AMD RDNA 4のOut-of-Order Memoryとは何か?コード例で理解するGPU進化
はじめに
2025年登場のRDNA 4では Out-of-Order Memory が導入されました。この記事では、その挙動がどのようなものかを、架空のコードで解説します。私はRDNA 4のGPU(Radeon RX 9070 XT等)をもってないので実際に検証できていなく、こうなんじゃないか?、という話です。
1. 背景
RDNA 4の海外解説記事 [1][2][3]を読んでいたら"Out of Order Memory"の説明が目に止まりました。
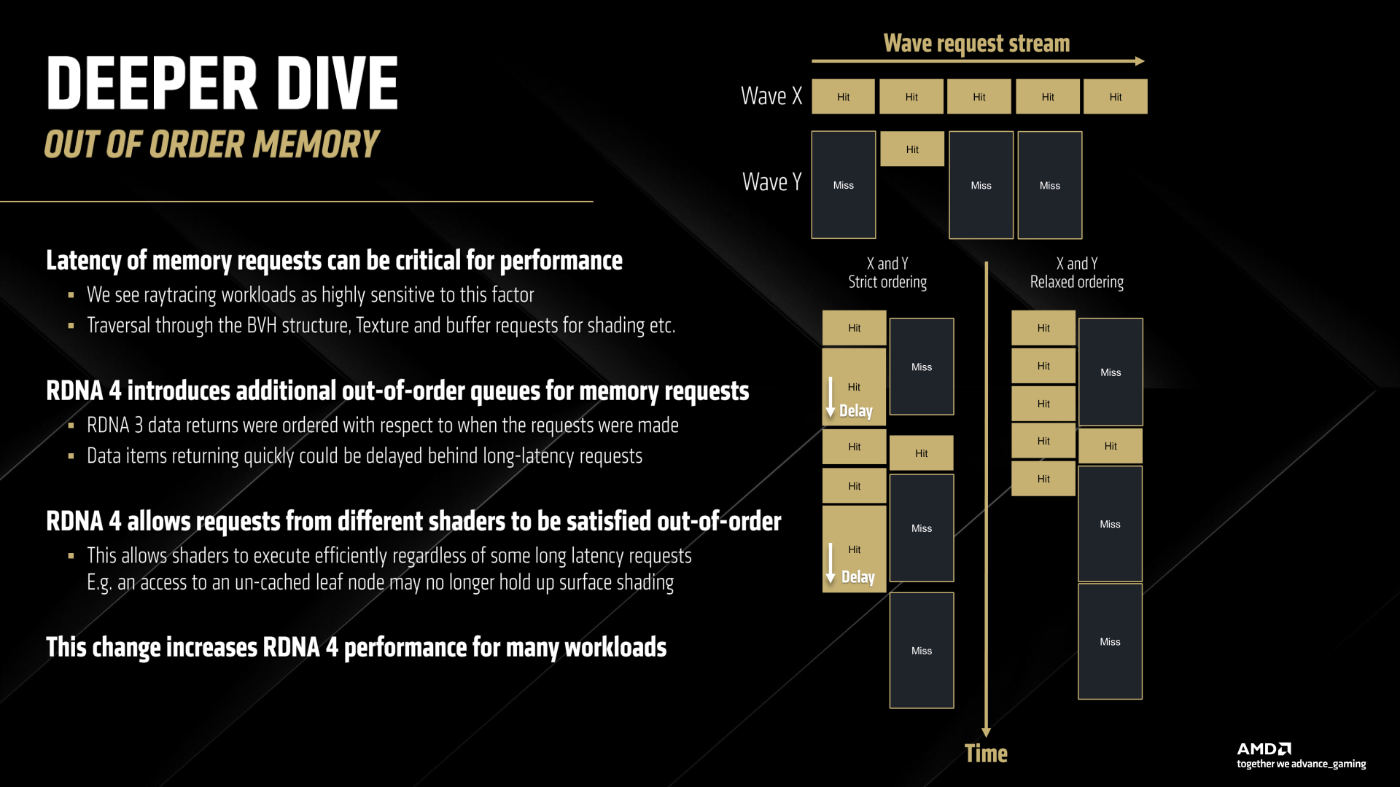
出典:「Better, more capable than expected: RDNA 4 architecture deep dive」、画像引用元: hwcooling.net
画像はAMDの公式資料に基づき引用されています
従来のGPU(特にRDNA 3以前)では、異なる Wave のメモリアクセスは返却順が強制的に In-Order となっていました。
その結果、キャッシュMissが1つ発生するだけで、後続のHit命令すら足止めされてしまう、という非効率が生じていました。上の図解の左側がその例ですが、Wave Xのメモリアクセスは完全にキャッシュにヒットしているのに関係ないWave Yが同じCU内でMissを起こしているとWave Xが足止めされてしまっています。
・・・いったいどういうことでしょうか?
2. コードで見る具体例
架空の計算コードでMissとHitが混在した状況を意図的に作り出しています。
// 128-thread = 2 wavefronts を 1CU に詰める想定
// Wave 0 (=X) : groupIndex 0-63
// Wave 1 (=Y) : groupIndex 64-127
[numthreads(128, 1, 1)]
void CSMain(uint3 DTid : SV_DispatchThreadID,
uint groupIndex : SV_GroupIndex)
{
// -----------------------------
// Wave 判定
// -----------------------------
uint waveID = groupIndex < 64 ? 0 : 1; // 0 → Wave X, 1 → Wave Y
uint laneID = groupIndex & 63; // 0-63
// -----------------------------
// ★ Wave X =キャッシュ Miss を強制 ★
// 遠いオフセットを付けて L2/L3 でも外れるように
// -----------------------------
if (waveID == 0)
{
uint index = (laneID * 8192u + DTid.x) % BigBufferLength;
volatile float sink = FarBuffer[index]; // (1) Miss 確定ロード
// sink を捨てれば OK(書き込み無し)
}
// -----------------------------
// ★ Wave Y =キャッシュ Hit を強制 ★
// 小さくて局所的な配列をアクセス
// -----------------------------
else
{
uint index = laneID; // 小さな範囲
float v = NearBuffer[index]; // (2) Hit ロード
OutBuf[index] = v * 2.0; // (3) 演算+書き込み
}
}
AMD RDNA 3
- 先に発行した Wave X の Miss が戻らない限り Wave Y の Hit を返せない(後述するがvmcnt由来のfalse dependency)
- Wave X が待つあいだ Wave Y の書き込みも保留 → Wave Y が足止め
AMD RDNA 4
- Hit の戻りは先に処理
- Wave Y は即座に完了
NVIDIA GPU
NVIDIA GPU(Turing以降)ではレジスタ単位のスコアボードで依存管理をしているようなので、(2)(3) を temp を待たずに先に実行 できます:
__global__ void Test(float* A, float* B, float* out)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
float temp = A[tid * 8192]; // (1) キャッシュMiss
float value = B[tid]; // (2) キャッシュHit
out[tid] = value * 2.0f; // (3) 計算
}
したがってSM内の別Warpに影響を及ぼすことは皆無といえます。
3. AMD GPUのWave内で起こっていること
「複数ロード → すぐ演算 → 必要なときだけ s_waitcnt」が基本動作
AMD GPUのGCN ~ RDNA 3 には4種類のメモリ・カウンタがあります[4]。
| カウンタ | 追跡対象命令例 |
|---|---|
VMcnt |
global_load, buffer_load, sample, 返値付き atomic |
VScnt |
各種ストア、返値なし atomic |
LGKMcnt |
LDS アクセス、SMEM(Scalar Load)など |
EXPCnt |
VS/VK 書き出し、パラメータ‐LDS など |
ロード発行時に対応カウンタが +1、データが VGPR に返って来た時に –1。Wave は s_waitcnt を実行して「カウンタ ≤ n になるまで待つ」まで、後続の ALU や別種メモリアクセスをどんどん発行できます。
; R0 = base pointer (SGPR)
; V0 = tid * 4
v_lshlrev_b32 v0, 2, v_tid ; 作業アドレス
global_load_dword v1, v0, s0 ; vmcnt = 1
v_add_u32 v2, vcc, v0, 64 ; 2 本目のアドレス
global_load_dword v3, v2, s0 ; vmcnt = 2
; ────────────── まだロード待たずに演算可能 ──────────────
v_mul_f32 v4, v_tid, 2.0 ; 完全に独立した計算
s_waitcnt vmcnt(1) ; 1 本目だけ完了待ち
v_add_f32 v5, v1, v4 ; ← v1 使用
s_waitcnt vmcnt(0) ; 2 本目も完了待ち
v_add_f32 v6, v3, v4 ; ← v3 使用
- ロード×2 を先に発行し、vmcnt が 2 になる
- 完全に独立した計算が実行されていく
- 値が本当に必要になる直前で s_waitcnt—そこで初めて Wave が stall
In-Order制約はWave間の問題だった
RDNA 3 以前でも同じWave内では複数のロードを投げて s_waitcnt vmcnt で任意のロード結果だけを待つ ― つまりWave内はもともとノンブロッキングでした。問題だったのは異なるWaveが同じ CU/WGP 内で共有していたメモリ要求キュー。このキューが「発行順でしか空けられない」ため、Missを起こしたWaveの後ろにHit Waveが並ぶと帰ってこられなかった、という挙動です。
RDNA 4では「Waveごとの OoO キュー追加」でこの偽依存(false dependency)を解消し、vmcntがWave専用に正しく減算されるため、Wave間の足止めが消えるようです。さらにRDNA 4でvmcnt系の細分化も行われ、Wave内ILPも改善しているようです[1:1]。
個人的な感想など
つまりAMDのGPUはRDNA 4でやっとNVIDIAの標準程度に追いついた、ということでしょうか・・。レイトレ実装したらランダムアクセスが増え性能劣化が目に余るようになったから、このようなハードウェア機構が今まで以上に求められたのだと思いました。
[1]の記事でも以下のように語られていました。
「誤ったクロスウェーブ依存関係の解決も目新しいものではありません。NvidiaはTuringで「アウトオブオーダー」クロスウェーブメモリアクセス処理を採用しており、おそらくはより新しいアーキテクチャにも採用されていると思われます。Intelも少なくとも第9世代(Skylake)グラフィックスの頃から同様の処理を採用していました。したがって、RDNA 4の「アウトオブオーダー」メモリサブシステムの強化は、画期的な新技術というよりも、世代的な調整と捉えるのが適切でしょう。」
- スコアボード周りの話は正直詳しくないので間違っていたら教えて下さい。
- 記事を書くにあたりとにかくChat GPTが頼りになりました。
参考文献
-
https://chipsandcheese.com/p/rdna-4s-out-of-order-memory-accesses ↩︎ ↩︎
-
https://www.coelacanth-dream.com/posts/2025/03/03/amd-rdna_4_rx-9070/ ↩︎
-
https://www.hwcooling.net/en/better-more-capable-than-expected-rdna-4-architecture-deep-dive/ ↩︎
-
https://www.amd.com/content/dam/amd/en/documents/radeon-tech-docs/instruction-set-architectures/rdna3-shader-instruction-set-architecture-feb-2023_0.pdf ↩︎
Discussion