クエリが期待通りレスポンスが出ないときの確認手順
そもそもクエリの発行について妥当かどうか?
データベースから情報を入手する処理が、妥当であることがまずは前提だと思います。仕様や要求に合わせての実装になると思います。クエリの最適化以前に妥当な実装になっているかの確認が必要だと思います。
-
頻度は妥当か?アプリケーション、システム側でキャッシュするべきなのに考慮せずに毎回実行しているなど
システム側でのキャッシュでカバーすべきなのに、毎回データベースに問い合わせを行うケースなど
例)ホテルの予約などをイメージすると、管理者側で1カ月の情報を閲覧するとき、予約者の氏名など含めた予約情報を取得するために、毎回氏名を取得hしている、利用者マスタを予約回数分取得のクエリが発行されるなどは、不適なケースだと思います。 -
条件が妥当か?
表示するのが1月分なので、1年分や、全部のデータを取得していないか?
例)ホテルの予約で、今日の予約の情報が必用なのに、一カ月対象でデータを取得しているなどので、不要な要求をデータベースに対して発行しているケース
上の2例はサンプルです。利用しているデータベースに合わせて最適な要件など整理して検討する必要があると思います。
クエリプランの入手
実行時に期待した速度にならない、クエリが判明したときには、妥当性確認の上、クエリが遅延している原因を確認する必要があります。テーブルデザインや、要件など考慮に入れて、最適なクエリかどうかの判断が必用で、クエリの実行が遅延の原因の時はクエリプランを確認することで、問題の確認できる可能性があります。
クエリプランを入手するには、発行しているクエリを特定して、推定プランの入手、実行プランの入手を行い、クエリプランが最適かどうかの判断を行うことが有用です。
以下クエリプランを入手済みの前提での問題把握、解決への手順になります。
どの処理でコストがかかっているかの確認
クエリプランをSSMSなどで開くと、クエリプランの中でどの処理にコストが掛かっているか判定できます。
想定外のIndexScan、TableScanなどの把握も可能です。

コストは※1、※2などでパーセントで確認可能。全体で100%なので上のQueryplanでは※1がコストかかっていることが確認できます。
期待したIndexを使えているか?
上記の通り、想定外のIndexScanなどはクエリのコストを想定以上に消費するケースがあります。
対策としては適切なIndexの追加を検討が有効です。SSMSのクエリプラン参照時に見える推奨Indexについては、今回プランを入手したクエリに対して、最適化するための提案です。テーブルの利用の仕方(どのようなセレクトが多いか)を考慮に入れて、最適なIndexを検討する必要があります。
また、IndexSeekになっているからといって、最適でないケースもあります。PredicateSeekでどのようにIndex検索するかが定時されているので、そちらが最適かどうか見るのも有効です。
- テーブル例(下部の「クエリテーブル作成データ作成」で作成)
- Index例(下部の「クエリIndex例」で作成)
クエリ例1
select
id ,kjsei , kjnam ,birth , postcode , prefecture , address
from dummy1_users
where birth = '20040101'
クエリプラン例1
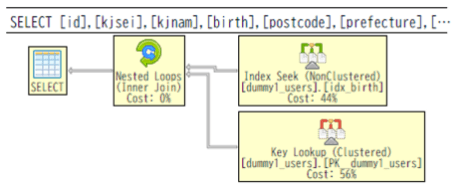
上記のクエリは、Index「idx_birth」が利用できていることが確認できるクエリです。
クエリ例2
select id ,knsei , knnam , prefecture ,address
from dummy1_users
where prefecture = '大阪府'
and address ='大阪府大阪市中央区上本町西 xxxxxxxx'
クエリプラン例2
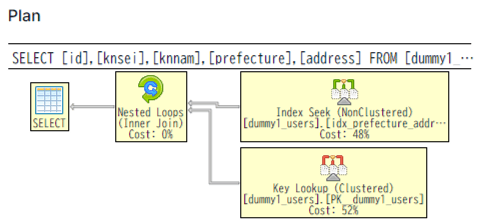
クエリ例3
select id ,knsei , knnam , prefecture ,address
from dummy1_users
where address ='大阪府大阪市中央区上本町西 xxxxxxxx'
クエリプラン例3
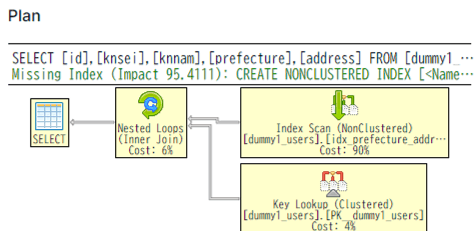
クエリ例2,3は一見どちらもクエリは期待通りIndex利用できている模様ですが、実際にクエリ3は「prefecture」列が指定できていないためIndexScanになっています。クエリ例2は「prefecture」が指定できているため、IndexScanでなくIndexSeekになっています。
一画面に、二つ並べて実行することで、各々のコストがどれくらいかかっているか確認可能。
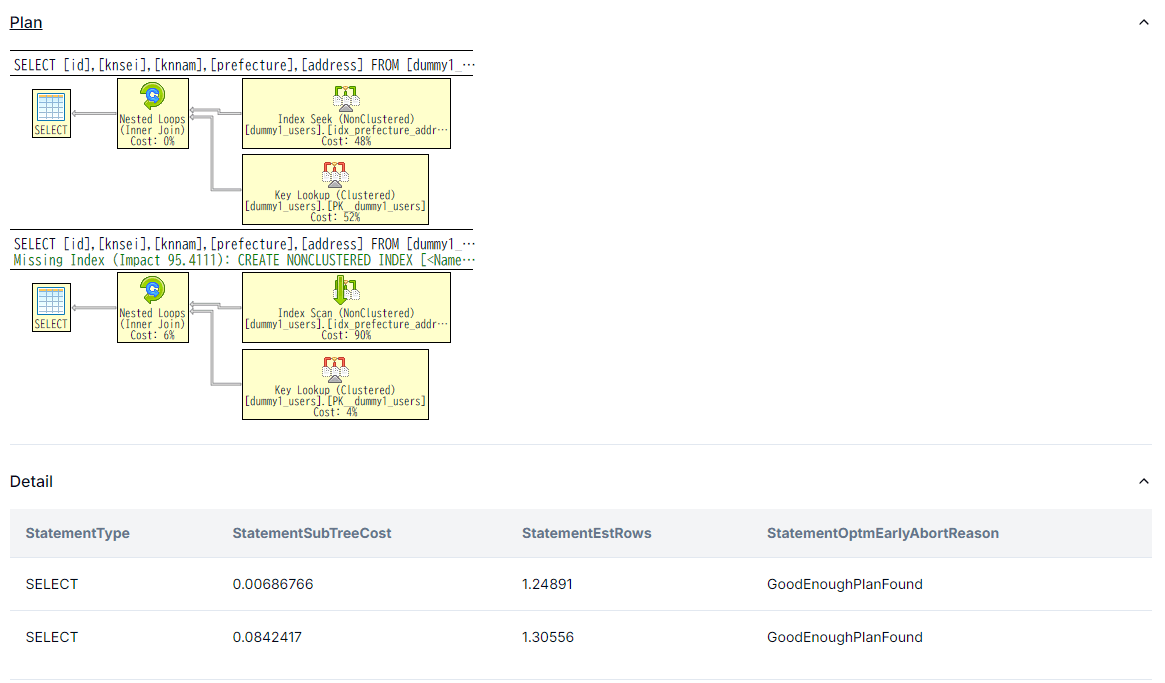
こちらでも確認可能(→ここ)
条件は最適だけど、最適なIndexが選ばれないケース
統計情報が古いケース
以下のクエリで統計情報更新日時の確認は可能性
-- o.name: テーブルの名前
-- s.name: 統計の名前
-- sp.last_updated: 統計情報が最後に更新された日時
SELECT
s.[name] AS StatisticsName,
sp.[last_updated] AS LastUpdated,
sp.[rows] AS [RowCount],
sp.rows_sampled AS RowsSampled,
sp.unfiltered_rows AS UnfilteredRows
FROM
sys.stats AS s
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) AS sp
WHERE
s.object_id = OBJECT_ID('dummy1_users');
統計情報は新しいが、最適なIndexが選ばれない。
キャッシュされたクエリプランが利用された可能性はあります。
統計情報更新で、プランは再評価され、期待してクエリプランが選択されるケースはあります。
統計情報更新のクエリは以下で実施可能。ただし、テーブルサイズによっては時間がかかるケースあり
UPDATE STATISTICS dummy1_users;
クエリプラン詳細の確認
-
並列処理が想定外に発生しサーバー、データベースが期待通り動かないケースがあります。
- サーバーのMaxDopを見直すか、クエリのオプションで、MaxDop 1 のクエリオプション付与で解決するケースもあります。
-
想定外のIndexが使われている。
- クエリ内のテーブルヒントで、インデックス指定することで、解決するケースがある。
- 統計情報が古いため、想定したプランが作成されないケースもある。その場合は手動で統計情報の更新が有効なケースあり
-
クエリ自体、クエリプラン自体問題ないが、クエリに対して結果の時間がかかる
- テーブル自体の断片化が高いため、クエリが物理的にDiskからデータを取り出すのに時間が掛かるケースはあります。
- 対象のテーブルに対して、REINDEXやRECONFIGURATIONなどで、テーブルの再構築、最構成を実行する
- ただし、上記処理中には該当テーブルに対して、ロックがかかるケースがありますので目的に応じての対応が最適だと思います。
-
補足
-
クエリプランなどについての説明は以下のサイト参考にさせていただいています。
SSMSでSQL Serverの実行計画を見てSQLチューニング -
MSのサイトの方がより充実しているが情報量が多すぎるので・・・
実際の実行プランの表示 -
クエリ・テーブル作成データ作成で使っている「postcode」は以下で作成
SQLServerへのCSVからのデータインポート(郵便番号データでの実例)
クエリ・テーブル作成データ作成
-
クエリ
use testdb --testdbで実行 -- テーブル作成 /****** Object: Table [dbo].[users] Script Date: 2024/09/07 10:54:43 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO -- drop table [dummy1_users] CREATE TABLE [dbo].[dummy1_users]( [id] [char](10) NOT NULL, [kjsei] [nvarchar](64) NULL, [kjnam] [nvarchar](64) NULL, [knsei] [nvarchar](64) NULL, [knnam] [nvarchar](64) NULL, [gender] [int] NULL, [birth] [nvarchar](8) NULL, [tel] [nvarchar](20) NULL, [portal_tel] [nvarchar](20) NULL, [postcode] [char](7) NULL, [prefecture] [nvarchar](10) NULL, [address] [nvarchar](100) NULL, CONSTRAINT [PK__dummy1_users] PRIMARY KEY CLUSTERED ( [id] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY] ) ON [PRIMARY] GO -- 一時テーブルを作成 CREATE TABLE #TempDummy1Users ( [id] CHAR(10), [kjsei] NVARCHAR(64), [kjnam] NVARCHAR(64), [knsei] NVARCHAR(64), [knnam] NVARCHAR(64), [birth] NVARCHAR(8), [gender] [int] , [tel] [nvarchar](20) , [portal_tel] [nvarchar](20) , [postcode] CHAR(7), [prefecture] NVARCHAR(10), [address] NVARCHAR(100) ); -- データ生成用のストアドプロシージャを作成 DECLARE @i INT = 1; DECLARE @startDate DATE = '1970-01-01'; DECLARE @endDate DATE = '2004-12-31'; DECLARE @range INT = DATEDIFF(DAY, @startDate, @endDate); WHILE @i <= 10000 -- 6分ぐらいかかる。 BEGIN -- ランダムなポストコードと都道府県を取得 DECLARE @randomPostcode CHAR(7); DECLARE @randomPrefecture NVARCHAR(10); DECLARE @randomCity NVARCHAR(MAX); DECLARE @randomAddress NVARCHAR(MAX); SELECT TOP 1 @randomPostcode = adrsubno, @randomPrefecture = prefecture_jpname, @randomCity = prefecture_jpname + locality_jpname + city_jpname FROM postcode where flg3=1 ORDER BY NEWID(); DECLARE @gender INT; DECLARE @random INT = ABS(CHECKSUM(NEWID())) % 10; -- 0 から 9 までのランダムな整数 SET @gender = CASE WHEN @random < 5 THEN 1 -- 「男性」 WHEN @random < 9 THEN 3 -- 「女性」 ELSE 9 END; INSERT INTO #TempDummy1Users ([id], [kjsei], [kjnam], [knsei], [knnam], [birth],[gender],[tel],[portal_tel], [postcode], [prefecture], [address]) VALUES ( RIGHT('0000000000' + CAST(@i AS VARCHAR(10)), 10), -- ID '姓' + CAST(@i AS NVARCHAR(10)), -- 姓 '名' + CAST(@i AS NVARCHAR(10)), -- 名 '姓' + CAST(@i AS NVARCHAR(10)), -- 姓 '名' + CAST(@i AS NVARCHAR(10)), -- 名 -- ランダムな生年月日を生成 FORMAT(DATEADD(DAY, ABS(CHECKSUM(NEWID()) % @range), @startDate), 'yyyyMMdd'), @gender, '06-6832-9999', -- tel '090-1903-9999', -- portal-tel @randomPostcode, -- 郵便番号 @randomPrefecture, -- 都道府県 @randomCity + ' xxxxxxxx' -- 住所 ); SET @i = @i + 1; END -- 一時テーブルの内容を確認 SELECT top(10) * FROM #TempDummy1Users; -- 一時テーブルから本テーブルにデータを移動 -- select * from dummy1_users INSERT INTO dbo.dummy1_users SELECT * FROM #TempDummy1Users; -- 一時テーブルを削除 DROP TABLE #TempDummy1Users;
クエリ・インデックス作成
-
クエリ
use testdb --testdbで実行 CREATE NONCLUSTERED INDEX idx_birth ON dbo.dummy1_users (birth); CREATE NONCLUSTERED INDEX idx_prefecture ON dbo.dummy1_users (prefecture); CREATE NONCLUSTERED INDEX idx_prefecture_birth ON dbo.dummy1_users (prefecture,birth); CREATE NONCLUSTERED INDEX idx_prefecture_address ON dbo.dummy1_users (prefecture,address);
Discussion