球面集中現象の可視化
はじめに
高次元の統計学の2.1節、高次元データベクトルの幾何学的表現について説明します。 Peter Hall,J. S. Marron,Amnon Neeman (2005) の論文の2節の図2も作成します。
まず読む前に高次元データについて知りたい方はこちらをチェック
高次元データベクトルの幾何学的表現(球面集中現象)
証明
(1)の証明
ここで
チェビシェフの不等式を用いて評価する。(大数の法則や中心極限定理使ってもいいです)
チェビシェフの不等式の定義:
ここで、
よって
これにより、d が無限に大きくなると、ほぼすべての x が半径
(2)の証明
ここで
となる。
Pythonコード
まず必要なライブラリをインポートする。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
次にグラフを出力する関数を定義する。標本は3つ。繰り返し回数は100回にしています。
def normal_plot(dim, lims, n=3, ite=100):
fig, axes = plt.subplots(2, 2, figsize=(10, 10))
axes = axes.flatten()
colors = ['red', 'blue', 'green']
for idx, d in enumerate(dim):
for _ in range(ite):
generator = np.random.default_rng()
data = generator.normal(size=(n,d))
pca = PCA(n_components=2)
data_transformed = pca.fit_transform(data)
#散布図
for i in range(n):
axes[idx].scatter(data_transformed[i, 0], data_transformed[i, 1],
c=colors[i], marker='o')
axes[idx].set_title(f"d={d}")
axes[idx].grid(True)
axes[idx].set_xlim(lims[idx])
axes[idx].set_ylim(lims[idx])
# Adjust layout to prevent overlap
plt.tight_layout()
plt.show()
最後に出力する。
dim = [2, 20, 200, 20000]
lims = [(-3, 3), (-5, 5), (-15, 15), (-150, 150)]
normal_plot(dim, lims)
次元によって軸の値も変えてあげる必要があることに注意
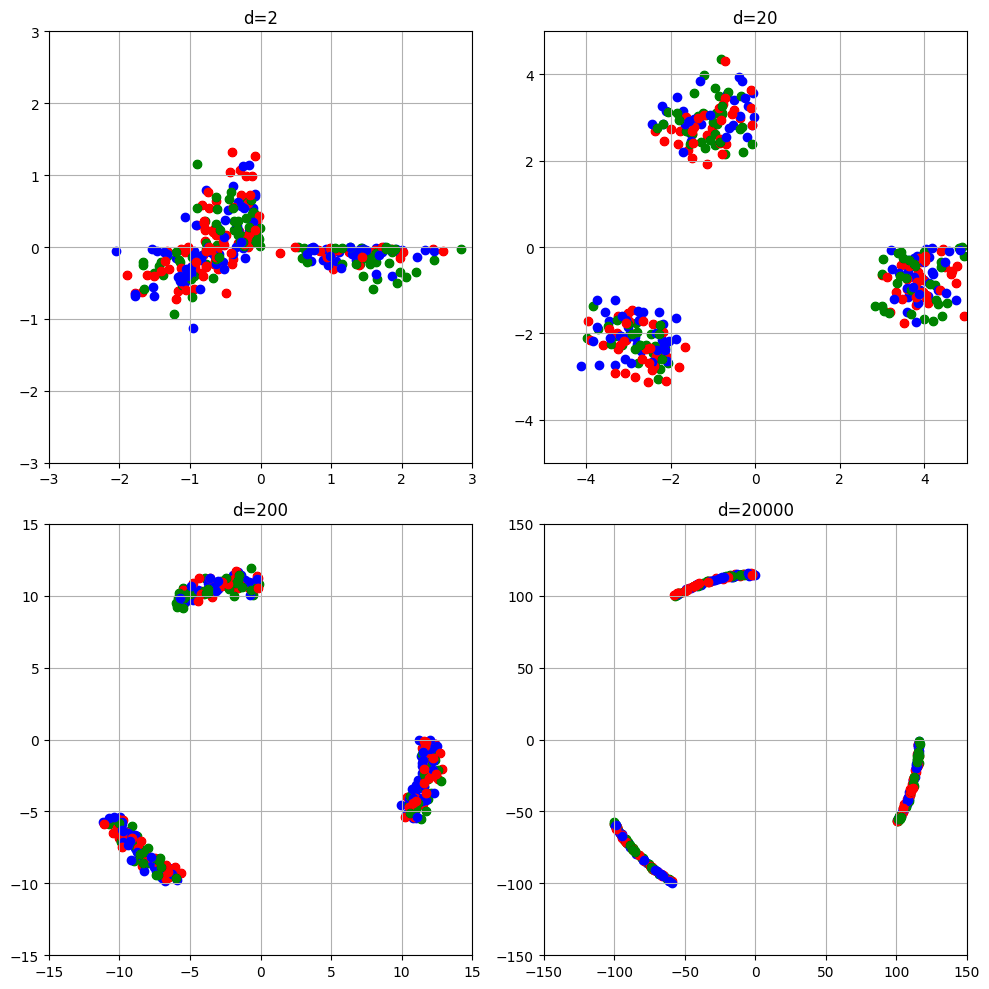
Peter Hall,J. S. Marron,Amnon Neeman (2005)の図2みたいに完全には集まらず、少し幅を持ってしまうのはなぜですかね。
参考文献
- Peter Hall,J. S. Marron,Amnon Neeman (2005) Geometric representation of high dimension, low sample size data. J.R. Statist. Soc. B 67, Part 3, pp. 427–444
https://academic.oup.com/jrsssb/article/67/3/427/7109487?login=false - 数学の景色「チェビシェフの不等式」https://mathlandscape.com/chebyshev-ineq/
- 青嶋誠、矢田和善 (2019)「高次元の統計学」
https://www.kyoritsu-pub.co.jp/book/b10003167.html
Discussion