetes にも影響力のあった DevRel の方が Google を辞めたそうです。会社に属するのはこれが最後で、講演とか技術顧問とか OSS 活動をメインで続けるらしい (twitter)
-
kubectl top nodesで表示されるノードのメモリ使用量が cgroup v1 よりも cgroup v2 の方が高く表示される問題が Azure の中の人から報告されてます。- cgroup v1 の時は root の cgroup の
memory.usage_in_bytesのファイルを見てるけど、cgroup v2 の場合は /proc/meminfo の情報からtotal - freeで計算している。で、cgroup v2 の方は inactive_anon (アクティブじゃないキャッシュ) が含まれていてその分高く表示されているかもらしい
- cgroup v1 の時は root の cgroup の
2023/6/30
- util パッケージ地獄はどこにでもある (comment - k/k#118680)
- kubernetes/utils は外部利用されるので API の互換性が保証されていて、kubernetes/kubernetes/pkg/utils は Kubernetes 内部でしか使ってないから適当、kubernetes/apimachinery の utils は外部利用されるけど kubernetes/utils よりは緩い保証
- 去年の夏にサードパーティのベンダーが Kubernetes のセキュリティ診断をやったらしく、4月に出た結果に対応するための Issue が作られていってる (k/k#118980)
2023/7/2
- EKS の CoreDNS Addon が PDB サポートした (comment - aws/containers-roadmap#1028)
- 必ず作られるようになったらしく、PDB を手動で作っているとバッティングするらしい
- PDB のデフォルト値 (ユーザーが設定を変えられない?) がいけてなくて議論中
2023/7/3
- kubectl 1.28 から diff に並列数を指定するオプション (
—concurrency) が追加されたので、差分表示が早くなる (k/k#118810)- Polar Signals の中の人がライブ配信でプロファイル取りながらどこが遅いか見てたらしい。良い宣伝 (youtube)
2023/7/4
-
container_memory_usage_bytesは memory.usage_in_bytes ファイルから情報を取ってきていて、RSS とキャッシュとスワップ領域の合計になっていたけど、kernel 4.4+ だと memory.usage_in_bytes に memory.kmem.usage_in_bytes の値が追加された。cAdvisor は既にcontainer_memory_rssとcontainer_memory_cacheとcontainer_memory_swapを Prometheus のメトリクスとして公開しているけど、memory.kmem.usage_in_bytes の値は公開されていなかったので、container_memory_kernel_usageを追加した。これで、4 つを足し算するとcontainer_memory_usage_bytesの値と同じになる (google/cadvisor#3306) - 今まで条件に一致するまで待つ時に kubectl wait --for=jsonpath='{.status.phase}'=Running pod/busybox みたいな形で値 (=Running) を指定しないといけなかったけど、kubectl 1.28 から任意の値が付与されるまで待てるようになるみたい (k/k#118160)
- 例えば、Service type LoadBalancer の IP が払い出されるまで待ちたい時に、これまでだと払い出される IP が予想できない時があったけど、そんな時でも待てるようになってる
# kubectl < 1.28 ✖ kubectl wait --for=jsonpath='{.status.loadBalancer.ingress}' svc/backends error: jsonpath wait format must be --for=jsonpath='{.status.readyReplicas}'=3 # kubectl >= 1.28 ❯ _output/bin/kubectl wait --for=jsonpath='{.status.loadBalancer.ingress}' svc/backends service/backends condition met
2023/7/6
- Flux v2 が GA (v2.0.0)
2023/7/7
- Chainguard Images は latest 系のタグ以外無料では使えなくなる (toVersus/otel-demo#1)
2023/7/8
- Sidecar containers のベースの PR がマージされました。follow-up の PR がいくつかあるはずですが、順調に行けば 1.28 でアルファ機能としてリリースされそう (k/k#116429)
2023/7/9
- GKE の Service type LoadBalancer (externalTrafficPolicy=Local) で、kube-proxy のヘルスチェックの返答のヘッダーからそのノード上で動いている Pod (Endpoint) の数を取ってきて、重み付け負荷分散する機能を追加する予定みたい (k/k#118999)
- eTP=Local の場合は、特定のノードに Pod が偏ってると現状はトラフィックが均等に分散されないので、それが解決できそう
2023/7/13
- kube-proxy が iptables のルールを書き換える直前に conntrack のエントリを削除してしまうので、凄い短い期間だけど UDP パケットが闇に消えちゃうことがあるらしい。kube-proxy の IPVS モードの E2E テストが Flaky な原因かもで調査中 (k/k#119249)
- iptables の同期間隔 (—iptables-min-sync-period) が Kubernetes の E2E テストの環境で (確か GKE も) 10 秒になってるから問題になってないだけかもらしい。EKS はデフォルトの 1 秒だったような
- Immutable ConfigMap / Secret を使ってる人は少なそうだけど、空文字列を値に入れるとシリアライズの問題でそれ以降ラベルなどのデータに関係ない部分の変更まで出来なくなってた問題が修正されたみたいです。ゼロ値難しい (k/k#119229)
- GKE Dataplane v2 に Managed Hubble がプレビュー機能できてる (doc)
- KubePug 用のらしいけど、非推奨 API の情報をいい感じにまとめたやつ (twitter)
2023/7/14
- GitHub の Kubernetes のスター数が 100k 超え (twitter)
- Kubernetes 1.24 から安全のため新しい Beta API はデフォで有効にされなくなったけど、
GKE に指定した Beta API を有効にできるオプションが追加された (doc) - runc がついに PSI メトリクスを収集するようになったので、あとは cAdvisor で対応されると CPU とかメモリ、I/O の負荷が見やすくなる (opencontainers/runc#3900)
2023/7/18
- Kubernetes の WG-LTS の復活は承認されたようです (kubernetes/community#7287)
- kubectl の公式コンテナイメージが 1.28 からリリースされる予定です (comment - k/k#116667)
2023/7/19
- Kubernetes 1.28 の機能追加のコードフリーズが発動 (mailing list)
2023/7/20
- コンテナランタイムの CRI-O もやっと CNCF Graduated プロジェクトに (twitter)
- PodStatus に RequestedResources を追加する機能がマージ間に合わなかったけど、Sidecar container 自体は無事に 1.28 でアルファ機能として入るみたいです (comment - kubernetes/enhancements#753)
2023/7/21
- IAM Identity を EKS API で管理する機能の実装予定のチラ見せ来てた (comment - aws/containers-roadmap#185)
- 今までの aws-auth の ConfigMap で管理する方法は認証モードは CONFIG_MAP と呼ばれ、これとは別に Access Entry API で管理する認証モードが追加されるっぽい
- クラスタ作成時や作成後にクラスタ管理者なら Access Entry API を介して IAM Identity を好きに変更可能
- 新規 EKS クラスタ作成時にクラスタ作成者の管理者権限を付与しないフラグが追加される
- 既存の EKS クラスタが対応する EKS プラットフォームバージョンに到達したら、Access Entry API を有効化できるようになる
- Access Entry API を有効化すると、クラスタ作成者の権限が確認できるようになり、その権限を落とすこともできる
- クラスタ作成者に管理者権限を渡すかどうかは認証モードに関わらず設定可能
- CONFIG_MAP の認証モードの時は、Access Entry API が無効になっているので、クラスタ作成者の Kubernetes 管理者ロールは非表示のまま
- finalizer の命名規則 (example.com/foo) がコアリソース (e.g. Namespace) だと強制されるけど、カスタムリソースだと強制されない問題
- コントローラーのチュートリアルで foo とか foo.bar を指定するものが既にあって壊れちゃうから警告返すしかなそうって話を SIG の Slack でしていた(slack)
- けど、それを知らず (?) に先走った人がエラーを返す PR を作ってしまってるからこれは通らなそう...テストもないし (k/k#119508)
2023/7/22
- Validating Admission Policy もコードフリーズ後の例外申請が通って 1.28 で Beta に昇格 (k/k#118644)
- 新しい API なので Beta に上がってもデフォルトで有効にはなっていない
2023/7/23
- kubectl debug の事前定義のプロファイルだとユースケースのカバーがやっぱり難しいので、ユーザー定義のカスタムプロファイルを追加する機能を予定しているらしい。だからもうこれ以上フラグを追加する気はない (comment - k/k#118755)
- 時間の余裕がなくてまだ誰も取り組んでいないけど、KEP-1441 を GA させて別の KEP で対応する予定 (comment - kubernetes/enhancements#1441)
- crictl / kubectl exec -it で繋げている状態で containerd を再起動すると exec したプロセスがリークしちゃう問題 (containerd/containerd#8856)
- containerd を再起動しなくても -it なしで exec して実行したプロセスを Ctrl+C で抜けてもリークしてるらしい
2023/7/25
- Gateway API の validating 用の Webhook は CEL for CRD に置き換えるみたい (kubernetes-sigs/gateway-api#2226)
- Gateway API は最新から 5 バージョンをサポートしていて、CEL for CRD が 1.25+ だからまた Kubernetes のバージョン毎に別の CRD を提供しないといけなくなるとこだったけど、CRD の
x-kubernetes-validationは 1.23 から効果はないけど使えるらしいので、CRD を分ける必要なかった (comment - kubernetes-sigs/gateway-api#2226)
- Gateway API は最新から 5 バージョンをサポートしていて、CEL for CRD が 1.25+ だからまた Kubernetes のバージョン毎に別の CRD を提供しないといけなくなるとこだったけど、CRD の
- Autopilot > 1.27 でバッチ処理やマルチプレイ用の Dedicated Game Server など長時間起動しておきたい時に、Cluster Autoscaler 用の annotation を Pod に付けておくとノードのスケールダウンやクラスタ更新時の移動が起きても最長で 7 日間は Evict されなくなった (release note, doc)
- イメージのプル時間を含むという意味深な制限があるので Pod 起動時から最長 7 日間かもしれないので、Dedicated Game Server のように起動しっぱなしのケースだと挙動をちゃんと見ないといけない
-
Image pull times are counted when calculating the extended run time.
-
- イメージのプル時間を含むという意味深な制限があるので Pod 起動時から最長 7 日間かもしれないので、Dedicated Game Server のように起動しっぱなしのケースだと挙動をちゃんと見ないといけない
2023/7/26
- Kubeflow も Incubation プロジェクトとして CNCF 入り (blog)
- [定期] NodeLocal DNSCache じゃなくて CoreDNS を DaemonSet で起動するだとダメなの? (comment - kubernetes/dns#594)
- クラスタ内の DNS として CoreDNS を動かすと Kubernetes plugin により DNS ベースのサービス検出が使えるようになる
- CoreDNS は Kubernetes の API サーバにコネクションを張って、Service や EndpointSlice の変更を watch する
- CoreDNS を DaemonSet として起動すると、ノードの数だけ CoreDNS が API サーバ経由で watch するので API サーバやその裏にいる etcd に負荷を掛けることになる (e.g. 1000 ノードあると 1000 台の CoreDNS が起動)
- NodeLocal DNSCache は単なる DNS のキャッシュサーバ + スタブリゾルバ (問い合わせ先の情報をもとにフルリゾルバに聞くだけ) なので API サーバを watch しない。API サーバから受け取ったリソースの情報を保持する必要がないのでメモリ使用量も削減できる
- クラスタ内の DNS には conntrack table を圧迫する問題もあり、NodeLocal DNSCache はそれも軽減できる
- DNS クエリは通常 UDP で投げられるが、UDP の場合、古い conntrack エントリの削除はデフォで 30 秒かかる。TCP のようにコネクションが切れるとすぐにエントリが消えたりはしない
- 昔はカーネルの conntrack の競合に関するバグが 3 つあって、特に conntrack テーブルが枯渇しやすかったが、2 つはもう解決されている
- NodeLocal DNSCache は Pod から NodeLocal DNSCache までは iptables の書き換えによりノード内に留まるので NOTRACK を指定することで conntrack テーブルの追跡を避け、NodeLocal DNSCache から
- CoreDNS までは UDP でなく TCP を使いことで conntrack テーブルが詰まらないようにしている
- CoreDNS を DaemonSet として起動しても internalTrafficPolicy=Local でも使わない限り、リクエストが同一.ノードの CoreDNS に投げられるとは限らない。kube-proxy は確率ベースでほぼ均等に負荷分散するように
- iptables を設定しているので、1000 台のノードがあると単純計算でリクエストの 1/1000 しか同一のノードに行かないことになる
- In-place Pod Vertical Scaling と VPA の連携の話で、現在の In-place Pod Vertical Scaling の機能だと resources を書き換える時に Pod が再起動する (同一ノードに割り当てられるリソースの余裕がない) か再起動なしで変更できるか分からない。VPA の実装によっては PDB 違反になるかもしれないので、再起動なしでリソース割り当てが変更できる時だけ書き換える API を追加するか、PDB 側の実装を変えてリソース割り当ての変更も考慮させる必要があるかも (comment - kubernetes/autoscaler#4016)
- ingress-gce にも最近マージされた Network LoadBalancer の Strong Session Affinity って名前が強そうだけど、既存のと何が違うんだろう (GoogleCloudPlatform/magic-modules#8409, kubernetes/ingress-gce#2175)
- 1.28 から提供予定の kubectl の公式イメージにシェルとか諸々便利なツールも入れるらしい (k/k#119567)
2023/7/28
- Cilium 1.14 リリース (twitter, blog)
- CNI のお掃除漏れもなくなって、cillium-agent が動いてない時に Pod がスケジュールされなくなってるし、CNI の設定ファイルを消さなくなったから NLB からブチっと外れることもなくなってるのが GKE ユーザーとしては一番嬉しいかも (cilium/cilium#23486)
2023/8/1
- 外部のコントローラーが Node オブジェクトを削除すると、Lease コントローラーが Node が存在しない場合のエラーを握り潰しているせいで OwnerReference のない Node の Lease オブジェクト (定期的に更新してノードの正常性を監視) が作られてそのままリークしちゃう問題 (k/k#109777)
- AWS の人が最近別で Issue を上げてたやつ (k/k#119660)
- AWS の人が修正の PR を上げたけど、#109777 との関連性を指摘された。で、Z Lab のuesyn さんが過去に修正の PR を上げていて、動きがなくて bot がクローズしてたのを dims さんが蘇らせてどっちの修正がいいか判断しようとしている (k/k#110834)
- 1 年以上前の PR を急に呼び覚まされて、Slack で呼び出し食らって困惑しているだろう uesyn さん (slack)
2023/8/2
- EKS の AL2 AMI のノードでオンラインで OS のパッチを自動適用する機能を有効化してくれって、Datadog の障害もう忘れたのかな? (aws/containers-roadmap#2098)
- Karpenter ってノードのテンプレート内の AMI の更新を検知してノードを入れ替えてくれるんだ (comment - aws/containers-roadmap#2098, comment - aws/karpenter#1738)
- EKS の Fargate ノードで Ephemeral Storage が最大で 175 GiB まで使えるようになった。元々 20 GiB しか使えなかったので、ML の推論とかデータ処理も動かしやすくなる? (blog)
- Flaky な E2E テストの調査でたまたま見つかったバグ。Service type ClusterIP を作ると status.loadBalancer.ingress[].ip は空だけど、パッチを当てて値を埋めることができる。その状態で Service type LoadBalancer に type を変えると、status.loadBalancer の値がリセットされずに残っちゃう (k/k#119700)
- Service type LoadBalancer から type を ClusterIP に変えたときは status.loadBalancer の値はリセットされる
2023/8/4
- SOCI on Fargate で ARM のコンテナイメージもサポートされた (aws/containers-roadmap#2078)
- Azure Cloud Controller Manager だと failure-domain.beta.kubernetes.io/zone の非推奨のノードラベルが 1.26 からノードに付与されなくなっている。PV で Node Affinity が設定できるらしく、非推奨なノードラベルをセレクタに設定していると immutable だから変更できず、Pod がスケジュールされなくなる問題があるらしい。だから、PV の Node Affinity を可変にする PR を 1.25 と 1.26 にも cherry-pick したい (comment - k/k#115391)
- SAP の人の報告だから、また Gardener で問題があったっぽい
2023/8/6
- terraform-provider-argocd を CNCF に寄贈して argoproj 組織の下に置けないか相談中らしい (oboukili/terraform-provider-argocd#323, slack)
- Argo CD で複数クラスタのリソースを管理している場合に Terraform でクラスタを登録できると便利?
2023/8/8
- Dataplane v2 は現状 netd が Cilium の CNI の設定ファイルをノード上の
/etc/cni/net.d/配下に配置することで kubelet がそれを検知してノードの状態を Ready に変更している。netd が CNI の設定ファイルを置く前に Cilium が起動しているかを Cilium のエンドポイントを呼び出して確認する処理を追加する PR だけど、
結局 Cilium Agent (anetd) が起動して Ready 状態になるまでは他の Pod が起動できない問題は残る (GoogleCloudPlatform/netd#220) - Argo CD v2.8.0 リリースされてた (release)
- 8/3 の sig-network ミーティングでも話をしていた metav1.Duration を置き換えるかもしれない文字列 + 正規表現でパースする新しい期間を表すフォーマットを作るよの GEP がマージされてた (, meeting)
- Gateway API のタイムアウト値で使う予定で 10m とか 1s とかの表記は変わらず、文字列で受け取るのでシリアライズ/デシリアライズの処理が変わるだけ
- Gateway API で検証して良さそうなら既存の metav1.Duration を使っている部分を置き換えるかも
- metav1.Duration をフィールドに変な値を入れると JSON から Unmarshal する時にパースしてエラーになって 500 エラーを返すだけだから validation 時のように有用なエラーを返せなくなるから良くないらしい
2023/8/9
- Go 1.21 で WASI 対応の wasm がビルドできるから ko でも wasm コンテナイメージをビルドできるようにするみたい (ko-build/ko#1095)
2023/8/10
- kube-proxy のログレベルを引数で上書きできなくなった 1.28 のリグレッション (k/k#119863)
- Go のデフォルト値問題と設定ファイルか引数どちらを優先するか問題のせいで、設定ファイルに何も指定してないのにゼロ値の 0 にログレベルが設定されちゃう 。1.28 のリリースまで 1 週間だけどリリース前に修正を取り込まないとまずい
- kube-proxy 以外には影響なくて、kube-proxy に —config で設定ファイルを渡すと起きちゃう。kube-proxy にはフラグで設定ファイルの値を上書きするようにする特別なフラグがあったりで、ややこしそう (k/k#119864)
2023/8/13
- Cloud Controller Manager の Pod が再起動でフォールバックする時に、今の設定だとリーダー選出に時間が掛かって、Node の追加や LB のバックエンドの更新ができない時間が増えちゃうから停止時に Lease を手放す設定を追加したい (k/k#119905)
- 今までなかった (k/k#119908)
- VictoriaMetrics v1.92.0 に上げることでメモリ使用量が 1/5 程度に減るかもらしい (twitter)
2023/8/15
- Kubernetes にも Trace Exemplar が入ろうとしている…!(k/k#119949)
- KEP-647 で kube-apiserver にトレーシングが入ったので、トレース情報とメトリクスを紐づけたい。Kubernetes の logs / metrics / tracing / featuregate 用のライブラリの component-base の metrics に実装を入れる。共通ライブラリで kube-apiserver 以外でも使われているので、インターフェイスの実装を上書きして、context で Trace ID や Span ID が伝搬されているときだけ Exemplar を紐づける感じか
2023/8/16
- Kubernetes 1.28 が予定通りリリースされました (blog)
2023/8/17
- Argo CD v2.8.0 で Application Controller に新しい sharding の方法が試験的に追加されていて、Argo CD に登録されている Cluster の一覧を Cluster ID で並び替えてラウンドロビンで Controller に割り当てるので、以前の方法のように特定の Controller に偏ることがなくなった。ただ、Argo CD の Cluster の登録を解除したりすると再割り当てしないといけないのが問題 (argoproj/argo-cd#13018)
- sharding の計算が重いので無駄に CPU 使いまくってる問題もある (argoproj/argo-cd#14337)
- StatefulSet を使わずにスケールしても動的に shard を割り当てるような提案もマージされている (実装はまだ) (argoproj/argo-cd#13221)
- CREATE と PATCH (strategic-merge-patch) は奥が深すぎる。CREATE の場合、ラベルが null (キーだけで値の指定なし) だと空文字列扱いだけど、PATCH だとフィールドが消える扱い (comment - k/k#119954)
- runc のバイナリを書き換えられるとまずい CVE があったので、今は runc のバイナリをメモリ上に載せている。runc のバイナリサイズが 13 MB 程度あるので、コンテナの数が増えるとメモリ消費も増えちゃう。runc のバイナリサイズを小さくしたいけどそれは難しいので、runc のプロセス自体を見えなくすればメモリ上に置く必要がなくなる。なので、execve で runc-dmz っていうダミーのプロセスに置き換える作戦。これでバイナリのサイズが glibc だと 1.1 MB、musl だと 13 KB まで減る (opencontainers/runc#3983)
- いっそのこと runc-dmz をアセンブリ言語で書けばとか //go:embed でバイナリテキストを runc のバイナリの中に埋め込めんで Go のコードから呼び出した方がいいとかいろいろ言ってる
2023/8/18
- Argo CD のおかげで GKE の自動更新停止祭りになりそう (release notes)
-
You can now easily identify clusters that use deprecated Kubernetes APIs removed in versions 1.25, 1.26, and 1.27. Kubernetes deprecation insights are now available for these versions.
- 1.24 -> 1.25 は PodSecurityPolicy が v1 に昇格せずに v1beta1 で消えたので Deprecation Insights に引っ掛かるけど、それ以降は GA に昇格しているだけなので引っ掛からないかも
-
2023/8/21
- sig-network に同一ポート番号で複数プロトコルな Conformance テストが追加されようとしている (k/k#120069)
- Cilium まだ対応してないけど、アントニオさんが責任持って対応させるらしい (cilium/cilium#26399)
2023/8/23
- Argo CD v2.8 で otel の intercepter がクライアント毎に毎回作られてメモリリークしている (argoproj/argo-cd#15148)
- 一度作った intercepter をクライアントで共有する修正の PR。v2.8.1 はリリースされちゃったので v2.8.2 以降で修正が入りそう (argoproj/argo-cd#15174)
2023/8/24
- Kubernetes で CVE 共有用に Issue のみ確保されてたやつ、どれも Windows ノードのやつだった (k/k#119339, k/k#119595, k/k#119594, slack)
2023/8/25
- Ambient Mesh ってノード毎にプロキシを置くわけじゃないのか。ノード毎のコンポーネントとして ztunnel がいるけど、あくまで Pod とリモートプロキシの間の通信を mTLS や L4 での処理でセキュアにするためのもので、L7 は触らない。リモートプロキシ (必ず同一のノードの Pod じゃない、何ならクラスタ外にも置ける) だと追加のホップが発生するのでパフォーマンス影響ありそうだけど、L7 処理が重くてサイドカーに比べて L7 処理のステップを 2 つから 1 つに減らしているから相殺されるはず (blog)
- ユーザー毎にアップロードした画像から生成したモデルで推論してアバター生成だと FUSE の POSIX 準拠していない制約も気にしなくて良さそう。モデル生成の方は並列で学習回してたりして、制約のせいで GCS FUSE を使えない感じなのかな (blog)
- EKS の CoreDNS アドオンの health プラグインに lameduck オプションが追加されたみたい。何秒待ってから停止するようにしたかは分からないけど、これで CoreDNS のローリング更新時に名前解決のエラーが出るの解消されそう (comment - aws/containers-roadmap#2026)
- EKS のベストプラクティスのドキュメントだと 30 秒にするの推奨してるっぽいので 30 秒かな? (aws/aws-eks-best-practices#314)
- EKS の CoreDNS アドオンの readinessProbe が livenessProbe と同じ /health になっていたけど、/ready に変更できるようになったっぽい (comment - aws/containers-roadmap#941)
2023/8/26
- CPU Limits 指定しないマンみたいだけど、便利かも (robusta-dev/krr)
2023/8/27
- kind は Kind でも KinD でもなく kind / KIND なのか (comment - kubernetes-sigs/kind#3290)
- 1.28 から公開されてる kubectl の公式イメージが Debian ベースになって bash とか jq が入った (k/k#119592)
- CI でマルチアーキのビルド失敗しているみたいで、一旦 revert されてた。原因調べて再トライするみたいだから期待するしかない (k/k#120219)
2023/8/30
- Gateway API の GA 前の最後のバージョンになる予定の v0.8.0 がリリース (release)
- Amazon VPC CNI plugin が BPF ベースの Network Policy をサポート (blog)
- 自前で BPF のライブラリを書いててえらい (aws/aws-ebpf-sdk-go)
- 1 年前くらいにチラ見せしてたのが、リリースされた感じ (comment - aws/containers-roadmap#478)
- Grafana Pyroscope が 1.0 に (twitter)
- Argo CD の新しい Application の依存関係の仕組みの PoC (argoproj/argo-cd#15280)
- Application に新しく追加される dependsOn フィールドに Application のラベルセレクタ or 名前を指定して DAG で依存関係を指定可能
- Application を同期していって Ready になるまでは待ってくれるし、syncDelay で同期開始を固定秒遅らせることもできる
- 現状は同一 namespace かつ AppProject じゃないとダメ
- UI や CLI のサポートはまだ
- Gateway API に GAMMA (Gateway API for Service Mesh) も実験的に入ったし、Service Mesh Interface (SMI) とはさよならするみたい (cncf/toc#1156)
- Kubernetes 1.28 で Sidecar containers の Feature Gate がオフの時に、initContainers の完了を待たずにメインのコンテナが実行されることがある結構やばいバグが NVIDIA の人から報告されてる。ノードが再起動した時 (PodSandbox が変わった時なので、crictl stopp でも再現) にのみ発生する (k/k#120247)
- Sidecar containers の機能のために新しく入ったコードを全て Feature Gate で守っていなくて起きたと言われてはいるけど、Sidecar containers みたいな既存の仕組みに乗っかってる実装だと現実的に難しいけど頑張って実装したみたい (k/k#120281)
- kaniko の由来は Make と image それぞれのギリシャ語を合体させてなんだ。蟹工船ではなかった (twitter)
2023/9/2
- GKE で Multus みたいに Pod に複数 NIC 挿せるようになって、GKE のノードプールの更新などの変更を並列実行できるようになってる (release notes)
- KubeCon NA 2023 の個人的に気になるセッション
-
Sustainable Scaling of Kubernetes Workloads with in-Place Pod Resize and Predictive AI - Vinay Kulkarni, eBay & Haoran Qiu, UIUC
- 最近 eBay に移った In-Place Pod Resize 機能の実装者による Cluster Autoscaler が Pending 状態の Pod をどう扱うかの話と過剰にリソース割り当てられた Pod を適切なサイズに調整するためにどういう変更を加えるべきかの話と、SLO を傷付けずに機械学習を活用して水平・垂直スケールどうやるかの研究の話
-
Zero-Downtime Live Migration of Stateful VMs on Kubernetes - Felicitas Pojtinger, Loophole Labs
- r3map を使って Kubernetes 上で動いているステートを持ったアプリのライブマイグレーションをネットワーク断などのダウンタイムなしで行う方法について
-
Reducing AI Job Cold Start Time from 15 Mins to 1 Min - Tao He, Google
- コンテナイメージを事前に読み込むことで AI / ML ジョブのコールドスタートを高速化できる話とそれ以外にも高速にスケールできるようにするための小技を紹介、15 分から 1 分に起動時間を減らすために今後 Containerd にどういう改善を加えていけるかの話もあるみたい
-
Observing a Large Language Model in Production - Phillip Carter, Honeycomb
- Honeycomb でリリースした LLM を呼び出すバックエンドの経験をもとに Observability どうやるべきかの話、ユーザーにとって重要な要素が何か、プロンプトの変更による影響をどう計測するか?SLO はどう設定したら良いか?
-
The Future of Interactive Data Science at Scale with Jupyter and Kubeflow - Andrey Velichkevich & Zachary Sailer, Apple
- 人が介在してもスケールするインタラクティブな AI/ML ワークフローを Jupyter と Kubeflow を組み合わせて作った話、Apple の発表なのも気になる
-
Maximizing GPU Utilization in Kubernetes with Virtual Kubelets - Goutam Verma, Google Summer of Code
- Virtual Kubelet + 軽量な独自実装の Controller で GPU の利用効率を高めた話、GPU のプールにどう効率的にワークロードを配置するか
-
Unlocking the Full Potential of GPUs for AI Workloads on Kubernetes - Kevin Klues, NVIDIA
- NVIDIA の klueska さんによるいつもの Dynamic Resource Allocation と NVIDIA GPU 用の Driver と Operator の話
-
Sidecar Containers Are Built-in to Kubernetes: What, How, and Why Now? - Todd Neal, Amazon & Sergey Kanzhelev, Google
- Sidecar containers が今になって実装された背景の話もするみたい
-
What's New in Containerd 2.0 - Phil Estes, AWS & Derek McGowan, Independent
- Containerd 2.0 に向けていろいろ試験的な機能が入ってるのでその紹介と既に deprecated 済みで消える機能の話
-
Multi-Network, New Level of Cluster Multi-Tenancy - Maciej Skrocki, Google & Doug Smith, Red Hat, Inc.
- 最近 GKE にも入った Pod のマルチネットワークの話で Multi-Network (sig-network) で議論が進んでいる PodNetwork カスタムリソースの話も
-
Data on Kubernetes Operator Maturity - Melissa Logan, Constantia.io; Michelle Au, Google; Robert Hodges, Altinity
- データベースを Kubernetes 上で管理するための Operator 開発のベストプラクティスや将来的にどうなるかなどのパネルセッション
-
Collecting Low-Level Metrics with eBPF - Mauricio Vásquez Bernal, Microsoft
- eBPF で低レイヤーのメトリクスを収集する話、ebpf_exporter / opentelemetry-ebpf / Inspektor Gadget の紹介
-
How and Why You Should Adopt and Expose OSS Interfaces Like Otel & Prometheus - Daniel Hrabovcak & Shishi Chen, Google
- ベンダーによる標準化された API (OpenTelemetry / OpenMetrics / Prometheus Remote Write / PromQL) の組み込み進んでいないね、Google Cloud はユーザーに Prometheus と OpenTelemetry API を公開していてその苦労話、Managed Prometheus とか Cloud Trace の裏話が聞けるかも
-
On-Demand Systems and Scaled Training Using the JobSet API - Abdullah Gharaibeh, Google & Vanessa Sochat, Lawrence Livermore National Laboratory
- JobSet API を活用した HPC システムのジョブの管理、Vanessa さんの前回の発表も独特で面白かったので楽しみ
-
How CERN Developers Benefit from Kubernetes and CNCF Landscape - Antonio Nappi, CERN
- CERN の中でも重要な Java アプリケーションも Kubernetes 上で動いているらしく、どうやって移行したかや使っている技術スタックの話など
-
Building Better Controllers - John Howard, Google
- Istio のコアメンテナによる Controller の正しい書き方の話、簡単なコントローラーの実装デモもあるらしい
-
On the Right Tack: Kubernetes at Uber Scale - Aditya Bhave, Uber Technologies
- 2023 年に Uber が Mesos + カスタムスケジューラから Kubernetes への移行が結構進み工夫したり苦労した話、動的ポートのサービス検出、イメージの事前フェッチによるデプロイの高速化、スケジューラー周りなどなど
-
Sustainable Scaling of Kubernetes Workloads with in-Place Pod Resize and Predictive AI - Vinay Kulkarni, eBay & Haoran Qiu, UIUC
2023/9/3
-
kubectl rollout restart って対象のリソース名を指定しないとその namespace 内のリソースを全部 restart しちゃうんだ、こわ (k/k#120118)
❯ kind create cluster Creating cluster "kind" ... ✓ Ensuring node image (kindest/node:v1.27.3) 🖼 ✓ Preparing nodes 📦 ✓ Writing configuration 📜 ✓ Starting control-plane 🕹️ ✓ Installing CNI 🔌 ✓ Installing StorageClass 💾 Set kubectl context to "kind-kind" You can now use your cluster with: kubectl cluster-info --context kind-kind Thanks for using kind! 😊 ❯ kubectl version Client Version: v1.28.1 Kustomize Version: v5.0.4-0.20230601165947-6ce0bf390ce3 Server Version: v1.27.3 ❯ kubectl create deployment nginx-1 --image=nginx deployment.apps/nginx-1 created ❯ kubectl create deployment nginx-2 --image=nginx deployment.apps/nginx-2 created ❯ kubectl get pods NAME READY STATUS RESTARTS AGE nginx-1-6d648b45b9-s2fhg 1/1 Running 0 16s nginx-2-dc589d58b-2pfck 1/1 Running 0 14s ❯ kubectl rollout restart deploy deployment.apps/nginx-1 restarted deployment.apps/nginx-2 restarted -
メンテナや関係者に代わって Issue に対して ChatGPT を使って回答してそうな迷惑な人が出てきたな... (comment - k/k#120318)
2023/9/5
- 予定通り DRA は 1.29 でベータ昇格を目指す。ただ、新しい resources API は新しい API なのでデフォルト有効化はされないはず。テストと他のコンポーネントとの連携などなどやることまだあるみたいなので、予定通り 1.29 で昇格できるかは微妙なとこ。この時期の開発サイクルは他と比べて短いし (kubernetes/enhancements#4181)
2023/9/6
- GKE が 1.28 をサポート (release note)
- Sidecar containers 機能が入ったことで initContainer の起動順に関するリグレッションが発生しているが、upstream の方はもう対応済みなので今後のパッチバージョンで取り込まれるはず (k/k#120281)
2023/9/7
- EKS のコントロールプレーンのログが Vended Logs 扱いになって 9 月分から勝手にコスト下がるらしい (aws/containers-roadmap#2056)
- Grafana がパッケージの署名に使う GPG キーの秘密鍵とパスフレーズを Drone CI (?) のログに誤って書き込んで流出させてしまい、やむなく GPG キーのローテーションを行った件の報告。再現性のあるビルドの整備中にサブシェルの中で難読化された秘密情報の扱いで思った挙動にならなくてお漏らししたらしい (blog)
2023/9/8
- sig-etcd が結成間近 (kubernetes/community#7372)
- sig-etcd で開発をやっていくけど、中の人たちは今開発に関わっている人たちだから変わりはなさそう
- Kubernetes 内の etcd 関連の更新プロセスにも関わる予定
- github.com/etcd-io 配下のリポジトリは Kubernetes に寄贈されたリポジトリと同じガバナンスに従う
- Kubernetes との連携部分の安定性の向上などが大きな目的
- etcd を安定した KVS に
- etcd の API の仕様のドキュメント化やテスト
- etcd への大きな変更にも Production Readiness Review のプロセスを通す
- 新しい機能は E2E テストと堅牢性テストを通す
- データ欠損の問題を素早く検知して自動復旧できるように
- etcd の運用を楽に
- 定期的にデフラグ実行しなくて良いように
- オンラインで更新・切り戻しできるように
- etcd と Kubernetes の Disaster Recovery 対応
- 2 台のノードでクラスタ化のサポート
- etcd の実装をよりインフラ構成管理に特化した形に
- etcd のクライアントライブラリに Kubernetes の CSI っぽいインターフェイスを導入して Reconciliation のお約束に従った基本的な機能を提供
- Kubernetes のスケールに大きく影響する watch cache の実装を etcd のクライアントライブラリに移動させる
- Kubernetes のコア部分以外のスケール要件への対応
- etcd を安定した KVS に
2023/9/9
- NetworkPolicy に ingress / egress のフィールドがあるのに policyTypes で Ingress / Egress を指定しないといけないのは、Egress の機能が後から入ったので後方互換性を担保するため。逆に ingress しか使わないなら policyTypes の指定は不要。ただ、egress だけ指定する場合に省略すると、デフォルトで ingress を全て拒否する設定になるので注意 (slack)
2023/9/10
- 今後ライセンスを変更をしないと口先では言っている OSS に、じゃあ CNCF プロジェクトに入って証明してみせてよ!と踏み絵させる未来になるのかな (X)
- CFS 使用時の CPU Burst の設定が今年の初めに OCI のランタイム仕様に入って、数日前に runc で設定できるようになり、次は containerd で設定できるようにする Issue。これが Kubernetes 側でどう設定できるようになるかはまだ議論されていなさそう (containerd/containerd#9078)
- Burstable CFS Bandwidth Controller (スクラップ)
- LWN の The burstable CFS bandwidth controller の記事の日本語訳 (スクラップ)
- OCI のランタイム仕様の PR (opencontainers/runtime-spec#1120)
- runc の実装の PR (opencontainers/runc#3749)
- Alipay の人が GKE の Image Streaming や AWS の SOCI snapshotter を自作しているみたいで、FUSE サーバーをコンテナ化して動かしているみたい (comment - containerd/containerd#5667)
- Image Streaming も SOCI snapshotter もホスト上でプロセスとして動いているはずなので少し違う。最初は DaemonSet で動かしていたけど更新時に FUSE のコネクションの情報 (fd) が飛んでエラーになるから、コントロールプレーン的な役目の DaemonSet を別で用意して FUSE サーバーが再起動した後に fd の情報を返してマウントポイントを復旧させる。ただ、このやり方だと起動が遅れると詰まっちゃうので、FUSE サーバーのコンテナを containerd のソケット経由で直接起動して、DaemonSet の方でこのコンテナを管理する形に変えた。これでも FUSE サーバーの起動が遅いので、FUSE サーバーをキャッシュ (?) して解決したらしい
2023/9/11
- あれ GKE の Alpha clusters 使っても Sidecar Container の機能使えないのか。何でだろう (release note)
- Dataplane v2 を使っている場合に 1.25 から 1.26 に更新すると、ネットワーク周りで問題が起きてサービスに影響出る可能性があるから自動更新停止中。修正予定だから手動でも上げないようにとのこと (release note)
- ClusterAutoscaler の ProvisioningRequest カスタムリソースの追加の AEP (Autoscaler Enhancement Proposal) がマージされてた (kubernetes/autoscaler#5848)
-
ML / HPC 向けに大量のジョブ (Pod) を全て載せられるだけのノードを確保 & 起動できなかった場合にノードをスケールインする
- 今までは必要な台数の Pod が起動できない場合でも中途半端にノードが起動されたまま残り、Pod が全て起動できていないので計算や学習が開始できない
- 無駄にリソースだけを消費する形になってしまい、ユーザーが明示的に Pod を消すまで残り続ける
-
ProvisioningRequest の使い方
- PodTemplate を作成して起動する Pod の設計図を埋め込む
- ProvisioningRequest を作成する
- PodSet (PodTemplate の名前と必要な台数の組み合わせ) を複数指定できるのでこれでグループ化
- ClusterAutoscaler が ProvisioningRequest に従ってノードプールを選択してノードを作成
- ClusterAutoscaler が必要なノードの台数を確保できたら Conditions フィールドに成功した旨が書き込まれる
- ノードが確保できたことを確認して、ユーザーが Pod を Job などで作成すると ClusterAutoscaler が確保したノードに Pod が起動される
- ProvisioningRequest と同一の namespace に作らないとダメ
- Pod が全部起動できたら ProvisioningRequest をユーザーが明示的に削除しても良いし、GC でいずれ削除される
- Pod の実行が完了してノードが不要になったら ClusterAutoscaler がスケールダウンする
-
10 年近い時を超えて道半ばで放棄された PodTemplate が使われようとしている (kubernetes/kubernetes#170)
❯ kubectl apply -f - <<EOF apiVersion: v1 kind: PodTemplate metadata: name: sleep template: metadata: name: sleep spec: containers: - name: sleep image: alpine command: ["/bin/sh"] args: ["-c", "sleep 100"] EOF podtemplate/sleep created ❯ kubectl get podtemplate NAME CONTAINERS IMAGES POD LABELS sleep sleep alpine <none> -
PodTemplate と Job 埋め込みの PodTemplateSpec で Pod の設計図を二重管理しないといけないっぽい
- Helm chart とかコントローラーとかツール側で補完しろみたい
-
2023/9/12
- 9/5 の WG-sidecar の録画がアップロードされたので、サイドカーコンテナ停止順の議論の流れやっと理解できた (youtube)
- TL;DR: NAVER の人が神で助かった
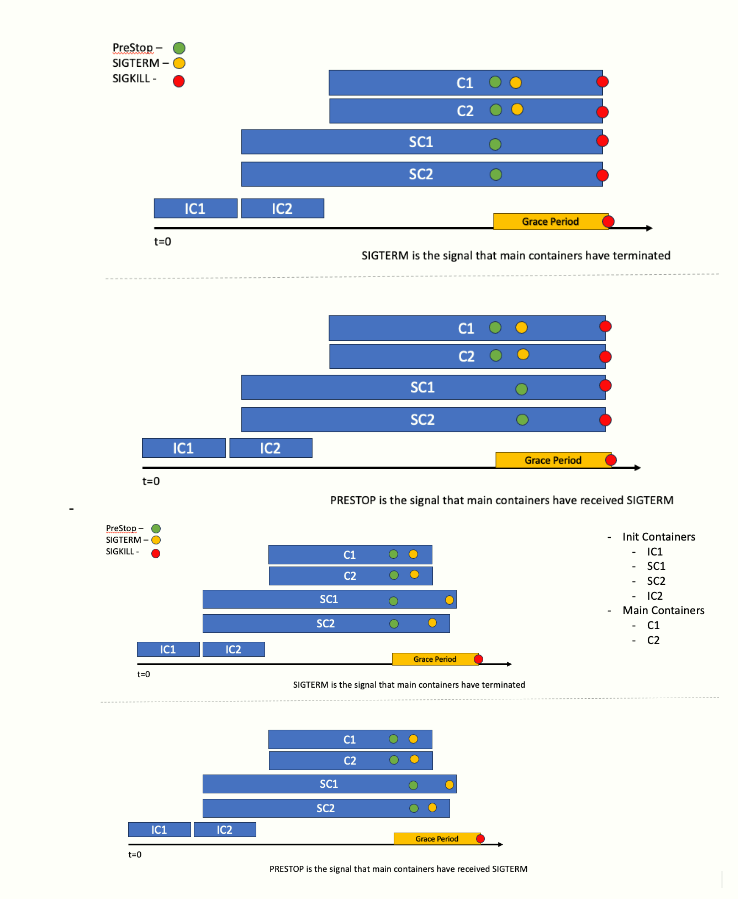
- WG-sidecar の 9/5 のミーティングで以下の図を元にコンテナの停止順を議論
- サイドカーコンテナとしてログ転送のコンテナがいる場合に、メインのコンテナが停止した後にバッファ内のログをフラッシュする必要があるから時間が掛かる
- terminationGracePeriodSeconds の間にメインコンテナとサイドカーコンテナの両方を安全に停止できるの?が焦点
- 図は上から 1. と 3. / 2. と 4. が同じ実装例で、1. と 2. は terminationGracePeriodSeconds 以内に停止処理が終わらなかった時の挙動を示している
- WG-sidecar のメンバーはコンテナの停止処理を勘違いしていて、Pre-Stop Hook と SIGTERM を別物だと思っていた
- 実際は killContainer の中でコンテナ毎に Pre-Stop を実行してから SIGTERM を送るのでひとまとまりな処理
- そのせいで、図の 1. と 3. が直感的で良さそうみたいな結論になっていたけど、NAVER の人だけが反論しようとしてた
- 9/5 のミーティングの後で WG-sidecar のメンバーの一人がサイドカーコンテナの停止順に関する KEP-753 の変更の PR を上げた (kubernetes/enhancements#4183)
- PR の中で terminationGracePeriodSeconds をサイドカーコンテナ毎に指定できるフィールドの追加を採用しないとしている
- terminationGracePeriodSeconds をサイドカーコンテナ毎に何で指定する必要が?って思ってたけど、コンテナ全体で terminationGracePeriodSeconds の時間を共有すると思っていたみたい。で、ログ転送のコンテナは停止に時間が掛かるから〜の話に繋がる
- フィールドの追加を嫌がっているのはこれ以上 API の変更を入れたくないから
- NAVER の人が PR のコメントで再度反論して、Pre-Stop Hook と SIGTERM が同じ処理の中で行われていて、切り離して実装しないといけない 1. と 3. だと大変だと反論 (comment - kubernetes/enhancements#4183)
- terminationGracePeriodSeconds がコンテナ全体で共有される前提で話は進んでいたけど、1. と 3. の実装おかしいかもな雰囲気にはなった
- PR の中で terminationGracePeriodSeconds をサイドカーコンテナ毎に指定できるフィールドの追加を採用しないとしている
- 9/12 のミーティング用に NAVER の人が資料を上げていて、想像していた図が載っていた...!(slide)
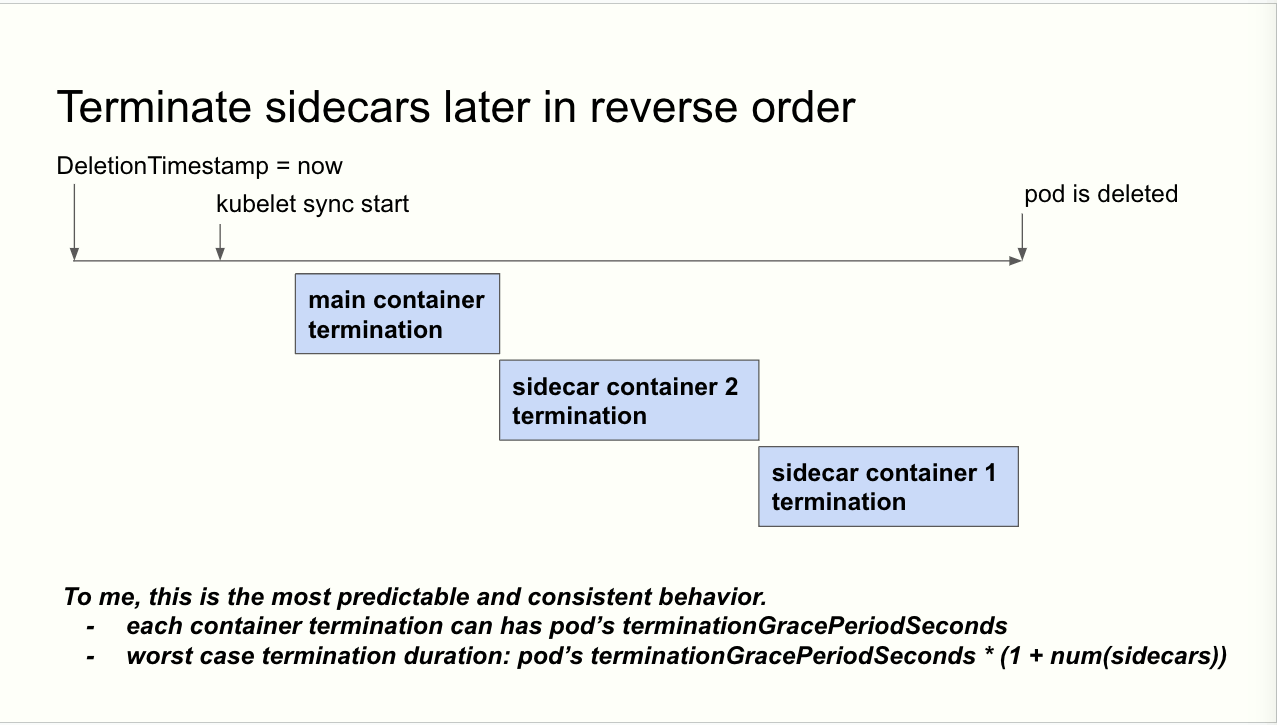
- おそらく KEP-753 の実装が終わったら別の KEP でやれそうなことの案
- Pod レベルで設定した terminationGracePeriodSeconds が全てのコンテナに適用されるので長くしたいケースはあるかも?
- Pod 全体での terminationGracePeriodSeconds の指定必要かな?
- KEP-753 は起動と逆順で停止だけど制御したい要望はある?

- おそらく KEP-753 の実装が終わったら別の KEP でやれそうなことの案
2023/9/13
- Gateway API のロゴ案 (comment - kubernetes-sigs/gateway-api#2202)
- sig-etcd が爆誕 (comment - kubernetes/community#7372)
- Cilium が CNCF Graduation に向けて投票を開始 (twitter)
- あと 3 人で
72.73%を超えてるのでこのまま行けば Graduation しそう
- あと 3 人で
- GKE の Dataplane v2 (Cilium) と ASM が連携 (Cilium Service Mesh?) するのか、単純に netd で ASM 用の追加の CNI の設定を管理するのか (GoogleCloudPlatform/netd#225)
2023/9/14
- 9/12 の WG-sidecar の録画 (youtube)
- メインコンテナとサイドカーコンテナは停止するときに同時に PreStop Hook を実行
- メインコンテナが停止するまではサイドカーコンテナに SIGTERM を送らない
- メインコンテナが停止したらサイドカーコンテナに SIGTERM を送る
- サイドカーコンテナ内での SIGTERM を送る順番は起動順と逆で、前のサイドカーコンテナが停止してから送る
- terminationGracePeriodSeconds の定義だと Pod の停止の猶予時間という説明なので、メインコンテナとサイドカーコンテナ全てが同じ猶予時間を持つのはおかしいかも
- メインコンテナしかいない今の実装だと並列に PreStop Hook を実行していくので、ほぼ同時に terminationGracePeriodSeconds のカウントダウンが始まり、あまり気にしなくて良かった
- 同時に PreStop を送りたい理由は Spot インスタンスだと 30 秒の限られた時間で後処理を全部終わらせないといけなくて、停止準備の処理である PreStop は早めに実行した方が terminationGracePeriodSeconds を無駄に消費しないから
- NAVER の人は不満そうで、上記の実装どうやるのか想像付かないのと PreStop Hook をすぐに実行しちゃったらその後でサイドカーコンテナに問題が起きた場合に再起動できなくなる懸念から。特に terminationPeriodSeconds が 30 分とか長い場合にサイドカーコンテナに問題が起きる可能性は高くなるのどうするのな姿勢
- 制限事項として進めて他の SIG の意見も仰ごうみたいな雰囲気に落ち着いてはいた
- 上記の実装の PR はもう上がっていて、killContainer の中で PreStop Hook は並列に実行しつつ、SIGTERM を送るとこは channel を使って無理やり止めている (k/k#120620)
- terminationGracePeriodSeconds も Pod 全体で共有する形になっていた
- 確かに SIGTERM を受ける順番が保証されてれば良いのかな?停止処理自体は SIGTERM 受けてから発動だろうし。PreStop Hook の中に停止処理を遅らせる以外の処理を書いてるケースあるのかな
- containerd に user namespace (コンテナ内の UID / GID とホスト側の UID / GID のマッピングを変えてコンテナ内で特権でもホスト側で悪さできないようにするやつ) の ID-mapped mount による実装のサポートが入った (containerd/containerd#8287)
- 昨日の Kubernetes 変更内容共有会でも話があったように Kernel >= 6.3 & containerd v2 以降でないと使えないので当分先になりそう
- ID-mapped mount による実装のおかげでステートレスなワークロードだけじゃなくて、ボリュームマウントしているワークロードもサポートするようになっている
- GKE で使ってる COS はまだ COS-105 が最新 LTS (GKE 1.27 で使用) でカーネルのバージョンが 5.15.x (release note)
- 次の COS の LTS 予定の COS-109 がカーネルのバージョン 6.1.x なのでまだまだかかりそう (release note)
2023/9/15
- Kueue と Cluster Autoscaler の ProvisioningRequest の連携を進めていく感じ (kubernetes/autoscaler#6108)
- klog に slog wrapper の実装が普通に入るみたいです。klog が slog に置き換わる訳じゃないのと、klog と slog が共存できたりするらしい。Go 1.21 以降だとデフォルトで使われる? (k/k#120696)
- logr と slogr はやっぱり思想とか API の違いがあるから裏側で良い感じにギャップを埋めてるのかな (link)
- slog は logger のインスタンスを context で渡せないから代わりに Handler を渡していてメモリ使用量増えそうだから Contextual logging の場合は向いてないとかなんとか、よく分からん (go-logr/logr#222)
- ノード上のコンテナイメージを指定した期間使われなかったら GC する機能の KEP (kubernetes/enhancements#4211)
- 今も kubelet がディスク容量の閾値 (デフォルト 85%) を超えると使っていないコンテナイメージを削除する機能がある
- ただ、使ってないコンテナイメージが無駄にディスク容量を占領しがち (e.g. コントロールプレーンの in-place 更新後の古いバージョンのイメージ) なので、消したいらしい
- 数週間に設定するのを想定している。CronJob とか定期実行かつ数週間に 1 回だとイメージ消されちゃって無駄にプルする必要があるかもが懸念
- コンテナイメージ使われてないって何で判断するんだろう。使われなくなった時刻をどう決定するかと kublet が再起動したときにその情報保持できるかは気になる
2023/9/16
- klog に slog wrapper の実装が普通に入るみたいです。klog が slog に置き換わる訳じゃないのと、klog と slog が共存できたりするらしい。Go 1.21 以降だとデフォルトで使われる? (k/k#120696)
- logr と slogr はやっぱり思想とか API の違いがあるから裏側で良い感じにギャップを埋めてるのかな (link)
- slog は logger のインスタンスを context で渡せないから代わりに Handler を渡していてメモリ使用量増えそうだから Contextual logging の場合は向いてないとかなんとか (go-logr/logr#222)
- ノード上のコンテナイメージを指定した期間使われなかったら GC する機能の KEP。今も kubelet がディスク容量の閾値 (デフォルト 85%) を超えると使っていないコンテナイメージを削除する機能がある。ただ、使ってないコンテナイメージが無駄にディスク容量を占領しがち (e.g. コントロールプレーンの in-place 更新後の古いバージョンのイメージ) なので、消したいらしい。数週間に設定するのを想定している。CronJob とか定期実行かつ数週間に 1 回だとイメージ消されちゃって無駄にプルする必要があるかもが懸念 (kubernetes/enhancements#4211)
- コンテナイメージ使われてないって何で判断するんだろう。使われなくなった時刻をどう決定するかと kublet が再起動したときにその情報保持できるかは気になる
- KEP-1287: In-Place Update of Pod Resources の 1.29 リリースサイクルの話 (youtube)
- 今 Owner が不在で進捗がないけど、ユーザーの要望は高いので Owner 探し中
- ByteDance (TikTok) のチームが一時的に Issue に上がってる問題の対応は引き受けてくれるらしい
- Pod の再起動を避けるために、リソース割り当てを変えられる時だけ変えて、変えられない時は何もしない API の要望があるらしい
- VPA 連携とか Windows サポートとか新しい API とかをアルファリリース (e.g. alpha2) で入れられるように動いていく
- 今 Owner が不在で進捗がないけど、ユーザーの要望は高いので Owner 探し中
- ノード上のルートファイルシステムとイメージを置くファイルシステムを別にしたい KEP (kubernetes/enhancements#4198)
- Kubelet が管理しているデータ、コンテナのデータ、コンテナイメージを別々のファイルシステム (ディスク) で管理したい
- e.g. Kubelet やコンテナ内のデータは書き込み可能なディスクに置いて、コンテナイメージは読み取り専用のディスクに置く
- 今はファイルシステムが分かれていないので...
- ディスク (e.g. sda0) に書き込み領域、emptyDir、ログ、読み取り専用領域、ephemeral storage が全部ある
- 一般的にコンテナイメージのサイズがディスク容量を圧迫しがち (e.g. AI / ML 系のイメージでモデル含んでいる場合とか)
- ディスク上のコンテナイメージやコンテナの GC 時 (特にコンテナイメージ) にノードに負荷が掛かる
- 今提案されているのは 3 種類
- ディスク (sda0) にコンテナのデータ (書き込み領域)、emptyDir、ログ、コンテナイメージ (読み取り専用領域)、ephemeral storage が全部ある (今の実装)
- ノードとコンテナのデータ / コンテナイメージの保存先を分ける
- sda0 に emptyDir、ログ、ephemeral storage を置いて、sda1 にコンテナのデータとコンテナイメージを置く
- ファイルシステムの不要なデータの GC の方法が変わる
- sda0 が容量の閾値を超えたら、終了済みの Pod のデータやログを削除
- sda1 が容量の閾値を超えたら、使用していないコンテナイメージとコンテナのデータを削除
- sda1 のディスクが圧迫されると、ノードの状態を Unhealthy に変更して、Pod が新しく起動できないようにする
- 読み取り専用領域を分離する
- sda0: コンテナのデータ、emptyDir、ログ、ephemeral storage を置いて、sda1 にコンテナイメージを置く
- containerd だと snapshotter の実装を変えないといけないので、このケース必要かどうか議論中
- GKE の Image Streaming もこの機能を使いたいので、Google からもレビュアーが出てる
- Kubelet が管理しているデータ、コンテナのデータ、コンテナイメージを別々のファイルシステム (ディスク) で管理したい
2023/9/17
- Job とかで generateName を使ったり、Deployment で Pod を作るとリソース名にランダム文字列が 5 つ付くの、リソース名が衝突したケースが実際にある。衝突すると api-server ではリトライされないので、クライアント側でリトライが必要。衝突しなくなるまで api-server でリトライするは負荷の問題などで現実的じゃない。3 回はリトライするとしても衝突し続ける可能性はあるので、そもそも衝突する可能性を減らしたい。で、ランダム文字列を 5 文字から 10 文字に変える PR が上がっているが、外部のコードで正規表現を使って Deployment から作られた Pod かを判定していたりしているとこが意外とある。そのプロジェクトに Issue を作って注意喚起して止まっている。OpenShift でも衝突の報告があって、api-server でリトライしてくれ要望がまた上がっている (k/k#116430)
-
terminationGracePeriod: 0で作成した StatefulSet / PV マウントした Pod を削除 or--grace-period=0フラグを指定して削除するとデータが壊れる可能性があるので注意。0 秒だとノード上からボリュームを取り外すのを待たずに Pod オブジェクトが削除されてしまう。なので、Kubelet が Pod を削除してボリュームをノードから外すのが間に合わず、StatefulSet Controller が新しい Pod を起動してしまう可能性がある。古い Pod と新しい Pod が同じボリュームを共有してしまうのでデータが壊れる可能性がある。特に Kubelet が一時的に API サーバと接続できない状況だと起こりやすい。Kubelet が API サーバに接続できるようになるまで古い Pod は動き続けてしまい、新しい Pod はその間も動き続けてしまう。terminationGracePeriod: 1だと Kubelet は Pod が停止してノードからボリュームが外れるまでは待つので問題は起きない。(k/k#120671)- StatefulSet に対して
terminationGracePeriod: 0を指定せず、最低でもterminationGracePeriod: 1を指定するように
- StatefulSet に対して
2023/9/18
- 最近の StatefulSet 周りのバグ修正がバグを産む負のスパイラル (comment - k/k#120731)
- 1.27 で Job の再実行を正しく行えるように Pod のライフサイクルに手が加わって影響で SIGTERM を受けて exit code 0 で終了した Pod が再度起動されなくなるバグが StatefulSet で発生
- DaemonSet でも同じバグが起きて修正済み
- StatefulSet で
podManagementPolicy: Parallelの場合に、Pod を並列に作成・削除しないバグの修正-
status.replicasの更新周りのバグが入り、Pod 作成時にすぐにstatus.replicasが正しい値に更新されず最初は小さい値が埋められてしまう -
status.replicasはローリングアップデートの遷移に使われる - パーティションを使っている場合にパーティション番号の小さな Pod が意図せず再起動される問題が発生
-
- 1 つ目の問題を解決するために、exit code 0 で終了した Suceeded な状態の Pod を再起動するように修正
- これにより今度は 2 つ目の問題との合わせ技で StatefulSet の基本的な挙動を確認するテストが Flaky になる
- Pod を再作成するときに間違った revision が使われているみたい
- Pod 再作成時に間違った revision が使われる問題の修正が上がっていて、
status.replicasじゃなくspec.replicasを見てローリングアップデートの完了を判断する方法 -
status.replicasの値が正しくない問題はまだ修正の PR が上がっていない - マージ後にテストやバグ報告で問題が発覚したら、それを引き起こした変更自体を revert するのが基本だから 2 つ目と 3 つ目の変更は revert されることになりそう
- 1 つ目の Pod のライフサイクル周りの変更は sig-node で話し合った結果戻すのもリスクで戻せなかったはず
- 1.27 で Job の再実行を正しく行えるように Pod のライフサイクルに手が加わって影響で SIGTERM を受けて exit code 0 で終了した Pod が再度起動されなくなるバグが StatefulSet で発生
2023/9/22
- カスタムリソースや Dynamic client で JSON シリアライズの代わりに CBOR を使って CPU 効率やデータサイズを改善する KEP (kubernetes/enhancements#4223)
- Kubernetes のコアリソースは Protobuf で効率化できているが、Protobuf はクライアントとサーバーでコンパイル時にスキーマが必要なので、カスタムリソースのように実行時に登録する場合は使えない
- Dynamic client も同様にスキーマレスでリソースを取り扱うための機能なので JSON でシリアライズして頑張ってた
- CBOR はスキーマ不要でシリアライズ可能で、ベンチマーク結果だとカスタムリソースで 8 倍、Dynamic client で 2 倍、エンコード / デコードの処理が高速化できた
- エンコード後のデータの先頭に 0xd9d9f7 の magic number が付くので CBOR と JSON が混ざっていても見分けが付く
- JSON と同様に stream で渡したデータのシリアライズも可能
- JSON Patch や JSON Merge Patch、Strategic Merge Patches などには対応できないと思われる
- 新しいデータ形式を Kubernetes に入れるのはリスクが高いので段階的にやっていく
- ライブラリ何を選ぶかと Go 以外の言語のサポートどうするか問題
- CBOR を選んだ理由は 2013 年からあって成熟しているし、JSON のデータ型を CBOR に変換、その逆も可能なので、やろうと思えばコアリソースでも使えるのと、スキーマ不要なのと、エンコードとデコード処理に掛かる CPU 時間もある程度減らせるから
- あと、シリアライズ後のデータも JSON に比べてコンパクトで、Fuzzer で生成した Pod リソースの簡単なテストでも 20% は削減できた
- 重複したキーを含むデータは CBOR だと不正なデータとして扱われるので JSON の場合と同様に最終的にエラーを返すことになりそう (Protobuf の場合は最後の重複したキーが勝つ)
- 存在しないフィールドをどう扱うかは考えないと、クライアントのバージョンがサーバー側の実装より新しい場合に問題になる
2023/9/23
- KEP-3673 の並列イメージプル数の制限に対して、Pod 内に複数コンテナある場合のイメージプルも並列にダウンロードして欲しいと要望が上がっている (slack)
- 現状の実装だとイメージをプルしてコンテナ起動して、次のイメージをプルしてコンテナ起動してと直列に実行するので変更が必要
- 挙動としては破壊的変更になるので、設定で切り替えられるようにしないといけない
- Pod 単位の設定で挙動を変えられるようにしても、複数のデカいイメージをダウンロードする必要がある Pod が Kubelet の並列ダウンロード数をブロックして他の軽いイメージの Pod の起動を遅らせやすくなる
- Kubelet が Pod を最速で起動できるように賢くコンテナイメージをダウンロードする必要がある
- 要望がどれくらいあるかで、やるにしても今の KEP とは別の KEP にする
- 現状でも Mutating Webhook でその Pod で必要なコンテナイメージの情報を initContainer の環境変数に埋め込んで、特権 + containerd のソケットをマウントした initContainer がイメージをプルするとかはできなくはない
- 同じように特権の DaemonSet で API Server を watch して自身のノードにスケジュールされた Pod がいたら、そのコンテナイメージを containerd のソケット経由で事前に読み込むみたいなのもできるけど、やりたくない (並列数の制限もできなそうなので、複数 Pod あるとノードの負荷が高くなりそう)
- wg-lts の Slack チャンネルに貼られてた。2017 年に Linux kernel の LTS を 2 年から最長 6 年 (通常は 2 年だけど必要なら伸ばす形) に拡張したけど、結果として全ての LTS バージョンで 6 年間サポートする形になり辛くなって、次の LTS バージョンから 2 年間サポートに戻すことになったそう。Kubernetes の LTS も 2 年以内で決めるのが現実的か (link)
2023/9/24
- 2019 年から意図的に Kubernetes のテストを自動でリトライしない (Flaky なテストが埋もれない) ようにしてきたことを、改めてポリシーとして明文化する PR。メーリングリストにも流してるから、最近 Flaky なテストがまた増えてきたから気を付けてねの意味合いがありそう (kubernetes/community#7538)
2023/9/26
- レプリカ数の少ないワークロードや StatefulSet などの状態を持ったワークロード向けの drain に代わるノードのメンテナンス用の API を追加する KEP (kubernetes/enhancements#4213)
- 既存の drain だと、ノードを cordon (Unschedulable) して、Eviction API で PDB を考慮しながらノード上の Pod を移動させ、Graceful Node Shutdown の機能で安全にノードが停止できるように一定時間待ってからノードを停止する
- drain でやっていることはノード上の Pod を全て退避しているだけで、フィルターを使って Demonset やローカルストレージのある Pod を除外することもできる
- アプリケーション開発者がやれることは PDB を設定するだけだが、
minAvailable: 1でmaxUnavailable: 0に設定されたワークロードでレプリカ数が 1 の場合、ノードの drain をブロックしてしまい、クラスタ管理者が手動で介入しないといけない - HPA を設定している場合も、
minReplica: 1かつレプリカ数が 1 の負荷の低い時間帯でもノードの drain をブロックしてしまう - Node Graceful Shutdown の機能を使って一定時間経過した後 (e.g. GKE のスポットインスタンスだと 30 秒) に安全に止めるにしても、アプリケーション開発者が設定した terminationGracePeriodSeconds は考慮されず、クラスタ管理者が設定したクラスタ全体の設定である ShutdownGracePeriod や ShutdownGracePeriodCriticalPods によって決まる
- ステートフルなワークロードだとデータの移行やバッファ内のデータの書き込みの時間が十分になく、データ欠損する可能性がある
- drain を実行した理由などのメタデータを書き込む仕組みがない
- コミュニティで開発されているツールがいくつかある。宣言的に drain を行うための node-maintenance-operator や Kafka / Zookeeper 専用で Eviction リクエストに対する Validating Admission Webhook でブロックしつつ PDB の maxUnavailable を 0 にしてデータの同期を待つ drain-cleaner、KubeVirt も Validating Admission Webhook で Eviction リクエストをブロックして裏側で VM のマイグレーションを実行している
- 最初は kubectl drain の現在の実装ベースの Node Maintenance Controller と NodeMaintenance オブジェクトを実装して (名前は後で変わるかも)、そのあとで上記の問題を解決できるように挙動をかえていく
- NodeMaintenance オブジェクトは最初はシンプルで、対象のノード名と理由を指定可能
- Node Maintenance Controller は NodeMaintenance オブジェクトを見て、対象の Pod の condition に TargetedByNodeMaintenance を指定
- kubectl drain はノードの状態を Unschedulable にした後で NodeMaintenance オブジェクトを作成するように実装が変わり、Pod の所有者のコントローラーが Pod を削除したりマイグレーションしたりする
- Node Maintenance Controller は実行中の Pod の退避の状況を NodeMaintenance オブジェクトのステータスの targetedPods に記録する
- Deployment Controller / ReplicaSet Controller への変更
- Deployment Controller が Pod の TargetedByNodeMaintenance の condition を監視して、Deployment の中の Pod で TargetedByNodeMaintenance のステータスがある数を
.status.ReplicasToDismissに記録する - RollingUpdate の maxSurge に 0 より大きな値が指定されていたら、Deployment Controller が Pod を台数分先に ReplicaSet に指定した台数を増やして起動してから (メンテナンス対象のノードには NoSchedule が指定されているので、必ず別のノードで起動する)、Pod を退避する
- Deployment Controller が Pod の TargetedByNodeMaintenance の condition を監視して、Deployment の中の Pod で TargetedByNodeMaintenance のステータスがある数を
- PDB に新しく maxSurge のフィールドを追加して、値か真偽値を指定できるようにする
- Deployment などを Pod を新規に追加しながら更新 (Surge Upgrade) する場合に、新規に追加された Pod が Eviction API の対象の Pod になる可能性があるので、maxSurge のフィールドを追加して PDB でも maxSurge を考慮できるようにする
-
maxSurge: trueの場合は、Deployment の maxSurge の値か Surge API を参照する -
maxSurge: 1の場合は、Deployment の maxSurge の値や Surge API の値を上書きできる - 値だけで良い気はするので、この辺りは今後の議論で変わりそう
- 新しく Surge API を追加する
- Scale API と同じサブリソース扱いで、Surge の機能をコアリソースや CRD で実装できるようになる
- kubectl drain や Disruption Controller が Surge API のステータスの情報を使って安全に Pod の退避を行えるようになる
- kubectl drain コマンドによるノードの drain 処理 (現在)
- ノードを cordon して Unschedulable 状態にする
- ノード上の Pod 一覧を取得
- mirror Pod (a.k.a. static Pods) や DaemonSet など一部の Pod をフィルターして除外
- 全ての Pod を順番に削除していく
- kubectl drain コマンドによるノードの drain 処理 (提案)
- ノードを cordon して Unschedulable 状態にする
- kubectl が NodeMaintenance オブジェクトを作成
- Node Maintenance Controller が NodeMaintenance オブジェクトを監視して諸々対象の Pod をフィルターして TargetByNodeMaintenance の condition を全ての Pod に付与
- Deployment Controller などの Pod の所有者の Controller が Pod を監視し、TargetByNodeMaintenance の condition が付与された場合に、Deployment などの Surge の設定を参考に別のノードに新しく Pod を作成
- Deployment Controller は Pod が Ready 状態になったら、メンテナンス対象のノード上にある Pod を削除
- mirror Pod (a.k.a. static Pods) や DaemonSet など一部の Pod をフィルターして除外
- Surge API の実装のないそれ以外の Pod をこれまで同様に Eviction API を使って移動
2023/9/27
- sig-network の長らく不在 (Chair と兼任) だった Technical Lead に Dan Winship さんがなりそう。kube-proxy の iptables / conntrack 周りは必ずと言ってもいいほど Dan さんが絡んでるし、最近だと誰も触りたくない iptables のルールの整理 (一部 Kubelet が作ってる iptables のルールがあってそれの削除) とかパフォーマンス改善 (全部のルールを restore して置き換えずに部分的にやるやつ) やってたり、kube-proxy の新しい nftables / nft モードの実装も予定していたり (mailing list)
- KEP-127: User Namespaces (コンテナ内とホスト上で UID / GID のマッピングを変えて特権コンテナがホストを掌握したりできなくするやつ) のベータ昇格はユーザーのフィードバックをもう少し貰いたいということで 1.30 になりそう。そもそも ID-mapped mount が Kernel >= 6.3 だったり、containerd も 2.0 が必要 (正式リリースまではまだまだ掛かりそう) なので仕方ない感じ。CRI-O はもう使えるっぽい? (slack)
- EKS 1.28 は GKE 1.28 から 3 週間遅れか。initContainers やスケリューラーのリグレッションとか結構クリティカルなのがあったので、その修正を待ってからな感じかな (blog)
- KEP-2008: Forensic Container Checkpointing でコンテナのスナップショットを作成する機能を kubectl に追加する PR。kubelet のスナップショットを取得する API を呼び出すだけなので、スナップショット自体はホスト上に root ユーザー以外がさわれない形で保存される。ダンプしたメモリページをファイルシステム上に保存するので、機密情報も含まれてるからこれを kubectl でローカルに持ってくるとか移動させるとかはセキュリティの観点から無理そう (k/k#120898)
2023/9/30
- CRD のフィールドの検証を Validating Admission Webhook じゃなくて CEL でやる時の辛み (comment - kubernetes/enhancements#4163)
- Gateway API の CRD には ParentRefs でリソースを参照する仕組みがあって、ParentsRef で複数の同じリソースを参照している場合にそれぞれが重複していないことを検証しないといけない
- 一意であることを識別するために、特定のフィールド (e.g. sectionname や port) が設定されていることを検証
- 一意であることを識別するために、特定のフィールド (e.g. sectionname や port) の値が重複していないことを検証
- 上記の 2 つのルールを個別に指定する必要があって複雑になる
- CEL のルールを 1 行に詰め込まないといけないため、可読性が下がる
- 1 つのルールを複数行に改行して書けるようになる予定
- CEL のルールの中にコメントを残せないので、ロジックを説明することが難しい
- Gateway API の場合は移行前の Validating Admission Webhook の PR にロジックの説明が書かれていたので何とかなった
- CEL Playground は素晴らしいが、操作を間違って作業内容が飛ぶなど荒削りな部分がある
- CEL の仕様書を結構読み込んだが、複雑なルールの例などはないので、どこか別の場所でも良いのであると便利そう
- 期待通りに動いてそうなルールができたら、それを手作業で 1 行にして CRD のコメントに書いた
- これも複数行に改行して書けるようになると解決しそう
- テストを実行してルールが正しく動作しているか検証するために、変更した CRD をクラスタにデプロイして、マニフェストを適用してみて見てみるしかなかった
- CRD の検証ルールを確認するのが結構面倒
- 結果として、Go で検証のロジックを実装するより 10 倍くらいの時間が掛かった
- CEL の開発者も交えて改善点の洗い出しと共有ができたので、今後徐々に改善はしていきそう?
- Gateway API の CRD には ParentRefs でリソースを参照する仕組みがあって、ParentsRef で複数の同じリソースを参照している場合にそれぞれが重複していないことを検証しないといけない
2023/10/1
- Cluster Autoscaler と Dynamic Resource Allocation (DRA) の連携 (k/k#120936, kubernetes/autoscaler#6163, slack)
- これまでは Cluster Autoscaler が Pending 状態の Pod をスケジュールするノードを作成するために、Cluster Autoscaler が持つ情報 (ノードとノード上の Pod) を使うだけで良かった
- Pod のスケジュールサイクルの中でノード上に動的にリソースを割り当てる (e.g. DRA の遅延割り当て) 場合は、Cluster Autoscaler に他の情報を渡す必要がある
- Cluster Autoscaler がスケジューリングサイクルの中で動的に割り当てられたリソースの情報を使えるように scheduler-plugin にインターフェイスを追加
- クラスタの現在の状態のスナップショットを取得し、ノードを追加することで Pending 状態の Pod をスケジュールできるかシミュレートする
- Pending 状態の Pod がシミュレートの中で作ったノードにスケジュールできるか判断するために、scheduler と同じ PreFilter / Filter plugin を使用する (Reserve / Bind plugin は使用しない)
- クラスタの状態を変更する plugin はスケジューリングの結果を記録する必要があって、これを新しいインターフェイスである ClusterAutoscalerPlugin で実装する
- Cluster Autoscaler の処理の流れ
- 起動時に plugin の初期化と Informer の起動
- シミュレーションの開始時に StartSimulation (ClusterAutoscalerPlugin インターフェイス) を呼び出し、クラスタの状態を CycleState に記録できるように一緒に渡す
- Pending 状態の Pod に対して、StartSimulation に渡したのと同じ CycleState を渡して PreFilter / Filter plugin を呼び出す
- その後で SimulateBindPod (ClusterAutoscalerPlugin インターフェイス) を呼び出して、StartSimulation に渡したのと同じ CycleState を渡す
- PreFilter / Filter plugin で修正された CycleState を渡さないのは、SimulateBindPod の中で CycleState 内の最終決定された結果を記録したいため?
- ClusterAutoscalerPlugin の処理の流れ
- StartSimulation が呼び出されると、必要なクラスタの状態のスナップショットを取得して、CycleState に格納する
- CycleState に格納された情報を見ることで、他の scheduler-plugin の拡張点も Cluster Autoscaler が関わっていることが分かるようになる
- PreFilter と Filter plugin を実行する時は通常のクラスタの状態を使わずに、StartSimulation で取得したクラスタの状態を使ってスケジュールできるか判断する
- SimulateBindPod で CycleState 内にあるクラスタの状態のスナップショットを更新する
- DRA の scheduler-plugin にも実装が必要で準備はできているが、まだ PR 化していない
- DRA plugin は ResourceClaim の状態のスナップショットを CycleState に保存し、ノードに割り当てられた ResourceClaim がこの Pod のために使えるかを確認する感じ
- 現状の実装だとベンダー固有の拡張処理があると面倒で、DRA のインターフェイスを満たした Plugin を公開して、CA 側で import してビルドする形になる
- Fake Driver + GKE で動作確認した結果
- 前提条件として Fake Driver はノード毎に 2 つの ResourceClaim をサポートしていて、特別なラベルを持つノードのみをサポート
- GKE 上にデフォルトのノードプールと特別なラベルの付いたノードプール (最初は 0 台) を用意した
- 見割り当ての ResourceClaim を 1 つ使用する Pod を作成するパターン
- Cluster Autoscaler が特別なラベルの付いたノードプールをスケールするのが正しい動きで、今回の修正があると想定通りに動作した
- 今回の修正がないと Cluster Autoscaler は Pending 状態の Pod をスケジュールできないと判断できず、特別なラベルの付いたノードプールをスケールアウトしなかった
- 見割り当ての ResourceClaim を 1 つ使用する Pod が 3 台ある場合も、Cluster Autoscaler は特別なラベルの付いたノードプールからノードを 2 台起動できた
- 3 つの Pod が同一の ResourceClaim を参照している場合も、1 つのノードだけを起動する (2 つノードは不要) だけで良く正しく動作した
- 同一の ResourceClaim を参照する Pod を 3 つずつ 3 セット作成する場合は、Cluster Autoscaler の一度のスケールアウトでノードが 2 台追加される想定だが、なぜか 1 度目のスケールアウトで 1 台のノードしか追加されず 2 回すケールアウトが必要になっていて現在調査中
- DRA は 1.29 でベータ昇格を目指しているが、新しい API (e.g. ResourceClaim, ResourceClass, ...) は GA するまでデフォルトで有効化されないので、Cluster Autoscaler に 1.29 でインターフェイスを実装しても、デフォルトで有効化されて使われるようになるのは GA 以降になる
2023/10/3
- Regular / Sidecar containers で停止処理に入る (PreStop Hook 中や SIGTERM の処理中) とその後は何が起きてもコンテナは再起動しなくなる仕様になる予定だった。PreStop Hook の処理の中で自分自身のプロセスを停止した場合と問題が起きて停止した場合とで区別がつかないから。だけど、Agones (Kubernetes 上で GameServer を管理) だと、ゲームの仕様によって terminationGracefulPeriodSeconds を 1 時間とか長くして、マルチプレイの試合が終わるまで GameServer の Pod が停止しないようにすることがよくある。なので、Agones の開発者を議論に召喚してみたら、Sidecar container の KEP のことを知らなかったみたいで、確かに Agones だと問題になるねって賛同してくれた。今までは Tim が長時間掛かる terminationGracePeriodSeconds の影響 (停止処理中にログ収集のエージェントが異常終了したらそれ以降 Regular containers のログが欠損する) を指摘していたけど、Agones のユースケースがそこに加わったので、明日の WG-sidecar のミーティングに Tim と Agones の開発者を呼んでお話しすることになった。1.29 で Sidecar containers はベータに昇格予定だったけど、この辺りちゃんと考えてから進めないと、後で変えるの大変になるから良かった。結論がどうなるかはわからないけど、橋渡しして良かった (kubernetes/enhancements#4183)
- WG-sidecar のミーティングに向けたまとめ (kubernetes/enhancements#4183)
- preStop Hook は Sidecar container の起動順とは逆に並列に実行
- Sidecar container の停止処理が始まると、
restartPolicy: OnFailureと同じ挙動になる。exit code が 0 で終了した場合は再起動しない。それ以外の場合はそのコンテナを再起動して、起動後にすぐに PreStop Hook の処理に入る - PreStop Hook と SIGTERM の間には完了の意味に違いがあること、Regular container とも違うことを明文化する
- WG-sidecar のミーティングに向けたまとめ (kubernetes/enhancements#4183)
2023/10/5
- GKE 1.28 のアルファクラスターで Sidecar containers の機能が最初に使えなかったの、GKE コントロールプレーンにいる Mutating Admission Webhook のせいか。1.28 の新しい API の型定義で Webhook をコンパイルし直さないと initContainers に新しく追加された restartPolicy が解釈できなくて、書き換える時にフィールドが握り潰されちゃって Sidecar container として起動できなくなっちゃう。多分 PodReadinessGate を差し込むやつかな
- 1.29 で Sidecar containers がベータに昇格するとデフォルトで有効化されるから懸念しているみたい。アルファに一年居座ると 1.28 以降で再コンパイルした Webhook が増えるけど、完璧に防げるわけじゃないから悩ましい。Production Readiness Review でこの懸念が問題なければベータに行く感じか
- GKE 1.28 以上なので影響あるところはないと思いますが、COS ベースのノードを使っていると systemd で指定している logrotate のパスが間違っているせいで動かず、ディスク容量が枯渇してノードが異常状態になって自動回復の機能でノードが drain されて再作成されるみたいなのを繰り返すらしいので上げない方が良いですね (release note)
2023/10/6
- Linux Foundation が BastionZero と Docker と共同で OpenPubKey を発表して、コンテナイメージの署名をクライアントサイドだけでやれるようになる (Docker CLI に組み込まれる) らしく、Sigstore のようにサーバーサイドのコンポーネントが不要でお手軽になるのではと言われている。ただ、Sigstore にサーバーサイドのコンポーネントがいるのも理由があって、そのお気持ちのブログ記事。OpenPubKey は署名された鍵の有効性をクライアントサイドだけでどう担保するのか、生の JWT OIDC トークンを使うのでユーザーの不要な情報まで公開することになるなど (blog)
- Sidecar containers は KEP フリーズに間に合ってベータ昇格も OK を貰ったので 1.29 でベータ昇格予定。ベータでデフォルト有効になるので使えるようになります。(comment - kubernetes/enhancements#753)
- ただ、この時期の開発サイクルは短くてコードフリーズまで 1 ヶ月ない (11/1 予定) ので予定通りベータに昇格できるかはまだ分からないです
- Tekton を CNCF に寄贈する動きが (google groups)
2023/10/8
- StatefulSet で podManagementPolicy を Parallel に設定して数の多い replicas (e.g. 100) で作成すると、kube-controller-manager (KCM) がクラッシュする問題。並列で Pod を作成する時に PVC の情報を取得して、ロックを掛けずにラベルを更新している箇所があってそれが原因らしい (k/k#121053)
2023/10/9
- WIP だけど kube-proxy の nftables モードの実装。iptables の実装をベースに nftables に置き換えているのと、iptables 特有の hacky な実装を取り除いている (k/k#121046)
- nftables の操作を nft で行うための wrapper ライブラリ (danwinship/nftables)
- コンテナ名や Pod 名のラベルはカーディナリティの問題で含められないけど、コンテナや Pod の起動時間のメトリクスの追加
- namespace 毎の initContainers / containers / ephemeral containers のコンテナの起動時間のメトリクスで、ノード / namespace 単位でコンテナの起動時間が遅い奴がいないか、Pod の起動時間が遅い原因がどの種類のコンテナの起動時間に影響を受けているか (k/k#120580)
- 現状の Pod の起動時間のメトリクス (
pod_start_sli_duration_seconds) はコンテナイメージのプル時間を除外しているので、それも含めた Pod の全体の起動時間のメトリクスを追加 (k/k#121041)
- Topology Aware Routing でゾーン内のノードの CPU 数の合計で補正されない & 同一ゾーンに Endpoint が存在しないとクラスタ全体にフォールバックする PreferZone のコントロールプレーン側 (EndpointSlice controller) の実装。kube-proxy とか Cilium にこれらの情報を使うよう修正が必要 (k/k#121060)
2023/10/11
- HTTP/2 の Rapid Reset の DOS の kube-apirserver の対応 (k/k#121120)
- エラーが起きた時にロックの中で sleep しているのは詰まる原因になるのでやめている
- 匿名ユーザーのコネクションが残らないように切断しようとしている
- ヘッダーで
Connection: closeってことは Keep-Alive を無効化しているだけ?
- ヘッダーで
- Go の net パッケージの修正と合わせてクライアントが早期に reset したであろうコネクションを切断
- タイムアウトを過ぎていないのに reset されたかで判断
- PR は FeatureGate で ON/OFF できるようにして速攻でマージされてました。Header に
Connection: closeって書き込んでたの Go 固有の挙動で、HTTP/1 と同じ挙動を HTTP/2 でもできるようにしていて HTTP/2 の GOAWAY フレームを送信して切断できるようになっているらしい (commit) - Security Bulletin でも紹介されていて現状だと Authorized Network で IP 制限してねしか回避策がないから、この感じ GKE にも上の修正を Kubernetes のリリース待たずに速攻で cherry-pick しそう (security bulletins)
- Go 側の修正で最大ストリーム数を 100 に制限しているが、認証ユーザーの場合、その制限に達するまでにメモリ使用量が高騰するのは避けられないので Go の upstream にも報告して対策考えるっぽい (k/k#121197)
- 各 API グループのリソースのバージョンが Kubernetes のバージョン毎に並んでいて便利 (X)
2023/10/12
- Cilium が CNCF Graduated に到達 (cncf/landscape#3554)
- netd の CNI の設定ファイルを作るのに必要なノードの情報を API サーバー経由で取ってきたりするのに使っている curl がどんどんスリムになっていく (GoogleCloudPlatform/netd#232)
2023/10/14
- EKS の Managed Node Group のバージョンスキューが 1 バージョンだけだった制限が 1.23 を境に消えた感じか。1.28 からかと思ったら、それ以前のバージョンもコントロールプレーンと 2 バージョンまで離れても大丈夫になったみたい。そもそも何の制約でこうなってたんだろう (comment - aws/containers-roadmap#1473)
- PodTopologySpread でドメイン (e.g. ゾーン、Spot or On-Demand, ...) 毎に重み付けして分散させる機能の提案 (k/k#121211)
- DB が特定のゾーンにいるのでレイテンシ悪化を避けるために 70% を特定のゾーンに、ゾーン障害の影響を避けるために残りの 30% を他のゾーンに配置したい
- ゾーン障害で DB も死にそうだけど master が特定のゾーンにいてフェイルオーバーはできるってケースなのかな?
- On-Demand のインスタンスに 70% で Spot インスタンスに 30% の Pod を配置したい
- KEP-3990 で PodTopologySpread にフォールバックする仕組みを追加する予定でそれも併用したい
- 古いノードに 90% で新しいノードに 10% で徐々に新しいノードにワークロードを移行したい
- メルカリさんだから GKE 更新の話とかかな?
- 現状以下のいずれかの方法で対策できるが運用コストが高くなるので何とかしたい
- Deployment と HPA をそれぞれのドメイン毎に作成する
- これはよくあるやつ
- 同じ Deployment を使うけど Mutating Admission Webhook を使ってノード毎の Pod の数を計算して動的に NodeAffinity を差し込む + descheduling の仕組みも必要
- descheduling の仕組みは Descheduler とは別で実装が必要そうな
- Deployment と HPA をそれぞれのドメイン毎に作成する
- Karpenter は On-Demand / Spot の割合の指定をサポートしていて、ノードのラベルに
capacity-spread的なラベルを指定して、Spot 用の Provisioner で2,3,4,5の値を指定して、On-Demand 用の Provisioner で1の値を指定することで、Spot を 80% で On-Demand を 20% で Pod が配置されるようにしている。仮想的なドメインって呼んでるっぽい (comment - k/k#121211)
- DB が特定のゾーンにいるのでレイテンシ悪化を避けるために 70% を特定のゾーンに、ゾーン障害の影響を避けるために残りの 30% を他のゾーンに配置したい
2023/10/15
-
1.30 以降になるけど、kubectl debug の事前定義のプロファイルをカスタマイズする機能の KEP。 JSON ファイルに ContainerSpec の変更したい箇所を記載して、
kubectl debug —custom <path/to/json>で渡すと指定したプロファイルで生成した PodSpec の ContainerSpec に StrategicMergePatch で JSON ファイルで指定した変更を加えてから Pod を作成する (k/k#4293) -
新しいコンテナの種類 (e.g. Ephemeral containers) を subresource として追加したのとその権限を組み込みの ClusterRole である admin とか edit に付与していないのには意味がある (comment - k/k#121217)
- 古いバージョンの admission-plugins とか Security Policy は新しいコンテナの種類のフィールドのことを知らないので握り潰してバイパスできてしまうので、subresource 化 + 組み込みの ClusterRole に権限を追加しない方針
- 組み込みの admin とか edit には Aggregated ClusterRoles が設定されているので、権限を追加したい場合は
rbac.authorization.k8s.io/aggregate-to-admin: "true"やrbac.authorization.k8s.io/aggregate-to-edit: "true"のラベルを付与した ClusterRole を作って必要な権限を付与するだけで良い
❯ kubectl get clusterrole admin -ojsonpath='{.aggregationRule.clusterRoleSelectors[0].matchLabels}' {"rbac.authorization.k8s.io/aggregate-to-admin":"true"} -
アルファ機能として追加されていた ClusterCIDR の API が Kubernetes 1.29 でアルファの段階で削除される (k/k#121229, mailing list)
- 元々は kube-controller-manager の中に nodeipam-controller でクラスタ作成後に Pod に割り当てる IP 範囲を拡張できるように追加された
- NodeIPAM の機能は kube-cloud-controller-manager や CNI plugin として実装して使っているところが多く、nodeipam-controller で改善しても GKE 以外で恩恵がない。それだけじゃなく、バグの温床にもなり得る
- 例えば flannel は iptables のルールを作るために Pod IP の範囲かそうでないかを把握する必要があって、 nodeipam-controller で PodCIDR の範囲を変えるだけだとダメ
- flannel 自体が Pod IP の範囲を知れるように ClusterCIDR を読み取る機能が実装されているが、ClusterCIDR の意図した使い方じゃない
- flannel も次のリリースでフラグ (と実装も?) 消す予定 (flannel-io/flannel#1564)
- flannel 自体が Pod IP の範囲を知れるように ClusterCIDR を読み取る機能が実装されているが、ClusterCIDR の意図した使い方じゃない
- 今後は out-of-tree でカスタムリソースとして開発を進めて、NodeIPAM 周り含めてどうするのがみんなにとって幸せかを模索していくらしい
2023/10/17
- PreStop / PostStart hook に sleep の action を追加する PR がマージされました。このまま問題なければ 1.29 でアルファ機能として入りそう (k/k#119026)
- CNI 1.1 の GC のコマンド追加の実装がマージされていました (containernetworking/cni#1022)
- CNI の plugin を chain として複数実行していく中で途中で問題が起きた時にこれまでの変更を切り戻す
- Pod の network namespace が削除ずみだけど、CNI plugin の実装のバグなどで仮想 NIC とか FIrewall ルールとかが残っているのを定期的にお掃除
- ノードが再起動した直後に再起動直前の設定をお掃除してやり直す
- 予定通り Gateway API の v1 リリースの準備が進んでいて、KubeCon 2023 NA までに正式リリースされるはず (release notes)
- ゾーン毎や Spot / On-Demand で Deployment を分割したときに良い感じに Pod の数や配置を調整してくれる Balancer っていうカスタムリソースが sig-autoscaling で開発されてたらしい。scale subresource に対応しているから HPA とも併用できる (Balancer)
2023/10/19
- MS が公開した Open Application Model (OAM) をさらに抽象化したような、開発者がどのプラットフォームにでもアプリを良い感じに楽にデプロイできるツール。Azure の Bicep 言語で書いたりでこれはこれで癖ありそう (X)
2023/10/20
- Forensic Container Checkpointing でデバッグ以外のユースケースもカバーしてから 1.30 以降でベータ昇格を目指す感じかな。どこまでやるかによるけど、まだ時間は掛かりそう (kubernetes/enhancements#4305)
- 起動処理に時間がかかるアプリで起動直後にチェックポイントを取得しておいて、それ以外のコンテナはメモリページを元の場所に戻すだけで良くなるので、コンテナの起動を高速化できる (すでに本番利用されている)
- コンテナのライブマイグレーション。HPC 領域だとハードウェアの故障の予兆検知して移動させる研究はよくある。Google はノードのリソース不足で優先度の低い状態を持ったジョブを停止せずに移動させている。AI / ML の学習でも使える。Spot インスタンスを利用している場合に、停止シグナルか定期取得か分からないけど、チェックポイントを取得しておけば限られた時間でも別のノードに再起動なしで移動できる。
- スケジューラーと協調してチェックポイントの作成や別ノードへのアーカイブの転送を良い感じに自動化してやってくれたらユーザー体験が抜群に良くなるけど、先の話か別の KEP でやることになりそう
- KEP-4188: local pods information は 1.29 で機能は入らなそう (comment - kubernetes/enhancements#4188)
- 1.26 から Pod Disruption Condition (Job が再試行できるかを判断するために停止理由を condition に追加) がデフォルト有効になった影響で、環境変数やポートのリストに重複キーがある Pod が消えない問題の修正 (k/k#121103)
- Client Side Apply (重複時にエラーにならない) で重複した環境変数やポート番号を持つマニフェストを反映したあとで、Pod GC がステータスの更新に Server Side Apply (リストの種類が map 扱いなので重複時にエラーになる) を使っていたせいでエラーになって掃除できない
- 単純に Client Side Apply でエラーにすると既存のマニフェストが反映できなくなるので破壊的変更になるので無理
- Server Side Apply のリストの扱い方を重複を許可する (atomic) ように変更すると、リストの要素を全て読んでから変更を加える必要が出てくるので、複数のコントローラーが変更を加えるケースでコントローラーの実装によっては壊れる可能性があるので難しい
- PodGC controller は condition を追加する SSA に重複エラーで失敗した時にその Pod に condition を追加せずに Pod を削除する道もあるが、この問題は PodGC controller 以外 (e.g. Taint manager, scheduler の preemption) でも起こり得るので、そちらでの対応が難しい (単純に失敗したら Pod を消すという話では済まない)
- そもそもサーバーからのエラーがステータスコード 500 が返ってくるだけで理由も分からないので上記のやり方ができない
- 既存のユーザーに影響がないように修正するの大変で結局 controller で status の更新を SSA でやってる部分を Strategic Merge Patch / Patch に変更することで一時的に対応
- 根本解決はリストの種類が map で変更を Server Side Apply する時に賢く反映できる方法を考える (kubernetes-sigs/structured-merge-diff#234)
2023/10/23
-
COS-109 でインスタンス停止時に dbus に問題が起きて停止シグナルを送れず、Node Graceful Shutdown が期待通り動かない問題。dbus 再起動すると接続がタイムアウトするようになる。systemd の問題か COS の問題か切り分けて、GKE で COS-109 を使うようになるまでには修正入るはず (k/k#121124)
- COS の問題じゃなくて dbus の再起動がそもそも推奨されていなかった。dbus 再起動後に dbus に依存したコンポーネントが自動的に再接続する訳ではない。Debian 系のディストリビューションだと dbus の再起動後に依存しているコンポーネントを再起動しているので問題にならない。
- 結論としては dbus の再起動する処理をテストから削除
-
まだプレビューだけど、GKE の Managed Prometheus 用にマネージド kube-state-metrics が使えるようになっている。収集するメトリクスは絞られていて、ノードのメトリクスがないのとラベルも有効になっているか怪しいので、ゾーン毎のアプリのリソース使用量とかレイテンシ比較に使うのは無理そう (doc
This package of kube state metrics includes metrics for Pods, Deployments, StatefulSets, DaemonSets, Horizontal Pod Autoscalers, Persistent Volumes, and Persistent Volume Claims.
-
一年先までで GKE で使うインスタンスを予約&自動起動する機能がプレビュー。最短でも 24 時間は利用しないといけなくて、予約時点で課金じゃなく利用開始から利用終了までの課金。N1 / N2 / N2D は最低 14 日利用が推奨されていて、その期間に近い方が承認されやすい。Google 側が 7 日以内に予約を承認するか断るか決める。利用開始の 8 週間前になると予約をキャンセルできなくなる。2 週間前までは開始時の変更が可能。期間やインスタンスのスペックなどの変更は Google の承認が必要で、1 週間以内に返答がある。(doc)
2023/10/26
- KEP-4210: ImageMaximumGCAge の PR がマージされて、kubelet の設定ファイルで imageMaximumGCAge に指定した期間イメージが使われていないと削除される。デフォルトは 0s で無効。イメージの GC が必要かのチェックはディスク容量の圧迫の場合と同じで 5 分。削除対象に CRI の API でピン留めされている Sandbox container (e.g. pause container) は含まれない。containerd だと pause のコンテナイメージは自動的にピン留めされるので消えない。このまま問題なければ 1.29 でアルファ機能として入る。FeatureGate で守られているので、有効化が必要。(k/k#121275)
- エッジケースだけど、ピン留めされていない Sandbox container がある場合、kubelet がコンテナランタイム経由でコンテナの一覧を取得しても pause コンテナが見えないので今後検討予定っぽい。
- コンテナイメージを使っているかはコンテナランタイム経由でコンテナイメージと起動中のコンテナ一覧を取得して付き合わせている
2023/10/27
- KEP-3939: PodReplacementPolicy をベータ昇格する PR がマージ。Job は evict されたりエラー終了するなどで停止処理に入るとすぐに新しい Pod を作るようになっていた。ML 系の Tensorflow や JAX だと IndexedJob の機能を使って、Pod に番号を振って (StatefulSet と同じ) その情報を使って担当のデータセットを並列処理したりする。まだ完全に停止していない状態で新しい Pod が起動しちゃうと Pod の番号が +1 されて変わっちゃうので、エラーになってしまう。Job のフィールドに新しく PodReplacementPolicy が追加され、Pod が完全に停止して Job の状態が Failed まで遷移するのを待ってから新しく Pod を作るポリシーを指定可能。デフォルト値は PodFailurePolicy の設定によって変わる。(k/k#121491)
2023/10/28
- KubeCon 2023 NA の Contributor Summit の Unconference の議題に controller-manager (KCM) 内のコントローラー群を HA 構成にする方法を議論したいっていうのがあって面白そう。Lease によるリーダー選出だと KCM 単位なので、その中のコントローラー群はコントロールプレーンのノードに分散配置できないとか、HA 構成のコントロールプレーンを更新するときにリーダーに選ばれる KCM が更新前後でフリップしちゃうから何とかしたい (comment - kubernetes/community#7531)
2023/10/29
- Kubernetes でもコミットにバイナリを含んだ状態でマージしちゃうことがある。過去を改変したいけど、開発者のローカル環境が壊れるので難しい。今後フルでプルする場合はこのバイナリが含まれるという十字架を背負うことに。今後は Linter などを実行している諸々チェック用のスクリプトに、ソースコード以外のファイル形式で数 MB のファイルの追加を検知したらエラー終了するなどのチェックを追加する予定 (k/k#121544)
- 過去にもあったらしい (comment - k/k#121440)
- kublet に Pod の起動時間 (イメージのプル時間を含む) のメトリクスも追加された。イメージのプル時間を含まないメトリクスは既にマージ済み。カーディナリティの関係で Pod 毎に起動時間が分かるわけではないけど、特定のノードで起動時間が掛かっているなとか、起動に時間のかかっているコンテナがいるなは分かりそう (k/k#121041)
- Pod 内のコンテナの image フィールドは更新可能なので、Sidecar コンテナを導入する上で変更した時の挙動を確認するテストを追加する話。Sidecar コンテナはやっぱり奥が深い (k/k#121333)
- Pod の image フィールドは mutable なので、起動後に変更が可能 (他にも activeDeadlineSeconds, tolerations が設定されている場合にキーの追加, terminationGracePeriodSeconds が負の値の場合に 1 に変更可能)
- terminationGracePeriodSeconds に関しては、k/k#98866 で負の値を設定した場合に 1 に解釈されるようになったため、既存の動作中の Pod で負の値を指定している場合に限り 1 に変更できるようにしている
-
The Pod "ubuntu-sleep" is invalid: spec: Forbidden: pod updates may not change fields other than
spec.containers[*].image,spec.initContainers[*].image,spec.activeDeadlineSeconds,spec.tolerations(only additions to existing tolerations),spec.terminationGracePeriodSeconds(allow it to be set to 1 if it was previously negative)
- Pod が初期化状態 (Initializing) の場合、例えば Init コンテナの実行中に Regular / Sidecar コンテナの image フィールを更新すると更新された image で起動
- コンテナの再起動は発生しない
- 1.28 時点で同様の挙動
- PodInitializing 状態を過ぎると Regular コンテナは古いイメージでまずは起動し、裏側で新しいイメージのプルを実行して完了したらコンテナを再起動して更新
- Sidecar コンテナは Init コンテナと同じフィールドを使っていて特に変更はまだ入っていないので、1.28 時点ではイメージが更新されないので修正が必要
- Pod が Terminating 状態で Regular コンテナのイメージを更新しても Regular コンテナのイメージは更新されない
- Regular コンテナが再起動されないので、PreStop hook が設定されていても実行されない
- Pod が Terminating 状態で Sidecar コンテナのイメージを更新すると、Sidecar コンテナは再起動して更新した image で起動
- Sidecar container は Init containers 扱いなので 1.28 時点ではイメージが更新されないので修正が必要
- Sidecar コンテナという概念を追加したため、
- Regular コンテナが停止中に Sidecar コンテナのイメージを更新したいケースはあるかもしれない
- Sidecar コンテナ自体が SIGTERM を受けて停止処理に入るまではイメージを更新したいケースがあるかもしれない
- 問題は Sidecar container を停止する時に PreStop や PostStart hook を再実行するか
- Pod が Terminating 状態の場合、Regular コンテナに PreStop hook が設定されていても実行されない。そもそもイメージが更新されることがない
- Sidecar コンテナは Init コンテナと同じフィールドを使っていて特に変更はまだ入っていないので、1.28 時点ではイメージが更新されないので修正が必要
- Sidecar コンテナ自体が SIGTERM を受けるまではイメージを更新したいユースケースはありそう
- Pod の image フィールドは mutable なので、起動後に変更が可能 (他にも activeDeadlineSeconds, tolerations が設定されている場合にキーの追加, terminationGracePeriodSeconds が負の値の場合に 1 に変更可能)
2023/10/31
- GKE の中の人が Kubernetes の user namespace の機能を containerd 1.7 で検証しようとしたら ID mapped mount のバリデーションでコンテナが起動できなかった。containerd 1.7 にも ID mapped mount のサポートを backport してくれって言ってるけど、機能追加の backport はできないって断られている。COS でも Linux kernel >= 6.3 のサポートがそろそろ入るのかな。COS-109 は Linux kernel 6.1 みたいだけど (containerd/containerd#9310)
- Kubernetes 1.28.3 の kube-schedular で Score plugin が無効で PreScore plugin が有効な場合に panic になる問題の修正。マネージドサービスを使っている場合は基本的に影響ないけど、kube-schedular を変にカスタマイズしていると壊れることがある。PodAffinity 用の PreScore plugin でスコア付け対象のノードがないか PodAffinity の設定がないと skip するようになった。Score plugin の数から skip した Score plugin の数を引いた数が実行する Score plugin の数。その数を使って実行する Score plugin を詰め込む slice を作っていた。なので、Score plugin を無効化していると負の数になって make で slice を作る時に panic になる。少し余分に slice のサイズを確保しちゃうけど、Score plugin の数で slice を作るように変更 (k/k#121632)
- また、原因っぽい PR を revert せずに修正入れてるけど大丈夫かな
- numPlugins が負の場合に Score plugin の数で slice を初期化しても良いような
2023/11/1
- Gateway API が v1.0.0 に到達 (releases)
- Gateway、GatewayClass、HTTPRoute の基本的なリソースが GA
- Gateway API の v1.0.0 に併せて GKE の Multi-cluster Gateway も GA (X)
- Sidecar containers は KEP のスコープを変えたらしく 1.29 で予定通りベータに昇格 (k/k#121579)
- 停止処理周りの変更は入っているので、停止処理中の再起動の部分がベータ昇格必須じゃなくなった感じ
- 停止処理中の再起動は新しく Feature Gate を追加してベータ以降で対応予定 (kubernetes/enhancements#4324)
- ベータ昇格が 1.20 だからそこから長かったけど、API サーバーが高負荷時に重要なリクエストを優先的に処理できるようにする API Priority and Fairness も GA (k/k#121089, k/k#121638)
- kube-proxy の nftables モードもアルファ機能で駆け込みで 1.29 に入った (k/k#121046)
- Kubernetes 1.29 の機能追加のコードフリーズが発動したので、後は例外申請して数日もらって機能入れるやつだけ (kubernetes/test-infra#31164)
- GKE だと既にこれ相当の機能があるので余り恩恵がないけど、Service に割り当てる IP 範囲を動的に拡張できる機能が Kubernetes 1.29 にアルファで入った (X)
- KEP-4323: Cluster Inventory API が新しく出来てた (kubernetes/enhancements#4323)
- 複数クラスタを管理するためのインベントリ (目録) を標準化したい
- Open Cluster Management (OCM) や Karmada、Clustenet、Fleet Manager などのように複数クラスタに渡ってアプリケーションをデプロイするプロジェクトが増えてきているので、Cluster Inventory API で共通のインターフェイスを定義できると良さそう
- Cluster Inventory API を介してクラスタやその特性、ステータス、ライフサイクルイベントを検出できると、ツールや手動作業で複数クラスタを管理しやすくなるし、ユーザーが実装の詳細を気にせずいろいろなツールを使える
- scheduler が Cluster Inventory API を使ってクラスタの特性 (e.g. 特定のクラウド、リソース、リソース使用量やレイテンシ) を考慮してマルチクラスタにワークロードをスケジュールしたり、Argo CD や Flux などの GitOps ツールが複数クラスタにデプロイするための情報を参照したり、MCS API で import / export するクラスタのグループ化に使ったり、クラスタのライフサイクルイベントを監視することでクラスタの自動スケールや更新を行える
- Cluster Manager (e.g. OCM, Karmada, Azure Fleet Manager, …) が Cluster Inventory API のリソースを管理してクラスタのステータスを最新化したりする
- Cluster Consumers が Cluster Inventory API を呼び出してワークロードのスケジュールやクラスタの運用管理などを行う
- Member Cluster が Cluster Manager が管理する Kubernetes クラスタ。Cluster Manager が Member Cluster から情報をとってきて Cluster Inventory API を更新する
- 少し前からある空っぽのリポジトリ (kubernetes-sigs/cluster-inventory-api)
- 今提案されている API はこんな感じ。status.resources に Node のステータス情報の合計を持つ感じかな?GPU とかも使えそう。status.properties が任意のキーと値のペアを埋め込める部分。status.condition に状態を持つ感じだとこれを参照して何かやるなら組み込みの type をいくつか定義してくれないと扱いづらいかも
- Node Feature Discovery を拡張して Cluster Feature のカスタムリソースに情報を書きこんでもらって、それを Cluster Manager が Cluster Inventory に書き込む感じか (kubernetes-sigs/node-feature-discovery#1423)
2023/11/2
- ECR のライフサイクルポリシーでワイルドカードが使えるようになるの取り組んでいて、確約はできないけど今年中にはリリースできそうとのこと (comment - aws/containers-roadmap#1213)
2023/11/4
- Kubernetes 1.30 以降で kubelet にイメージサイズでカテゴリ分けしたラベル (e.g. GT10MB, GT100MB, ...) の付いたイメージプル時間 (キュー待ち時間を含む) のヒストグラムのメトリクスが追加されるみたい。
Pod の Event の文言にもイメージサイズが入るので、Successfully pulled image "ghcr.io/dexidp/dex:v2.37.0" in 7m29.160689121s (7m29.160787807s including waiting). Image size 123456 bytes.みたいな感じになりそう (k/k#121719)
2023/11/6
- Argo CD v2.9.0 がリリースされてた。もうリリースページに変更内容書かないのかな (releases)
- アルファ機能で入った argocd-application-controller のシャードの動的リバランスくらいかな (blog)
- Job の Pod が Terminating で stuck する報告が多くて、大体 Admission Webhook のせいなのでトラブルシューティングの方法を公式サイトに追加しようとしている PR (kubernetes/website#43773)
- Pod の UPDATE 時にも Admission Webhook にリクエストを流すようになっていると問題が起きやすい
- Mutating Admission Webhook の場合に Pod Spec のほとんど全てが immutable なフィールド (e.g. image とか InPlacePodVerticalScaling が有効な場合の spec.resources) を変更しようとすると起きる
- 今は一部修正されているけど、Webhook のポリシーが Ignore かつ vault-k8s が停止中で CREATE 時に initContainer が差し込めなかった場合などに問題になっていた (hashicorp/vault-k8s#546)
- UPDATE のイベントでも Admission Webhook が処理するようになっているのが問題
- Job の Pod を削除した時に Job controller が finalizer を削除しようとして UPDATE イベントが発生し、
- vault-k8s が initContainer が差し込めていないことに気付き差し込もうとしてエラーになる
- 結果、Pod に付与された Job controller の finalizer が消えずに残って Terminating 状態で stuck する
- Validating Admission Webhook の場合は、Webhook を導入する前に作った Pod の UPDATE イベントで Webhook にリクエストが流れて検証した時にエラーになるパターンがある
- Validating Admission Webhook に違反している Pod が過去に作られている可能性があるので、UPDATE イベントで Webhook をトリガーするのは良くない
2023/11/7
- GKE は Primary CIDR と Pod CIDR は後から拡張できるけど、Service CIDR は後から拡張できないの、完全に勘違いしてた。だから、アントニオさんが Service CIDR の拡張機能を Kubernetes 1.29 でアルファ機能として入れたのか (link, link)
- アントニオさんの ServiceCIDR の拡張のデモのハイライト (youtube)
- デフォルトの ServiceCIDR の挙動と Service の割り当て可能な CIDR を拡張するために新しく追加した
- ServiceCIDR の挙動を見せる
- ServiceCIDR で定義した CIDR の IP を 1 つでも使用中だと ServiceCIDR に finalizer が付いているから消せない挙動を見せる
- デフォルトの ServiceCIDR を消そうとするがデモで作った Service が残っていたり、default namespace の kubernetes の Service (クラスタ内からの Kubernetes API サーバーの接続先) も残っていて消せない
- Service を全て消したらデフォルトの ServiceCIDR も消せるようになると言って Service を消し始める
- default namespace にある kubernetes の Service も消さないといけないのでおもむろに消そうとする
- 周りからは kubernetes の Service を消すとクラスタが壊れないかと心配されたり、これがライブ E2E テストだといじられるが、default namespace の kubernetes の Service は消してもしばらくすると再作成されるから問題ないと続ける
- 消してもすぐに kubernetes の Service が再作成されない
- watch じゃなくて定期的に polling しているからしばらく待っていれば再作成される、心配ないと言いながら kubectl get service を連打する
- 周りからも再作成されると信じてるよといじられる
- SIG-Network の Lead になった Dan さんから kubernetes の Service の再作成の仕組みはもう入っているの?と指摘されるが、ServiceCIDRs の実装以前からあると回答する (その間も kubectl get service を連打する)
- クラスタ作成時に作成されるだけだと思っていたと言われるが、API サーバーは kubernetes の Service がないと作成するようになっているから大丈夫、何秒間隔かは分からないけどと少し不安そうになる
- Dan は経験的な裏付けがあって指摘していそうだと周りから言われ、Dan が (再作成されないことを) 知っていてみんなの前でデバッグ作業をさせられているのかもしれないと返して、ついに諦めて次の話に進む
2023/11/8
- AKS の Karpenter Provider (Azure/karpenter)
- Karpenter の v1beta1 のカスタムリソースベース
- 単一の VM を作ってクラスタに参加できないといけないから、GKE で対応するのやっぱり難しそう
- WG-LTS で話に出ていた Rust のエディションみたいな概念 (compatibility version) を導入する案が KEP 化しそう (kubernetes/enhancements#4330)
2023/11/10
- ServiceCIDR の拡張の機能に対して IPv6 って知ってる?って煽りコメントにこの回答はかっこいい (X)
2023/11/14
- 前に議論になっていた initContainers で生成した環境変数を動的に後続のコンテナに埋め込む KEP (kubernetes/enhancements#4319)
- Vault などの秘密情報管理とか ML 系のフレームワークとかに動的に生成した環境変数を渡したいのがユースケース。PodSpec の envFron に新しく fileEnvSource が追加される。initContainer と後続のコンテナで emptyDir をマウントして、initContainer で書き込んだ環境変数を後続のコンテナで fileEnvSource で指定したパスとオプションで keySelector で一致した環境変数のキー名に限定して環境変数を埋め込み可能。
- SIG-Node とか WG-Batch の人たちも意外とこの機能の追加に前向きだった (k/k#114674, k/k#116993)
apiVersion: v1
kind: Pod
metadata:
name: pod-with-file-env-source
spec:
volumes:
- name: shared-env-volume
emptyDir: {}
initContainers:
- name: init-container
image: busybox:1.28
command: ['sh', '-c', 'echo "DYNAMIC_VAR=dynamic value" > /shared-env/vars.env']
volumeMounts:
- name: shared-env-volume
mountPath: /shared-env
containers:
- name: main-container
image: nginx:1.14.2
volumeMounts:
- name: shared-env-volume
mountPath: /shared-env
envFrom:
- fileEnvSource:
path: /shared-env/vars.env
keySelector:
- key: DYNAMIC_VAR
2023/11/15
- KubeCon 2023 NA は LLM / GenAI のプラットフォームを Kubernetes 上でどう構築するかという流れで Dynamic Resource Allocation (DRA) に注目が集まったみたいです。(google groups)
- DRA で GPU などを柔軟かつ効率的に使えますが、その代償として実装はかなり複雑です。Cluster Autoscaler との連携など今後更に複雑化する恐れがあるので、1.29 でベータに昇格せずにその辺りを整理することになりました。DRA を再構築するならアルファ段階の今という見方もあります。Tim Hockin が DRACon に迷い込んだみたいと揶揄するくらいに KubeCon で議論があったようで、今後は WG-Batch に合流して議論を進めていくみたいです。最初は WG-DRA を作る予定でしたが、WG-Batch の目的が同じ部分がある & SIG-Node / SIG-Scheduling / SIG-Autoscaling などのメンバーも集まっているということで一緒にやろうとなったようです。
2023/11/16
-
以前に話をしていた ProvisioningRequest API が GKE に Preview の機能として追加された。 (release note)
- ノードをずっと占有しないように 7 日で強制的に Evict されるようになっている。それ以前でもノード使ってなかったら消える
- GPU VM 以外では使えない
- ノードに問題が起きたり、更新作業でノード上の Pod を Evict すると、Pod をグループとして扱う ProvisiningRequest API ではその Pod が unschedulable になっちゃってそれ以降もうスケジュールされなくなる。だから、自動更新と自動復旧とかはサポートしていない (無効) なのか
2023/11/19
- Node の Capacity を上書きする機能が欲しいって言ってたの KEP 化して実装始まるかも?(comment - k/k#120832)
2023/11/20
- EKS のマネージドアドオンに CSI Snapshot Controller が追加された (comment - aws/container-roadmap#1838)
2023/11/21
- GKE の netd に Istio CNI のサポートが追加されようとしている。Anthos Service Mesh 関連かな (GoogleCloudPlatform/netd#251)
2023/11/23
- Reducing AI Job Cold Start Time from 15 Mins to 1 Min - Tao He, Google (youtube)
- AI / ML ワークロード用のコンテナイメージはベースイメージが大きく肥大化しがち (e.g. 30 GB)
- ベースイメージに GPU の高レベルなライブラリや ML フレームワークのライブラリが入っている
- ライブラリのサイズを減らそうにも全て OSS とも限らないので自分でビルドも難しい
- ホスト OS 側にライブラリを置くとアプリケーションのライブラリの依存関係が壊れる
- ホスト OS 側に GPU ドライバの低レベルなライブラリ (API) やカーネルモジュールが入っているが比較的容量が少ない (e.g. 数十 MB 程度)
- Dive でベースイメージのレイヤーを覗いたところ GPU やフレームワークのライブラリは軒並み 数 GB 程度ある
- イメージプルを高速化させる手法はいくつかある
- クラスタ全体に対するソリューション
- kube-fledge などの DaemonSet を使ってイメージを事前にロードする
- Kraken や Dragonfly 2 などの P2P を使った分散ダウンロード
- Docker Registry Cache や Spegel などのクラスタ内にキャッシュ用のレジストリを用意する
-
ノード単位でのソリューション <--- 今日話す内容
- 追加ディスクを用意してコンテナイメージを事前にロードする
- containerd に変更を加えてイメージレイヤーの unpack (展開) を並列化して高速化する
- Kubelet の並列イメージプルの機能 + 最大並列プル数制限の機能を使う
- クラスタ全体に対するソリューション
- 追加ディスクを用意してコンテイメージを事前ロードする方法
- コンテナイメージのプル時間を完全になくせる
- コンテナイメージをダウンロード & 展開をしておいてそれらを含めたディスクイメージを事前に作成しておく
- ノードが追加される時にディスクイメージから追加ディスクを作成してノードにマウントする
- 追加ディスクの作成に当然コストが掛かるが、クラウド環境において追加ディスクはディスクイメージへのポインタと見ることができて、作成時にデータのコピーは発生しないのでディスクの複製 (作成) 自体は数秒で終わる
- containerd の snapshotter plugin が ブートディスクと追加ディスクの両方からデータを読み取る
- containerd 関連のデータはブートディスクから、コンテナのキャッシュは追加ディスクから読み取る
- containerd はレイヤー毎にキャッシュを使い回すので、同じベースイメージ (レイヤー) を使っている場合に起動が早くなる
- アプリケーションが共通のライブラリやフレームワークを使っている場合、ライブラリ用のコンテナイメージやフレームワーク用のコンテナイメージをベースイメージとして用意して置いておくと良い
- ベースイメージを分けておけば、パラメータや設定、コードの変更は少ないイメージレイヤーに閉じ込められるので高速起動の恩恵を受けられる
- 事前にロードしたベースイメージのサイズの違いで大きく起動時間は変わず、ほぼ一定で 1 分未満に抑えられる
- 追加ディスクの作成とノードへのマウントやキャッシュの準備などを含めても 10 秒掛からない程度
- クラウド環境のブロックストレージは分散ストレージになっており、ディスクイメージからディスクを作成する場合に毎回全てのデータをコピーする訳ではない
- ディスクを作成した時点では裏側のデータブロックを参照しているだけ
- データの複製自体もデータブロックの使用頻度が増えるとスケールする仕組みになっている (同じディスクイメージからディスクをたくさん作った場合にスケールする訳ではないので注意) ので、ベースイメージの参照が多ければ多いほど複製は高速になる
- GKE の機能として 2023 年末か 2024 年にリリース予定らしい
- ブートディスクと追加ディスクの両方から読み取る機能は GKE 固有の snapshotter の実装になる
- 開発者とインフラチームに分かれている想定で、開発者がこのライブラリやフレームワークのバージョンを使いたいと言ったら、インフラチームがディスクイメージを用意する感じの機能っぽい
- CI / CD のパイプラインにディスクイメージのビルドも含めてねってことみたい
- GKE としてはディスクイメージを参照する機能しかなくディスクイメージの作成は完全にユーザー側でやる必要がありそう
- snapshotter の実装を OSS 化する予定があるかという質問に対して、イメージのビルドツールは OSS 化の予定があるが snapshotter の実装は OSS 化の予定がないと答えているため
- containerd に変更を加えてイメージレイヤーの unpack (展開) を並列化して高速化する
- containerd のイメージプルは Fetch と Unpack の 2 つのステップがある
- ベンチマークの結果からダウンロードしたコンテナイメージの圧縮ファイルの unpack (展開) に時間が掛かっていること、ディスク IO がボトルネックになっていることが分かった
- コンテナイメージのダウンロードとディスクへの書き込みはレイヤー毎にスレッドで並列化されている
- 圧縮ファイルの展開とディスクへの書き込みは単一スレッドでレイヤー単位で直列に行われている (だから遅い)
- ディスクに対する read / write の操作のスループットが他の操作 (e.g. ネットワークやインメモリ操作) に比べて 1/5 - 1/3 程度で遅い
- クラウド環境のブロックストレージは分散ディスクなので遅い
- ブロックストレージは並列に操作すると速くはなる
- 高速なブロックストレージを使えば問題は解決するかというとそうではない
- アプリケーションがブロックストレージのスループット上限まで使い切ろうと思うと、IO queue depth の値が 20 を超えていないといけない
- ベンチマークの結果 containerd の IO queue depth の値は大体 5 程度なのでスループットを最大限活用できていない
- スループットの高いブロックストレージに変えても恩恵が受けられないのはこれが理由
- containerd の実装を変えて高い IO queue depth の値まで持っていく必要がある
- containerd の unpack がレイヤー毎に直列で行われているのは、レイヤー内のファイルが依存関係を持っている可能性があるから
- 同じファイルを複数のレイヤーで上書きしたり、削除したりしている場合がある
- 最後のレイヤーで今まで修正していたファイルを削除する場合もなくはないので直列に unpack するしかない
- 他の理由として複数のファイルシステムをサポートするために直列に処理しているというのもある
- 同じファイルを複数のレイヤーで上書きしたり、削除したりしている場合がある
- containerd がレイヤー毎に異なるディレクトリに並列で unpack しておいて、後から軽量な操作 (e.g. mv や rename やマウントの作成) をレイヤー毎に順番に直列で実行することでコンテナを作成する
- AI / ML のコンテナイメージは大体 30 レイヤーを超えているので、並列に unpack することで恩恵を受けられる
- ベンチマークの結果、ディスクのスループットを上げる (Google Cloud の場合ディスクサイズを増やすとスループットが上がる) とイメージプルに掛かる時間を短くすることができる
- スライドの文言からは 6 GB のコンテナイメージのプル時間を 230 秒 -> 40 秒に減らせたとある
- スライドのグラフからは 1.5 TB のディスクサイズの追加ディスクを使用して 6 GB のコンテナイメージのプル時間が 270 秒 -> 90 秒に改善したことが読み取れるので、ディスク容量を 1.5 TB より更に増やした場合の結果が ↑ っぽい
- Kubelet の並列イメージプルの機能 + 最大並列プル数制限の機能を使う
- 発表でも軽く流していたので省略
- 質問タイム
- コンテナレイヤーの圧縮フォーマットを変えた場合にイメージプルが高速化するかは見たか?
- zstd アルゴリズムを試したことがあってイメージプル時間を改善はできたが、ダウンロードや Unpack のステップが必要なのでゼロにはできない
- コンテナレイヤーの圧縮フォーマットを変えた場合にイメージプルが高速化するかは見たか?
- AI / ML ワークロード用のコンテナイメージはベースイメージが大きく肥大化しがち (e.g. 30 GB)
2023/11/29
- cert-manager が KubeCon EU 目標で CNCF の Graduated プロジェクトになるよう進めていくらしい (cncf/toc#1212)
2023/11/30
- SOCI Index を手動で作成せずに自動で作成するようにして欲しい要望。GKE の Image Streaming はキャッシュ作る時に変換してて、ユーザー側で変換いらない気がしている (aws/containers-roadmap#2218)
- GKE Autopilot 1.27.6-gke.1248000 からDaemonSet の Pod が全て起動できないノードがあると、よりインスタンスサイズの大きなノードプールに置き換えてくれる (release note)
2023/12/1
- Kubernetes 1.29 のリリースは 12/13 に延期。Golang の脆弱性修正のパッチリリースが 12/5 に予定されていてそれを取り込むため (mailing list)
2023/12/3
- cgroup v2 の場合に memory.oom.group が有効になって、子プロセスの OOMKill でコンテナ全体が死ぬようになったのやっぱり影響が出ているみたいで、PFN のすぱぶろさんが報告している。確かに ML だと子プロセスが死んでも親プロセスが新しく子プロセスを立ち上げて計算を続行したいケースはあるだろうし、ノートブック系のツールとの相性も悪い。現状は無効にするオプションがないので、Kubelet にパッチ当てて無効化しているらしい。ほとんどのワークロードが恩恵を受けられるという前提 & 過去の挙動が間違っているという理由からユーザー体験重視で Pod レベルで ON/OFF する機能は不要と過去に判断された。Pod レベルでなくていいから、Kubelet のオプションで無効化する機能を入れたいというのが要望 (comment - k/k#117793)
- Balancer の件はさんぽしさんが KubeCon NA で SIG-Autoscaling の方と話したみたい。メルカリとしても Deployment を複数作るのが本番運用している大規模なクラスタに導入する障壁だと。Balancer は実験的なプロジェクトとして始まって、当時 scheduler に変更を加える案も出ていたけど、実験的な取り組みのためにそこたでやれないということで却下になっている。やっぱり scheduler に変更を加えて Pod Topology Spread Constraints で weight 指定できた方が良さそうだけど、どう?って SIG-Scheduling の他のメンバーに聞いてるとこ (comment - k/k#121211)
2023/12/7
- ノードに AI デバイスとか NIC デバイスが刺さっている場合に、NIC デバイスに近い AI デバイスの方が RDMA の恩恵を受けられるので、DRA でユーザーがデバイス ID を指定できるようにしたい。
ベンダーが実装した DRA ドライバでデバイス ID の指定をサポートしていたらそれを使えば良いだけだけど、そうとは限らないので DRA の実装でいい感じに抽象化できないかみたいな話かな。
Pod の annotation にノード名やデバイス ID を指定しておくと、Admission Webhook が Pod の ResourceClaim や ResourceClaimTemplate をより良いものに書き換えるみたいな流れ。
DRA が余計に複雑になるから流石に upstream には入らなそう (pohly さんも klueska さんも DRA のコアで入れるべきじゃない派) だけど、みんな色々やりたくて大変そう (k/k#122198) - Node Capacity を上書きする機能は SIG-Node も好意的なので KEP 化しそう (comment - k/k#120832
- 元々 Google の人が要望を上げていたり、SIG-Autoscaling / Google の人も絡んでたりで何かありそう。
We want to run a multi-node cluster on a single host and we do not want each node to have access to a full VM capacity but instead we would like to provide each node with a part of host
- capacity.ML / HPC 系のバッチ処理で物理的な距離が近い方がネットワーク含め性能が上がるから、複数ノードを 1 つの仮想マシン上に突っ込むみたいなことをやりたいとか?
- 元々 Google の人が要望を上げていたり、SIG-Autoscaling / Google の人も絡んでたりで何かありそう。
- Dynamic Resource Allocation (DRA) の WG-Batch のミーティングで使う今後どうしていくかのドキュメントきた (google docs)
- 通常のリソースや拡張リソース (Device Plugin ベース?) のスケジュールに比べて DRA は DRA ドライバの処理が入るので遅くなる
- DRA の scheduler plugin がスケジューリングサイクルの中で処理をブロックしてしまうので、DRA を使っていない Pod のスケジューリングにも影響してしまう
- Reserve で ResourceClaim に紐付ける Pod を選んで予約していた処理の一部を PreBinding に移して (goroutine で動作させて) 処理をブロックしないようにしようとしてるやつ
- Cluster Autoscaler との連携をどうするか事前定義したリソース種類と数値で指定する方法が連携はしやすいけど、今の DRA のカスタムリソースほどの表現力がなくなるのでそれで良いのか
- Kubelet が Pod の再スケジューリングをトリガーする話も他の案のところに書かれている...
- NCCL のライブラリを使うと NIC の経路の最適化をやってくれるらしい
2023/12/9
- アントニオさん SIG-Network の Tech Lead になりそう (mailing list)
2023/12/10
- Pod の終了時に /dev/termination-log に書き込むと Pod Status の最後に停止した理由として表示されるようになるけど、/dev/termination-log に大量に書き込んだ時に Ephemeral storage の上限を超えても Evict されないらしい (k/k#122224)
2023/12/13
- 定期的に Issue が立つ気がする Service 経由のリクエストが Pod に均等に分散していないのでは?の話。kube-proxy の IPVS モードだとデフォルトでラウンドロビンだから iptables モードよりも均等になるらしい (comment - k/k#122015)
- WG-Batch の Job に PDB を設定できるようにしたい要望は SIG-Apps に棄却された。マネージャーとワーカーに分かれていて並列実行の時とかに PDB を付けたい感じかな (comment - k/k#121957)
2023/12/14
- Kubernetes 1.29 がリリースされました (mailing list, blog)
- ReadWriteOncePod が GA
- ReadWriteOnce は同一ノード上の複数の Pod から読み書きできるという問題があり、1 つの Pod しか読み書きできない ReadWriteOncePod が新しく追加されたという経緯CSI Node Expand Secret の機能が GAボリューム拡張の機能を使うときに SAN などの一部のストレージで拡張の操作にパスフレーズが必要なので指定可能に
- KMS v2 が GA
- Kubernetes のオブジェクトなどを暗号化するのに外部の KMS を利用できるようにする機能で、v2 はパフォーマンス改善やキーのローテーション、ヘルスチェック、可観測性が向上した
- TaintManager を opt-out 可能に
- NodeLifecycleController は Unhealthy なノードに taints を付け、NoExecute の taints が付いている場合にノードを削除する
- NodeLifecycleController から taints が付いている場合にノードを削除する部分を TaintManager として分離
- 最初からベータかつデフォルト有効な機能
- Taint ベースの Pod の退避の機能が KCM (kube-controller-manager) の --enable-taint-manager のフラグで On/Off できたけど、Taint-based Pod Eviction の機能が GA してからフラグがなくなった。Apple の人たちが社内で独自の要件にあった TaintManager を利用しているのに利用できなくなったので opt-out したいところから始まったやつ
- SIG-Node 的には組み込みの TaintManager を改善したい気持ちがあるので、ON/OFF には反対してい流ので今後は分離できた TaintManager に改善を入れていくはず...?
- レガシーな Secret ベースのサービスアカウントトークンの掃除
- 1.24 からデフォルトで無期限のサービスアカウントトークンが生成されなくなって、1.27 から使用していないサービスアカウントトークンにラベル付けするようになった
- 1.29 からついに 1 年間使っていないラベルの付いたサービスアカウントトークンが削除される少し怖い機能だけど、セキュリティ的な懸念からやむなし
- 1.29 からアルファな機能
- Pod Affinity と Anti-affinity に matchLabelKeys が指定可能に
- kube-proxy に nftables モードを追加
- Service の IP 範囲を動的に増やしたり減らしたり
- Windows ノード向けに正しいプラットフォームのコンテナイメージをプルできるように
- Windows ノードでもオンラインで Pod のリソース割り当てを変更可能に
- API server Priority and Fairness (APF) と CRD Validation Expression Language (CEL ルールで検証) が GA
- kube-cloud-controller-manager (KCCM) の in-tree のクラウドプロバイダーの実装が削除
- APF のベータ API が非推奨に正しい情報を返していなかった Node オブジェクトの status.nodeInfo.kubeProxyVersion が非推奨に
- リリースブログには書いてないけど、Sidecar container の機能はベータ昇格でデフォルトで利用可能です
The SidecarContainers feature has graduated to beta and is enabled by default.
- ReadWriteOncePod が GA
2023/12/16
- In-place Pod Vertical Scaling のアルファ機能を有効にするとデフォルトの ResizePolicy を埋め込むせいで PodSpec に変更が入り、クラスタ内のコンテナが一斉に再起動するバグ。アルファ機能なので修正は 1.29 に cherry-pick されず、1.30 で修正される予定。In-place Pod Vertical Scaling は 1.30 でもアルファ機能のままっぽい (k/k#122028)
- WG-LTS の中で過去のリグレッションの傾向を分析した結果、Kubernetes 1.19 以降のマイナーバージョンで cherry-pick によるパッチリリースへのリグレッションの混入が必ず発生していた。backport / cherry-pick のガイドラインを厳しくして、リグレッションや脆弱性、データ欠損、FeatureGate のデフォルト値の変更 (アルファなのに有効になってたり、バグ報告が多くて無効にしたり) に絞る案が出ている。もし、バグ修正を backport する場合は、正当な理由とリスク分析が必要。バグ修正の backport / cherry-pick は最初のマイナーバージョン (e.g. 1.30.0) のリリース前に行われるべき (k/community#7634)
2023/12/19
- EKS の aws-auth の置き換えは aws-auth と新しい EKS API を同時に使うオプションもあるから移行するときに使えそう (blog)
- 最近 GKE の新しいバージョンで Dataplane v2 有効で新規に作ると NotReady になっちゃってたのこれの影響かな (GoogleCloudPlatform/netd#259)
- デュアルスタッククラスタを作っている場合に、GKE 1.28 以降で NEG に IPv6 のエンドポイントも追加されるようになる。既存クラスタも GKE 1.28 以降になると自動的に移行が始まるらしく、エンドポイント (≒ Pod) 毎に 1-2 分のダウンタイムが発生する (release note)
- Fly.io のマネージド Kubernetes の Fly Kubernetes (FKS) が使えるようになった話。FKS は Kubernetes どうしても使いたい人向けで、内部的に K3s と Virtual Kubelet を使っている。Virtual Kubelet で kubelet の API を Fly.io の Machine API に変換して、K3s の kine を使って etcd ではなくローカルの SQLite にオブジェクトを保存しているみたい。Fly.io の既存の仕組みに kube-proxy とか CNI とかノードに近い概念があるから不要なコンポーネントはさらに排除して K3s よりも軽量らしい。CoreDNS と SQLite と Virtual Kubelet だけ動いている (blog)
2023/12/21
- EKS にも Deprecation Insights が来た。GKE の Deprecation Insights と違ってマイナーバージョンの自動更新が止まるとかはなさそう。EKS の場合、自動更新が EoL 過ぎた後にしか起きないからかな (news)
- EKS の Amazon Linux 2023 のサポートは 2024 年初頭予定 (comment - awslabs/amazon-eks-ami#1385)
- Job API に managed-by のラベルを追加して Job コントローラの処理を無効化する KEP (kubernetes/enhancements#4370)
- Kueue の延長でマルチクラスタで Job を実行するための MultiKueue の開発が始まっている
- MultiKueue ではマネージャーとワーカーのパターンを採用していて、管理クラスタと
Job を複製して実行するワーカークラスタに分かれる - ユーザーが管理クラスタに Job を作成すると、管理クラスタ内の Kueue コントローラがワーカークラスタに Job の複製を作成して実行する。Kueue コントローラがワーカークラスタで実行された Job の状態を管理クラスタの Job の状態に同期反映する
- 上記をサポートするために、外部のコントローラ (e.g. Kueue コントローラ) が同期できるように Job コントローラが Job の状態を更新するのを無効化したい
- managed-by のラベルが付いた Job は Job コントローラが同期しないようにする
- 管理クラスタの Job コントローラの同期処理の無効化は Job 単位でコントロールプレーンの設定を変えずに行いたい。マネージド Kubernetes の多くでコントロールプレーンがいじれないのが理由
- ラベルを付与することである API の状態を別の API の状態に同期する仕組みは EndpointSlice コントローラのミラーや IPAddress コントローラで使われている
- Job にラベルが付与されていたら syncJob の処理の一部を飛ばすだけなので、最初からベータ機能として導入したい
- Job コントローラの処理を一部スキップする機能を導入すると、コア機能以外でみんな好き勝手に独自処理を入れてコミュニティを分断する可能性がある
2023/12/23
- Cilium の開発をしている Isovalent が Cisco に買収された (X)
- お財布の紐キツくなっているはずだけど、来年も Google 様から Kubernetes の開発に 300 万ドルの Google Cloud のクレジットが提供されるみたい

2023/12/28
- StatefulSet の volumeClaimTemplate のフィールドを更新したら PVC のフィールドも更新してよ by 青山さん (comment - k/k#121178)
- cgroup v1 の非推奨化が 1.30 で予定されている。RHEL 7 の関係で Linux カーネルの最小サポートバージョンが 3.10 なので、cgroup v1 の実装が完全に消えるのは先になりそう (comment - k/k#116799)