Amazon SageMaker HyperPod上のRay Jobs:スケーラブルで回復力のある分散AI
Amazon SageMaker HyperPod上のRay Jobs:スケーラブルで回復力のある分散AI
基盤モデル(FM)のトレーニングと推論により、業界全体で計算ニーズが大幅に増加しています。これらのモデルは効果的にトレーニングと運用を行うために、大量の高速コンピューティングを必要とし、従来のコンピューティングインフラストラクチャの限界に挑戦しています。ワークロードを複数のGPUアクセラレーテッドサーバーに分散するための効率的なシステムと、開発者の生産性とパフォーマンスの最適化が必要です。
Rayは、分散Pythonジョブの作成、デプロイ、最適化を簡単にするオープンソースフレームワークです。Rayの中核には、開発者がアプリケーションを単一マシンから分散クラスターにシームレスにスケールできるようにする統一されたプログラミングモデルがあります。タスク、アクター、データのための高レベルAPIセットを提供し、分散コンピューティングの複雑さを抽象化することで、開発者がアプリケーションのコアロジックに集中できるようにします。Rayは、シンプルな機械学習(ML)実験とスケーラブルで回復力のある本番アプリケーションの両方に同じコーディングパターンを促進します。Rayの主な機能には、効率的なタスクスケジューリング、フォールトトレランス、自動リソース管理が含まれ、MLモデルからリアルタイムデータ処理パイプラインまで、幅広い分散アプリケーションを構築するための強力なツールとなっています。ライブラリとツールの成長するエコシステムにより、Rayは複雑でデータ集約型の問題に取り組むために分散コンピューティングのパワーを活用しようとする組織にとって人気のある選択肢となっています。
Amazon SageMaker HyperPodは、大規模なFMの開発とデプロイのために特別に構築されたインフラストラクチャです。SageMaker HyperPodは、独自のソフトウェアスタックを作成して使用する柔軟性を提供するだけでなく、インスタンスの同一スパイン配置による最適なパフォーマンス、および組み込みの回復力も提供します。SageMaker HyperPodの回復力とRayの効率性を組み合わせることで、生成AIワークロードをスケールアップするための強力なフレームワークを提供します。
この記事では、SageMaker HyperPod上でRayジョブを実行するための手順を説明します。
Rayの概要
このセクションでは、AI/MLワークロード向けのRayツールとフレームワークの概要を説明します。主にMLトレーニングのユースケースに焦点を当てます。
Rayは、高度にスケーラブルで並列なPythonアプリケーションを実行するように設計されたオープンソースの分散コンピューティングフレームワークです。RayはAIワークロード全体でコンピューティングニーズを管理、実行、最適化します。単一の柔軟なフレームワークを通じてインフラストラクチャを統合し、データ処理からモデルトレーニング、モデルサービング、さらにその先までのAIワークロードを可能にします。
分散ジョブについて、RayはMLワークフローの並列化とスケーリングのための直感的なツールを提供します。リソース割り当て、タスクスケジューリング、ノード間通信の複雑さを気にすることなく、開発者がトレーニングロジックに集中できるようにします。
高レベルでは、Rayは3つの層で構成されています:
- Ray Core:並列および分散コンピューティングのプリミティブを提供するRayの基盤
-
Ray AIライブラリ:
- Ray Train – PyTorch、TensorFlow、Hugging Faceなどの人気のあるMLフレームワークのビルトインサポートを提供することで、分散トレーニングを簡素化するライブラリ
- Ray Tune – スケーラブルなハイパーパラメータチューニングのためのライブラリ
- Ray Serve – 分散モデルのデプロイメントとサービングのためのライブラリ
- Rayクラスター:ワーカーノードがRayタスクとアクターとしてユーザーコードを実行する、一般的にクラウドにある分散コンピューティングプラットフォーム
この記事では、SageMaker HyperPod上でRayクラスターを実行することに深く掘り下げます。Rayクラスターは、単一のヘッドノードと複数の接続されたワーカーノードで構成されています。ヘッドノードは、タスクスケジューリング、リソース割り当て、ノード間の通信を調整します。Rayワーカーノードは、モデルトレーニングやデータ前処理などの分散ワークロードをRayタスクとアクターを使用して実行します。
RayクラスターとKubernetesクラスターは相性が良いです。KubeRayオペレーターを使用してKubernetes上でRayクラスターを実行することで、RayユーザーとKubernetes管理者の両方が開発から本番までのスムーズな道筋の恩恵を受けます。このユースケースでは、Amazon Elastic Kubernetes Service(Amazon EKS)を通じて調整されるSageMaker HyperPodクラスターを使用します。
KubeRayオペレーターを使用すると、Kubernetes上でRayクラスターを実行できます。KubeRayは以下のカスタムリソース定義(CRD)を作成します:
- RayCluster – Kubernetes上のRayインスタンスを管理するための主要なリソース。Rayクラスター内のノードは、KubernetesクラスターのPodとして現れます。
- RayJob – 一時的なRayクラスター上で実行されるように設計された単一の実行可能なジョブ。Rayクラスターによって実行されるタスクまたはタスクのバッチを送信するための高レベルの抽象化として機能します。RayJobはまた、ジョブが送信されたときにクラスターを自動的にスピンアップし、ジョブが完了したときにシャットダウンすることで、Rayクラスターのライフサイクルを管理し、一時的なものにします。
- RayService – Rayクラスターとその上で実行されるServeアプリケーションを単一のKubernetesマニフェストにまとめます。通常はサービスエンドポイントを通じて外部通信を必要とするRayアプリケーションのデプロイメントを可能にします。
この記事の残りの部分では、RayJobやRayServiceには焦点を当てません。分散MLトレーニングジョブを実行するための永続的なRayクラスターの作成に焦点を当てます。
RayクラスターがSageMaker HyperPodクラスターとペアになると、Rayクラスターは強化された回復力と自動再開機能のロックを解除します。これについては後でより詳しく説明します。この組み合わせは、動的なワークロードの処理、高可用性の維持、長時間実行ジョブに不可欠なノード障害からのシームレスな回復のためのソリューションを提供します。
SageMaker HyperPodの概要
このセクションでは、SageMaker HyperPodとそのインフラストラクチャの安定性を提供する組み込みの回復力機能を紹介します。
トレーニング、推論、ファインチューニングなどの生成AIワークロードには、数千のGPUアクセラレーテッドインスタンスの大規模クラスターの構築、維持、最適化が含まれます。分散トレーニングの目的は、クラスター利用率を最大化し、トレーニング時間を最小化するために、これらのインスタンス全体でワークロードを効率的に並列化することです。大規模な推論では、レイテンシーを最小化し、スループットを最大化し、最高のユーザーエクスペリエンスのためにそれらのインスタンス全体でシームレスにスケールすることが重要です。SageMaker HyperPodは、これらのニーズに対応するために特別に構築されたインフラストラクチャです。大規模なGPUアクセラレーテッドクラスターの構築、維持、最適化に関連する差別化されていない重労働を排除します。また、トレーニングまたは推論環境を完全にカスタマイズし、独自のソフトウェアスタックを構成する柔軟性も提供します。SageMaker HyperPodでは、オーケストレーションにSlurm または Amazon EKSを使用できます。
その巨大なサイズと大量のデータでトレーニングする必要性により、FMは多くの場合、GPUやAWS Trainiumなどの数千のAIアクセラレーターで構成される大規模なコンピュートクラスター上でトレーニングおよびデプロイされます。これらの数千のアクセラレーターのうちの1つに障害が発生すると、クラスター内の故障したノードを特定、分離、デバッグ、修復、回復するために手動の介入が必要となり、トレーニングプロセス全体が中断される可能性があります。このワークフローは障害ごとに数時間かかる可能性があり、クラスターの規模が大きくなるにつれて、数日ごとまたは数時間ごとに障害が発生することが一般的です。SageMaker HyperPodは、クラスターインスタンスの健全性チェックを継続的に実行し、不良インスタンスを修正し、最後の有効なチェックポイントを再ロードし、ユーザーの介入なしにトレーニングを再開するエージェントを適用することで、インフラストラクチャの障害に対する回復力を提供します。その結果、モデルのトレーニングを最大40%速く行うことができます。また、デバッグのためにクラスター内のインスタンスにSSHで接続し、マルチノードトレーニング中のハードウェアレベルの最適化に関する洞察を収集することもできます。SlurpやAmazon EKSなどのオーケストレーターは、リソースの効率的な割り当てと管理を促進し、最適なジョブスケジューリングを提供し、リソース利用率を監視し、フォールトトレランスを自動化します。
ソリューション概要
このセクションでは、SageMaker HyperPod上でマルチノード分散トレーニング用のRayジョブを実行する方法の概要を説明します。SageMaker HyperPodクラスターの作成、KubeRayオペレーターのインストール、Rayトレーニングジョブのデプロイメントのプロセスについて説明します。
この記事ではクラスターを手動で作成するためのステップバイステップガイドを提供していますが、aws-do-rayプロジェクトをチェックしてみてください。このプロジェクトは、Amazon EKSまたはSageMaker HyperPod上でRayを使用した分散Pythonアプリケーションのデプロイメントとスケーリングを簡素化することを目的としています。Rayクラスター、ジョブ、サービスのデプロイと管理に必要なツールをコンテナ化するためにDockerを使用します。aws-do-rayプロジェクトに加えて、Amazon SageMaker Hyperpod EKSワークショップを強調したいと思います。このワークショップは、SageMaker Hyperpodクラスター上で様々なワークロードを実行するためのエンドツーエンドの体験を提供します。GitHubリポジトリawsome-distributed-trainingからのトレーニングと推論ワークロードの複数の例があります。
先ほど紹介したように、KubeRayはKubernetes上でのRayアプリケーションのデプロイメントと管理を簡素化します。以下の図はソリューションアーキテクチャを示しています。
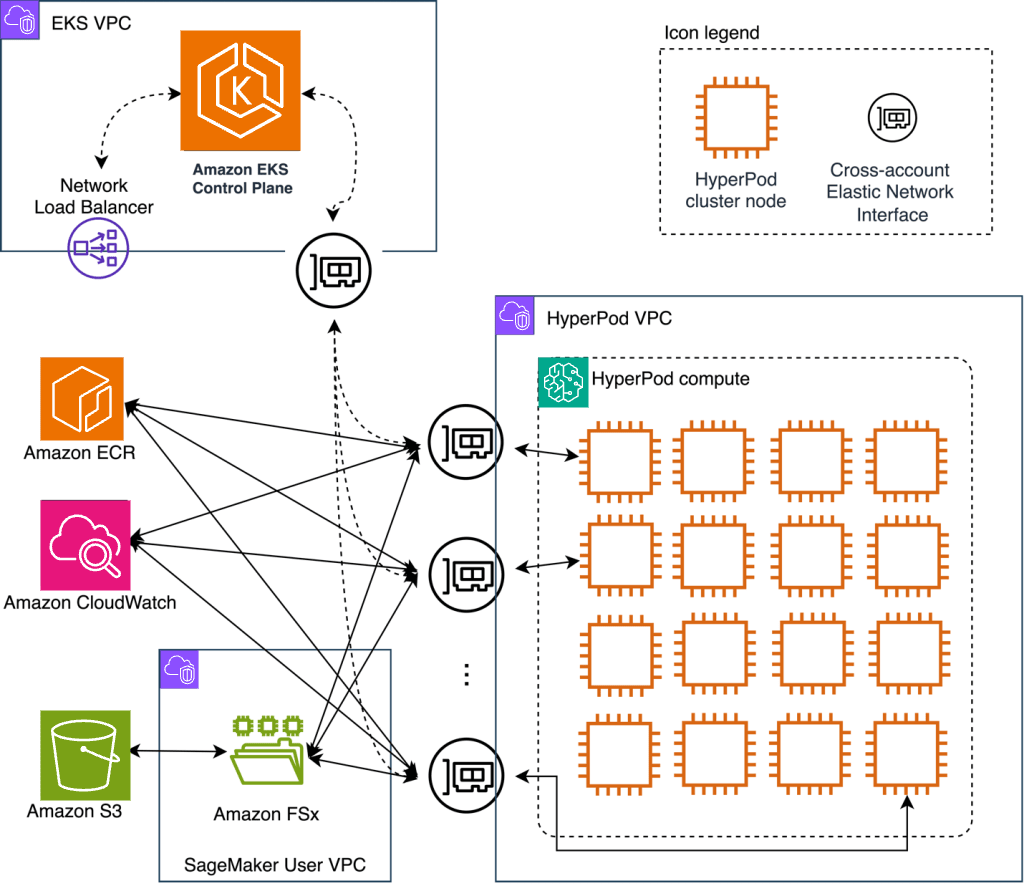
SageMaker HyperPodクラスターの作成
前提条件
Ray on SageMaker HyperPodをデプロイする前に、HyperPodクラスターが必要です:
- これはCloudFormationを使用してEKS SageMaker HyperPodクラスターをセットアップするためのワンクリックデプロイメントです。このスタックをデプロイしてください。ソースはAmazon EKS Support in SageMaker HyperPod Workshopからのものです。これで、「FSx for Lustreの共有ファイルシステムの作成」セクションに直接進むことができます。
既存のEKSクラスターにHyperPodをデプロイすることを希望する場合は、ここの手順に従ってください。これには以下が含まれます:
- EKSクラスター – 前提条件のセットを満たす既存のEKSクラスターにSageMaker HyperPodコンピュートを関連付けることができます。あるいは推奨される方法として、単一のAWS CloudFormation テンプレートで既製のEKSクラスターをデプロイできます。EKSクラスターのセットアップ手順については、GitHubリポジトリを参照してください。
- カスタムリソース – マルチノード分散トレーニングを実行するには、デバイスプラグイン、Container Storage Interface(CSI)ドライバー、トレーニングオペレーターなど、様々なリソースをEKSクラスターに事前にデプロイする必要があります。また、ヘルスモニタリングエージェントとディープヘルスチェックのための追加リソースもデプロイする必要があります。HyperPodHelmChartsは、Kubernetesで最も一般的に使用されるパッケージマネージャーの1つであるHelmを使用してプロセスを簡素化します。インストール手順については、Install packages on the Amazon EKS cluster using Helmを参照してください。
以下は、前提条件をデプロイした後の既存のEKSクラスター上にHyperPodクラスターを作成するためのワークフロー例です。これはクイックデプロイオプションには必要ありません。参考用です。
cat > cluster-config.json << EOL
{
"ClusterName": "ml-cluster",
"Orchestrator": {
"Eks": {
"ClusterArn": "${EKS_CLUSTER_ARN}"
}
},
"InstanceGroups": [
{
"InstanceGroupName": "worker-group-1",
"InstanceType": "ml.p5.48xlarge",
"InstanceCount": 4,
"LifeCycleConfig": {
"SourceS3Uri": "s3://amzn-s3-demo-bucket",
"OnCreate": "on_create.sh"
},
"ExecutionRole": "${EXECUTION_ROLE}",
"ThreadsPerCore": 1,
"OnStartDeepHealthChecks": [
"InstanceStress",
"InstanceConnectivity"
]
},
{
"InstanceGroupName": "head-group",
"InstanceType": "ml.m5.2xlarge",
"InstanceCount": 1,
"LifeCycleConfig": {
"SourceS3Uri": "s3://amzn-s3-demo-bucket",
"OnCreate": "on_create.sh"
},
"ExecutionRole": "${EXECUTION_ROLE}",
"ThreadsPerCore": 1,
}
],
"VpcConfig": {
"SecurityGroupIds": [
"${SECURITY_GROUP_ID}"
],
"Subnets": [
"${SUBNET_ID}"
]
},
"NodeRecovery": "Automatic"
}
EOL
提供された設定ファイルには2つの重要なハイライトが含まれています:
- "OnStartDeepHealthChecks": ["InstanceStress", "InstanceConnectivity"] – 新しいGPUまたはTrainiumインスタンスが追加されるたびにディープヘルスチェックを実行するようSageMaker HyperPodに指示します
- "NodeRecovery": "Automatic" – SageMaker HyperPodの自動ノード回復を有効にします
以下のAWS Command Line Interface(AWS CLI)コマンドを使用してSageMaker HyperPodコンピュートを作成できます(AWS CLIバージョン2.17.47以降が必要です):
aws sagemaker create-cluster \
--cli-input-json file://cluster-config.json
{
"ClusterArn": "arn:aws:sagemaker:us-east-2:xxxxxxxxxx:cluster/wccy5z4n4m49"
}
クラスターのステータスを確認するには、以下のコマンドを使用できます:
aws sagemaker list-clusters --output table
このコマンドは、クラスター名、ステータス、作成時間を含むクラスターの詳細を表示します:
------------------------------------------------------------------------------------------------------------------------------------------------------
| ListClusters |
+----------------------------------------------------------------------------------------------------------------------------------------------------+
|| ClusterSummaries ||
|+----------------------------------------------------------------+---------------------------+----------------+------------------------------------+|
|| ClusterArn | ClusterName | ClusterStatus | CreationTime ||
|+----------------------------------------------------------------+---------------------------+----------------+------------------------------------+|
|| arn:aws:sagemaker:us-west-2:xxxxxxxxxxxx:cluster/zsmyi57puczf | ml-cluster | InService | 2025-03-03T16:45:05.320000+00:00 ||
|+----------------------------------------------------------------+---------------------------+----------------+------------------------------------+|
あるいは、SageMakerコンソールでクラスターのステータスを確認することもできます。しばらくすると、ノードのステータスがRunningに移行するのを確認できます。
FSx for Lustre共有ファイルシステムの作成
Rayクラスターをデプロイするには、SageMaker HyperPodクラスターが稼働していることに加えて、共有ストレージボリューム(例:Amazon FSx for Lustreファイルシステム)が必要です。これはSageMaker HyperPodノードがアクセスできる共有ファイルシステムです。このファイルシステムは、SageMaker HyperPodクラスターを起動する前に静的にプロビジョニングするか、その後に動的にプロビジョニングすることができます。
共有ストレージの場所(クラウドストレージやNFSなど)の指定は、シングルノードクラスターではオプションですが、マルチノードクラスターでは必須です。ローカルパスを使用すると、マルチノードクラスターのチェックポイント時にエラーが発生します。
Amazon FSx for Lustre CSIドライバーは、AWS APIコールを認証するためにサービスアカウント用のIAMロール(IRSA)を使用します。IRSAを使用するには、EKSクラスターにプロビジョニングされているOIDC発行者URLに関連付けられたIAM OpenID Connect(OIDC)プロバイダーが必要です。
以下のコマンドを使用して、クラスター用のIAM OIDCアイデンティティプロバイダーを作成します:
eksctl utils associate-iam-oidc-provider --cluster $EKS_CLUSTER_NAME --approve
FSx for Lustre CSIドライバーをデプロイします:
helm repo add aws-fsx-csi-driver https://kubernetes-sigs.github.io/aws-fsx-csi-driver
helm repo update
helm upgrade --install aws-fsx-csi-driver aws-fsx-csi-driver/aws-fsx-csi-driver\
--namespace kube-system
このHelmチャートには、kube-system名前空間にデプロイされるfsx-csi-controller-saという名前のサービスアカウントが含まれています。
eksctl CLIを使用して、AmazonFSxFullAccess AWS管理ポリシーを添付して、ドライバーが使用するサービスアカウントにバインドされたIAMロールを作成します:
eksctl create iamserviceaccount \
--name fsx-csi-controller-sa \
--override-existing-serviceaccounts \
--namespace kube-system \
--cluster $EKS_CLUSTER_NAME \
--attach-policy-arn arn:aws:iam::aws:policy/AmazonFSxFullAccess \
--approve \
--role-name AmazonEKSFSxLustreCSIDriverFullAccess \
--region $AWS_REGION
--override-existing-serviceaccountsフラグは、fsx-csi-controller-saサービスアカウントがEKSクラスターに既に存在することをeksctlに知らせ、新しいものを作成せずに、代わりに現在のサービスアカウントのメタデータを更新します。
作成されたAmazonEKSFSxLustreCSIDriverFullAccess IAMロールのAmazon Resource Name(ARN)でドライバーのサービスアカウントに注釈を付けます:
SA_ROLE_ARN=$(aws iam get-role --role-name AmazonEKSFSxLustreCSIDriverFullAccess --query 'Role.Arn' --output text)
kubectl annotate serviceaccount -n kube-system fsx-csi-controller-sa \
eks.amazonaws.com/role-arn=${SA_ROLE_ARN} --overwrite=true
この注釈は、FSx for Lustreサービスとの対話に使用するIAMロールをドライバーに知らせます。
サービスアカウントが適切に注釈付けされていることを確認します:
kubectl get serviceaccount -n kube-system fsx-csi-controller-sa -o yaml
変更を有効にするためにfsx-csi-controllerデプロイメントを再起動します:
kubectl rollout restart deployment fsx-csi-controller -n kube-system
FSx for Lustre CSIドライバーは、ファイルシステムをプロビジョニングするための2つのオプションを提供します:
- 動的プロビジョニング – このオプションはKubernetesのPersistent Volume Claims(PVC)を使用します。希望するストレージ仕様でPVCを定義します。CSIドライバーはPVCリクエストに基づいてFSx for Lustreファイルシステムを自動的にプロビジョニングします。これにより、簡単なスケーリングが可能になり、手動でファイルシステムを作成する必要がなくなります。
- 静的プロビジョニング – この方法では、CSIドライバーを使用する前にFSx for Lustreファイルシステムを手動で作成します。サブネットIDやセキュリティグループなど、ファイルシステムの詳細を設定する必要があります。その後、ドライバーを使用して、このあらかじめ作成されたファイルシステムをコンテナ内のボリュームとしてマウントできます。
この例では、動的プロビジョニングを使用します。fsx.csi.aws.comプロビジョナーを使用するストレージクラスを作成することから始めます:
cat <<EOF > storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fsx-sc
provisioner: fsx.csi.aws.com
parameters:
subnetId: ${SUBNET_ID}
securityGroupIds: ${SECURITYGROUP_ID}
deploymentType: PERSISTENT_2
automaticBackupRetentionDays: "0"
copyTagsToBackups: "true"
perUnitStorageThroughput: "250"
dataCompressionType: "LZ4"
fileSystemTypeVersion: "2.12"
mountOptions:
- flock
EOF
kubectl apply -f storageclass.yaml
-
SUBNET_ID:FSx for LustreファイルシステムのサブネットID。HyperPodの作成に使用したのと同じプライベートサブネットを使用する必要があります。 -
SECURITYGROUP_ID:ファイルシステムに添付されるセキュリティグループID。HyperPodとEKSで使用されているのと同じセキュリティグループIDを使用する必要があります。
次に、fsx-claimストレージクレームを使用するPVCを作成します:
cat <<EOF > pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-claim
spec:
accessModes:
- ReadWriteMany
storageClassName: fsx-sc
resources:
requests:
storage: 1200Gi
EOF
kubectl apply -f pvc.yaml
このPVCは、ストレージクラスで指定された仕様に基づいてFSx for Lustreファイルシステムの動的プロビジョニングを開始します。
Rayクラスターの作成
SageMaker HyperPodクラスターとFSx for Lustreファイルシステムの両方が作成されたので、Rayクラスターをセットアップできます:
- 依存関係をセットアップします。Kubernetesクラスターに新しい名前空間を作成し、Helmチャートを使用してKubeRayオペレーターをインストールします。
KubeRayオペレーターバージョン1.2.0以降を推奨します。このバージョンは、障害(例:EKSまたはSageMaker HyperPodノードのハードウェアの問題)が発生した場合の自動Ray Pod退避と置換をサポートしています。
# KubeRay名前空間を作成
kubectl create namespace kuberay
# Helmチャートリポジトリを使用してKubeRayオペレーターをデプロイ
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
helm repo update
#CRDとKuberayオペレーターv1.2.0の両方をインストール
helm install kuberay-operator kuberay/kuberay-operator --version 1.2.0 --namespace kuberay
# Kuberayオペレーターポッドがヘッドポッドにデプロイされます
kubectl get pods --namespace kuberay
- Rayクラスターマニフェスト用のRayコンテナイメージを作成します。最近の
rayproject/ray-mlイメージの非推奨化(Ray バージョン2.31.0以降)により、Rayクラスター用のカスタムコンテナイメージを作成する必要があります。したがって、必要なRay依存関係がすべて含まれている[rayproject/ray:2.42.1-py310-gpu](https://hub.docker.com/layers/rayproject/ray/2.42.1-py310-gpu/images/sha256-1c67c9417c2cd1b8c2347827c02a358b563d30fb4e83a3d7d328bd356adcec29)イメージをベースにして、トレーニング依存関係を含めて独自のカスタムイメージを構築します。このDockerfileは必要に応じて変更してください。
まず、ベースのRay GPUイメージをベースにして、必要な依存関係のみを含むDockerfileを作成します:
cat <<EOF > Dockerfile
FROM rayproject/ray:2.42.1-py310-gpu
# Install Python dependencies for PyTorch, Ray, Hugging Face, and more
RUN pip install --no-cache-dir \
torch torchvision torchaudio \
numpy \
pytorch-lightning \
transformers datasets evaluate tqdm click \
ray[train] ray[air] \
ray[train-torch] ray[train-lightning] \
torchdata \
torchmetrics \
torch_optimizer \
accelerate \
scikit-learn \
Pillow==9.5.0 \
protobuf==3.20.3
RUN pip install --upgrade datasets transformers
# Set the user
USER ray
WORKDIR /home/ray
# Verify ray installation
RUN which ray && \
ray –-version
# Default command
CMD [ "/bin/bash" ]
EOF
次に、提供されたスクリプトを使用してイメージをビルドし、コンテナレジストリ(Amazon ECR)にプッシュします:
export AWS_REGION=$(aws configure get region)
export ACCOUNT=$(aws sts get-caller-identity --query Account --output text)
export REGISTRY=${ACCOUNT}.dkr.ecr.${AWS_REGION}.amazonaws.com/
echo "This process may take 10-15 minutes to complete..."
echo "Building image..."
docker build --platform linux/amd64 -t ${REGISTRY}aws-ray-custom:latest .
# 必要に応じてレジストリを作成
REGISTRY_COUNT=$(aws ecr describe-repositories | grep \"aws-ray-custom\" | wc -l)
if [ "$REGISTRY_COUNT" == "0" ]; then
aws ecr create-repository --repository-name aws-ray-custom
fi
# レジストリにログイン
echo "Logging in to $REGISTRY ..."
aws ecr get-login-password --region $AWS_REGION| docker login --username AWS --password-stdin $REGISTRY
echo "Pushing image to $REGISTRY ..."
# イメージをレジストリにプッシュ
docker image push ${REGISTRY}aws-ray-custom:latest
これで、必要なRay依存関係とコードライブラリ依存関係を含むRayコンテナイメージがAmazon ECRに用意されました。
- Rayクラスターマニフェストを作成します。トレーニングジョブをホストするためにRayクラスターを使用します。RayクラスターはKubernetes上のRayインスタンスを管理するための主要なリソースです。ヘッドノードと複数のワーカーノードを含むRayノードのクラスターを表します。Ray cluster CRDは、Rayノードのセットアップ方法、通信方法、リソースの割り当て方法を決定します。Rayクラスター内のノードは、EKSまたはSageMaker HyperPodクラスターのPodとしてマニフェストされます。
クラスターマニフェストには2つの異なるセクションがあることに注意してください。headGroupSpecはRayクラスターのヘッドノードを定義し、workerGroupSpecsはRayクラスターのワーカーノードを定義します。ジョブは技術的にはヘッドノードでも実行できますが、ジョブが実行される実際のワーカーノードからヘッドノードを分離するのが一般的です。したがって、ヘッドノードのインスタンスはより小さいインスタンス(つまり、m5.2xlargeを選択)にすることができます。また、ヘッドノードはクラスターレベルのメタデータも管理するため、ノード障害のリスクを最小限に抑えるために(GPUはノード障害の潜在的な原因となる可能性があるため)、非GPUノードで実行することが有益な場合があります。
cat <<'EOF' > raycluster.yaml
apiVersion: ray.io/v1alpha1
kind: RayCluster
metadata:
name: rayml
labels:
controller-tools.k8s.io: "1.0"
spec:
# Rayヘッドポッドテンプレート
headGroupSpec:
# `rayStartParams`は`ray start`コマンドを設定するために使用されます。
# KubeRayの`rayStartParams`のデフォルト設定については、https://github.com/ray-project/kuberay/blob/master/docs/guidance/rayStartParams.mdを参照してください。
# `rayStartParams`で利用可能なすべてのオプションについては、https://docs.ray.io/en/latest/cluster/cli.html#ray-startを参照してください。
rayStartParams:
dashboard-host: '0.0.0.0'
#podテンプレート
template:
spec:
# nodeSelector:
#node.kubernetes.io/instance-type: "ml.m5.2xlarge"
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
- name: ray-head
image: ${REGISTRY}aws-ray-custom:latest ## IMAGE: ここでヘッドポッドが実行するイメージを選択できます
env: ## ENV: ここでヘッドポッドに送信するものを設定できます
- name: RAY_GRAFANA_IFRAME_HOST ## PROMETHEUS AND GRAFANA
value: http://localhost:3000
- name: RAY_GRAFANA_HOST
value: http://prometheus-grafana.prometheus-system.svc:80
- name: RAY_PROMETHEUS_HOST
value: http://prometheus-kube-prometheus-prometheus.prometheus-system.svc:9090
lifecycle:
preStop:
exec:
command: ["/bin/sh","-c","ray stop"]
resources:
limits: ## LIMITS: ヘッドポッドのリソース制限を設定
cpu: 1
memory: 8Gi
requests: ## REQUESTS: ヘッドポッドのリソースリクエストを設定
cpu: 1
memory: 8Gi
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265 # Rayダッシュボード
name: dashboard
- containerPort: 10001
name: client
- containerPort: 8000
name: serve
volumeMounts: ## VOLUMEMOUNTS
- name: fsx-storage
mountPath: /fsx
- name: ray-logs
mountPath: /tmp/ray
volumes:
- name: ray-logs
emptyDir: {}
- name: fsx-storage
persistentVolumeClaim:
claimName: fsx-claim
workerGroupSpecs:
# このグループのポッドレプリカはワーカータイプ
- replicas: 4 ## REPLICAS: 必要なワーカーポッドの数
minReplicas: 1
maxReplicas: 10
# 論理グループ名、この場合はsmall-group、機能的にもなれます
groupName: gpu-group
rayStartParams:
num-gpus: "8"
#podテンプレート
template:
spec:
#nodeSelector:
# node.kubernetes.io/instance-type: "ml.p5.48xlarge"
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
- name: ray-worker
image: ${REGISTRY}aws-ray-custom:latest ## IMAGE: ここでヘッドノードが実行するイメージを選択できます
env:
lifecycle:
preStop:
exec:
command: ["/bin/sh","-c","ray stop"]
resources:
limits: ## LIMITS: ワーカーポッドのリソース制限を設定
nvidia.com/gpu: 8
#vpc.amazonaws.com/efa: 32
requests: ## REQUESTS: ワーカーポッドのリソースリクエストを設定
nvidia.com/gpu: 8
#vpc.amazonaws.com/efa: 32
volumeMounts: ## VOLUMEMOUNTS
- name: ray-logs
mountPath: /tmp/ray
- name: fsx-storage
mountPath: /fsx
volumes:
- name: fsx-storage
persistentVolumeClaim:
claimName: fsx-claim
- name: ray-logs
emptyDir: {}
EOF
- Rayクラスターをデプロイします:
envsubst < raycluster.yaml | kubectl apply -f -
- オプションで、ポートフォワーディングを使用してRayダッシュボードを公開します:
# ヘッドポッドを実行するkubectlサービスの名前を取得
export SERVICEHEAD=$(kubectl get service | grep head-svc | awk '{print $1}' | head -n 1)
# ヘッドポッドサービスからダッシュボードをポートフォワード
kubectl port-forward --address 0.0.0.0 service/${SERVICEHEAD} 8265:8265 > /dev/null 2>&1 &
これで、http://localhost:8265/にアクセスしてRayダッシュボードを表示できます。
- トレーニングジョブを起動するには、いくつかのオプションがあります:
- Rayジョブ送信SDKを使用する方法。Rayダッシュボードポート(デフォルトで8265)を通じてRayクラスターにジョブリクエストを送信できます。詳細については、Ray Jobs CLIを使用したクイックスタートを参照してください。
- ヘッドポッドで直接Rayジョブを実行する方法。ヘッドポッドに直接execしてからジョブを送信します。詳細については、RayCluster クイックスタートを参照してください。
この例では、最初の方法を使用し、SDKを通じてジョブを送信します。したがって、トレーニングコードが利用可能な--working-dirのローカル環境から単純に実行します。このパスを基準に、メインのトレーニングPythonスクリプトを--train.pyで指定します。
working-dirフォルダ内には、トレーニングの実行に必要な追加のスクリプトも含めることができます。
fsdp-ray.pyの例は、aws-do-ray GitHubリポジトリのaws-do-ray/Container-Root/ray/raycluster/jobs/fsdp-ray/fsdp-ray.pyにあります。
# jobs/フォルダ内で
ray job submit --address http://localhost:8265 --working-dir "fsdp-ray" -- python3 fsdp-ray.py
Pythonトレーニングスクリプトを実行するには、Rayを使用するようにトレーニングスクリプトが正しく設定されていることを確認する必要があります。これには以下の手順が含まれます:
- モデルを分散実行し、正しいCPU/GPUデバイスで実行するように設定
- データローダーをワーカー間でデータをシャードし、正しいCPUまたはGPUデバイスにデータを配置するように設定
- メトリクスを報告しチェックポイントを保存するトレーニング関数を設定
- トレーニングジョブのためのスケーリングとCPUまたはGPUリソース要件を設定
-
[TorchTrainer](https://docs.ray.io/en/releases-2.8.0/train/api/doc/ray.train.torch.TorchTrainer.html#ray.train.torch.TorchTrainer)クラスを使用して分散トレーニングジョブを起動
Rayを最大限活用するために既存のトレーニングスクリプトを調整する方法の詳細については、Rayドキュメントを参照してください。
以下の図は、これらの手順を完了した後に構築した完全なアーキテクチャを示しています。
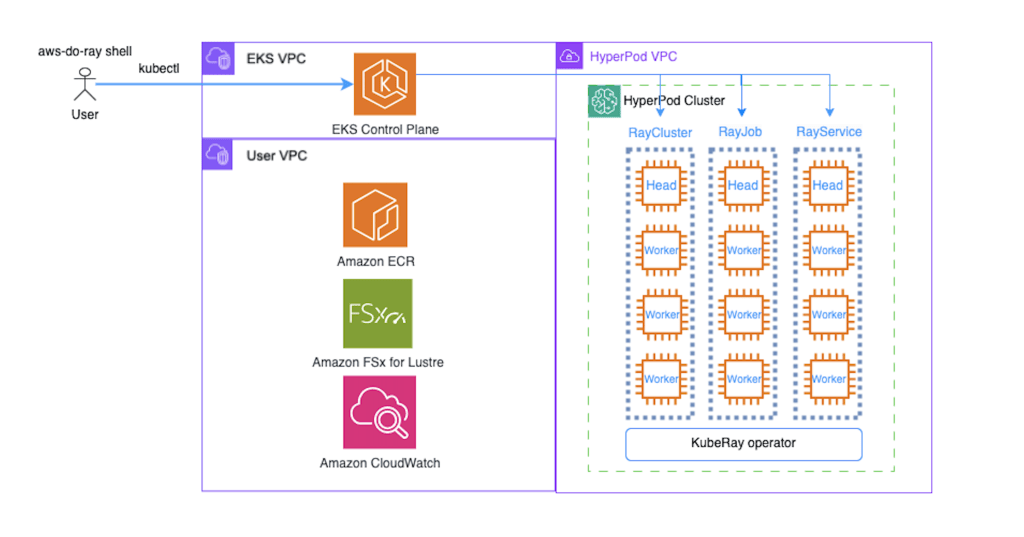
ジョブ自動再開機能によるトレーニングジョブの回復力の実装
Rayは、分散システムで避けられない障害に対する堅牢なフォールトトレランスメカニズムを備えて設計されています。これらの障害は一般的に2つのカテゴリーに分類されます:ユーザーコードのバグや外部システムの問題に起因するアプリケーションレベルの障害と、ノードのクラッシュ、ネットワークの中断、またはRay内部のバグによって引き起こされるシステムレベルの障害です。これらの課題に対処するために、Rayはアプリケーションが障害を検出、回復、適応できるようにするツールと戦略を提供し、分散環境での信頼性とパフォーマンスを提供します。このセクションでは、SageMaker HyperPodが補完する最も一般的な2つのタイプの障害と、それらにおけるフォールトトレランスの実装方法を見ていきます:Ray Trainワーカーの障害とRayワーカーノードの障害です。
- Ray Trainワーカー – これは、Ray Train(Rayの分散トレーニングライブラリ)内で特にトレーニングタスクに使用されるワーカープロセスです。これらのワーカーは、分散トレーニングジョブの個々のタスクまたはシャードを処理します。各ワーカーは、データの一部の処理、モデルのサブセットのトレーニング、または分散トレーニング中の計算の実行を担当します。これらはRay Trainのオーケストレーションロジックによって調整され、集合的にモデルをトレーニングします。
- Rayワーカーノード – Rayレベルでは、これはRayクラスター内のRayノードです。タスク、アクター、その他のプロセスをRayヘッドノードによってオーケストレーションされるように実行する責任があるRayクラスターインフラストラクチャの一部です。各ワーカーノードは、タスクを実行したり分散オブジェクトを管理したりする複数のRayプロセスをホストできます。Kubernetesレベルでは、RayワーカーノードはKubeRayオペレーターによって管理されるKubernetesポッドです。この記事では、Kubernetesレベルでのrayワーカーノードについて説明するので、それらを_ポッド_と呼びます。
執筆時点では、ヘッドポッドのフォールトトレランスと自動再開機能に関する公式のアップデートはありません。ヘッドポッドの障害は稀ですが、そのような障害が発生した場合は、トレーニングジョブを手動で再起動する必要があります。ただし、最後に保存されたチェックポイントから進行状況を再開することはできます。ハードウェア関連のヘッドポッド障害のリスクを最小限に抑えるために、ヘッドポッドを専用のCPUのみのSageMaker HyperPodノードに配置することをお勧めします。これは、GPU障害がトレーニングジョブ障害の一般的な原因となるためです。
Ray Trainワーカーの障害
Ray Trainは、RayActorErrorsなどのワーカー障害を処理するためのフォールトトレランスを備えて設計されています。障害が発生すると、影響を受けたワーカーは停止され、操作を維持するために新しいワーカーが自動的に起動されます。ただし、障害後にトレーニングの進行を継続するには、チェックポイントの保存とロードが不可欠です。適切なチェックポイントがないと、トレーニングスクリプトは再起動されますが、すべての進行状況が失われます。したがって、チェックポイントはRay Trainのフォールトトレランスメカニズムの重要なコンポーネントであり、コードに実装する必要があります。
自動回復
障害が検出されると、Rayは障害が発生したワーカーをシャットダウンし、新しいワーカーをプロビジョニングします。これは発生しますが、トレーニングが継続できるまで常に再試行するようにトレーニング関数に指示することができます。ワーカー障害からの回復の各インスタンスは再試行とみなされます。再試行の回数は、[RunConfig](https://docs.ray.io/en/latest/train/api/doc/ray.train.RunConfig.html)の[FailureConfig](https://docs.ray.io/en/latest/train/api/doc/ray.train.FailureConfig.html)のmax_failures属性を通じて設定できます。このRunConfigはTrainer(例:[TorchTrainer](https://docs.ray.io/en/latest/train/api/doc/ray.train.torch.TorchTrainer.html))に渡されます。以下のコードを参照してください:
from ray.train import RunConfig, FailureConfig
# 実行を最大でこの回数まで回復を試みます。
run_config = RunConfig(failure_config=FailureConfig(max_failures=2))
# 再試行回数に制限なし。
run_config = RunConfig(failure_config=FailureConfig(max_failures=-1))
詳細については、障害とノードの先取りの処理を参照してください。
チェックポイント
Ray Trainのチェックポイントは、ローカルまたはリモートに保存されたディレクトリを表す軽量なインターフェースです。例えば、クラウドベースのチェックポイントはs3://my-bucket/checkpoint-dirを指し、ローカルチェックポイントは/tmp/checkpoint-dirを指す場合があります。詳細については、トレーニング中のチェックポイントの保存を参照してください。
トレーニングループでチェックポイントを保存するには、まず一時的なものでも構わないローカルディレクトリにチェックポイントを書き込む必要があります。保存時には、torch.save、pl.Trainer.save_checkpoint、accelerator.save_model、save_pretrained、tf.keras.Model.saveなどの他のフレームワークのチェックポイントユーティリティを使用できます。次に、Checkpoint.from_directoryを使用してディレクトリからチェックポイントを作成します。最後に、ray.train.report(metrics, checkpoint=...)を使用してチェックポイントをRay Trainに報告します。チェックポイントと一緒に報告されるメトリクスは、最高のパフォーマンスを示すチェックポイントを追跡するために使用されます。報告すると、チェックポイントは永続ストレージにアップロードされます。
[ray.train.report(..., checkpoint=...)](https://docs.ray.io/en/latest/train/api/doc/ray.train.report.html#ray.train.report)でチェックポイントを保存し、マルチノードクラスターで実行する場合、NFSまたはクラウドストレージが設定されていないとRay Trainはエラーを発生させます。これは、Ray Trainがすべてのワーカーが同じ永続ストレージの場所にチェックポイントを書き込めることを期待するためです。
最後に、ディスク容量を解放するためにローカルの一時ディレクトリをクリーンアップします(例:tempfile.TemporaryDirectoryコンテキストを終了することで)。チェックポイントはエポックごとまたは数イテレーションごとに保存できます。
以下の図は、このセットアップを示しています。
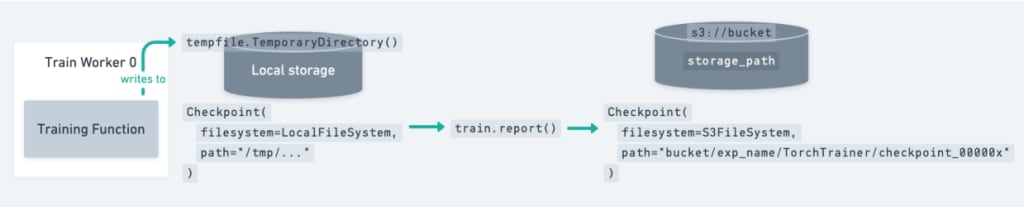
以下は、ネイティブPyTorchを使用してチェックポイントを保存する例です:
import os
import tempfile
import numpy as np
import torch
import torch.nn as nn
from torch.optim import Adam
import ray.train.torch
from ray import train
from ray.train import Checkpoint, ScalingConfig
from ray.train.torch import TorchTrainer
def train_func(config):
n = 100
# トイデータセットを作成
# データ : X - dim = (n, 4)
# ターゲット : Y - dim = (n, 1)
X = torch.Tensor(np.random.normal(0, 1, size=(n, 4)))
Y = torch.Tensor(np.random.uniform(0, 1, size=(n, 1)))
# トイニューラルネットワーク : 1層
# モデルをDDPでラップ
model = ray.train.torch.prepare_model(nn.Linear(4, 1))
criterion = nn.MSELoss()
optimizer = Adam(model.parameters(), lr=3e-4)
for epoch in range(config["num_epochs"]):
y = model.forward(X)
loss = criterion(y, Y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
metrics = {"loss": loss.item()}
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
checkpoint = None
should_checkpoint = epoch % config.get("checkpoint_freq", 1) == 0
# 標準的なDDPトレーニングでは、モデルはすべてのランクで同じなので、
# グローバルランク0のワーカーだけがチェックポイントを保存・報告する必要があります
if train.get_context().get_world_rank() == 0 and should_checkpoint:
torch.save(
model.module.state_dict(), # 注意: モデルをアンラップします
os.path.join(temp_checkpoint_dir, "model.pt"),
)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
train.report(metrics, checkpoint=checkpoint)
trainer = TorchTrainer(
train_func,
train_loop_config={"num_epochs": 5},
scaling_config=ScalingConfig(num_workers=2),
)
result = trainer.fit()
Ray Trainには、チェックポイントのオプションを設定するための[CheckpointConfig](https://docs.ray.io/en/latest/train/api/doc/ray.train.CheckpointConfig.html#ray.train.CheckpointConfig)も用意されています:
from ray.train import RunConfig, CheckpointConfig
# 例1: 最新の2つのチェックポイントのみを保持し、他は削除します
run_config = RunConfig(checkpoint_config=CheckpointConfig(num_to_keep=2))
# 例2: 最高の2つのチェックポイントのみを保持し、他は削除します
run_config = RunConfig(
checkpoint_config=CheckpointConfig(
num_to_keep=2,
# *最高の*チェックポイントは以下のパラメータで決定されます:
checkpoint_score_attribute="mean_accuracy",
checkpoint_score_order="max",
),
# これによりチェックポイントはS3に保存されます
storage_path="s3://remote-bucket/location",
)
トレーニングジョブが失敗して再試行する場合にチェックポイントからトレーニング状態を復元するには、トレーニングループを自動再開するように変更し、Ray Trainジョブを復元する必要があります。保存したチェックポイントのパスを指定することで、トレーナーを復元してトレーニングを継続できます。以下は簡単な例です:
from ray.train.torch import TorchTrainer
restored_trainer = TorchTrainer.restore(
path="~/ray_results/dl_trainer_restore", # S3などのクラウドストレージパスも指定可能
datasets=get_datasets(),
)
result = restored_trainer.fit()
復元を効率化するために、スクリプトに自動再開ロジックを追加できます。これにより、有効な実験ディレクトリが存在するかどうかを確認し、利用可能な場合はトレーナーを復元し、そうでない場合は新しい実験を開始します:
experiment_path = "~/ray_results/dl_restore_autoresume"
if TorchTrainer.can_restore(experiment_path):
trainer = TorchTrainer.restore(experiment_path, datasets=get_datasets())
else:
trainer = TorchTrainer(
train_loop_per_worker=train_loop_per_worker,
datasets=get_datasets(),
scaling_config=train.ScalingConfig(num_workers=2),
run_config=train.RunConfig(
storage_path="~/ray_results",
name="dl_restore_autoresume",
),
)
result = trainer.fit()
要約すると、Ray Trainライブラリを使用する際のフォールトトレランスと自動再開を提供するには、FailureConfigのmax_failuresパラメータを設定し(SageMaker HyperPodノードが再起動または交換されるまで再試行を継続するために-1に設定することを推奨)、コードでチェックポイントを有効にしていることを確認する必要があります。
Rayワーカーポッドの障害
前述のRay Trainワーカーの障害から回復するメカニズムに加えて、Rayはワーカーポッドレベルでもフォールトトレランスを提供します。ワーカーポッドが失敗した場合(これにはrayletプロセスが失敗するシナリオも含まれます)、そのポッド上で実行中のタスクとアクターは失敗し、このポッドのワーカープロセスが所有するオブジェクトは失われます。この場合、タスク、アクター、オブジェクトのフォールトトレランスメカニズムが開始され、他のワーカーポッドを使用して障害から回復を試みます。
これらのメカニズムはRay Trainライブラリによって暗黙的に処理されます。タスク、アクター、オブジェクトの基礎となるフォールトトレランス(Ray Coreレベルで実装)の詳細については、フォールトトレランスを参照してください。
実際には、ワーカーポッドの障害が発生した場合、以下のようになります:
- Rayクラスターに空きワーカーポッドがある場合、Rayは空きワーカーポッドで失敗したワーカーポッドを置き換えて回復します。
- 空きワーカーポッドはないが、基盤となるSageMaker HyperPodクラスターに空きのSageMaker HyperPodノードがある場合、Rayは空きのSageMaker HyperPodノードの1つに新しいワーカーポッドをスケジュールします。このポッドは実行中のRayクラスターに参加し、この新しいワーカーポッドを使用して障害が回復されます。
KubeRayのコンテキストでは、Rayワーカーノードはkubernetesポッドとして表現され、このレベルでの障害には、ソフトウェアレベルの要因によるポッドの退避やプリエンプションなどの問題が含まれる可能性があります。
ただし、考慮すべき重要なシナリオとしてハードウェア障害があります。基盤となるSageMaker HyperPodノードがGPUエラーなどのハードウェアの問題で利用できなくなった場合、そのノード上で実行中のRayワーカーポッドも必然的に失敗します。この時点で、SageMaker HyperPodクラスターのフォールトトレランスと自動修復メカニズムが開始され、障害のあるノードを再起動または交換します。新しい正常なノードがSageMaker HyperPodクラスターに追加された後、RayはSageMaker HyperPodノードに新しいワーカーポッドをスケジュールし、中断されたトレーニングを回復します。この場合、RayのフォールトトレランスメカニズムとSageMaker HyperPodの回復力機能が連携してシームレスに動作し、ハードウェア障害が発生した場合でもMLトレーニングワークロードが自動的に再開され、中断された場所から再開できることを保証します。
ご覧のように、SageMaker HyperPod上のRay Trainワークロードが回復して自動再開できるようにする組み込みの回復力とフォールトトレランスメカニズムが様々にあります。これらのメカニズムは本質的にトレーニングジョブを再起動することで回復するため、トレーニングスクリプトにチェックポイントを実装することが重要です。また、一般的にAmazon Simple Storage Service(Amazon S3)バケットやFSx for Lustreファイルシステムなどの共有および永続的なパスにチェックポイントを保存することが推奨されます。
クリーンアップ
この記事で作成したSageMaker HyperPodクラスターを削除するには、SageMaker AIコンソールを使用するか、以下のAWS CLIコマンドを使用できます:
aws sagemaker delete-cluster --cluster-name <cluster_name>
クラスターの削除には数分かかります。SageMaker AIコンソールでクラスターが表示されなくなったら、削除が正常に完了したことを確認できます。
CloudFormationスタックを使用してリソースを作成した場合は、以下のコマンドを使用して削除できます:
aws cloudformation delete-stack --stack-name <stack_name>
結論
この記事では、SageMaker HyperPod上でRayクラスターをセットアップおよびデプロイする方法を示し、ストレージ構成やフォールトトレランス、自動再開メカニズムなどの重要な考慮事項を強調しました。
SageMaker HyperPod上でRayジョブを実行することは、Rayの柔軟性とSageMaker HyperPodの堅牢なインフラストラクチャを組み合わせた、分散AI/MLワークロードのための強力なソリューションを提供します。この統合により、長時間実行およびリソース集約型のタスクに不可欠な強化された回復力と自動再開機能が提供されます。RayのDistributed ComputingフレームワークとSageMaker HyperPodの組み込み機能を使用することで、この記事で説明したトレーニングワークロードを特に含む複雑なMLワークフローを効率的に管理できます。AI/MLワークロードの規模と複雑さが増し続ける中、RayとSageMaker HyperPodの組み合わせは、機械学習における最も要求の厳しい計算課題に取り組むためのスケーラブルで回復力のある効率的なプラットフォームを提供します。
SageMaker HyperPodを始めるには、Amazon EKS Support in Amazon SageMaker HyperPod workshopとAmazon SageMaker HyperPod Developer Guideを参照してください。aws-do-rayフレームワークの詳細については、GitHubリポジトリを参照してください。
著者について
Mark Vinciguerraはニューヨークを拠点とするAmazon Web Services(AWS)のアソシエイトスペシャリストソリューションアーキテクトです。自動車および製造業セクターに焦点を当て、組織が人工知能および機械学習ソリューションをアーキテクト、最適化、スケーリングするのを支援することを専門としており、特に自動運転車技術に関する専門知識を持っています。AWSに入社する前は、ボストン大学でコンピュータ工学の学位を取得しました。
Florian Stahlはドイツのハンブルクを拠点とするAWSのワールドワイドスペシャリストソリューションアーキテクトです。人工知能、機械学習、生成AIソリューションを専門とし、お客様がAWS上でAI/MLワークロードを最適化およびスケーリングするのを支援しています。データサイエンティストとしてのバックグラウンドを持つFlorianは、自動運転車分野のお客様との協力に焦点を当て、組織が洗練された機械学習ソリューションを設計および実装するのを支援するための深い技術的専門知識を提供しています。彼は世界中のお客様と密接に協力して、AIイニシアチブを変革し、AWS上での機械学習投資の価値を最大化しています。
Anoop Sahaは、生成AIモデルのトレーニングと推論に焦点を当てたAmazon Web Services(AWS)のシニアGTMスペシャリストです。トップの基盤モデルビルダー、戦略的顧客、AWSサービスチームと提携して、AWS上での分散トレーニングと推論をスケールで実現し、共同GTMモーションをリードしています。AWSに入社する前は、主にAIインフラストラクチャのシリコンおよびシステムアーキテクチャに焦点を当てて、スタートアップや大企業で複数のリーダーシップ役割を務めてきました。
Alex Iankoulskiは、お客様がAWS上でコンテナと高速コンピューティングインフラストラクチャを使用してAIワークロードをオーケストレーションするのを支援することに焦点を当てたプリンシパルソリューションアーキテクト、ML/AIフレームワークです。彼はまた、オープンソースのdoフレームワークの作者であり、世界最大の課題を解決しながらイノベーションのペースを加速するためにコンテナ技術を適用することを愛するDockerキャプテンでもあります。
Discussion