サーバを取り違えて再起動した話
この記事は、本番環境でやらかしちゃった人 Advent Calendar 2021の17日目の記事になります。
数年前にやらかした「障害対応中に冗長構成のサーバを取り違えて、二次障害を発生させた」件について懺悔しつつ振り返ることで、ヒューマンエラーに対する自分の考え方を共有したいと思います。
当時の業務
当時は複数のオンプレミスのシステムに対して、24時間体制で運用・保守を実施する部署に所属していました。
担当としては、システムの監視業務が主で、システムが発報したアラームを確認し、初期対応を行ってから開発部門にエスカレーションするまでを行っていました。
システムの概要
障害となったシステムは、デュープレックス構成[1]のサーバを備えており、クラスタ管理ソフトによって制御されていました。

システムの概要
障害発生前のサーバ状態はA系が待機系、B系が稼働系となっており、通常と逆の運用状態でした。
経緯
やらかした当日の自分の状態は以下のような感じでした。
- 夜勤で夕方から勤務に入り、数時間の仮眠をはさみながら翌朝まで業務を実施
- 自分は入社半年のエンジニアとしてベテランの先輩とペアで作業
このころは夜勤に慣れておらず、仮眠もあまり寝れなかったのでかなり意識が朦朧としている事が多かったです。
やらかしの詳細
空も明るくなり夜勤もあと数時間で終わりだと気が緩んでいたところ、複数のシステムが一斉にアラームしました。メンバーが散り散りになって対応に当たり、自分は上記のシステムを担当しました。
1. アラームの確認
アラーム内容をざっと確認したところ、サーバでアプリケーションが停止しアラームが発生しているようでした。
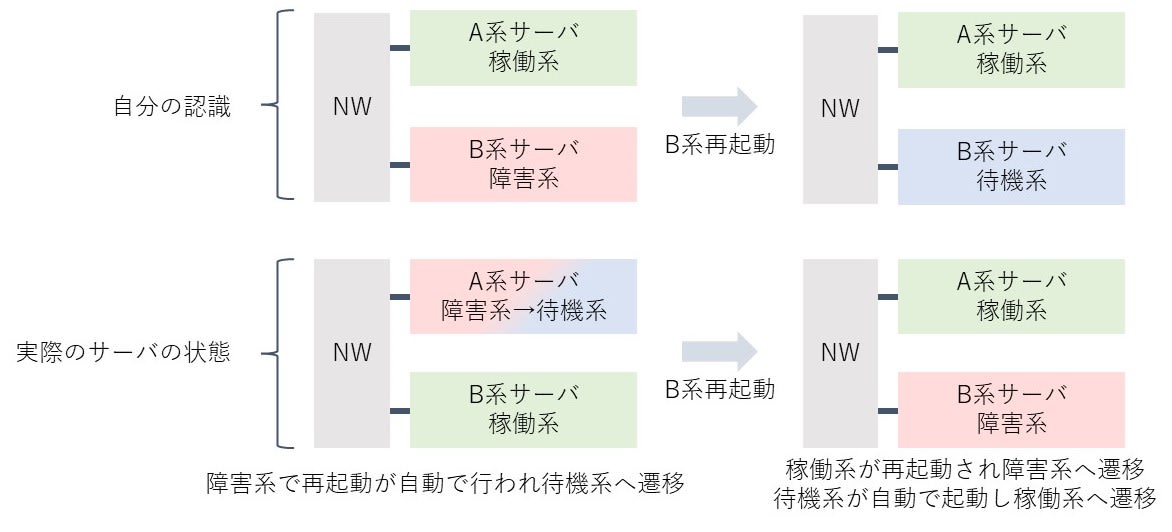
ここで監視ソフト上のアイコンでは、B系が赤色、A系が緑色だったため、アラームの詳細を確認せずにB系が障害中で、A系が稼働中であると判断しました。
そこで障害が発生したB系サーバを再起動することにしました。
2. 障害発生したサーバの再起動
障害中と認識していたB系を復旧させるために再起動コマンドを投入しました。
再起動が始まると、監視ソフトには多数の処理失敗を示すアラームが発生し、障害が両系へと波及して2次障害が発生しました。
ここで何か誤った操作をしたのではないかと思い、最初のアラーム内容を確認してみると、障害が発生したのはA系であり、再起動をかけたB系は稼働中だった事が発覚しました。
2次障害の影響を確認したところ、障害が発生したA系が自動で待機系として起動しており、B系を再起動した時に自動系切替で処理を継続していたため、ほとんど業務への影響はありませんでした。
障害の概況
ヒューマンエラーとヒューマンファクターの分析
上記のようなヒューマンエラーを起こした背景には、何かしらのヒューマンファクターが存在します。再発防止を図るためには、発生した事象であるヒューマンエラーを追及しても意味がなく、事象を生み出したヒューマンファクターを調べることが重要です。
M-SHELモデル
M-SHELモデル(Wikipedia)は、人と周りの環境の関係性からヒューマンファクターを整理した図の事です。

M-SHELモデル
| 略称 | 単語 | 意味 |
|---|---|---|
| m | Management | マネジメント、管理 |
| S | Software | マニュアル、作業標準 |
| H | Hardware | 装置、設備 |
| E | Environment | 作業環境 |
| L | Liveware | 人間、作業者(中央は当事者、周囲は関係者) |
M-SHELモデルに基づいて、ファクターとなる事項を分類すると以下のようになります。
分類するファクター自体は「なぜなぜ分析」や「VTA」などで分析することをお勧めします。
| 略称 | 該当事項 |
|---|---|
| Management | 非適切な疲労管理・人員管理 |
| Software | 障害対応時のマニュアル不備 (新システム移行直後で手順整理が追いついていなかった) |
| Hardware | 監視ソフトの不適切な設定 (障害発生時にステータスが更新されなかったり、正常時に異常ステータスを示すなど設定の不備) |
| Environment | 通常行わない作業 (障害対応) |
| Liveware | 身体状況 (夜勤明け)、精神状況 (障害対応に対する極度の緊張)、能力不足 (装置に対する知識不足・経験不足) |
この中で是正できるもの(マニュアル不備やソフト設定、能力不足)については、できる対応を取りました。また、是正が難しいもの(精神状況、作業特性)については、そういったヒューマンファクターが存在するという前提で、ほかの項目(Hardware:フェールプルーフ、Management:教育、Software:手順書)で対応を取りました。
また、自分の経験上、分析を実施する人の立場や経験によって結果が異なってきますので、当事者を含めて複数人で分析し、対応を検討することが望ましいと思います。
まとめ
ミスはどれだけ気を付けていてもなくなりませんが、ミスの原因を分析して学ぶことで再発や類似事象を防ぐことは可能です。本番環境でやらかしちゃった人 Advent Calendar 2021を読んだ方々が同じやらかしをしないための参考となれば幸いです。
-
デュープレックス構成とは、装置の信頼性を高めるために同じシステムを2系統用意して、通常は片側を運用し、もう片方を待機させておく方式。「アクティブ/スタンバイ構成」とも言われたりする。参考サイト:E-Words ↩︎
Discussion
すみません。記事を読んでもよく理解できませんでした。
本文とこの図はどのような関係なのでしょうか?

コメントいただきありがとうございます。
とてもお恥ずかしい話ですが、本文中の系が途中から間違っていました...
本文を図に合うように修正いたしましたので、お時間のある時にお読みください。