Kubernetes の upstream のキャッチアップ
先日、Kubernetes Meetup Tokyo #59 で「KEP から眺める Kubernetes」というタイトルで発表しました。発表の後で Kubernetes の upstream のキャッチアップ方法について質問を受けました。その場で回答はしたのですが、ちょうど社内の共有会で似たような話をしたところだったので、加筆修正したものを公開しておきます。
はじめに
Kubernetes の upstream を追いかけ始めて 1 年ちょっと経ったので、その経験をまとめます。Kubernetes の upstream やエコシステムを観察しているだけで、コントリビュータではありません。間違っている部分があったらごめんなさい...!
Kubernetes の開発体制や開発者の所属組織の分布、新しい機能を追加する際のプロセスの話を簡単にしてから私のキャッチアップ方法についてまとめています。最後にこれまでに観測できた出来事をいくつか紹介します。
Special Interest Group (SIG)
Kubernetes の世界は広大です。縦割り・横割りなど粒度は様々なのですが、テーマ毎に Kubernetes の世界を分割して、専門家やその分野に興味のある人たちで集まって開発を進めています。このグループのことを Special Interest Group (SIG) と呼びます。各 SIG には Chair (SIG の活動の取りまとめ役) と Tech Lead (SIG で進めている技術的な課題の管理) がそれぞれ 2 名以上います。SIG によって人数は様々ですが、その下でメンバーが活動しています。
開発者の所属組織の分布
Community Group に SIG の一覧と各 SIG の Chair が記載されています。Chair の組織を見て貰うと分かる通り、Google と RedHat の人が多いです。Tech Lead に関しても kubernetes/community のページで確認できますが、こちらは所属組織までは記載されていません。ただ、こちらも Google と RedHat の人が多いです。
CNCF はコミュニティ活動の正常性を監視するための Grafana ダッシュボードを公開しています。例えば、Company Statistics by Repository Group のダッシュボードを見てみると Kubernetes の開発者の所属組織の分布が大まかに分かります。指標として Contributions を指定しているので、コミットの他にレビューやコメント、Issue / PR の作成などが含まれます。ベストな指標ではないかもしれませんが、今回はこの指標で見ていきます。
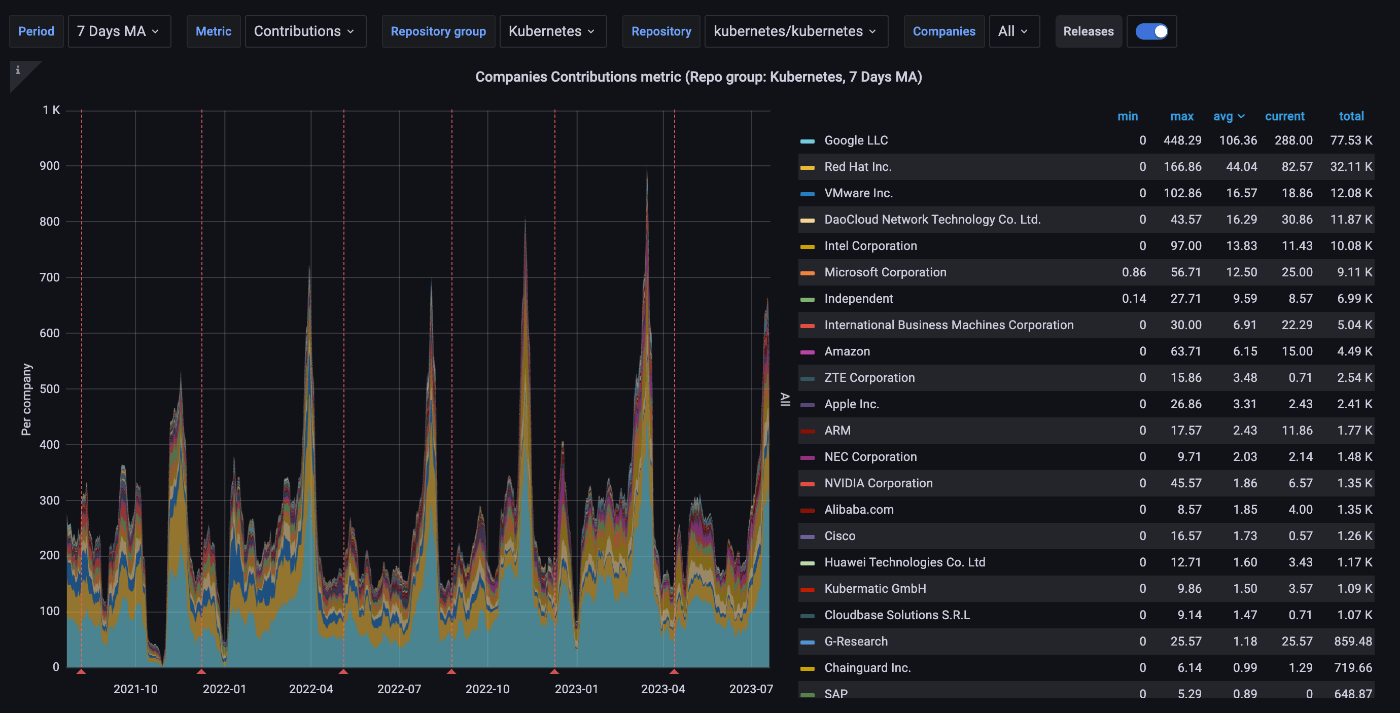
- 曜日による影響を抑えるために、7 日間の移動平均を取っています。
- 対象のリポジトリを Kubernetes に制限しています。
- 平均を見ると Google の開発者が多く、RedHat がその後に続いていることが分かります。RedHat は Kubernetes をフォークして OpenShift 用にカスタマイズしている (openshift/kubernetes) ので、その影響があるのかもしれません。
- VMware も頑張ってはいるのですが、最近は落ち込み気味です。この原因については後ほど触れます。
- DaoCloud という中国の企業が順調に勢力を拡大しています。Alibaba よりも存在感があります。SIG Cluster Lifecycle で kubeadm のメンテナでそれ以外にも SIG Node や壊れた E2E テストの面倒、Issue のトリアージなどをやってらっしゃる pacoxu さんや SIG Scheduling の approver である kerthcet さんがいるのと、carlory さんなど他の方も参戦していて勢いがあります。
- Intel は CPU のトポロジ関連、Device Plugins や Dynamic Resource Allocation などのハードウェアアクセラレータ関連の機能の改善をメインでやっています。また、それ以外にも kubernetes/component-base で構造化ログ周りの改善や Linter の導入など手広くやっている pohly さんもなんかもいます。
- Microsoft は SIG Auth 関連で強いのと Windows 対応周りの面倒を見ているので、指標の値よりも存在感はある気がします。
- Amazon は今まで存在感がなかったのですが、最近はあることがきっかけで存在感を増しています。この要因についても後ほど触れます。
Kubernetes Enhancement Proposal (KEP)
Kubernetes に新しい機能を追加する場合、Kubernetes Enhancement Proposal (KEP) を発行する必要があります。Kubernetes の開発者は、KEP を通して実装の詳細や安定化に向けた方針を議論します。KEP は機能の実装状況や今後の動きを把握するためにも使われます。Kubernetes Enhancement Proposal Process に書かれているように、Rust の RFC の仕組みを参考にして作られています。Rust の RFC が Python を参考にしているので大元を辿ると PEP (Python Enhancement Proposal) です。KEP の一覧はダッシュボードで確認できます。
新しく KEP を発行する場合は、事前に k/k の Issue や Slack、SIG のミーティングで KEP についての議論と承認を受ける必要があります。KEP を発行することになったら、 進行を追跡できるように Issue を作成します。この Issue 番号が KEP の番号になります。それから KEP テンプレートを埋めて PR を作成し、実装の詳細を詰めたり、Production Readiness Review を受けたりします。
貴重な経験者談が日本語で読めるので、KEP のプロセスについてはこちらを参照下さい。
情報源
ブログ記事や Twitter 以外にも、自分で情報を漁っています。
GitHub
GitHub で Kubernetes やエコシステム周りのリポジトリを watch しています。watch することで Issue / PR の通知が確認できるようになります。
- 全ての Issue / PR を読むのは無理なので、取捨選択しながら読んでいます。
- マージされた PR やクローズされた Issue を優先的に見ます。
- 平日は寝る前の 1-2 時間くらい、休日は暇な時 (1-6 時間?) に眺めています。
- 最近は余裕も出て来たので 先週の Kubernetes を見つつ、自分が追ってきた内容や理解の復習をしています。
- PC だと GitHub の Notifications のページで見ていきます。
- コードを追うのは難しいですが、議論だけならスマホでも見ています。
-
GitHub Mobile を最近使っています。
- Issue / PR のスレッドが多くなった時に PC サイトだと最初のスレッドから展開されるのですが、GitHub Mobile だと新しいスレッドから展開されるので嬉しいです。(PC サイトの方も同じにして欲しい)
-
GitHub Mobile を最近使っています。
- 興味のない Issue / PR は Unsubscribe していきます。追わないと決めた SIG の話題も Unsubscribe した方が効率良くなりそうですが、何か良い情報が得られるかもしれないという思いに負けて Unsubscribe できていないです。
- 依存関係の更新
- 細かいリファクタリング (Go の ioutil パッケージの非推奨に伴う切り替えの PR が一時期多かった…)
- chore 系
- Windows 関連 (Microsoft の方見ていたらごめんなさい🙇)
- 気になる話題は Save して一覧で見た時に分かりやすいようにしています。Save している Issue / PR の通知は優先して見ます。
- Notifications を見るときはタイトル以外に画像の赤枠の部分が重要です。この場合は、
+1とあるので pacoxu さんと Bot の未読のコメントがあることが分かります。こういう場合は、興味のあるタイトルの Issue / PR だと中身を確認します。

- 他にも以下の画像の場合だと、最後にコメントしているのが Bot で
+1などの表示がないことから Bot しかコメントしていないことが分かります。こういう Issue / PR は中身を確認しません。Bot が動きのない Issue / PR を整理するためにコメントを付けているか、PR だと conflict が発生していて rebase してねのコメントです。そのままの状態で放置しておきます。Notifications が溜まってくるとストレスな人間なので、いくつか Issue / PR の内容を確認し終わった後に定期的にこういった Bot がコメントしているだけの Issue / PR を既読にして Done 状態に持っていくことで平静を保っています。無意味な作業ではあるのですが、長く続けていくには結構重要なルーティンだと思います。

- 以下の画像のように
+10と複数のコメントが付いているのと Bot を含めた複数の人間が関与しているものに関しては新しい Issue / PR の可能性が高いです。こういう Issue / PR はタイトルを見て興味があれば優先的に見ています。ただ、太古の Issue / PR が掘り起こされただけの場合もある (その場合は Bot が最後に来ることは少ない?) ので、中身を見てみないとやっぱり判別は付きません。

GitHub の通知を見始めた頃は何を話しているのか全く分かりませんでした。コンテキストを知らないので当然ではあるのですが、技術的な話も全く理解できませんでした。分からないものを読むことに抵抗がないのと、後で分かるようになってきた時の楽しさが勝つので、半年くらい分からない状態で耐えました。1 年ちょっと経って PR の変更内容に関してはちゃんと読めば何となく理解できるようになったかな (体感 30% くらい?) ぐらいなので、まだまだ先は長いです。分からない状態の時にまずやったのが、人を覚えることでした。この人はどこの所属でどの SIG にいて何が専門なのかが分かると、どういう立場からコメントしているのかが見えてきました。Issue / PR のコンテキストに関しては、めげずに追い続けることで半年くらいで掴めて来ました。
Issue / PR の中身まで読んでるやつ
全ての Issue / PR の中身を読んでいる訳ではありません。Issue / PR のタイトルで気になるものがあった場合に中身まで読むかどうかです。ラフではありますが、優先度順に並べているつもりです。
-
- KEP 置き場。Kubernetes の新しいマイナーバージョンのリリースサイクルが始まってから KEP フリーズの時期までは KEP の議論が活発になります。開発者の多くが夏休みの宿題は休み明け直前までやらない派なので、freeze 前の駆け込みラッシュは凄まじいです。
-
- 言わずもがな Kubernetes のコア機能の開発が進められているところです。こちらも機能追加のコードフリーズ前は追うのが大変になります。SIG Auth や SIG Storage、SIG Cluster Lifecycle 関連のものはタイトルしか読まなかったりします。メルカリの sanposhiho さんがスケジューラ周りの実装や PR のレビューをバシバシやっていたり、NTT の mochizuki875 さんも Issue を拾って調査・修正していたりして尊敬しかないです。
-
- 高レイヤーなコンテナランタイム。GKE や EKS など多くのクラウドプロバイダーや Docker でも使われています。Kubernetes の CRI 周りの変更や Kubelet の変更に合わせて containerd に変更が入ることが多いです。2.0 の破壊的変更に向けて実験的な機能の安定化やお掃除が進んでいるようです。
-
- 低レイヤーなコンテナランタイムの参照実装。GKE や EKS など多くのクラウドプロバイダーで使われている。runc のバグやパフォーマンス劣化は深刻なので軽く眺めてます。低レイヤーな話なのでついていけないですが、それはそれで楽しいです。
-
- Pod 内で動いているコンテナのメトリクスを収集している Kubelet に同梱されているやつ。cgroup v2 の PSI メトリクス の追加の PR (google/cadvisor#3083) のマージを待っています。
-
- Container Native Interface (CNI) の仕様について話をするところ。CNI 1.1 に向けて STATUS (containernetworking/cni#1003) や GC (containernetworking/cni#981) などの新しい挙動の策定を進めているようです。GKE Dataplane v2 で使われている Cilium など CNI plugin に影響する仕様なので目を通すようにしています。
-
- Kubernetes の CI で使うために開発された Docker in Docker で動く軽量な Kubernetes クラスタ。個人的に良く使っているので、眺めてます。メンテナ不足もあり、最近は新しい機能の追加に消極的で、Kubernetes のバージョンへの追従がメインです。最近だと正式に GPU 対応が入りそうです。(kubernetes-sigs/kind#3290)
-
- GKE で利用されている Ingress Controller の実装。IPv4 / IPv6 デュアルスタック LB 対応やマルチネットワーク (?)、check-ingress-gce なる CLI ツールの追加や Google Cloud の API を叩く回数を減らしたり、Gateway API があるにしては活動は活発です。Google さん Gateway API の実装も OSS として公開してくれると嬉しいです。
-
- GKE が内部的に使っている Cloud Provider なので GKE の新機能の動向が見れたり。直近はノードに複数 NIC を刺す (将来的には Pod にも?) ための対応をしてる雰囲気があります。PR だけだとイマイチ何をしているのかイメージがつきません。
-
- ML / HPC 向けに Job の Deployment / StatefulSet 的な立ち位置のものを作ろうプロジェクトです。新しいプロジェクトなので動きが激しくて楽しいです。CyberAgent の tenzen-y さんも動いてます。
-
kubernetes-sigs/apiserver-network-proxy
- GKE の private cluster でも有効化予定の Konnectivity Servie の中身。コントロールプレーンと Kubelet の間の通信がこれまで SSH tunnel だったが、gRPC の双方向通信 (HTTP CONNECT による通信もあるにはある) に置き換えられる。良く問題を起こすので軽く眺めている。Google の人たちだけで開発が進められていたが、最近は Microsoft の人も開発に参加していて良い感じです。
-
- DaemonSet として実行され、PTP plugin 用の CNI の設定ファイルを生成して、ノードに配置してくれる GKE 固有のやつ。
-
- Kubernetes の Controller を書いた時などに使える E2E フレームワーク。Kind のクラスタを作ったり、Helm chart をインストールしたり、テストが終わったらお片付けしたりも抽象化してくれていて便利です。
-
kubernetes-sigs/cloud-provider-kind
- クラウドプロバイダー向けの機能を Kind で検証するためのダミーのクラウドプロバイダーの実装。ローカル環境でクラウドリソースを扱うような処理をエミュレートするのに便利です。
-
- 7 人の代表が務める Steering Committee (コミュニティのガバナンス) の動きが見れます。最近はコントリビューターが身につけられる (KubeCon とかでコントリビューターか見分けが付く) グッズ制作の話 (?) とかやってます。(kubernetes/steering#265)
Issue / PR のタイトルだけ読むやつ
-
kubernetes/test-infra
- Kubernetes の CI 周りの諸々のツールや設定が置かれている場所。テスト結果の可視化や Flaky なテストの特定、テストログの管理、Bot による Comment Ops などいろいろ。色々な組織や SIG の関係者が集まっているので、カオス。Kubernetes の大きめの変更は金曜日にマージして週末活動が少ない間に様子を見て、月曜日に直すみたいな僕らの感覚とはちょっと違ったやり方をしています。最近は CI の一部を Google Cloud (GKE) から AWS (EKS) に移す作業をやっていた。Google Cloud が 3M$ / year のクラウドクレジットを CNCF に提供していて、それに続いて AWS も 3M$ / year のクラウドクレジットを提供してくれるようになったので絶賛移行中。Google Cloud の場合は、CI が動いているインフラのオンコール担当がいるくらいちゃんと管理していて、気分転換に眺めることがあります。
-
kubernetes-sigs/kubetest2
- Kubernetes の E2E テストで仕様する Kind / GKE クラスタを作成して、Ginkgo ベースの E2E テストを実行して、クラスタを停止するといった一連の流れを良い感じに実行してくれます。 クラスタを作る部分とテストを実行する部分は拡張可能で、EKS も独自に aws/aws-k8s-tester を作って内部で使っているようです。
-
containernetworking/plugins
- コミュニティで開発が進められている CNI plugin の集まったリポジトリです。GKE も利用している loopback / PTP / bandwidth などの CNI plugin もいるのでタイトルだけ見て関係ありそうなものを見ています。
-
kubernetes-sigs/gateway-api
- Ingress の進化系の Gateway API の仕様について議論されているところです。Gateway API は Kubernetes のコア機能として開発されていません。Kubernetes のリリースサイクルに縛られず、ユーザーのフィードバックも得られやすいということで、あえて CRD として実装する道を選びました。本当は内容まで見たいのですが、流れが早く追い切れないです。
Slack
Kubernetes 公式の Slack チャンネルに参加しています。
-
#kubernetes-usersは実質機能していないので、抜けています。 - 質問がある場合は、
#sig-networkなどのSIG の専用チャンネルでした方が良いです。ただ、スルーされることが多いので、興味を持ってもらえるように文章を工夫するなりするしかないです。 -
#sig-networkなどの SIG の専用チャンネルだと深い質問があるのと、GitHub の Issue / PR で議論する前に Slack で事前に相談するパターンがあるので眺めてます。
Mailing List
-
kubernetes-dev
- この Google Group に入っていないと見れない Google Docs や Google Slides があるので入った方がお得です。開発者向けのアナウンスなんかも飛んできます。
-
kubernetes-sig-network
- SIG Network をメインで追いかけているので入ってます。アナウンス以外にもアイデアレベルの機能の議論などもあります。
-
kubernetes-sig-node
- SIG Node も軽く追いかけているので入ってます。メーリングリストはそんなに動きが激しくないのでちょうど良いです。
-
kubernetes-sig-scheduling
- スケジューラ関連の Issue / PR も少しずつ追えるようになってきたので少し前に参加しました。
-
kubernetes-sig-apps
- Deployment や StatefulSet などコアなリソースに関わる議論があるかもなので入っています。
SIG Meeting
隔週である SIG Network のミーティングの録画は見るようにしています。録画は YouTube に上がっています。SIG によってチャンネルが異なることがあります。SIG Network の録画は Kubernetes のチャンネルにあります。録画のアップロードは遅れがちなので、Issue / PR / Slack の「何でこんなやり取りしているんだろう」の答え合わせになります。
たまに SIG Node のミーティングの録画も見ます。SIG Node の録画は kubernetes-sig-node のチャンネルにあります。最近更新が止まっていて困っています。
KubeCon の録画やスライド
YouTube の CNCF チャンネルに 2-3 週間後に上がってきます。
観測した出来事
開発者のやり取りを見るのは「どうぶつの森」感覚です。今日はその中でも重大なバグの発覚 / 対応の流れ (GKE のここが好き話も含む) と AWS の存在感の話を紹介します。
Kubernetes 1.22 の Pod ライフサイクル関連のやばいバグ
2022/4/11 に Pod のステータスが Terminated, OutOfMemory, OutOfcpu, ContainerStatusUnknown になった場合に、古い Pod にリクエストが流れ続けてしまう問題が k/k#109414 で報告されました。Pod IP は新しく起動した別の Pod に紐付いているのに、なぜか古い Pod にリクエストが流れるというものでした。Spot VM を使っている場合、ノードが利用できなくなると別のノードに Evict されて Terminated 状態な Pod が残るので発生確率が高くなることが予想されます。ただ、この時点では再現手順はなく、SIG Network も重要視していませんでした。
それから少し時間が空いて、2022/4/29 に k/k#109718 で似たような問題が報告されました。最初の報告と同じく、また GKE の利用者からの報告でした。4/29 の Issue には詳細な情報があり、SIG Network で当時 RedHat だった aojea さん (現在は Google) も最初の報告である k/k#109414 との関連を疑い始めます。
そして、2022/5/12 についに再現手順が comment - k/k#109414 で共有されます。2022/5/19 に aojea さんが原因を見つけて修正の PR である k/k#110115 を投げました。原因は Pod のライフサイクルに関わる変更でした。ここを触ると大体何かが壊れます。
今回の問題は Pod のライフサイクルに関わるため、SIG Network は SIG Node と協力して対応を進める必要があります。SIG の壁を越える必要があるので、必然的に修正のハードルが上がります。SIG Node の当時 RedHat だった smarterclayton さん (現在は Google) が aojea さんの PR のレビューを開始しました。
2022/5/24 に GKE のネットワークチームの bowei さんもコメントで反応しました。Kubernetes の開発者が Issue の中で /cc をし始めると重大な問題であることが多いです。
2022/5/25 に SIG Network 兼 GKE の開発チームの robscott さんが comment - k/k#110115 でレビューを開始しました。そして、2022/5/27 に今度は GKE ネットワークチームの swetharepakula さんが comment - k/k#110115 でレビューを開始しました。
2022/5/27 にサポートケースを起票するページから確認できる Google Cloud の既知の問題にこの件が載りました。開始日時が 2022/5/27 になっていますが、あくまで Google Cloud が障害として認めた時刻を記載しているようです。(これまでの一連の流れから、5/27 より前に GKE の開発チームが問題を認識していたはずなので...。)

2022/5/28 に robscott さんが aojea さんの PR をベースにレビュー対応した k/k#110255 の PR を作成します。なるはやでマージして GKE にも取り込みたかったようです。余り見たことがない動きだったので、ワクワクしました。SIG Network の Chair で Google の thockin さんとリレーして無事にマージされました。これで無事に問題は解決しました。
今回のケースだと運用していた GKE クラスタを 1.22 に上げる前に問題が解決されたので、特に影響はなかったです。社内でこの問題ヤバそうと共有して、後は行く末を見守っていただけでした。ただ、仮に修正が遅れて GKE 1.22 に更新する時期が来ても、メンテナンス除外設定など (他にも GKE 1.22 の非推奨 API である extensions/v1beta1 の Ingress をわざと叩いて、コントロールプレーンの自動更新を避け続けるとか) を駆使して 1.22 への更新をギリギリまで待つといった動きは取れました。Kubernetes の upstream を観察していて良かったと思えた出来事でした。
GKE は重大なバグの修正をパッチバージョンのリリースを待たずに取り込んでくれます。CHANGELOG-1.22 を見ると分かるのですが、Kubernetes の upstream だと 1.22.11 にしかこの修正は cherry-pick されていません。ただ、GKE だと 1.22.9 に取り込まれていました。Google Cloud のサポート問い合わせをしていると、comment - k/k#109718 にあるようにこの修正はこのパッチバージョンに入ったよと教えてくれます。
この一連のバグの修正の話は KubeCon 2022 NA で映画化 (SIGs Aren’t Silos: A Case Study Into Solving Inter-Domain Problems In Kubernetes Development - Swetha Repakula & Antonio Ojea Garcia) されています。SIG Network と SIG Node が協力してどのように問題を解決したかのケーススタディの題材として挙げられています。当時リアルタイムで解決の様子を見ていた (原作を読んでいた) ので、KubeCon で発表すると聞いた時はすごく楽しみだったのを覚えています。
GKE の良さはいろいろとあると思うのですが、個人的に各 SIG に Google の人が必ずいて、重大なバグの修正を Kubernetes のパッチバージョンのリリースを待たずに、既存のパッチバージョンに取り込んでくれるところが一番だと思っています。EKS や AKS だとそこまではやってくれません。EKS が Kubernetes 1.22 に当ててたパッチの情報は aws/eks-distro で確認できますが、今回の修正が入った形跡はありません。別件ですが、k/k#105204 の修正が EKS や AKS にそれぞれ取り込まれていない報告 (comment - k/k#105204, comment - k/k#105204) があったりしました。GKE のパッチバージョンには cherry-pick されて取り込まれていたので、問題ありませんでした。
GKE のソースコードは GKE のノード上に置かれています。
❯ kubectl debug -it node/gke-ngsw-development-nap-e2-standard--261828bc-nkjr --image=cgr.dev/chainguard/wolfi-base:latest -- ash
Creating debugging pod node-debugger-gke-ngsw-development-nap-e2-standard--261828bc-nkjr-p5mvf with container debugger on node gke-ngsw-development-nap-e2-standard--261828bc-nkjr.
/ # ls /host/home/kubernetes/kubernetes-src.tar.gz
/host/home/kubernetes/kubernetes-src.tar.gz
別のターミナルを開いて、kubectl cp でソースコードをローカル環境にコピーしてきます。それを Kubernetes の対応するバージョンのソースコードに上書きします。
kubectl cp node-debugger-gke-ngsw-development-nap-e2-standard--261828bc-nkjr-v95zd:host/home/kubernetes/kubernetes-src.tar.gz ~/Downloads/kubernetes-src.tar.gz
GKE 1.27.2-gke.2100 のソースコードと upstream の 1.27.2 のソースコードを比較してみると、1.27.2-gke.2100 には k/k#115398 の修正が追加で cherry-pick されていることが分かります。ノードの CSI ボリュームの制限用の scheduler plugin が Secret / ConfigMap しか使っていない Pod でも無駄に反応していて、スケジューリングの時間が無駄に掛かっていたのを修正した PR です。このように GKE はユーザー影響の大きなバグ修正を自分たちの判断で修正のパッチバージョンを待たずに既存のパッチバージョンに取り込んでくれます。
Gardener が遭遇したやばいバグ
Gardener という SAP が開発している GKE / EKS みたいなマネージドな Kubernetes as a Service をマルチクラウド上で管理するためのツールがあります。Gardener で管理している Google Cloud 上の Kubernetes クラスタを 1.20 から 1.21 に更新した際に、ノードから GCE の永続化ディスク (PV) が外れ、ノードが Unhealthy 状態になり、ノード上で動作していた Pod が I/O エラーを吐いて死亡する絶望のバグを踏み抜きました。(k/k#109354)
Kubernetes のバージョンと CSI 関連のコンポーネントのバージョンミスマッチが原因のようです。
GCE PD CSI migration が有効になっていてかつ external-provisioner >= v2.1.1 の組み合わせで発生するバグで、最終的に external-provisioner のバージョンを v2.1.0 で固定かつ手動作業で回避することができます。1.20 から 1.21 に更新したことで完全に削除されたラベルの影響で GCE ディスクの zone の情報が UNSPECIFIED になって壊れたそうです。(external-provisioner v2.1.1 に依存していたライブラリが Kubernetes 1.21 以降でしか動かない前提だったっぽい?)
GKE だと自分たちで CSI のコンポーネントを開発しているかつ GKE 側で管理してくれるので、こういう依存関係の問題に遭遇しにくいです。マネージドはやっぱり楽ですね!仮に遭遇したとしても新しいバージョンのアーリーアダプターが人柱になってくれるはずです。
この Issue に対する Google 側の反応が最初悪く、SAP の人が今回も無視するつもりか (以前も報告して無視されたっぽい) って途中でブチギレていたのですが、流石に Google 側もやばいと思ったのか k8s/issues/109354 Analysis にあるように対応策を 5 つも考えて返していました。それを見た SAP の人も機嫌が直っていてホッとしました。
最近 AWS の存在感が増してる話
KubeCon 2022 NA の Keynote: AWS ❤️ K8s - Nathan Taber, Head of Product for Kubernetes, AWS の Keynote で AWS がどれだけ Kubernetes や周辺エコシステムに貢献しているかの話がありました。この中で、AWS は AWS 用の Cloud Provider を開発していて、Cluster API にもコントリビュートしていて、Kubernetes の upstream にも貢献しているというくだりがあります。最近 Kubernetes 本体に入れた変更の例として、Kubernetes API Server のレスポンスの gzip の圧縮レベルの最適化を上げています。動画の 68 秒目 からの話で、この修正は k/k#112299 のことです。Revisit gzip compression in k8s API の Google Docs に書かれているように、丁寧にパフォーマンス検証をやっていて凄いは凄いのですが、各ベンダーが協力して KEP を作って新しい機能を実装している中で存在感のないのが AWS でした。
AWS のコントリビューションのグラフを見ても 2022/10 から急激にコントリビュートが増えているのが分かります。

これは dims さんという方が VMware から AWS に移った影響です。最近は Kubernetes の CI 周りのインフラやライブラリの依存関係などなどを見られていて、すごく気の良い人で顔も広くいろんな SIG に入り込んで橋渡しをするのが上手な方です。registry.k8s.io の ECR へのリダイレクト対応や Kubernetes の CI の一部を EKS 環境へ移行する対応を先導していました。
Kubernetes 1.28 で注目の集まっている KEP-753: Sidecar Containers の実装にも AWS の tzneal さんが関わっています。Karpenter の SIG Autoscaling への寄贈にも dims さんは絡んでいそうな雰囲気があります。人が一人動くだけで組織のプレゼンスが大きく変わるのは面白いですよね。Kubernetes における AWS の存在感はこれからも増していくはずなので、今後も目が離せないですね。
まとめ
趣味で Kubernetes を追いかけていますが、業務で役に立つ情報を手に入れることもできます。誰かがまとめてくれた情報を見るわけではないので、効率は非常に悪いです。ただ、通常だと絶対に知り得ないような情報を知ることもできます。一人で Kubernetes の世界の出来事をカバーするのは不可能です。この記事を読んで、Kubernetes を追いかける人が一人でも増えてくれると幸いです。そして、いつか自分しか追ってないだろって情報を共有して下さい...!
Discussion