ModernBERTを理解する
2024年12月20日にModernBERTが発表されました。
ModernBERTは、これまでのBERTやRoBERTaなどのTransformerのエンコーダ型モデルを改善したモデルです。
ModernBERTは、Answer.AIとLightOnによりリリースされました。
この記事では、ModernBERTの中身について、論文やブログ記事を見ながら理解していきます。
概要
- シーケンス長が最大8192トークンへ
- PositionalEncodingを回転位置埋め込みであるRoPE(Rotary Positional Encoding)に置き換える
- Unpaddingにより、長さの異なるトークン列を含むバッチの処理時間を短縮
- Attention層にLocal AttentionとGlobal Attentionの仕組みを導入し、学習時間を短縮
- 処理の高速化のため、Flash Attentionを使用
- 学習データの多様性のため、Webドキュメント、コード、科学論文などの英語ソースで2兆個のトークンを学習
- 次文予測(Next-Sentence Prediction)を廃止
- MLMによる学習でのトークンのマスク比率を15%から30%へ
ModernBERTの特徴
PositionalEncodingをRoPEに置き換え
PositionalEncodingをRoPE(Rotary Positional Encoding)に置き換えることで、モデルは単語同士の関係をより正確に理解できるようになり、より長いシーケンス長に拡張できるようになります。
Transformerでは、入力トークンの順序を考慮せずに学習を行うため、Positional Encodingによりトークンごとに一意の位置ベクトルを割り当て、単語埋め込みと合算する工夫を行っています。
一方で、Rotary Positional Encodingは、「RoFormer: Enhanced Transformer with Rotary Position Embedding」という論文で2021年に提案されており、トークンごとに位置ベクトルを追加するのではなく、単語埋め込みに回転を適用するアプローチをとります。
論文では、以下のような記載がありました。
(論文引用) Positional Embeddings We use rotary positional
embeddings (RoPE) (Su et al., 2024) instead
of absolute positional embeddings. This choice is
motivated by the proven performance of RoPE in
short- and long-context language models (Black
et al., 2022; Dubey et al., 2024; Gemma et al.,
2024), efficient implementations in most frameworks,
and ease of context extension.
GoogleのGemma 2のアーキテクチャでも、位置埋め込みにRoPEを用いています。
Gemma 2 は、ロータリー位置埋め込み(RoPE)や近似 GeGLU 非線形性の実装など、オリジナルの Gemma モデルと同じアーキテクチャ基盤を共有しています。
Alternating Attention
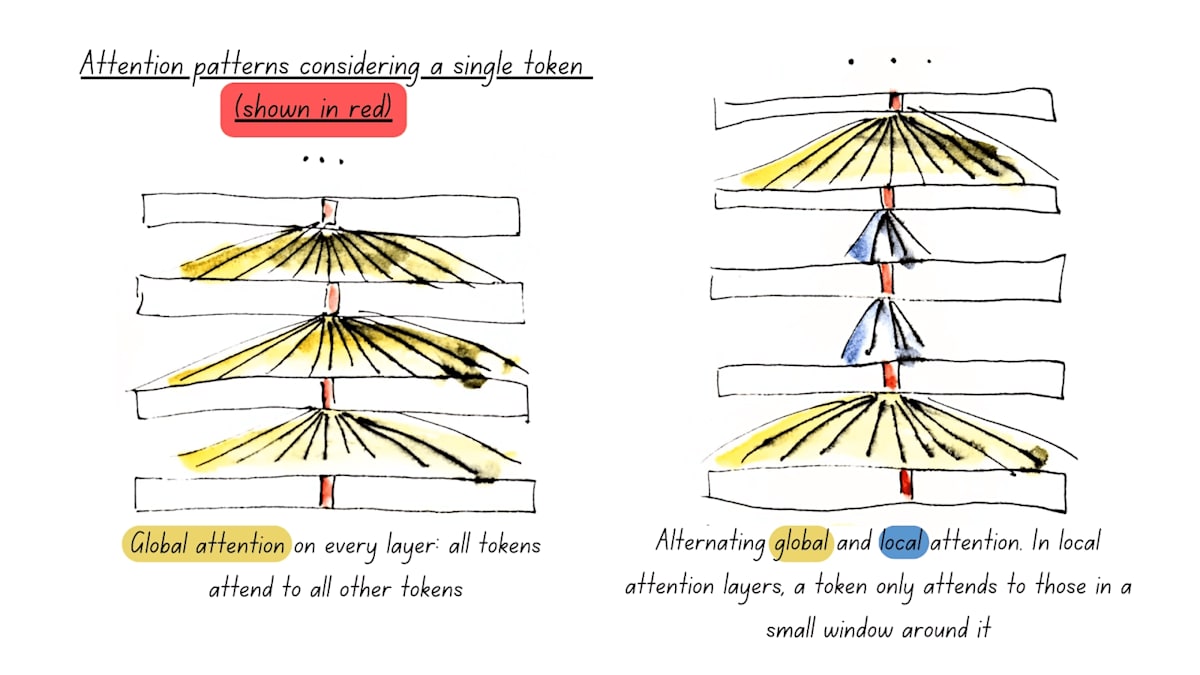
テキストのすべての単語を一度に考慮するのではなく、あるときは単語の小さな範囲(ローカル アテンション)に注目します。
また、あるときは全ての単語(グローバル アテンション)を考慮します。
この組み合わせによって、モデルがテキストの直接的な文脈と全体的な意味の両方を効率的に理解できるようになります。
こちらも、GoogleのGemma 2でも、local attentionおよびglobal attentionが用いられています。
Unpadding(Sequence Packing)
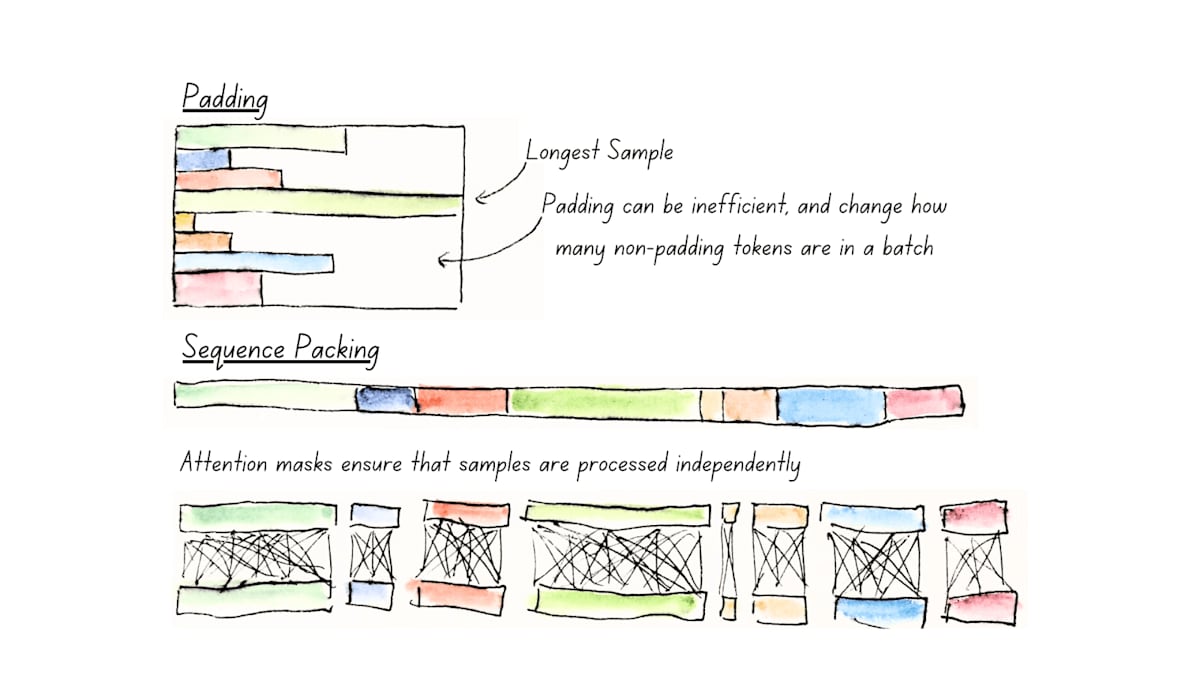
パディングとシーケンス パッキングの比較。シーケンス パッキング (「アンパディング」) では、パディング トークンの計算を無駄にすることがなくなり、バッチあたりの非パディング トークン カウントがより安定します。サンプルは、慎重なマスキングによって個別に処理されます。
同じバッチ内で複数のトークン列を処理するために、エンコーダー型モデルでは、同じ長さのトークン列とする必要があります。
その際に、通常は、paddingを追加することで、同じ長さのトークン列としていました。
(例えば、あるトークン列が512トークン列に満たない300トークンであった場合に、残りの212トークンをpaddingで埋める)
このpaddingが多く使われる場合、非常に非効率です。
そこで、unpaddingにより、paddingを全て削除し、バッチサイズが1のミニバッチに連携つして、不要な計算を回避する方法をとっています。
8192トークン列での学習の際にpaddingが増えすぎると、学習コストがかかりそうだと思いましたが、unpaddingによる対策がなされていそうです。
以下の論文では、学習や推論の際に、Unpaddingを利用しているようです。
(論文引用) MosaicBERT(Portes et al., 2023) and GTE (Zhang et al., 2024) in employing unpadding (Zeng et al.,2022)
Hardware-Aware Model Design
学習の工夫
- 学習データは多様性のため、WikipediaやWikibooksだけでなく、Webドキュメント、コード、科学論文などの英語ソースで2兆個のトークンを学習
(論文引用) Both ModernBERT models are trained on 2 trillion tokens of primarily English data from a variety of data sources, including web documents, code, and scientific literature, following common modern data mixtures.
- 次文予測(Next-Sentence Prediction)を廃止(RoBERTaでも、性能向上が見られなかったため、廃止されている)
(論文引用) We remove the Next-Sentence Prediction objective which introduces noticeable overhead for no performance improvement
- トークンのマスク比率は30%
BERTでは、ラベルなしデータを事前学習するため、トークンをマスクすることによる学習(Masked Language Model)を行います。デフォルトは15%となっていますが、ModernBERTでは、より高いマスク比率である30%を採用しています。
以下の論文が引用されていました。
まとめ
この記事では、ModernBERTを紹介しました。
シーケンス長が8192トークンまで拡大されているため、RAGでの活用や長い文章に対して適用しやすくなりそうです。
個人的には、ModernBERTを使って、シーケンスラベリングタスクである固有表現抽出を試したいと思っています。
Discussion