JuliaでRNNが完成しなかった話
お前は3年間何やってたんだ!?
このセリフ,浪人生同士の自虐?煽り?ネタで使ってましたね.元ネタはハイキュー!!です.
今回は B4,M1,M2 の3年間何やってたんだ[1]って状況に陥った話です.
具体的に言うと,JuliaのFluxを使って1番シンプルなRNNを作ろうとして四苦八苦した挙句未完成であるという話です.
ちなみにRNNはTensorflowを振り回して時系列の予測をしたことがある程度で,自然言語に利用したことはなく,ゼロD2巻も途中までしか進めてないです.すみません…
よくあるsin波の予測だけしました.ノイズなしです.
Fluxの仕様変更で古い内容になってそうです…
実行環境
Julia 1.8.1
JupyterLab
using Flux
using Plots
#using CUDA
GPUの利用についてはUdemyの講義を見たにもかかわらず,結局使いこなせなかったです…
function main(N,step,epoch)
#=最初に損失関数としてMSEを定義.
[end]指定しているのはRNNの最後の出力値だけを使用するseq-to-1を作りたかったため.
このやり方が正しいのかはわからないです=#
function Loss(x,y)
return sum(Flux.Losses.mse(model(x')[end],y))
end
model = Chain(RNN(1,60,tanh),Dense(60,1,identity))
y1 = sin.(Array{Float32}(range(0π,18π,N)))
#=学習データとテストデータに分ける(なんかもっとカッコイイ書き方あった気がしたけど愚直に)
今回は学習データを更に検証データに分けないです(面倒くさかったので)=#
hoge = Int(N*0.8)
y_train = y1[1:hoge]
y_test = y1[hoge+1:end]
Y1 = []
for i = 1:hoge-step
Y1 = push!(Y1,y_train[i:i+step-1])
end
#学習データにおける正解データ
Y2 = y_train[step+1:end]
data = zip(Y1,Y2)
#最適化するパラメータ(のはず…)
ps = Flux.params(model)
#とりあえずAdam
opt = Adam(1e-3)
#学習
for i = 1:epoch
Flux.reset!(model)
Flux.train!(Loss,ps,data,opt)
end
Y3 = []
for i = 1:N-hoge-step
Y3 = push!(Y3,y_test[i:i+step-1])
end
#テストデータにおける正解データ
Y4 = y_test[step+1:end]
#予測値を入れる配列
Y5 = []
#予測
for foo in Y3'
Y5 = push!(Y5,model(foo)[end])
end
#描画
plot(Y4,label="Original")
plot!(Y5,label="Predict")
end
#引数は左から全データ数,過去データ数,学習回数
@time main(1000,50,350)
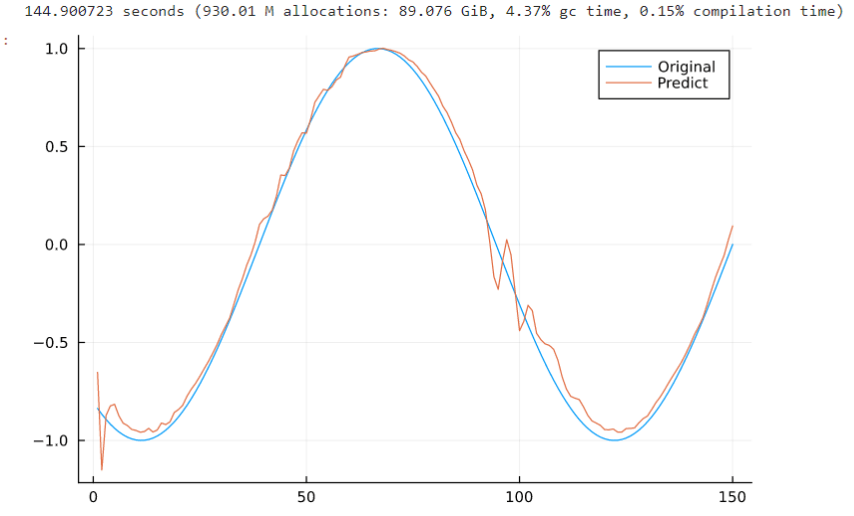
スクショですみません.
それにしてもなんか汚いですね.
人工的データなうえに,出力された予測値を次々と入力データに加えていく予測をしていないのですが…
ましてやノイズ混じりのsin波を学習させたわけではないんですけど…
ハイパラが悪いのか,やり方が間違っているのか…
※2024/1/8追記
純粋にパラメータ数が足りなかったようです.LSTMですが過去のステップ数×2くらいを中間層のニューロン数にしたらある程度きれいにできました.
改善点の一部
・研究でもないのでハイパラは気分で設定してます.過去データのステップ数により勾配が消失なりしているかもしれないです.今度しっかり設定します.
・損失関数の減少具合を可視化していないあたりも酷いものです.学習が十分なのか把握できません.今度やります.
・時系列の予測では,損失関数にも使ったMSE系統の指標や相関係数あたりを使い,精度の確認を定量的にすると思うんですがやってないです.今度やります.
・ミニバッチとか考えておらず,そのうえステートフルだと思いこんでいるけど本当にそうなっているのかわからないですね.今度調べます.
・ドロップアウト,正則化なんて考える余裕はなかったです.やり方調査含めて今度やります.
こんな感じでよくわからないまま,雰囲気でFluxが用意してくれている関数(train!やreset!)を振り回すだけでした.
Tensorflowを使っていた時もライブラリを振り回すだけだったんですけど,それでも予測できちゃうから,ここに来て改めてしっかり理解していないことを痛感しました.
MLPを読みTensorflow+Kerasのサイトで引数を確認しただけで,「完全に理解した状態」でしたね.
ということで,RNNは未完成のため,詳しい人がいらっしゃったら教えてください.
また気力がある時に英語のサイトを探せば何かわかるかもしれないので,進展があれば更新します.
参考にしたけど英語を正確に読めていないから結局参考に出来ていないサイト
-
B4の時は順伝播NNを作ったけどおまけコンテンツだったため卒論の付録にも入れず,M1~M2の時は講義含めて順伝播とSimpleRNN,LSTMを使ってはいた.ただしメインの手法に対する比較で入れたからTensorflow+Kerasで実装してみたに近い… ↩︎
Discussion