[Kubernetes 1.30] Dynamic Resource Allocation の再構築
[Kubernetes 1.27] Dynamic Resource Allocation のいまで紹介した Dynamic Resource Allocation (DRA) の内部的な仕組みに Kubernetes 1.30 で大きく変更が入ることになりました。内部的な仕組みの変更なので、ユーザー視点ではこれまでと利用方法は変わりません。ResourceClass に追加されたフィールドを有効にしないと新しい仕組みが使えないため、クラスタ管理者は対応が必要になります。
世界的に AI / ML の活用が進んだことで GPU 需要が高まり、如何に効率よく GPU を利用できるかが鍵となっています。そのような情勢の中、KubeCon + CloudNativeCon 2024 EU でも DRA は大きく取り上げられました。昨年末の KubeCon + CloudNativeCon 2023 NA では Tim Hockin が "DRACon に迷い込んだみたいだ" と発言するなど、開発者の中での注目度は高まっていました。ただ今回は、KubeCon の Keynote で取り上げられるなどユーザーの立場でも DRA を目にする機会が増えたのではないでしょうか。
- Keynote: Accelerating AI Workloads with GPUs in Kubernetes - Kevin Klues & Sanjay Chatterjee
- Keynote: The Cloud Native News Show: AI Breakthroughs Revealed
- DRAcon: Demystifying Dynamic Resource Allocation - from Myths to Facts - Kevin Klues & Patrick Ohly
- [KubeCon Contributor Summit] Dynamic Resource Allocation - the path towards GA
本記事では、Kubernetes 1.30 での DRA の変更内容と今後の動きについて、上記の発表やサンプルの Resource Driver の実装を元に紹介していきます。DRA がなぜ必要なのかと Kubernetes 1.27 時点での仕組みに関しては [Kubernetes 1.27] Dynamic Resource Allocation のいまで紹介しているのでまずはそちらを読んでもらうのが良いです。
DRA が抱えていた課題
DRA は Kubernetes 1.26 でアルファ機能として入りました。新しくコア API グループとして resource.k8s.io が追加され、ResourceClass, ResourceClaimTemplate, ResourceClaim, PodScheduling などのコアリソースが導入されました。Kubernetes 1.27 で API バージョンが v1alpha2 に更新され、PodScheduling は PodSchedulingContext に変更され、複数の Resource Driver が Pod に必要なリソースの準備を行える仕組みが追加されました。そして、Kubernetes 1.28 では Resource Driver が複数のリソース要求を一気に依頼できるようになりパフォーマンスが改善しました。それ以外にも DRA 用の Scheduler Plugin のパフォーマンス改善など順調に進化を続け、Kubernetes 1.29 でベータ昇格を目指していました。しかし、ベータ昇格は API の成熟を意味し、API の破壊的な変更が難しくなります。DRA は以下の問題を抱えており、このままベータ昇格するよりも問題を解消するためにアーキテクチャを再考する道を選びました。
- Cluster Autoscaler や Karpenter など Node の自動スケールツールとの連携
- DRA の遅延割り当ての機能による DRA Scheduler Plugin のパフォーマンスと Pod のスケジュール時間への影響
- GPU や FPGA などの Node のローカルリソース以外の SR-IOV ネットワークデバイスなどの利用
- DRA の Resource Driver と kube-scheduler のやり取りなどの実装の複雑さ
特に 1 つ目の Node の自動スケールツールとの連携は重要で、世界的な GPU の在庫不足によりオンプレ環境だけでなくクラウド環境を利用して AI / ML ワークロードを動かすケースが増えています。クラウド環境では Node の自動スケールにより必要な時に GPU リソースを確保し、効率的に利用することが重要です。Kubernetes 1.29 までの DRA では、Resource Driver を開発するベンダー (e.g. NVIDIA, Intel, ...) が任意のパラメータ (e.g. 利用する GPU の数、Time Slicing や MIG などの GPU の利用方法, ...) をカスタムリソースとして表現し、ユーザーが要求することができました。ただ、そのパラメータとして任意の値やベンダー固有の設定を指定できるため、Cluster Autoscaler や Karpenter などがそのパラメータをどう解釈して良いか分かりません。当初は Cluster Autoscaler にクラウドプロバイダーやベンダーが手を加えてセルフビルドし、パラメータを解釈できるようにするといった案を推していたようですが、もう少し良い方法がないか模索することとなりました。
KEP-4381: Structured Parameters for Dynamic Resource Allocation
Structured Parameters は、DRA のベンダー固有のパラメータを Kubernetes のコア機能 (e.g. kube-scheduler) やそれ以外のツール (e.g. Cluster Autoscaler, Karpenter, ...) が理解可能な形に変換する仕組みです。DRA の利用者が指定したパラメータを DRA driver が解釈し、Kubernetes のコア機能として事前に定義された"構造化されたモデル"に変換します。kube-scheduler や Cluster Autoscaler などのコンポーネントはこの"構造化されたモデル"を元に判断を下すことで、ベンダー固有の実装の詳細を知ることなしに DRA と連携することができます。
-
resource.k8s.io/v1alpha2の API グループに新しく ResourceSlice が追加されました。DRA driver から提供された情報をもとに kubelet が ResourceSlice を Node 単位で作成し、利用可能なリソースを"構造化されたモデル"として API サーバに公開します。kube-scheduler や Cluster Autoscaler などはこの ResourceSlice を見て、Node にこれ以上 Pod を配置できるかなどを判断します。 -
resource.k8s.io/v1alpha2の API グループに新しく ResourceClaimParameters を追加しました。これまで通り DRA の利用者は ResourceClaim にベンダー固有のパラメータ (CRD) を紐付けます。DRA driver は、GPU を 3 基使いたいや GPU の time-slicing の機能を使いたいなどのベンダー固有のパラメータを解釈して ResourceClaimParameters というリソースに変換します。 - kube-scheduler や Cluster Autoscaler は ResourceSlice や ResourceClaimParameters などのリソースの情報を利用して Pod を配置する Node を決めたり、新しく追加した Node に Pod を起動できるかシミュレーションします。
- kube-scheduler はPod をどの Node に配置するか決定すると、Binding API を呼び出して Pod の
.spec.nodeNameを確定します。それと同時にインメモリに保存している割り当て可能なリソースの情報を更新します。Pod の配置先の Node で動いている kubelet が DRA driver に対して Pod に割り当てるリソースを準備を依頼します。
Kubernetes 1.30 より前の Classic DRA の時代は、Pod Scheduling Context を介して kube-scheduler と DRA driver controller がやり取りを繰り返し、Pod の配置先の Node を決定していました。

Kubernetes 1.30 以降の Structured Parameters では、kube-scheduler が ResourceClaimParameters と ResourceSlice の情報を見て Pod の配置先の Node を決定できるようになりました。Pod Scheduling Context を介す必要がなくなり、割り当て済みのリソースの情報を DRA driver 側で追跡する (e.g. NodeAllocationState) 必要もなくなったため、シンプルになっています。

Kubernetes 1.30 以降も Classic DRA のサポートは継続しており、2024/4/29 現在非推奨化の予定はありません。NVIDIA/k8s-dra-driver や intel/intel-resource-drivers-for-kubernetes、kubernetes-sigs/dra-example-driver などの DRA driver は Classic DRA と Structured Parameters の両方に対応しています。
ResourceSlice の公開
ResourceSlice は kubelet が公開します。DRA driver の kubelet-plugin が kubelet に公開するリソースの情報を渡します。そのため、kubelet に新しく gRPC の Streaming RPC として NodeListAndWatchResources を追加しました。この API を DRA driver の kubelet-plugin が実装することで、kubelet が ResourceSlice を作成します。fake-dra-driver の NodeListAndWatchResources では、起動時に公開するリソースの情報を Streaming RPC 経由で渡す実装となっています。起動後に GPU の異常などを検知して公開するリソースの情報を変更したい場合は、処理を追加すれば実現できます。
func (d *driver) NodeListAndWatchResources(req *drapbv1.NodeListAndWatchResourcesRequest, stream drapbv1.Node_NodeListAndWatchResourcesServer) error {
model := d.state.getResourceModelFromAllocatableDevices()
resp := &drapbv1.NodeListAndWatchResourcesResponse{
Resources: []*resourceapi.ResourceModel{&model},
}
if err := stream.Send(resp); err != nil {
return err
}
// Keep the stream open until the driver is shutdown
<-d.doneCh
return nil
}
DRA driver の kubelet-plugin は ResourceModel のリストを kubelet に送ります。この ResourceModel が Kubernetes のコア機能として提供するとした"構造化されたモデル"のことです。
// ResourceModel must have one and only one field set.
type ResourceModel struct {
// NamedResources describes available resources using the named resources model.
//
// +optional
NamedResources *NamedResourcesResources `json:"namedResources,omitempty" protobuf:"bytes,1,opt,name=namedResources"`
}
// NamedResourcesResources is used in ResourceModel.
type NamedResourcesResources struct {
// The list of all individual resources instances currently available.
Instances []NamedResourcesInstance
}
// NamedResourcesInstance represents one individual hardware instance that can be selected based
// on its attributes.
type NamedResourcesInstance struct {
// Name is unique identifier among all resource instances managed by
// the driver on the node. It must be a DNS subdomain.
Name string
// Attributes defines the attributes of this resource instance.
// The name of each attribute must be unique.
Attributes []NamedResourcesAttribute
}
NamedResourcesInstance の中の Attributes に Kubernetes でサポートしている型がいくつか定義されています。Kubernetes 1.30 時点では Int や Boolean、String などの一般的な型以外にも Pod の resources で使用している Quantity や Semantic Version 2.0.0 などが用意されています。
// NamedResourcesAttributeValue must have one and only one field set.
type NamedResourcesAttributeValue struct {
// QuantityValue is a quantity.
QuantityValue *resource.Quantity
// BoolValue is a true/false value.
BoolValue *bool
// IntValue is a 64-bit integer.
IntValue *int64
// IntSliceValue is an array of 64-bit integers.
IntSliceValue *NamedResourcesIntSlice
// StringValue is a string.
StringValue *string
// StringSliceValue is an array of strings.
StringSliceValue *NamedResourcesStringSlice
// VersionValue is a semantic version according to semver.org spec 2.0.0.
VersionValue *string
}
DRA driver の実装者は kubelet-plugin の実装で、ベンダー固有のパラメータを Kubernetes が理解できる ResourceModel に変換する処理を書くことになります。fake-dra-driver では、Fake デバイスの UUID と Model (e.g. ULTRA-10, ULTRA-100 などのシリーズ) をそれぞれ String 型のアトリビュートに変換しています。
// https://github.com/toVersus/fake-dra-driver/blob/v0.1.4/cmd/fake-dra-kubeletplugin/state.go#L165-L191
func (s *DeviceState) getResourceModelFromAllocatableDevices() resourceapi.ResourceModel {
var instances []resourceapi.NamedResourcesInstance
for _, device := range s.allocatable {
instance := resourceapi.NamedResourcesInstance{
Name: strings.ToLower(device.uuid),
Attributes: []resourceapi.NamedResourcesAttribute{
{
Name: "uuid",
NamedResourcesAttributeValue: resourceapi.NamedResourcesAttributeValue{
StringValue: &device.uuid,
},
},
{
Name: "model",
NamedResourcesAttributeValue: resourceapi.NamedResourcesAttributeValue{
StringValue: &device.model,
},
},
},
}
instances = append(instances, instance)
}
return resourceapi.ResourceModel{
NamedResources: &resourceapi.NamedResourcesResources{Instances: instances},
}
}
kubelet が新しく ResourceSlice を作成する流れは以下の通りです。
- kubelet が NodeListAndWatchResources の RPC を呼び出して DRA driver の kubelet-plugin と接続 (source)
- ResourceModel を受け取るまで待つ (source)
- ResourceModel を受け取ったら後から参照できるようにキャッシュに保存 (source)
- ワークキューにメッセージを積んで ResourceSlice 作成を指示 (source)
- ResourceSlice の処理を行うワーカーがキャッシュから対象のリソースの情報を取得 (source)
- 取得したリソースの情報をもとに ResourceSlice を作成 (source)
ResourceSlice は <node_name>-<driver_name>-<random string> で作成されるため、リソース名が可能な限り衝突しないようになっています。fake-dra-driver の情報をもとに kubelet が作成した ResourceSlice は以下のようになっています。8 個の Fake デバイスが刺さった Node を想定した実装となっているため、namedResources.instances の下に 8 個のデバイスの情報 (UUID とモデル) が格納されています。
ResourceSlice のサンプル
apiVersion: resource.k8s.io/v1alpha2
driverName: fake.resource.3-shake.com
kind: ResourceSlice
metadata:
creationTimestamp: "2024-04-09T06:00:18Z"
generateName: fake-dra-driver-cluster-worker-fake.resource.3-shake.com-
name: fake-dra-driver-cluster-worker-fake.resource.3-shake.com-rxbh6
resourceVersion: "1464"
uid: de1c599b-9d1f-4385-98b1-2dff0573dcd5
namedResources:
instances:
- attributes:
- name: uuid
string: FAKE-a1e41d9f-5b3a-d8f8-1b08-177352484a68
- name: model
string: ULTRA_10
name: fake-a1e41d9f-5b3a-d8f8-1b08-177352484a68
- attributes:
- name: uuid
string: FAKE-5d25fe96-37be-6082-ae92-d398d7d7038d
- name: model
string: ULTRA_10
name: fake-5d25fe96-37be-6082-ae92-d398d7d7038d
- attributes:
- name: uuid
string: FAKE-9fe9fc83-a0ec-2e8a-8749-e1a9423947d4
- name: model
string: ULTRA_10
name: fake-9fe9fc83-a0ec-2e8a-8749-e1a9423947d4
- attributes:
- name: uuid
string: FAKE-68cb1988-7257-2eff-4c68-f58c5ba83bd8
- name: model
string: ULTRA_10
name: fake-68cb1988-7257-2eff-4c68-f58c5ba83bd8
- attributes:
- name: uuid
string: FAKE-b944f3e9-c628-b1dc-edb1-262aaee87362
- name: model
string: ULTRA_10
name: fake-b944f3e9-c628-b1dc-edb1-262aaee87362
- attributes:
- name: uuid
string: FAKE-5bb9fd80-12c1-17f8-de47-7a3e76d565dc
- name: model
string: ULTRA_10
name: fake-5bb9fd80-12c1-17f8-de47-7a3e76d565dc
- attributes:
- name: uuid
string: FAKE-4d6cc6e5-e22d-3807-f026-783d55841ea5
- name: model
string: ULTRA_10
name: fake-4d6cc6e5-e22d-3807-f026-783d55841ea5
- attributes:
- name: uuid
string: FAKE-0fc445e2-800c-177d-95e6-7fdad6b2427a
- name: model
string: ULTRA_10
name: fake-0fc445e2-800c-177d-95e6-7fdad6b2427a
nodeName: fake-dra-driver-cluster-worker
kubelet が ResourceSlice を作成したことで、kube-scheduler やそれ以外のコンポーネントが Node 毎に割り当て可能なリソースの情報を参照することができます。
これまで GPU の情報を Node Feature Discovery を使って Node のラベルとして公開していましたが、Structured Parameters を使えば ResourceSlice を通して公開できるようになりました。公開した情報は後述するように CEL の式を使って数値を比較するなど、ラベルよりも柔軟にリソースのフィルターが可能となります。NVIDIA の DRA driver は製品名などの情報に加えて NVIDIA GPU や CUDA のドライバのバージョンも公開しています。 (source)
Pod の起動までの流れ
ユーザーがベンダー固有のパラメータを利用して Pod を起動していく処理を見ていきます。fake-dra-driver では以下のように Fake デバイスの個数 (count) とそれらを仮想的に分割する個数 (split) を指定できます。また、セレクタを使用することで特定のモデルの Fake デバイスを利用するといったことも指示できます。
apiVersion: fake.resource.3-shake.com/v1alpha1
kind: FakeClaimParameters
metadata:
name: multiple-fakes
spec:
count: 4
split: 2
selector:
model: ULTRA_100
上記の FakeParameters は ResourceClass もしくは ResourceClaimTemplate に紐づけることができます。今回は ResourceClaimTemplate に紐付けてみます。
apiVersion: resource.k8s.io/v1alpha2
kind: ResourceClaimTemplate
metadata:
name: multiple-fakes
spec:
spec:
resourceClassName: fake.3-shake.com
parametersRef:
apiGroup: fake.resource.3-shake.com
kind: FakeClaimParameters
name: multiple-fakes
ULTRA_100 モデルの複数の Fake デバイスを使用する Pod を作成します。先ほどの ResourceClaimTemplate を参照し、Pod の resources に埋め込みます。Kubernetes 1.30 より前の DRA の利用方法と特に変更箇所はありません。
apiVersion: v1
kind: Pod
metadata:
name: pod0
labels:
app: pod
spec:
terminationGracePeriodSeconds: 3
containers:
- name: ctr0
image: cgr.dev/chainguard/wolfi-base:latest
command: ["ash", "-c"]
args: ["export; sleep infinity"]
resources:
claims:
- name: fakes
resourceClaims:
- name: fakes
source:
resourceClaimTemplateName: multiple-fakes
ResourceClaimParameters への変換
では、DRA driver controller が FakeClaimParameters を ResourceClaimParameters に変換する処理を見ていきましょう。fake-dra-driver には新しく ClaimParametersGenerator の処理を追加しています。
- Dynamic client から FakeResourceParameters のカスタムリソース用の Informer を作成 (source)
- Informer にイベントハンドラを設定して、FakeClaimParameters の作成と削除を契機に実行する処理を登録 (source)
- FakeClaimParameters のカスタムリソースが追加されたら、FakeClaimParameters から ResourceClaimParameters を作成 (source)
FakeClaimParameters から ResourceClaimParameters へのマッピングは DRA driver の実装者の責務です。fake-dra-driver の場合は、newResourceClaimParametersFromFakeClaimParameters で実装しています。
- FakeClaimParameters に指定された Fake リソースの個数 (
count) 分だけ ResourceRequest を作成 - FakeClaimParameters にセレクタが設定されている場合は CEL の式を生成し、そうでない場合はどのリソースでも許可するという意味で
trueを指定 (source) - FakeClaimParameters の情報から生成した ResourceRequest を埋め込んだ ResourceClaimParameters を生成 (source)
ResourceClaimParameters のサンプル
apiVersion: resource.k8s.io/v1alpha2
driverRequests:
- driverName: fake.resource.3-shake.com
requests:
- namedResources:
selector: attributes.string["model"] == "ULTRA_10"
vendorParameters: null
- namedResources:
selector: attributes.string["model"] == "ULTRA_10"
vendorParameters: null
- namedResources:
selector: attributes.string["model"] == "ULTRA_10"
vendorParameters: null
- namedResources:
selector: attributes.string["model"] == "ULTRA_10"
vendorParameters: null
vendorParameters:
count: 4
selector:
model: ULTRA_10
split: 2
generatedFrom:
apiGroup: fake.resource.3-shake.com
kind: FakeClaimParameters
name: multiple-fakes
kind: ResourceClaimParameters
metadata:
creationTimestamp: "2024-04-21T01:50:16Z"
generateName: resource-claim-parameters-
name: resource-claim-parameters-k4jpz
namespace: test7
ownerReferences:
- apiVersion: fake.resource.3-shake.com/v1alpha1
blockOwnerDeletion: true
kind: FakeClaimParameters
name: multiple-fakes
uid: 0accc427-e2b3-4d6d-b946-cacabc31f9d9
resourceVersion: "1247"
uid: e97b149e-c2f0-41f1-bd7e-113beaaeeb30
shareable: true
ResourceClaim の作成
ResourceClaimTemplate から ResourceClaim を作成するのは Kubernetes Controller Manager (KCM) の中にいる resourceclaim controller の役割です。
- イベントハンドラで Pod の作成や更新、削除のイベントを検知して ResourceClaimTemplate から ResourceClaim を作成 (source)
- Pod と生成した ResourceClaim の紐付けを ResourceClaim の
.status.reservedForに記録 (source) - ResourceClaim の
.status.allocationは kube-scheduler が Pod をスケジューリングする中で情報を書き込む - リソースを利用していた Pod が停止した場合に ResourceClaim の
.status.allocationを削除してリソースを解放する必要があり、それは resourceclaim controller の役割 (source)
KCM により ResourceClaim が作成されると、kube-scheduler は Pod のスケジューリング処理を開始します。
Pod のスケジューリング
kube-scheduler には Scheduling Framework を用いた Scheduler Plugin である dynamicresources が実装されています。dynamicresource の Scheduler Plugin は PreEnqueue / PreFilter / Filter / PostFilter / PreScore / Reserve / PreBind / Bind / EnqueueExtensions とほぼ全ての拡張点が実装されています。
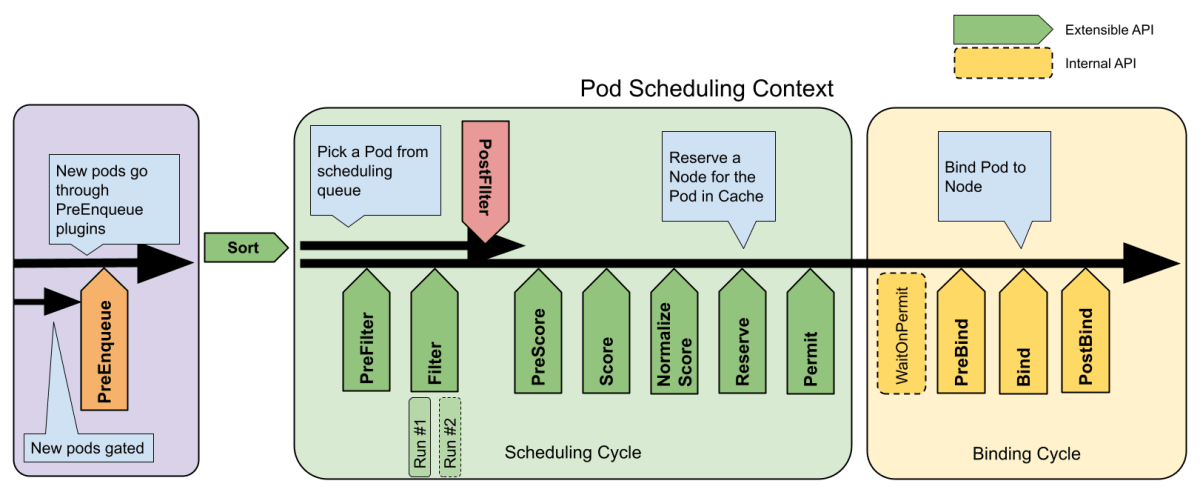
出典: https://kubernetes.io/docs/concepts/scheduling-eviction/scheduling-framework/
- PreFilter 拡張点で ResourceClassParameters / ResourceClaimParameters のフィルターで指定した CEL の式をコンパイルして CycleState に書き込む (source, source)
- PreFilter 拡張点でノードが公開しているリソースの情報 (ResourceSlice の NamedResources) を CycleState に書き込む (source, source)
- Filter 拡張点で候補の Node に紐付いた NamedResources に対して CEL を実行して条件を満たす Node を絞り込む (source, source, source)
- Reserve 拡張点の中でリソースの払い出しを要求し、ResourceClaim の
.status.allocationに設定される対象のノードの情報 (kubernetes.io/hostnameによるセレクタ) とリソースの情報を生成する (source, source, source)- スケジューリングサイクルは Pod 毎に直列で実行されます。API サーバを経由したオブジェクトの更新などの重たい処理は他の Pod のスケジュールをブロックする可能性があります。そのため、Reserve 拡張点では ResourceClaim の
.status.allocationの更新は行わず、あくまで更新する内容を CycleState に保存するだけです。 - inFlightAllocations と呼ばれる排他制御可能な map にも情報を保存します。この情報を PreFilter 拡張点で使います。DRA では複数の Pod が同じリソースを共有できるため、Pod A が既に要求したリソースを Pod B でも参照する可能性があります。また、Scheduling Cycle は直列で実行されますが、Binding Cycle は並列で実行されます。そのため、Binding Cycle で Pod A と Pod B の PreBind 処理の実行開始のタイミングが逆転する可能性があります。inFlightAllocations でリソースの払い出しの状況を追跡し、リソースの払い出しが完了してから Pod B のスケジュールを開始します。現在払い出し中の ResourceClaim の情報を追跡し、PreFilter 拡張点で払い出し中の ResourceClaim を参照している Pod のスケジュールは開始しないように制限しています。(source)
- inFlightAllocations とは別に volumebinding plugin でも利用されている AssumeCache を使った claimAssumeCache も用意されています。claimAssumeCache は Informer cache とは別に自前で管理している ResourceClaim のキャッシュで、最新の ResourceClaim の情報を使って Pod の配置を考えることができます。PreBind 拡張点で
status.reservedForのフィールドを更新した後に、AssumeCache として保持している ResourceClaim の情報を更新します。(source) Binding Cycle は Scheduling Cycle とは異なり、処理をブロックしません。そのため、PreBind 拡張点で更新した ResourceClaim の内容が Informer キャッシュに反映されるまでにラグがあり、その間に新しい Scheduling Cycle が開始され最新でない ResourceClaim の情報を使ってスケジュール先のノードの配置を決定してしまうかも知れません。(可能性としては低い) これを避けるために API サーバを経由しないローカルのキャッシュを保持しています。claimAssumeCache は PreFilter 拡張点で割り当て済みのリソースを集計するために使用します。ResourceSlice で公開されている利用可能なリソースの情報と inFlightAllocations で現在払い出し中のリソースの情報、claimAssumeCache の中に保存された最新の ResourceClaim のstatus.reservedForの情報から割り当て済みのリソースを特定します。(source)
- スケジューリングサイクルは Pod 毎に直列で実行されます。API サーバを経由したオブジェクトの更新などの重たい処理は他の Pod のスケジュールをブロックする可能性があります。そのため、Reserve 拡張点では ResourceClaim の
- PreBind 拡張点で ResourceClaim の
.status.allocationを追加 (source, source) - PreBind 拡張点で ResourceClaim の
.status.reservedForを追加し、どの Pod がこの ResourceClaim を利用する予定か情報を書き込む (source) - PreBind 拡張点で CycleState から払い出しの終わった ResouceClaim の情報を削除 (source)
今回は Structured Parameters に関わる処理だけを見てきましたが、最終的に kube-scheduler が Pod の配置先の Node を決定し、DefaultBinder により Pod の .spec.nodeName が設定されます。
kubelet による Pod の起動
kubelet による Pod の起動の流れは Kubernetes 1.29 以前と同じです。
- kubelet が自身の Node で起動すべき Pod を見つける
- kubelet は gRPC API である NodePrepareResources を呼び出して Node 上のリソースを準備するための情報をまとめるように DRA driver に依頼
- fake-dra-driver では、kube-scheduler が Pod のスケジュールの中で割り当てたリソースの情報を StructuredResourceHandle 経由で教えてもらい、FakeClaimParameters のパラメータの情報も埋め込まれているので割り当てるリソースの情報を整理 (source)
- fake-dra-driver は Prepare を呼び出して、リソースの払い出しを行う
- fake-dra-driver の場合は、特にリソースの払い出しは行わず、Containerd Device Interface (CDI) を通してコンテナの環境変数に Fake リソースの情報を書き込むだけ (source)
- fake-dra-driver は CDI の JSON ファイルを作成し、指定されたパスに配置する (source)
- fake-dra-driver は NodePrepareResources の処理を完了して、kubelet に CDI の情報などを返却する
- kubelet は ResourceClaim の annotation に JSON 形式の CDI の情報を保存 (source)
- kubelet が再起動しても復旧できるようにファイルベースの checkpoint の仕組みを使って状態を保存 (source)
- PodSandbox の作成など通常の Pod の起動の処理を続ける
Pod が起動するまでの流れは以上となります。
Kubernetes 1.31 以降の改善
Dynamic Resource Allocation (DRA) は Kubernetes 1.31 以降も大きな変更が予定されており、Kubernetes 1.32 でベータ昇格を目指しています。
WG-Device-Management の発足
KubeCon Europe 2024 の Contributor Summit の Unconference で議論があり、WG-Device-Management の発足が決まりました。kubernetes/community#7805 で WG のスコープやゴールを整理し、正式に WG として認められました。DRA は 2023 年 11 月から WG-Batch に合流して議論を進めてきました。今後は WG-Device-Management の中で DRA 以外の要件も含めて議論・開発を進めていくようです。
WG-Device-Management と時を同じくして、Kubernetes 上で AI / ML の Inference ワークロードを動かすための基本要素の開発などを進める WG-Serving も発足しました。既存の WG-Batch や WG-Serving から要望を受けながらより実用性のある機能も追加されていくはずです。
Classic DRA
Kubernetes 1.26 で導入された KEP-3063: Dynamic Resource Allocation with Control Plane Controller (a.k.a. Classic DRA) より先に Kubernetes 1.30 で導入された KEP-4381: Dynamic Resource Allocation with Structured Parameters の機能の安定化を進めるようです。既存の DynamicResourceAllocation の Feature Gate で有効になるのは Structured Parameters の機能となり、DRAControlPlaneController の Feature Gate で有効になるのは Classic DRA の機能となります。
Classic DRA には Cluster Autoscaler などの外部のコンポーネントとの連携が難しいことやスケジューラーのスループットに影響を与えるなど懸念がありますが、Network-attached accelerator など当てはまるユースケースがあるのではと考えているようです。Classic DRA の仕組みが今後残るのか消えるのか、別の仕組みに生まれ変わるのかはユースケース次第になりそうです。
kubelet v1alpha2 gRPC API の削除
DRA: remove support for v1alpha2 kubelet gRPC API で kubelet の v1alpha2 の API が削除され、v1alpha3 への移行が必須となりました。これにより、Structured Parameters で利用する NodeListAndWatchResources のインターフェイスの実装が必須となります。fake-dra-driver では、
feat: Bump kubelet gRPC API to v1alpha3 で対応しています。Kubernetes 1.31 で resource.k8s.io グループを v1alpha3 を導入する都合で破壊的変更が避けられず、kubelet の gRPC API も v1alpha3 のみをサポートする形にしたようです。
Cluster Autoscaler との連携
Cluster Autoscaler は kube-scheduler の Scheduling Framework の PreFilter / Filter 拡張点を実行して、追加する予定の Node が Pod の要件を満たしているかシミュレーションしています。ResourceSlice として Node で利用可能なリソースの情報を公開し、kube-scheduler の dynamicresource plugin の PreFilter / Filter 拡張点で CEL ベースのフィルターを実行できるようになりました。これにより、Cluster Autoscaler が割り当てるリソースの詳細を知ることなしに連携できるようになります。
ただ問題なのは、dynamicresource plugin はローカルの AssumeCache に ResourceClaim の最新の情報を保持しています。
- AssumeCache を PreFilter / Filter 拡張点で利用し、Pod の配置先の Node をフィルタリングしている
- AssumeCache の情報は PreBind / Unreserve 拡張点で更新・削除される
Cluster Autoscaler は PreFilter / Filter 拡張点しか利用していないため、独自に AssumeCache に変更を加える仕組みが必要です。そのため、kube-scheduler のイベントハンドラの仕組み (イベント駆動で Pod を activeQ に移動する仕組み) に AssumeCache を統合し、ResourceClaimCache() と呼ばれる関数を使って AssumeCache を外部から操作できるようになる予定です。
Cluster Autoscaler はノードプールの台数を増減するだけなので、既存の Node の ResourceSlice の情報を使って新しく追加した Node に Pod が配置できるかシミュレーションすることはできそうです。ただ、Karpenter や GKE のノード自動プロビジョニング (NAP) など任意のインスタンスを起動 or ノードプールを作成するタイプのツールとどう連携するのかは気になります。Karpenter は Scheduler Plugin を利用していないので、クラウド側のインスタンスタイプの情報を別途取得して、ResourceSlice の情報と合わせてシミュレーションすることになるのでしょうか。
構造化されたモデルの拡張
klueska/nvk8s-resourcemodel では ResourceSlice の NamedResource に新しくフィールド (SharedLimits と Resources) を追加し、リソース毎に割り当て可能な上限 (e.g. NVIDIA GPU の場合、メモリは 40Gi, MPS のプロセス数は 96, ...) と Pod が割り当てられた際に実際に消費するリソースの情報 (e.g. MIG で 2g.10gb として分割するとメモリは 9856Mi, MPS のプロセス数は 28, ...) をそれぞれ公開する試みです。kube-scheduler は割り当て可能なリソースの上限を超えないように、実際に消費するリソースの情報を計算しながら Pod の配置を考えることができます。これにより、共有・分割可能なリソース (e.g. NVIDIA GPU の MIG, Intel GPU の Virtual Function) を参照する Pod を賢く配置することができるようになります。
まとめ
KEP-4381: Structured Parameters for Dynamic Resource Allocation の登場により、DRA は以前に比べてシンプルなアーキテクチャになったように感じます。Structured Parameters だけをサポートする DRA driver であればコードもスッキリします。fake-dra-driver のコードも大部分を削除することができました。KEP-4381 は Kubernetes 1.32 でベータ昇格を目指していることもあり、Kubernetes 1.31 は DRA に関する破壊的変更が多く入る予定です。Cluster Autoscaler との連携や構造化されたモデルの拡張など気になる部分がたくさんあるので、今後も定期的に記事にまとめたいと思います。
Discussion