AWS 初心者がpythonを使ってリアルタイム文字起こし+感情分析をする
はじめに
こんにちは、toshiki です。
今回はAWSのサービスを使ってリアルタイムの文字起こし+テキスト感情分析を行ったので、その備忘録としてこの記事を書きました!
やったこと
1.マイクからの音声をリアルタイムで文字起こし
2.文字起こしされた内容をテキスト感情分析にかける
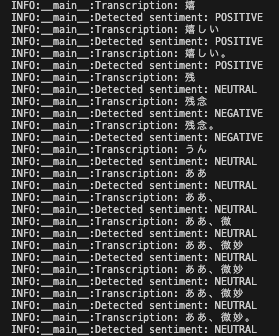
下記の写真みたいな文字起こしと感情分析ができます
対象読者
- AWS初心者の方
- とりあえず文字起こし+テキスト感情分析したい方
使用技術
Amazon Transcribe(文字起こし)
Amazon Transcribe は音声をテキストに変換してくれるサービスです。
Amazon Transcribe にはバッチ処理(音声ファイルのテキスト変換)とストリーミングの2種類ありますが、今回はマイクに喋った内容をリアルタイムで文字起こしをしたかったのでストリーミングを使用しました!
また、Amazon Transcribe では SDK、HTTP/2、WebSocket を利用して文字起こしできるのですが、今回は実装が他2つと比べて楽?らしいSDKを使いました!
Amazon Comprehend(感情分析)
Amazon Comprehend は機械学習を使った自然言語処理を行うサービスです。
キーワード抽出や固有名詞抽出とかもできるみたいですが、今回はテキスト感情分析(Sentiment)のみを使用しています!
Sentiment は以下4種類の感情をスコアリングして返してくれます。
- Positive
- Negative
- Mixed
- Neutral
また、Amazon Comprehend も AWS SDK for Python(Boto3)が用意されており、これを使用して楽に実装できます!
実装
Boto3を使う前に
Boto3を使う前にAWSの認証情報を設定する必要があります。下記リンクを参考にしてください。
実装コード
実装コード
import asyncio
import pyaudio
import boto3
import logging
from botocore.exceptions import ClientError
from amazon_transcribe.client import TranscribeStreamingClient
from amazon_transcribe.handlers import TranscriptResultStreamHandler
from amazon_transcribe.model import TranscriptEvent
# Configuration
SAMPLE_RATE = 16000
BYTES_PER_SAMPLE = 2
CHANNEL_NUMS = 1
CHUNK_SIZE = 1024 # 1KB chunks
REGION = "ap-northeast-1"
TRANSCRIPT_LANGUAGE_CODE = "ja-JP"
MEDIA_ENCODING = "pcm"
COMPREHEND_LANGUAGE_CODE = "ja"
# Setup logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class ComprehendDetect:
"""Handles sentiment detection using Amazon Comprehend."""
def __init__(self, comprehend_client):
self.comprehend_client = comprehend_client
def detect_sentiment(self, text, language_code):
try:
response = self.comprehend_client.detect_sentiment(
Text=text, LanguageCode=language_code
)
sentiment = response["Sentiment"]
logger.info("Detected sentiment: %s", sentiment)
return sentiment
except ClientError as error:
logger.error("Error detecting sentiment: %s", error)
raise
# Initialize Comprehend client
comp_detect = ComprehendDetect(boto3.client('comprehend', region_name=REGION))
class MyEventHandler(TranscriptResultStreamHandler):
"""Handles transcription events and performs sentiment analysis."""
def __init__(self, output_stream):
super().__init__(output_stream)
async def handle_transcript_event(self, transcript_event: TranscriptEvent):
"""Processes transcription event and detects sentiment."""
results = transcript_event.transcript.results
for result in results:
for alt in result.alternatives:
transcript_text = alt.transcript
logger.info("Transcription: %s", transcript_text)
self.analyze_sentiment(transcript_text)
def analyze_sentiment(self, text):
"""Performs sentiment analysis on transcribed text."""
comp_detect.detect_sentiment(text, COMPREHEND_LANGUAGE_CODE)
async def basic_transcribe():
"""Captures audio from microphone and sends it to Amazon Transcribe."""
client = TranscribeStreamingClient(region=REGION)
# Start transcription stream
stream = await client.start_stream_transcription(
language_code=TRANSCRIPT_LANGUAGE_CODE,
media_sample_rate_hz=SAMPLE_RATE,
media_encoding=MEDIA_ENCODING,
)
# PyAudio setup for live audio capture
p = pyaudio.PyAudio()
try:
audio_stream = p.open(format=pyaudio.paInt16,
channels=CHANNEL_NUMS,
rate=SAMPLE_RATE,
input=True,
frames_per_buffer=CHUNK_SIZE)
async def write_chunks():
"""Captures audio and sends it to Transcribe in chunks."""
try:
while True:
audio_data = audio_stream.read(CHUNK_SIZE, exception_on_overflow=False)
await stream.input_stream.send_audio_event(audio_chunk=audio_data)
except asyncio.CancelledError:
pass
finally:
await stream.input_stream.end_stream()
# Instantiate handler and start processing events
handler = MyEventHandler(stream.output_stream)
await asyncio.gather(write_chunks(), handler.handle_events())
finally:
# Ensure resources are cleaned up
if audio_stream:
audio_stream.stop_stream()
audio_stream.close()
p.terminate()
if __name__ == "__main__":
try:
asyncio.run(basic_transcribe())
except KeyboardInterrupt:
logger.info("Transcription stopped by user.")
かるーく説明
文字起こしについてはAWS SDK を使用した文字起こし内にあるストリーミング文字起こしのPythonコードを基本的には使っています。
しかし、このコードはaiofileライブラリを使用して音声ファイルの文字起こしを行うような実装になっているため、この部分をリアルタイム音声の文字起こしを行うように変更する必要があります。
そこで、今回はpyaudioライブラリを使用して、マイクからのリアルタイム音声をaudio_stream.read(CHUNK_SIZE)で読み取って、stream.input_stream.send_audio_event()で Amazon Transcribe に文字起こし処理を行わせています。
テキスト感情分析については、こちらのコードからdetect_sentiment()だけ引っこ抜いてきて、文字起こしされたテキスト引数に与えています。
まとめ
AWSや機械学習の知識がなくても簡単に作れたのでSDKには感謝ですね!
コードに関してはPython初心者なので変な実装をしていたらご指摘いただけますと幸いです!
Discussion
コメントありがとうございます!おそらくこちらのことですかね?使用してみようと思います!