Chat VectorでLLaVAを日本語対応させる
はじめに
「Chat Vectorを使って日本語LLMをチャットモデルに改造する」という記事を読んでLLMの重みを足し引きするだけで異なる言語のSFTモデルを作成できるの面白いなと思ったので試してみたという何番煎じか分からないChat Vector記事です。
LLMに対してはすでに多くの人が試されているようでしたので、本記事ではVLMであるLLaVAに対して試してみました。
作成したモデルは以下で公開しています。
Chat Vectorとは
Chat VectorはChat Vector: A Simple Approach to Equip LLMs with Instruction Following and Model Alignment in New Languagesで提案された手法で、以下の式で学習済みモデルの重みを演算することで英語以外の言語にSFTやRLHFを行うに等しい性能を与えることができるという手法です。
「英語のSFT/RLHFモデル」 - 「英語の事前学習済みモデル」 + 「他言語の継続事前学習済みモデル」 = 「他言語のSFT/RLHFモデル」
論文の以下の図が分かりやすいです。
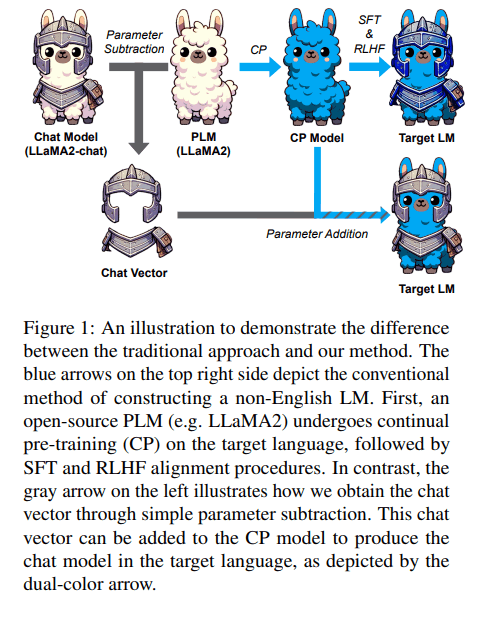
Chat Vector: A Simple Approach to Equip LLMs with Instruction Following and Model Alignment in New Languages, Huang, S. et al. (2023)
また、Chat Vectorで作成したモデルをその言語のデータセットで学習させることでさらに性能が向上するそうです。
Chat VectorでLLaVAを日本語対応させる
LLaVAは大きくVision Encoder、Vision Projector、LLMという3つの部品からできていますが、LLMの部分だけ上記のように重みを加減算します。
LLM以外の部分はLLaVAの重みをそのまま流用します。
今回使用するLLaVAの重みはliuhaotian/llava-v1.5-7bです。このモデルのベースのLLMはmeta-llama/Llama-2-7b-hfです。
日本語の継続事前学習済みモデルとしてLLaMA2をベースとしているものを使用する必要があるためelyza/ELYZA-japanese-Llama-2-7bを使用します。
以下に使用するモデルを整理しました。
| モデルの種類 | モデル名 |
|---|---|
| ① 英語事前学習済みモデル | meta-llama/Llama-2-7b-hf |
| ② ①を日本語で継続事前学習したモデル | elyza/ELYZA-japanese-Llama-2-7b |
| ③ ①をVLMとしてファインチューニングしたモデル | liuhaotian/llava-v1.5-7b |
重みを加減算して日本語LLaVAの重みを作成するコードは以下です。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
from llava.model.builder import load_pretrained_model
if __name__ == "__main__":
vlm_model_name = "liuhaotian/llava-v1.5-7b"
vlm_tokenizer, vlm_model, image_processor, context_len = load_pretrained_model(
model_path=vlm_model_name,
model_base=None,
model_name="llava-v1.5-7b",
load_bf16=True,
device_map="cpu",
device="cpu"
)
ja_model_name = "elyza/ELYZA-japanese-Llama-2-7b"
ja_tokenizer = AutoTokenizer.from_pretrained(ja_model_name)
ja_model = AutoModelForCausalLM.from_pretrained(ja_model_name, torch_dtype=torch.bfloat16, device_map="cpu")
eng_model_name = "meta-llama/Llama-2-7b-hf"
eng_tokenizer = AutoTokenizer.from_pretrained(eng_model_name)
eng_model = AutoModelForCausalLM.from_pretrained(eng_model_name, torch_dtype=torch.bfloat16, device_map="cpu")
if ja_tokenizer.vocab_size == eng_tokenizer.vocab_size:
# 除外対象
skip_layers = []
else:
exit(1)
for k, v in ja_model.state_dict().items():
if (k in skip_layers) or ("layernorm" in k):
continue
chat_vector = vlm_model.state_dict()[k] - eng_model.state_dict()[k]
new_v = v + chat_vector.to(v.device)
vlm_model.state_dict()[k].copy_(new_v)
new_model_name = "chat-vector-llava-v1.5-7b-ja"
vlm_model.save_pretrained(new_model_name)
vlm_tokenizer.save_pretrained(new_model_name)
実行するためにはLLaVAのリポジトリをcloneして以下のように配置してください。
.
├── llava
└── create_chat_vector_llava.py
評価
Chat Vectorで作成したモデルを評価するために以下のベンチマークで評価を行いました。
以下の表のchat-vector-llava-v1.5-7b-jaが今回作成したモデルです。
| Model | JA-VG-VQA-500 (ROUGE-L) |
JA-VLM-Bench-In-the-Wild (ROUGE-L) |
Heron-Bench(Detail) | Heron-Bench(Conv) | Heron-Bench(Complex) | Heron-Bench(Average) |
|---|---|---|---|---|---|---|
| Japanese Stable VLM | - | 40.50 | 25.15 | 51.23 | 37.84 | 38.07 |
| EvoVLM-JP-v1-7B | 19.70 | 51.25 | 50.31 | 44.42 | 40.47 | 45.07 |
| Heron BLIP Japanese StableLM Base 7B llava-620k | 14.51 | 33.26 | 49.09 | 41.51 | 45.72 | 45.44 |
| Heron GIT Japanese StableLM Base 7B | 15.18 | 37.82 | 42.77 | 54.20 | 43.53 | 46.83 |
| llava-jp-1.3b-v1.0-620k | 12.69 | 44.58 | 51.21 | 41.05 | 45.95 | 44.84 |
| llava-jp-1.3b-v1.1 | 13.33 | 44.40 | 50.00 | 51.83 | 48.98 | 50.39 |
| chat-vector-llava-v1.5-7b-ja | 18.64 | 42.23 | 53.61 | 44.36 | 44.48 | 46.10 |
全体的にどのベンチマークでも高い性能がでていて、Heron-Bench(Detail)は公開されている日本語VLMでトップの性能でした。
また出力結果を見ていると以下のような日本文化に関するタスクにも答えることができているのが印象的でした。

Question: このイラストが示す作品のあらすじを詳細に教えてください。
Answer : このイラストは、アニメーション映画「千と千尋の神隠し」からのものです。\n映画の中では、主人公の千尋が老婆に家に招待され、美味しい料理を食べながら話をするシーンが描かれています。\nこのイラストでは、老婆と千尋がテーブルに座って食事を楽しんでいる様子が描かれています。\nまた、映画に登場する他のキャラクターや背景もイラストに含まれており、作品の世界観を表現しています。

Question: 写真に写っている建物の名称はなんですか?
Answer : 写真に写っている建物の名称は「金閣寺」です。
まとめ
本記事ではChat Vectorを使用して英語で学習されていたLLaVAを日本語に対応させました。
Chat Vectorやその他のマージ手法を使用することで、英語のデータセットを日本語に翻訳して、学習させるという手間が必要なくなる可能性があるのはありがたいなと感じました。
今回は、自身の環境の都合でさらに日本語翻訳したデータセットで学習することで性能がさらに向上するかは確認できませんでした。そのうち試してみようと思います。
Discussion