LLaDA:言語モデルの自己回帰モデルに代わる拡散モデルベースのアプローチとは
LLMは日々進化しており、chatgptやgeminiをはじめとしたモデルが私たちの生活に浸透しています。私は日頃エンジニアとして働いていますが、業務ではcopilotに支えられ、文章修正にはChatGPTを利用し、洗濯物のタグ(乾燥禁止とか)を読む際にはgeminiを使用しています。これらのLLMの多くは自己回帰モデルと呼ばれる、1度の推論で1つのトークンを予測し、予測されたトークンも含めて次の予測を行う逐次的な推論方法を基盤としています。しかし自己回帰モデルに変わる拡散モデルに基づいた新しいアプローチ「LLaDA(Large Language Diffusion Model)」が登場しました。
LLaDaとは何か?自己回帰モデルとの違い

LLaDAは従来の自己回帰モデルとは異なり、拡散モデルの考え方を応用しています。拡散モデルで重要となってくるのは、拡散過程(フォワードプロセス)と逆拡散過程(リバースプロセス)です。
フォワードプロセス
元のテキストデータ
リバースプロセス
マスクされた状態から開始し、徐々に元のテキストデータを復元していくプロセスです。このリバースプロセスは、マスクされたトークンを予測する「マスク予測モデル器」によってパラメータ化されます。
LLaDaはこのマスク予測器にTransformerアーキテクチャを利用しています。自己回帰モデルが過去のトークンのみを見て、次のトークンを予測する逐次的なバイアスを持つ一方、LLaDAのアプローチは双方向の依存関係を持つ出力分布を構築することを可能とします。よって、隣接トークンだけでなく、出力する文全体を考慮した出力が得られうる利点があります。
また、LLaDAは最尤推定の境界を最適化することで訓練され、確率推論のための原理に基づいた生成アプロートを提供します。この原理に基づいたアプローチは、LLaDAが従来の自己回帰モデルと同じようにin-context learningのような能力を持つ可能性を示唆しています。
性能
事前学習およびSFTされたLLaDAは、自己回帰モデルベースのモデル(1B)と比較して印象的な能力を示しています。
強力なスケーラビリティ

MMLU、ARC-C、CMMLU、PIQA、GSM8K、HumanEvalの6つのベンチマークにおいて、自己回帰モデルのベースラインと比較して、ベースラインを上回る結果が得られています。
特に、GSM8KでのFLOPSの指数増加に対して2乗スケールで精度が向上している点が印象的です。
In-Context-Learning

LLaDa 8Bは事前学習後のベンチマークにおいて、LLaMA3 8Bと比較して、中国語タスクや数学・理科の性能が良いことがわかりました。
Instruction Following
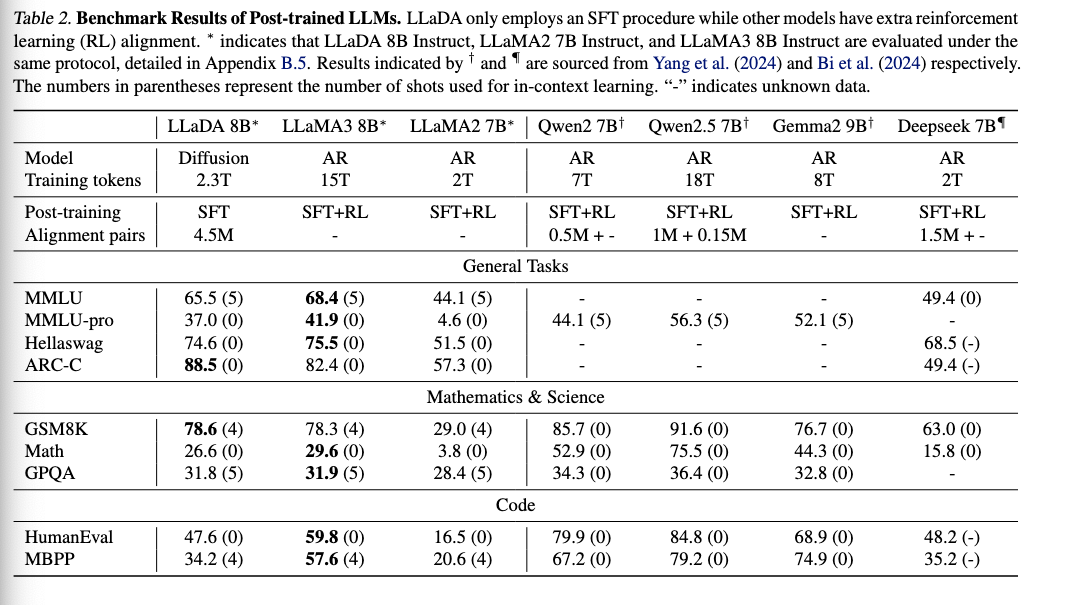
SFT後に、LLaDAはマルチターン対話などのベンチマークで、RLをした後のLLaMA3 8Bとコンペティティブな結果を得ています。ここでLLaDAはRLを未実施である状態なので、RLを適用して更なる精度向上を狙う研究も行う予定とのことです。
Reversal Reasoning

こちらの記事で解説されていますが、従来のLLMが「AはBである」という事実に基づいて訓練された場合、逆に「BはAである」と推測することができないという問題を抱えているという指摘があります。LLaDAでは、自己回帰モデルのもつ逆方向の推論が苦手な特性と克服していると主張しています。これは、LLaDAがトークンを均一に扱う帰納バイアスがないためだと言及されています。
LLaDA 8Bモデルは、2.3兆トークンで事前学習され、450万ペアのデータでSFTされています。H800GPU (H100の中国向けのもの)で0.03 million per hoursです。
結論
LLaDAでは、LLMの主流である自己回帰モデルに注目し、拡散モデルが大規模言語モデリングにおける実行可能かつ有望な代替手段であることを示しました。スケーラビリティとReversal Reasoningにおける結果は、今後のLLM研究に新しい道を開く可能性があります。まだ、強化学習によるアラインメントが未実施などの課題が残されていますが、LLaDAはLLMの可能性を広げる新たなアプローチといえます。直近ではGoogleがGemini Diffusionを発表して、その応答速度の速さが注目されていましたね。今後もdiffusion LLMに関する動向をウォッチしてきます。
Discussion