React PlotlyとかJulia使って投資信託のダッシュボードを自作する
※クライアントサイドでTypeScriptを使っていたから,AWSにCDKTFでデプロイしようとしたけど,ECS周りの知識が無さすぎたのとお金の関係でJuliaの利用を諦めてrenderに無償枠でデプロイしたデモサイトがこちら
renderにデプロイする際にも色々壁にぶつかったのでそれを簡単な記事にします.近日.でも移植は朝5時に起きて,昼間箱根旅行して,帰ってきて0時半には完了していたから,割とスピーディーだったかも.ありがとうChatGPT
viteの利用やめてNextにしたり,配置変えたりと若干下のキャプチャとは違います.が本質的には同じです.詳しくは先にも書いたように別記事で
追々機能追加したり,セキュリティ面考慮したり,デプロイ方法インフラ周り,テスト考えたりって感じで,やらなきゃいけないことを端折ってかなり雑に作ってます.
簡単な背景
昨今投資信託が騒がれてますよね?
駅とか電車の広告で資産形成と整形と転職はよく見るジャンルな気がします.
春先は「なんで私が東大に?」と,よく煽られている気がしますw
それはさておき,自分も本格的に投資信託始めました.
ポイント投資は前からやっていて,ちまちまやっていたら1.25倍くらいになっていたので「ウェェェェェィwww」って感じでしたが,いざ本格的に現金入れ始めたらS&P500とオールカントリーが落ちまして損してますw
長期投資なので気にしちゃいけないんですけどね.
とはいえ,儲かれば嬉しいじゃないですか?
予測して当てたいじゃないですか?
ってことで可視化,分析したいと思いました.
やったこと
React Ploltyっていうのを使ってブラウザで可視化できるようにしました. 1人で可視化,分析するだけだったら,Jupyter Notebookでもよかったんですけどね.ちょうどJuliaも正式にColabで使えるとか聞きましたし.あとはSplunkとかみたいなソフトのダッシュボードを使うのもありだと思います.
でも,転職してReact使い始めていたこと,Juliaで使っているPlotlyがReactでも使えるとかいう謎の親近感でReact Plotlyを選定しました.
ただ,JavaScriptもTypeScriptもReactもNext(今回使ってないけど)もよくわからんのですw
あと,React Plotlyという名前ですが本質的にはplotly.jsらしいですね.
改めて使った主な技術
- フロント側:TypeScript,React(Plotly)
- バックエンド:Julia
- DB:PostgreSQL
- 他:Nginx
- 開発環境のインフラ:Docker compose
って感じです
投資信託のファンドの基準価額情報については,三菱UFJアセットマネジメントさんのAPIを使ってます.
LINK
あんまりAPIバンバン叩くのもよろしくないので,取得した情報は一旦DBに格納して,必要に応じてDBから吸い上げる構成にしました.
DBは記載の通りPostgreSQLです.この記事書いている時点では基本的なSQLしか書いていないので,PostgreSQLでなくても良かったです.サーバに直接JSONファイルで保存しても良かったレベル.使った理由を強いて言えば一応現職で使われているからですかね.
バックエンドはJuliaにしました.フロント側のコードからfetchされたらレスポンスを返すのと,コンテナ起動時に三菱UFJさんのAPIから価格情報取ってきて,テーブル作って格納したりしてます.
別にPythonでもよかったのですが,Julia使いたかったという理由でJuliaにしました.PythonでSQLAlchemyとFastAPI使えば,もう少しネットに情報とかも転がっていて容易に作れたり,ある程度安全に作れる気もしてますw
Juliaで使ったライブラリは主にJSON.jl,HTTP.jl,LibPQ.jlですね.
JSON.jlはJuliaプログラミング大全で紹介されていたり,ヘルプが比較的わかりやすかったのですが,HTTP.jlとLibPQ.jlはドキュメントとChatGPTと過去に使われてた方のブログを行き来しながらなんとか使ってました.
ChatGPTが教えてくれる内容が嘘だったり,ドキュメントの英語がいまいち理解できなかったり(LibPQはほぼドキュメントがなかった気が),過去に実施された方とやりたいことがズレていたり,過去の偉人の実装力に理解が追いつかなかったりでしたw
今後は解析していきたいので,そういう意味でもPythonの方が統計や機械学習ライブラリが揃っている気もしなくもないのですが,Juliaでも出来るんだぞいって意気込みでやっていこうと思いますw
Nginxはリバースプロキシです.フロント,バックエンド,Nginx,DBでコンテナを分割していて,ブラウザからfetchする際にクロスオリジン系のエラーを対応しなければいけず,それをしても良かったのですが(フロントエンドのセキュリティ本を途中までしか読んでないなかったことを思い出す),本気でデプロイする時もNginxを噛ませる気がするので.
Docker-composeを使ったことについては特に強い思いはないです.MacBookのローカル環境をあまりごちゃごちゃにしたくない気持ちからコンテナを使いました.
とはいえPackage.jsonやProject.tomlに関してはプロジェクトを分けていてもローカルにも同じパッケージの内容が入ってきています.それでもNginxやPostgreSQLはコンテナのみにインストールされているので…
実際のブツ
リーダーにブツを渡す簡単な仕事!
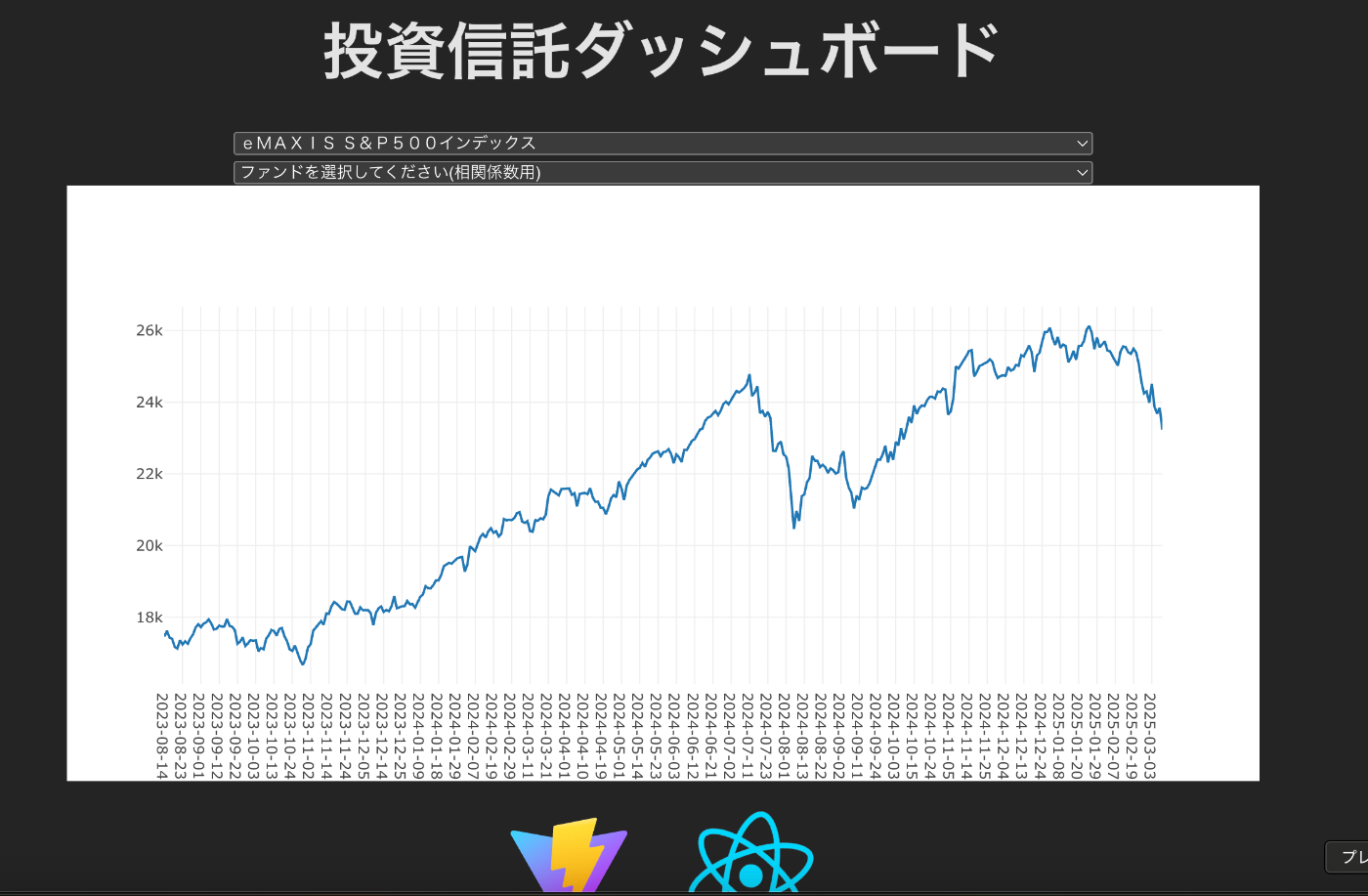
多分S&P500の時系列.一番古いデータの日時は,APIの仕様変更があったと記載があった直後で,実際はもっと古いデータも取得できる気はしてます…
ViteとReactのロゴは面白いから残したままです.一旦.
下の相関係数用の選択肢からファンドを選ぶと,時系列が出ているファンドの価格推移と過去30日分のデータで相関係数を求めます.もちろん過去30日のデータがある場合に限ります…
相関係数もただ原系列に対して実施ではなく,標準化して,差分系列に対して実施しています.
研究から離れて3年近く経ち,時系列解析について殆ど忘れてしまっているのですが,非定常な時系列に対して,そのまま解析はしないと思います.セオリー的に.(たまにニューラルネットにそれ含めて学習!みたいにブッこんでる人も見かけたことありますが).
標準化した時の相関係数と差分系列の相関係数の違いについてはペンと紙がないと真面目に考えられないです.やばいな.中学レベルの数学がががが.というか普通にJulia使って計算して比較してみればいいだけかw
ただ,上がったり下がったりの変動について個人的には知りたいので,差分系列にした方がいいのかなって気がしています.トレンドもほぼ消えますし.

オルカンとS&P500はどうやら強い相関があると思われる(因果じゃないよ!断定もしてないよ!)
相関係数だけ見て,自分のポートフォリオってやつを見直すのもありかもしれないですね.
自分の場合はオルカンとS&P500両方に入金して,両方下がっているのでw
もっと早く計算すれば良かったw
今後について
- renderでもAWSでもGCPでもいいから(今アカウントを持っていて候補になる)デプロイしていくことを考えます
- セキュリティとか何も考えていないので考えねば.今ならインジェクションもできちゃうかも?認証情報とかもお粗末だし,暗号化とか本番時のNW構成とかもなぁ…
- HTTP通信の勉強しながらもうちょいコード変えます.そういえばネスペ申し込んだのに参考書読んですらない
- jestよくわからん,juliaのテスト方法もいまいち.前にJuliaでGitHub Actionsいじってみたから,もっとちゃんと拡張したいですね…
- ログちゃんと吐き出さないと,今の時点でも結構きつい
- UIがな〜…CSS何もいじっていないし,今はファンドをselectタグで選んでいるけど,501以上あるから探すの大変…Reactのコンポーネントも駆使してグラフを見やすくしたいですね…
- もっとPlotlyのオプションでかっこよくしたい
- 予測しちゃうか?(周波数解析した感じ,確率論的な動きをしていて顕著な周期性はないように見えたかも)
- DBもインデックス作らなきゃね.そこまで今は遅くないけど
- Juliaの速さを追求するか…機械学習やるなら並列とかもこの際に使いこなしたいですね
- 普通に時系列解析系の本を読み直す(北川本とか経済・ファイナンスデータの計量時系列分析かな?)
Discussion