インフラ監視に関するベストプラクティスまとめてみた
株式会社JDSCの水島です。
インフラ監視について、各社が出しているベストプラクティスをまとめて記事にしました。
私自身、まだ知識が浅いところがあるので、より気になったところはコメント頂けると嬉しいです。
インフラ監視をなぜやるか
プロダクトは、ある日突然動作が停止するときがやってきます。
その原因は、実装したコードがうまく動作してないかもしれないし、使っているクラウドサービスが落ちてるかもしれないし、ユーザの同時接続数が急増しているかもしれません。
(攻撃ではない場合、これは嬉しいけれども. ..)
このような状況が発生したときに、開発メンバーはどうすればいいでしょう?
とりあえずは、何らかの方法で発生した問題に対して障害対応を行うことでしょう。
その後、報告書を書き、発生した問題に対する改善案を考え、修正実装をリリースすると思います。
しかし、こうした対応の間、プロダクトは停止しているので、その分だけビジネス上の損失を出してしまい、同時にプロダクトの信頼性は損なわれてしまいます。おまけに、障害対応に手を取られている間、チームで進めていた新規機能開発は止まってしまいます。
このような事態を防ぐために有効な手段の一つが、インフラ監視です。
インフラ監視を行うことで、プロダクトを提供しているシステムが安定して動作し続けることを担保し、システムの可用性とパフォーマンスを計測し、サーバーダウンなどのビジネス上深刻な問題を事前に対処することが可能になります。
このほかにも、継続的にインフラ監視を行うことで、プロダクトに対するベストなリソースのプロビジョニングを実現したり、脆弱な機能や不正なアクセスを検知することでセキュリティを向上することも可能になります。
また、ここで重要なのは、ビジネス上深刻な問題を事前に検知するということです。
起こりうる問題のきっかけを検知して、適切な対応を行うことができれば、
あなたのプロダクトは(ユーザからみると)安定した価値を提供することが可能です。
自動化の重要性
では、プロダクトに対して発生する問題を事前に検知するにはどうすればいいでしょうか?
まず浮かぶのは、本番環境で運用されているwebサーバーのログを見る、直接サービス画面を見に行って不具合が起きてないかを確認するなどの対応でしょうか。
最近のwebサービスは、クラウド上で動いている事例が多いとはいえ、動いているアプリケーションの不具合を人力で監視するのは現実的ではありません。
開発メンバーが動作しているプロダクトの画面や流れてくるログを常に見ていれば不可能ではないと思いますが、そんな仕事は退屈ですし、生産性も高くありません。
また、これも大規模なプロダクトにおいては実現そのものが難しいと思います。
近年の盛んに採用されているk8sに代表されるように複数のコンテナを使用し、それぞれアプリケーションが動いていて、それぞれにリソースを持ち、それぞれにログを吐いているみたいな状況だと、上記のような対応を取ることは難しいでしょう。
このため、インフラ監視には自動化がとても重要になってきます。
自動化されたインフラ監視により、迅速で的確な対応が可能になります。
自動化することで人間に依存しなくなるため、勤務時間外の問題にも対応できます。
適切な監視が行えていれば、発生する問題も少なくなっていき、余った時間でさらなるプロダクトの改善もできるようになるでしょう。
つまり、インフラ監視を適切に行うことにより、最小限の介入とリソースで、問題の解決に費やす時間、費用、労力を削減することができます。
では、どのようにインフラ監視を自動化していけばいいのか、を以下に書いていきます。
インフラ監視のベストプラクティス
0. 導入するモニタリングツールを決めよう
まずはインフラ監視を行うためのモニタリングツールを決めましょう。
こういったモニタリングツールで、有名なところだと、MakerelやDatadogなどのSaaSサービスがあると思います。
こうしたSaaSサービスの導入にあたって、利用料が発生することが問題になることがありますが、個人的な考えとして、お金払って解決できることは、お金を払った方がよいと思っています。
プロダクトを作っている際、解決すべき課題はお金を払っても解決できないことが多いので、お金を払って解決できることはしちゃった方が早いという考えです。
(同時に、そこにはバグが存在しないことになるのも嬉しい)
また、彼らは他のプロダクトに対しても、サービスの提供を行なっているので、
自分達で機能開発するより、高速に、適切な機能を提供してくれるケースが多いです。
こういったツールを使っていれば、既に運用知見を持っているエンジニアが外部に存在するので、
自前で運用するケースに比べて、不要なオンボーディングや学習コストをかける必要がなくなります。
しかし、こういったツールの導入は会社のフェーズやプロダクトによって異なると思うので、自分達のプロダクトにとって最適なツールを導入するようにしましょう。
1. 重点的に管理する対象を整理する
次に、あなたのプロダクトにとって重要な(管理するべき)インフラ及び周辺システムについて整理しましょう。
プロダクトにとって必要な要素は多くありますが、本当に重要な要素はそこまで多くありません。
たとえば、webサービスの例だと最も重要な(管理するべき)インフラとは、本番環境でアプリケーションを動かしているWebサーバやDBサーバでしょう。
一方、開発環境で使用しているstaging環境のwebサーバや静的データを配置しているストレージなどは、プロダクトにとって必要ですがそこまで重要ではないでしょう。
(重要ではないとは言ってないです)
理想を言えば、プロダクトに関わっている全てのインフラ及び周辺システムに対して監視を行うことが望ましいですが、あなたの時間は有限ですし、プロダクトの成長はそれを待ってくれません。
なので、管理するべきインフラ及び周辺システムを整理し、それらに優先順位をつけましょう。
優先順位が高いほど、プロダクトにとってクリティカルであり、それがもたらす価値が大きいというイメージです。
こうすることで、必要な情報だけを取得しやすくなります。
2. プロダクトにとって最も重要なmetrics(指標)を定義する
次は、管理対象の何を知ることができれば、あなたのプロダクトが安定して動作するのかということを考えます。
プロダクト上で発生する全ての情報を監視する必要はありません。
逆に全てを監視することは悪手です。その分、収集されるログのデータ量は無駄に増えますし、本当に必要な情報の取得に時間がかかってしまいます。
先ほども述べた通り、開発に携わるメンバーの時間は有限です。
プロダクトにとって最も重要なmetricsを定義し、それだけを取得するようにしましょう。
metricsは大別するとwork metricsとresource metricsに分けることができます。
それぞれ以下のような意味です。
work metrics
システムの有用な出力に関するmetricsです。
測定することで、プロダクトの健全性について知ることができます。
worm metricsは、プロダクトのアベイラビリティを監視、追跡し、アプリケーションとそれを運用するインフラの有効性を理解するために非常に有効です。
work metricsはさらに以下の四つに分類することができます。
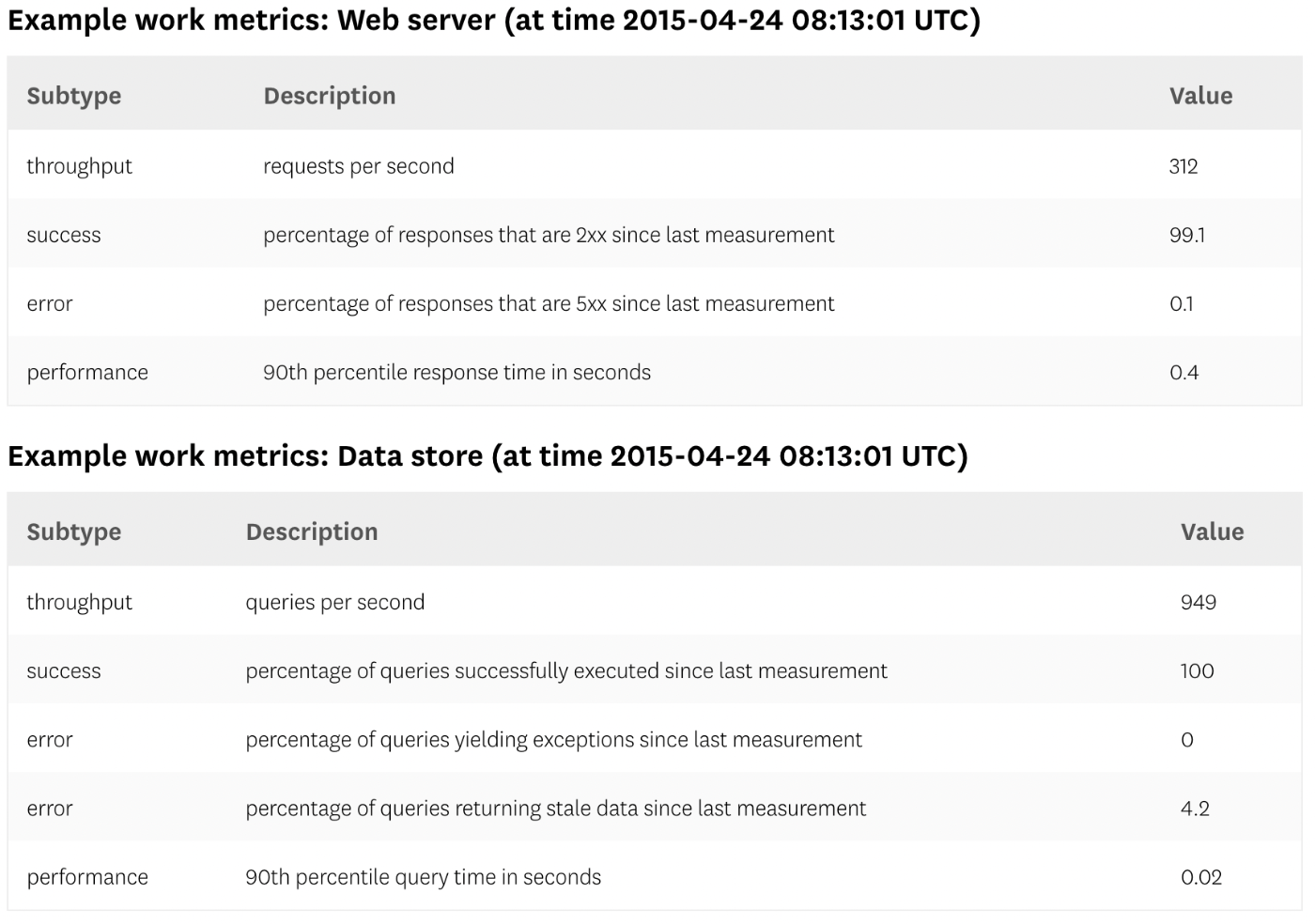
throughput
システムが単位時間あたりに実行している作業量です。スループットは通常、絶対数として記録されます。
success
正常に実行された作業の割合を表します。
error
通常、単位時間あたりのエラー率として表されるか、スループットによって正規化されて、作業単位あたりのエラーが生成されます。エラーメトリクスは、エラーの潜在的な原因がいくつかある場合、成功メトリクスとは別にキャプチャされることがよくあります。その中には、他のメトリクスよりも深刻または実用的なものもあります。
performance
コンポーネントがその作業をどれだけ効率的に行っているかを定量化します。最も一般的なパフォーマンスメトリックはレイテンシーです。これは、作業単位を完了するために必要な時間を表します。レイテンシーは、平均または「0.1秒以内に返されたリクエストの99%」などのパーセンタイルとして表すことができます。
resource metrics
インフラリソースに関するmetricsです。
Webサーバは、用意されたサーバリソースのCPU、メモリなどのリソースを消費して動作しています。
これはあるWebサーバが消費しているリソースだけに関心があるのであって、それがどれだけ有用かということは示唆していません。
utilization
対象のリソースに対する現状の使用率。
どれくらいのリソースを使っているかを示す。
saturation
対象のリソースが、要求されている処理待ちのリクエスト数。
大抵の場合queueに追加される。
errors
対象の内部で発生しているエラー。
対象が処理した結果からは知ることができないエラー。
availability
対象が安定的にリクエストに応答する時間の割合。
以下は、それぞれのリソースにおけるresource metricsの例です。

大抵の場合、work metricsの方がより重要です。
webサービスであれば、サーバーが単位時間あたりに正常発行しているページ数や、DBに対する単位時間あたりのクエリ処理数、システム全体に対する時間あたりのエラー発生件数などがwork metricsなどにあたり、これらはプロダクトのアベイラビリティや品質に直結します。
こうして取得するmetricsを絞ることで、より効率的に、迅速な監視を行うことが可能になります。
3. 通知するべきmetricsを定義する
ここまでで、モニタリングするべきmetricsは定義されました。
とりあえずこの指標だけ見ておけば、プロダクトに発生する問題は検知できると思います。
ただ、このままだとmetricsをずっと見ておくことになるので、適切なAlertを設定してあげましょう。
Alertを設定する際には、
「そのAlertが飛んできたときに、開発メンバーが何らかの対応を取れるものだけにする」
というルールが重要です。
悪いAlertの例
例えば、AWSやGCPなどのサービスが落ちてしまったとき、私たちのプロダクトも機能しなくなりますが、私たちにできることは何もありません。
せいぜい早く復旧してくれることを祈るくらいです。
もう一つ悪いAlertの例を挙げると、単位時間あたりに発生している404エラーの数があるでしょう。
404はNot Foundエラーなので、アプリケーションの状態によらず、プロダクトに訪れたユーザの行動に依存しているからです。
その404エラーをユーザが意図的に発生させていた場合、こちらですることは特にありません。
また、404エラーの原因として、特定のリンクが間違っているなどが考えられるかもしれませんが、このような場合ユーザからの報告やGoogle Analyticsなど、他のチャネルで気づくことが可能です。
Alertは、それが飛んできたとき、復旧のための具体的な行動が取れるAlertだけに絞りましょう。
望ましいAlertの例
たとえば、webサービスの場合、単位時間あたりのエラー発生割合は有効なwork metricsだと思われます。もし仮に単位時間あたりのエラー発生割合が10%を超えているようであれば、何らかの機能が十分に機能してないと思われます。
この場合、開発メンバーは対象アプリケーションのログを見に行って、発生している問題を特定し、その問題に対する修正コードをadhocにリリースすることが可能です。
もう一つ例をあげると、単位時間あたりに発生している502エラーの数が考えられます。
502はBad Gatewayエラーなので、プロダクトに関連している何らかのリソースで問題が発生していると思われます。おまけに問題の解決に対してユーザが出来ることは何もありません。
502の原因として、サーバーのリソース不足が考えられるならスケールアップ・アウト対応を行う必要がありますし、DNS等の設定が間違っているなら正しい設定に修正する必要があります。
ここで設定したルールはとても重要です。
もし仮に全てのmetricsについてAlertを飛ばしてしまえば、開発メンバーはどのAlertを対応するべきかわからなくなってしまいます。
また、そのような状態になっていれば、Alertが飛んできても誰も気にしなくなるでしょう。
これだと、Alertを飛ばしている意味がありません。
4. Alertを通知するメンバーと場所を決める
次は、Alertの通知先を決めましょう。
通知先は、あなた一人だけが見られる場所ではなく、開発に関係あるメンバーが、負荷なく見られる場所がいいでしょう。社内でSlackなどを利用している場合は、そこに専用の部屋を作って通知するのがよいと思います。
また全てのAlertを一つのチャンネルにまとめるのではなく、管理対象ごとに分離した方が良いケースが多いです。
webアプリケーションの場合だと、frontend, backend, databaseは必ず存在していると思いますが、通知チャンネルを作る時は、これら全てのログを一つにまとめるのではなく、こういった管理対象ごとに分けた方が視認性が上がります。
Slackの場合だと、以下のような切り分けをおこなってやればよいでしょう。
- サービス名_frontend_production
- サービス名_frontend_staging
- サービス名_backend_production
- サービス名_backend_staging
通知先を適切に切り分けて設定しておくことで、開発メンバーはより少ない労力で、迅速に発生している問題について知ることができるようになります。
5. 定期的にmetricsをレビューする
ここまでの対応で、現状において適切なモニタリングができるようになっていると思います。
しかし、プロダクトは時間とともに成長し、それに伴って必要なmetricsやAlertも変化していきます。これは時間とともにAlertやmetricsの鮮度が落ちてくることを意味します。
必要ないAlertは誰も見ないし、そうした意識が根付くことで、他の重要なAlertまで見られなくなります。
これを防ぐために、設定したAlertやmetricsに対して、チームでレビューを行いましょう。
チームの開発サイクルによっても変わってきますが、最低でも一月に一回はこうしたレビューを行った方が望ましいです。
こうした対応を行うことで、metricsやAlertの鮮度を保つことができると同時に、他のメンバーから監視に対する意見やアドバイスを受けることができます。
終わりに
ここまでの対応を適切に行うことができれば、プロダクト上で発生する問題をかなり少なくすることが可能だと思います。
しかし、こうした監視をいきなり完璧に行うことは難しいです。
そこでまずは、プロダクトにとって最も優先順位が高い対象に対して、一つずつmetricsやAlertを追加していくことをお勧めします。
それが上手くいけば一つずつ管理対象を増やしていけばよいです。
こうした対応を継続的に行うことで、モニタリングの習慣がないチームでも、少しずつ意識の改善を行うことができると思います。
(基本的に、プロダクトが不安定な状態は誰も望んでないという前提ですが...)
適切なインフラ監視を行うことで、より安定性の高いプロダクトを作って行くことが可能になります。記事をよんでくれた皆さんが、よりよいプロダクトを作ることの一助になれば嬉しいです。
参考文献
Discussion