[翻訳] Amazon SageMaker AI で OpenAI GPT-OSS モデルをファインチューニング
Fine-tune OpenAI GPT-OSS models on Amazon SageMaker AI using Hugging Face libraries のブログ翻訳。
著者: Pranav Murthy および Sumedha Swamy
投稿日: 2025年8月11日
カテゴリ: Amazon SageMaker, Amazon SageMaker AI, お知らせ, 人工知能, Foundation models
2025 年 8 月 5 日にリリースされた OpenAI の GPT-OSS モデル、gpt-oss-20b と gpt-oss-120b が、Amazon SageMaker AI と Amazon Bedrock を通じて AWS で利用可能になりました。これらの事前学習済みテキスト専用 Transformer モデルは、Mixture-of-Experts (MoE) アーキテクチャ上に構築されており、トークンごとにパラメータのサブセットのみをアクティブ化することで、計算コストを削減しながら高い推論性能を実現します。これらのモデルは、コーディング、科学的分析、数学的推論に特化しており、128,000 のコンテキスト長、調整可能な推論レベル(低/中/高)、監査に適したトレースを持つ chain-of-thought (CoT) 推論、構造化出力、およびエージェント AI ワークフローをサポートするツール使用をサポートしています。OpenAI のドキュメントで説明されているように、両モデルは安全性に焦点を当てた学習と敵対的ファインチューニング評価を受けて、悪用に対する堅牢性を評価し強化しています。以下の表はモデル仕様をまとめたものです。
| モデル | レイヤー数 | 総パラメータ数 | トークンあたりのアクティブパラメータ数 | 総エキスパート数 | トークンあたりのアクティブエキスパート数 | コンテキスト長 |
|---|---|---|---|---|---|---|
| openai/gpt-oss-120b | 36 | 1170億 | 51億 | 128 | 4 | 128,000 |
| openai/gpt-oss-20b | 24 | 210億 | 36億 | 32 | 4 | 128,000 |
GPT-OSS モデルは Amazon SageMaker JumpStart を使用してデプロイ可能であり、Amazon Bedrock API を通じてもアクセス可能です。両方のオプションにより、開発者は GPT-OSS モデルを本番グレードの AI ワークフローにデプロイし統合する柔軟性を得られます。すぐに使えるデプロイメントに加えて、これらのモデルは Hugging Face エコシステムのオープンソースツールを使用し、SageMaker AI の完全管理インフラストラクチャ上で実行することで、特定のドメインやユースケースに合わせてファインチューニングできます。
大規模言語モデル(LLM)のファインチューニングは、事前学習済みモデルの重みを、より小さなタスク固有のデータセットを使用して調整し、特定のドメインやアプリケーションに合わせてモデルの動作を調整するプロセスです。GPT-OSS のような大規模モデルのファインチューニングは、ゼロから学習するコストをかけることなく、幅広い汎用性を持つモデルをドメイン固有のエキスパートに変換します。モデルをあなたのデータと専門用語に適応させることで、より正確でコンテキストを理解した出力を提供し、信頼性を向上させ、幻覚を減らすことができます。その結果、安全でエンタープライズグレードのデプロイメントに理想的な、スケーラビリティ、柔軟性、オープンウェイトの利点を保持しながら、対象タスクに優れた特化型 GPT-OSS が得られます。
この投稿では、SageMaker AI トレーニングジョブを使用して完全管理されたトレーニング環境で GPT-OSS モデルをファインチューニングするプロセスを説明します。このワークフローでは、ファインチューニングに Hugging Face TRL ライブラリ、複数の GPU とノード間での分散トレーニングを簡素化する Hugging Face Accelerate ライブラリ、および数十億パラメータモデルの効率的なトレーニングのためにデバイス間でモデル状態を分割してメモリ使用量を削減する DeepSpeed ZeRO-3 最適化技術を使用します。その後、この設定を多言語推論データセット HuggingFaceH4/Multilingual-Thinking で GPT-OSS モデルをファインチューニングするために適用し、GPT-OSS が複数言語にわたって構造化された CoT 推論を処理できるようにします。
ソリューション概要
SageMaker AI は、Foundation Model (FM) のライフサイクル全体を合理化する管理された機械学習 (ML) サービスです。迅速な探索のためのホスト型インタラクティブノートブック、大規模で分散されたファインチューニングのための完全管理された一時的なトレーニングジョブ、および大規模なモデルトレーニングとファインチューニングワークロードのための永続的なトレーニングインフラストラクチャに対する詳細な制御を提供する Amazon SageMaker HyperPod クラスターを提供します。SageMaker での管理されたホスティングを使用することで、本番環境でモデルを確実に提供でき、再利用可能なパイプラインや完全管理された MLflow などの AIOps 対応ツールのスイートが、実験追跡、モデル登録、シームレスなデプロイメントをサポートします。組み込まれたガバナンスとエンタープライズグレードのセキュリティにより、SageMaker AI は、データエンジニア、データサイエンティスト、ML エンジニアに、FM をエンドツーエンドで構築、トレーニング、デプロイ、ガバナンスするための統一された完全管理プラットフォームを提供します。
GPT-OSS は、Hugging Face SFTTrainer を使用して LLM をファインチューニングするためのレシピとして記述できる最新の Hugging Face TRL ライブラリを使用して SageMaker でファインチューニングできます。これらのレシピは、Qwen、Mistral、Meta など、他のオープンウェイト言語モデルや視覚モデルのファインチューニングにも適応できます。この投稿では、単一ノードマルチ GPU セットアップまたはマルチノードマルチ GPU セットアップのいずれかで分散セットアップで GPT-OSS をファインチューニングする方法を示し、Hugging Face Accelerate を使用してマルチデバイストレーニングを管理し、DeepSpeed ZeRO-3 を使用して大規模モデルをより効率的にトレーニングします。これらを組み合わせることで、より高速なファインチューニングと大規模データセットへのスケーリングが可能になります。
また、Open Compute Project の 4 ビット浮動小数点量子化フォーマットである MXFP4 (Microscaling FP4) についても紹介します。これは、テンソルを小さなブロックにグループ化し、各ブロックがスケーリングファクターを共有することで、モデルの精度を保持しながらメモリと計算の必要性を削減し、効率的なモデルトレーニングに適しています。量子化を補完するものとして、すべての重みを変更する代わりに少数の追加パラメータを学習することで大規模モデルを適応させる LoRA などの Parameter-Efficient Fine-Tuning (PEFT) 手法を探求します。このアプローチは、メモリと計算効率が高く、量子化されたモデルとの互換性が高く、制約のあるハードウェア環境でもファインチューニングをサポートします。
以下の図は、この構成を示しています(出典)。
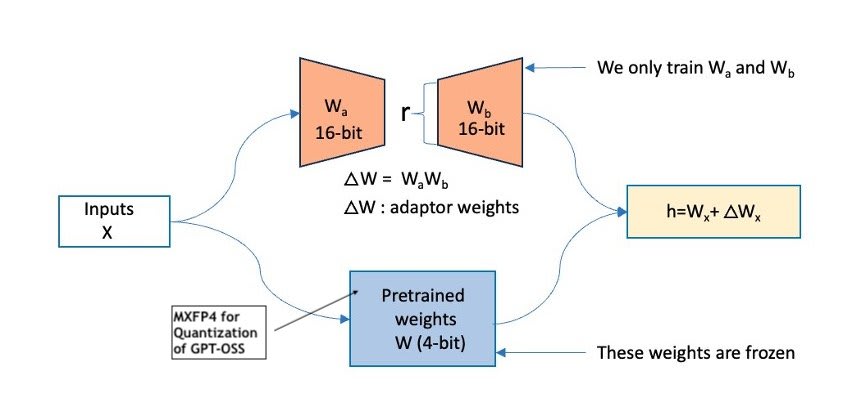
MXFP4 量子化、LoRA などの PEFT ファインチューニング手法、および Hugging Face Accelerate と DeepSpeed ZeRO-3 による分散トレーニングを組み合わせることで、インフラストラクチャと計算コストを管理可能に保ちながら、gpt-oss-120b や gpt-oss-20b などの大規模モデルを効率的かつスケーラブルにファインチューニングして高性能なカスタマイゼーションを実現できます。
前提条件
SageMaker AI で GPT-OSS モデルをファインチューニングするには、以下の前提条件が必要です:
- AWS リソースを含む AWS アカウント。
- SageMaker AI にアクセスするための AWS Identity and Access Management (IAM) ロール。IAM が SageMaker AI とどのように連携するかについて詳しくは、Amazon SageMaker AI の AWS Identity and Access Management を参照してください。
- この投稿で提供されるノートブックは、AWS 認証情報が適切に設定され、AWS アカウントにアクセスするように構成されている限り、PyCharm や Visual Studio Code などの統合開発環境 (IDE) を含む、お好みの開発環境から実行できます。ローカル環境を設定するには、AWS CLI の設定 を参照してください。オプションとして、SageMaker AI での簡単な開発プロセスのために Amazon SageMaker Studio を使用することをお勧めします。
- この投稿に従う場合、120B モデルのファインチューニングには ml.p5en.48xlarge インスタンス、20B モデルには ml.p4de.24xlarge インスタンスを使用します。この投稿で紹介するサンプルノートブックを実行するには、これらの SageMaker コンピュートインスタンスへのアクセスが必要です。不明な場合は、AWS Management Console で AWS サービスクォータ を確認できます:
- クォータの管理 で AWS サービスとして Amazon SageMaker を選択します。
- ファインチューニングに興味のあるモデルに基づいて ml.p4de.24xlarge for training job usage または ml.p5en.48xlarge for training job usage を選択し、アカウントレベルでの増加を要求します。
- GitHub リポジトリ へのアクセス。
GPT-OSS ファインチューニングのビジネス成果
グローバル企業は、多言語仮想アシスタント、複数拠点のサポートデスク、国際的な知識システムなど、複数言語にわたる複雑な推論をサポートする AI ツールをますます必要としています。FM は強力な出発点を提供しますが、多様な言語コンテキストでの効果は、構造化された推論入力、つまり論理ステップを明示的に複数言語にわたって表面化するデータセットに依存します。そのため、多言語の CoT スタイルデータセットでのテストは価値ある最初のステップです。これにより、言語と推論パターンを切り替える際にモデルがどの程度推論の一貫性を保持するかを検証でき、大規模なドメイン固有の多言語データセットにスケーリングする前に堅牢な基盤を築くことができます。GPT-OSS は、ネイティブな CoT 機能、長い 128,000 コンテキストウィンドウ、調整可能な推論レベルを備えているため、このタスクに特に適しており、本番デプロイメント前に多言語推論性能を評価し改良するのに理想的です。
SageMaker AI での多言語推論のための GPT-OSS モデルのファインチューニング
このセクションでは、トレーニングジョブ を使用して SageMaker AI で OpenAI の GPT-OSS モデルをファインチューニングする方法を説明します。SageMaker トレーニングジョブは分散マルチ GPU およびマルチノード構成をサポートしているため、オンデマンドで高性能クラスターを起動し、数十億パラメータモデルをより高速にトレーニングし、ジョブが完了すると自動的にリソースをシャットダウンできます。
環境の設定
以下のセクションでは、SageMaker Studio JupyterLab ノートブックインスタンス からコードを実行します。VS Code や PyCharm などのお好みの IDE を使用することもできますが、前提条件で説明したように、ローカル環境が AWS で動作するように構成されていることを確認してください。
以下の手順を完了してください:
- SageMaker AI コンソールで、ナビゲーションペインの Domains を選択し、ドメインを開きます。
- Applications and IDEs の下のナビゲーションペインで、Studio を選択します。
- User profiles タブで、ユーザープロファイルを見つけ、Launch を選択してから Studio を選択します。
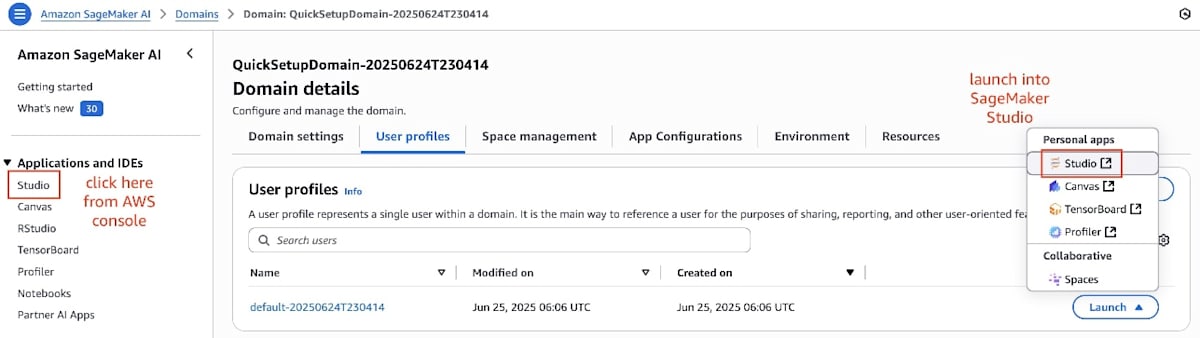
- SageMaker Studio で、少なくとも 50 GB のストレージを持つ ml.t3.medium JupyterLab ノートブックインスタンスを起動します。
ファインチューニングジョブは NVIDIA アクセラレータを搭載した別の一時的なトレーニングジョブインスタンスで実行されるため、大きなノートブックインスタンスは必要ありません。

- ファインチューニングを開始するには、まず GitHub リポジトリ をクローンし、
3_distributed_training/models/openai--gpt-ossディレクトリに移動してから、Python 3.12 以上のバージョンカーネルで finetune_gpt_oss.ipynb ノートブックを起動します:
# GitHub リポジトリをクローン
git clone https://github.com/aws-samples/amazon-sagemaker-generativeai.git
ファインチューニング用データセット
適切なデータセットの選択と整理は、LLM のファインチューニングにおける重要な最初のステップです。この投稿では、フランス語、スペイン語、ドイツ語などの言語に翻訳された CoT 例を含む多言語推論データセット Hugging FaceH4/Multilingual-Thinking を使用します。多様な言語、様々な推論タスク、明示的なステップバイステップの思考プロセスの組み合わせにより、モデルが構造化された推論をどのように処理し、多言語入力に適応し、異なる言語コンテキスト間で論理的一貫性を維持するかを評価するのに適しています。約 1,000 の例があり、迅速な実験には十分小さく、GPT-OSS のような大規模な事前学習済みモデルのファインチューニングと評価を実証するには十分です。データセットは、Hugging Face Datasets ライブラリを使用してわずか数行のコードで読み込むことができます:
# データセットをメモリに読み込み
dataset_name = 'HuggingFaceH4/Multilingual-Thinking'
dataset = load_dataset(dataset_name, split="train")
以下はサンプルデータのコードです:
{
"reasoning_language": "French",
"developer": "You are a recipe suggestion bot, ...",
"user": "Can you provide me with a step-by-step ...",
"analysis": "D'accord, l'utilisateur souhaite une recette ...",
"final": "Certainly! Here's a classic homemade chocolate ...",
"messages": [
{
"content": "reasoning language: French\n\nYou are a ...",
"role": "system",
"thinking": null
},
{
"content": "Can you provide me with a step-by-step ...",
"role": "user",
"thinking": null
},
{
"content": "Certainly! Here's a classic homemade chocolate ...",
"role": "assistant",
"thinking": "D'accord, l'utilisateur souhaite une recette ..."
}
]
}
教師ありファインチューニングでは、GPT-OSS モデルをトレーニングするために messages キーのデータのみを使用します。TRL の SFTTrainer がこの形式をネイティブにサポートしているため、そのまま使用できます。messages キーのみを含むすべての行を抽出し、JSONL 形式で保存し、ファイルを Amazon Simple Storage Service (Amazon S3) にアップロードします。これにより、データセットが実行時に SageMaker トレーニングジョブから容易にアクセスできるようになります。
# messages キーのみを保持
dataset = dataset.remove_columns(
[col for col in dataset.column_names if col != "messages"]
)
# JSONL 形式で保存
dataset_filename = os.path.join(dataset_parent_path, f"{dataset_name.replace('/', '--').replace('.', '-')}.jsonl")
dataset.to_json(dataset_filename, lines=True)
...
from sagemaker.s3 import S3Uploader
# データ保存先バケットを選択
data_s3_uri = f"s3://{sess.default_bucket()}/dataset"
# S3 にアップロード
uploaded_s3_uri = S3Uploader.upload(
local_path=dataset_filename,
desired_s3_uri=data_s3_uri
)
print(f"Uploaded {dataset_filename} to > {uploaded_s3_uri}")
MLflow による実験追跡(オプション)
SageMaker AI は 完全管理された MLflow 機能 を提供しているため、実験内で複数のトレーニング実行を追跡し、視覚化で結果を比較し、モデルを評価し、最良のものをモデルレジストリに登録できます。MLflow はエージェントワークフローとの統合もサポート しています。
TRL の SFTTrainer は、MLflow、TensorBoard、Weights & Biases などの実験追跡ツールとネイティブに統合されています。SFTTrainer を使用すると、トレーニングパラメータ、ハイパーパラメータ、損失メトリクス、システムメトリクスなどを一元的な場所にログできるため、監査証跡、ガバナンス、合理化された実験追跡が提供されます。このステップはオプションです。SageMaker 管理 MLflow を使用しない場合は、SFTTrainer パラメータ reports_to を tensorboard に設定できます。これにより、すべてのメトリクスがローカルディスクにログされ、ローカルまたは リモート TensorBoard サービス を使用して視覚化できます。
# ローカルディスクにログするには none に設定
MLFLOW_TRACKING_SERVER_ARN = None # または "arn:aws:sagemaker:us-west-2:<account-id>:mlflow-tracking-server/<server-name>"
if MLFLOW_TRACKING_SERVER_ARN:
reports_to = "mlflow"
else:
reports_to = "tensorboard"
print("reports to:", reports_to)
TRL の SFTTrainer から SageMaker の MLflow 追跡サーバーにログされた実験は、主要なメトリクスとパラメータを自動的にキャプチャします。SageMaker 管理 MLflow サービスは、リアルタイム視覚化をレンダリングし、最小限の設定でトレーニングハードウェアをプロファイルし、並行実行比較を可能にし、組み込み評価ツールを提供して、ファインチューニングジョブをエンドツーエンドで追跡、トレーニング、評価します。
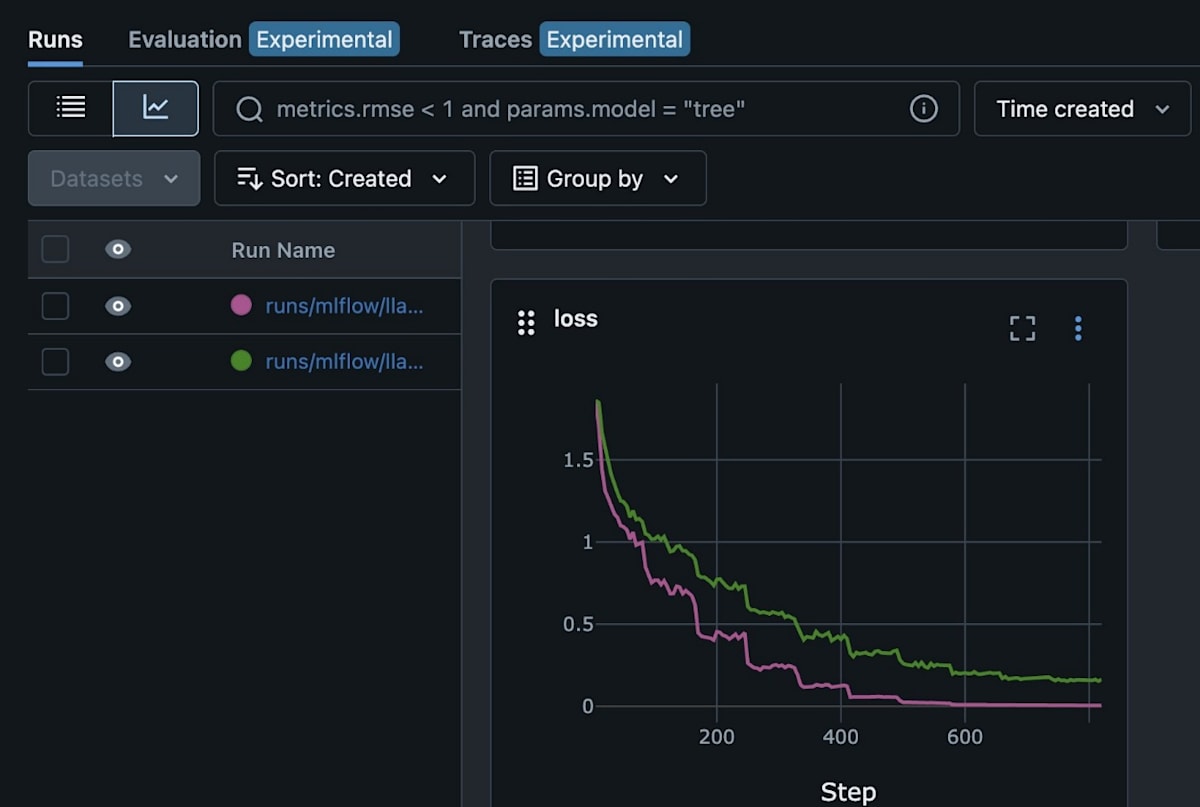
トレーニングジョブでの GPT-OSS ファインチューニング
以下の例では、gpt-oss-20b モデルをファインチューニングする方法を示します。gpt-oss-120b に切り替えるには、単純に model_name を更新するだけです。このセクションで示すモデルとインスタンスのマッピングは、このノートブックワークフローの一部としてテストされています。特定のユースケースに合わせてインスタンスタイプとインスタンス数を調整できます。
以下の表は、異なるモデル仕様をまとめたものです。
| GPT‑OSS モデル | SageMaker インスタンス | GPU 仕様 |
|---|---|---|
| openai/gpt-oss-120b | ml.p5en.48xlarge | 8× NVIDIA H200 GPU、各 96 GB HBM3 |
| openai/gpt-oss-20b | ml.p4de.24xlarge | 8× NVIDIA A100 GPU、各 80 GB HBM2e |
# ユーザー定義変数
model_name = "openai/gpt-oss-20b"
tokenizer_name = "openai/gpt-oss-20b"
# SageMaker コンテナ内のデータセットパス
dataset_path = "/opt/ml/input/data/training/HuggingFaceH4--Multilingual-Thinking.jsonl"
output_path = "/opt/ml/model/openai-gpt-oss-20b-HuggingFaceH4-Multilingual-Thinking/"
# Ampere、Hopper、Grace Blackwell のみサポート
bf16_flag = "true"
SageMaker トレーニングジョブは、指定された S3 プレフィックスまたはファイルからデータセットをトレーニングコンテナに自動的にダウンロードし、/opt/ml/input にマッピングします。トレーニングアーティファクトとログは /opt/ml/output に保存され、最終的にトレーニングまたはファインチューニングされたモデルは /opt/ml/model に保存されます。このパスにモデルを保存することで、SageMaker がモデル登録、デプロイメント、その他の自動化などの下流ワークフローで自動的に検出できるようになります。bf16_flag を設定または設定解除して、float16 と bfloat16 を選択できます。float16 はメモリ使用量が少ないですが数値範囲が狭く、bfloat16 は同様のメモリ節約で広い範囲を提供し、大規模モデルのトレーニングでより安定しています。bfloat16 は、NVIDIA Ampere、Hopper、Grace Blackwell などの新しい GPU アーキテクチャでサポートされています。
オープンソース Hugging Face レシピによるファインチューニング
Hugging Face の TRL ライブラリを使用すると、Supervised Fine-Tuning (SFT) レシピを定義できます。これらは基本的に、TRL の SFTTrainer と構成ツールを使用して、Meta、Qwen、Mistral、そして現在は OpenAI GPT‑OSS などの FM のファインチューニングを最小限の設定で合理化する事前構成されたトレーニングワークフローです。これらのレシピは、新しいデータセットにモデルを適応させるプロセスを簡素化します。
yaml_template = """# モデル引数
model_name_or_path: {{ model_name }}
tokenizer_name_or_path: {{ tokenizer_name }}
model_revision: main
torch_dtype: bfloat16
attn_implementation: kernels-community/vllm-flash-attn3
bf16: {{ bf16_flag }}
tf32: false
output_dir: {{ output_dir }}
# データセット引数
dataset_id_or_path: {{ dataset_path }}
max_seq_length: 2048
packing: true
packing_strategy: wrapped
# LoRA 引数
use_peft: true
lora_target_modules: "all-linear"
### GPT-OSS 固有
lora_modules_to_save: ["7.mlp.experts.gate_up_proj", "7.mlp.experts.down_proj", "15.mlp.experts.gate_up_proj", "15.mlp.experts.down_proj", "23.mlp.experts.gate_up_proj", "23.mlp.experts.down_proj"]
lora_r: 8
lora_alpha: 16
# トレーニング引数
num_train_epochs: 1.
per_device_train_batch_size: 6
per_device_eval_batch_size: 6
gradient_accumulation_steps: 3
gradient_checkpointing: true
optim: adamw_torch_fused
gradient_checkpointing_kwargs:
use_reentrant: true
learning_rate: 1.0e-4
lr_scheduler_type: cosine
warmup_ratio: 0.1
max_grad_norm: 0.3
bf16: {{ bf16_flag }}
bf16_full_eval: {{ bf16_flag }}
tf32: false
# ログ引数
logging_strategy: steps
logging_steps: 2
report_to:
- {{ reports_to }}
save_strategy: "epoch"
seed: 42
"""
config_filename = "openai-gpt-oss-20b-qlora.yaml"
recipe.yaml ファイルには以下の主要パラメータが含まれています:
-
モデル引数:
- model_name_or_path または tokenizer_name_or_path – ファインチューニングするベースモデルとトークナイザーのパスまたは識別子。モデルはディスクからローカルに読み込むか、Hugging Face Hub から読み込むことができます。
-
torch_dtype – トレーニング精度を設定します。
bfloat16は、より広い数値範囲でより良い安定性を提供する float16 レベルのメモリ節約を提供し、NVIDIA Ampere、Hopper、Grace Blackwell GPU でサポートされています。代替として、古いバージョンの NVIDIA GPU ではfloat16に設定します。 -
attn_implementation – より新しい Hopper GPU でサポートされている、より高速な注意計算のために vLLM FlashAttention 3 (
kernels-community/vllm-flash-attn3) カーネルを使用します。代替として、古い NVIDIA GPU ではeagerに設定します。
-
データセット引数:
- dataset_id_or_path – JSONL ファイルとしてのローカルデータセットの場所、またはデータセットの Hugging Face Hub ID。
-
max_seq_length – シーケンスあたりの最大トークン長(例:
2048)。より長い推論出力トークンを必要とするデータセットには、より長いシーケンス長を提供します。より長いシーケンス長はより多くの GPU メモリを消費します。
-
LoRA 引数:
-
use_peft – LoRA を使用した PEFT を有効にします。PEFT の場合は
true、フルファインチューニングの場合はfalseに設定します。 -
lora_target_modules – LoRA 適応のターゲットレイヤー(例:
all-linearレイヤーはほとんどの密およびMoEのデフォルト)。 - lora_modules_to_save – LoRA トレーニング中にフル精度で保持する GPT-OSS 固有のレイヤー。
- lora_r または lora_alpha – LoRA 更新のランクとスケーリングファクター。
-
use_peft – LoRA を使用した PEFT を有効にします。PEFT の場合は
-
ログと保存引数:
- report_to – 実験追跡統合(MLflow や TensorBoard など)。
レシピが定義されテストされた後、モデル名、データセット、エポック数、PEFT 設定などの構成をシームレスに交換し、最小限またはコード変更なしでファインチューニングワークフローを実行または再実行できます。
SageMaker エスティメータ
次のステップとして、SageMaker トレーニングジョブエスティメータを使用してトレーニングクラスターを起動し、モデルファインチューニングを実行します。SageMaker AI エスティメータ API は、完全管理されたインフラストラクチャでトレーニングジョブを定義および実行するための高レベル API を提供し、環境設定、スケーリング、アーティファクト管理を処理します。サーバーを手動でプロビジョニングすることなく、トレーニングスクリプト、入力データ、計算リソースを指定できます。SageMaker は、それぞれのフレームワークに最適化された事前構築済みの Hugging Face と PyTorch エスティメータも提供しており、最小限の設定でモデルをトレーニングおよびファインチューニングすることが簡単になります。
以下のパッケージがインストールされた Python 3.12 以上を使用して GPT-OSS をファインチューニングすることをお勧めします。スクリプトのルートディレクトリに requirements.txt ファイルを追加または更新してください。SageMaker エスティメータは、このファイルを自動的に検出し、実行時にリストされた依存関係をインストールします。
%%writefile code/requirements.txt
transformers>=4.55.0
kernels>=0.9.0
datasets==4.0.0
bitsandbytes==0.46.1
trl>=0.20.0
peft>=0.17.0
lighteval==0.10.0
hf-transfer==0.1.8
hf_xet
tensorboard
liger-kernel==0.6.1
deepspeed==0.17.4
lm-eval[api]==0.4.9
Pillow
mlflow
sagemaker-mlflow==0.1.0
triton
git+https://github.com/triton-lang/triton.git@main#subdirectory=python/triton_kernels
SageMaker エスティメータを定義し、ローカルトレーニングスクリプトディレクトリを指定します。SageMaker は内容をパッケージ化し、トレーニングコンテナ内の /opt/ml/code に配置します。これには、トレーニングスクリプト、ディレクトリ内の追加モジュール、および requirements.txt ファイルが存在する場合、SageMaker は実行時にリストされたパッケージを自動的にインストールします。
pytorch_estimator = PyTorch(
image_uri="763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.7.1-gpu-py312-cu128-ubuntu22.04-sagemaker",
entry_point="accelerate_sagemaker_train.sh", # SageMaker でアクセラレートを使用してトレーニングするための適応されたバッシュスクリプト - マルチ GPU
source_dir="code",
instance_type=training_instance_type,
instance_count=1, # マルチノードトレーニングサポート
base_job_name=f"{job_name}-pytorch",
role=role,
...
hyperparameters={
"num_process": NUM_GPUS, # インスタンスあたりの分散トレーニングを実行する GPU 数を定義
"config": f"recipes/{config_filename}",
}
)
SageMaker AI トレーニングジョブで GPT-OSS をファインチューニングするためのディレクトリ構造は以下の通りです:
code/
├── accelerate/ # Accelerate 構成ファイル
├── accelerate_sagemaker_train.sh # SageMaker トレーニングジョブでの Accelerate による分散トレーニング用起動スクリプト
├── gpt_oss_sft.py # GPT-OSS の教師ありファインチューニング (SFT) 用メイントレーニングスクリプト
├── recipes/ # 事前定義されたトレーニング構成レシピ (YAML)
└── requirements.txt # 実行時にインストールされる Python 依存関係
複数の GPU にわたってファインチューニングするために、Hugging Face Accelerate と DeepSpeed ZeRO-3 を使用します。これらは連携して大規模モデルをより効率的にトレーニングします。Hugging Face Accelerate は、デバイス配置、プロセス管理、混合精度設定を自動的に処理することで分散トレーニングの起動を簡素化します。DeepSpeed ZeRO-3 は、オプティマイザ状態、勾配、パラメータをデバイス間で分割することでメモリ使用量を削減し、数十億パラメータモデルがより高速に適合してトレーニングできるようにします。
以下のような簡単なコマンドで、Hugging Face Accelerate を使用して SFTTrainer スクリプトを実行できます:
accelerate launch \
--config_file accelerate/zero3.yaml \
--num_processes 8 gpt_oss_sft.py \
--config recipes/openai-gpt-oss-20b-qlora.yaml
SageMaker エスティメータを初期化する際に entry_point="accelerate_sagemaker_train.sh" を設定したため、SageMaker はトレーニングコンテナ内でこのコマンドを実行します。accelerate_sagemaker_train.sh スクリプトは以下のように定義されています:
#!/bin/bash
set -e
...
# Accelerate + DeepSpeed (Zero3) でファインチューニングを起動
accelerate launch \
--config_file accelerate/zero3.yaml \
--num_processes "$NUM_GPUS" \
gpt_oss_sft.py \
--config "$CONFIG_PATH"
PEFT vs フルファインチューニング
gpt_oss_sft.py スクリプトでは、use_peft を true または false に設定することで、PEFT とフルファインチューニングを選択できます。フルファインチューニングは、ベースモデルの重みに対するより大きな制御を提供し、より広い適応性と表現力を可能にします。しかし、破滅的忘却のリスクとトレーニングプロセス中のより高いリソース消費も伴います。
トレーニングの終了時には、完全に適応されたモデル重みが得られ、これを推論のために SageMaker エンドポイントにデプロイできます。その後、SageMaker Predictor を使用してデプロイされたエンドポイントに対して予測を実行できます。
結論
この投稿では、SageMaker AI で SageMaker トレーニングジョブ、Hugging Face TRL ライブラリ、および Hugging Face Accelerate と DeepSpeed ZeRO-3 による分散トレーニングを使用して、OpenAI の GPT-OSS モデル(gpt-oss-120b と gpt-oss-20b)をファインチューニングする方法を実演しました。SageMaker の完全管理された一時的なインフラストラクチャと TRL の合理化されたファインチューニングレシピを組み合わせることで、コスト効率的なカスタマイゼーションのための PEFT または最大限のモデル制御のためのフルファインチューニングのいずれかを使用して、GPT-OSS をドメインに迅速かつ効率的に適応させることができます。結果として得られるモデルアーティファクトを使用して、安全でスケーラブルな推論のために SageMaker エンドポイントにデプロイし、高度な推論機能を直接エンタープライズワークフローに導入できます。
さらに探求することに興味がある場合は、GitHub リポジトリ にこのウォークスルーで使用されたすべてのリソースが含まれています。これは、独自のデータセットで GPT-OSS のファインチューニングを実験し、結果として得られるモデルを実世界のアプリケーションのために SageMaker にデプロイするための優れた出発点です。SageMaker Studio ドメインクイックセットアップ を使用して数分でノートブックをセットアップし、すぐに実験を開始できます。
著者について

Pranav Murthy は AWS のシニア生成 AI データサイエンティストで、組織が Amazon SageMaker AI で生成 AI、深層学習、機械学習を使用してイノベーションを起こすことを支援することを専門としています。過去 10 年以上にわたって、彼はグローバルサプライチェーンの最適化からリアルタイム動画解析や多言語検索の実現まで、影響力の大きい問題に取り組むための高度なコンピュータビジョン (CV) と自然言語処理 (NLP) モデルを開発し、スケールしてきました。AI ソリューションを構築していないときは、Pranav はチェスなどの戦略ゲームをプレイしたり、新しい文化を発見するために旅行したり、意欲的な AI 実践者をメンタリングしたりすることを楽しんでいます。Pranav は LinkedIn で見つけることができます。

Sumedha Swamy は Amazon Web Services (AWS) のプロダクトマネジメントのシニアマネージャーで、機械学習の業界をリードする統合開発環境である SageMaker Studio、開発者および管理者エクスペリエンス、AI インフラストラクチャ、SageMaker SDK を含む Amazon SageMaker のいくつかの領域をリードしています。
リソース
ブログトピック
- Amazon Bedrock
- Amazon Comprehend
- Amazon Kendra
- Amazon Lex
- Amazon Polly
- Amazon Q
- Amazon Rekognition
- Amazon SageMaker
- Amazon Textract
フォロー
翻訳完了
この記事の翻訳が完了しました。Amazon SageMaker AI で Hugging Face ライブラリを使用して OpenAI GPT-OSS モデルをファインチューニングする包括的なガイドを日本語で提供しています。
主なポイント:
- GPT-OSS モデル(20B と 120B)の概要と仕様
- SageMaker AI での完全管理されたファインチューニング環境
- Hugging Face TRL、Accelerate、DeepSpeed ZeRO-3 を使用した分散トレーニング
- PEFT(LoRA)とフルファインチューニングの選択肢
- 多言語推論データセットでの実践的な例
- MLflow による実験追跡
- 本番デプロイメントへの道筋
この翻訳により、日本語話者が最新の GPT-OSS モデルを AWS 環境で効果的にファインチューニングするための詳細な手順を理解できるようになります。
Discussion