ローカルLLM向けのGUIアプリを作成した 2【会話編】
はじめに
- simple-text-generative-AIというローカルLLM(Large Langage Model)の初心者向けGUIアプリを作成しました。
- ローカルLLMとの基本的な会話やファインチューニングを誰でも行えるようにすることを目指しています。
- この記事では、前回の記事の続きで、simple-text-generative-AIによるローカルLLMとの会話までの使い方を説明します。
前回の記事
この記事では、simple-text-generative-AIの概要と導入方法をまとめています。
この記事を読んでほしい人
- ローカルLLMに興味がある人・初学者
- 気軽にローカルLLMとの会話を試してみたい人
できるようになること
- simple-text-generative-AIを用いたローカルLLMとの会話
- 異なるローカルLLMの性能・特徴比較
- モデルをロードするビットサイズが生成精度に与える影響比較
ローカルLLMとの会話方法
以降では、simple-text-generative-AIの使い方としてモデルの読み込みと会話までの流れを説明します。
使用環境
- Windows11
- GeForce RTX 3070 (メモリ8GB)
モデルの設定と読み込み
モデル設定のUIの全体画面は以下の通りです。基本的には、プルダウンやチェックボックス、ボタンに記載されている番号順に操作を行うとモデルの設定ができます。

- 使用するモデルのグループを選択します。今回は、試しに"line-corporation-instruction-model"を選択します。モデルによって適切なプロンプトが異なるため、この操作で自動的に決まります。
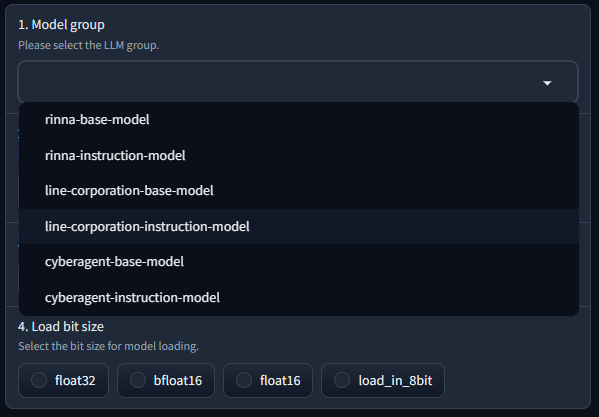
このプルダウンを設定した理由
ローカルLLMは、現在様々な企業や組織が開発し、公開しています。simple-text-generative-AIに登録しているモデルの数が多くなると、選択時のプルダウンが長くなります。そこで、モデルの整理を行うため、一旦このプルダウンを設定しました。モデルの検索機能のようなものです。
- 使用するモデルを選択します。
使用したい具体的なモデルを選択します。今回は、"line-corporation/japanese-large-lm-1.7b-instruction-sft"を選択しました。1で設定したグループに含まれるモデルのみがプルダウンで表示されるようにしています。
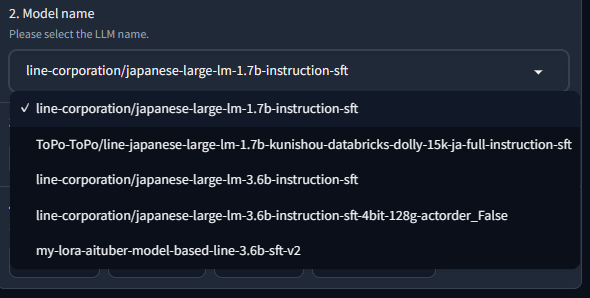
"line-corporation/japanese-large-lm-1.7b-instruction-sft"とは
- LINEヤフー株式会社(元LINE株式会社)が作成した日本語に特化したローカルLLMです。
- パラメータ数は1.7億パラメータであり、比較的小規模なモデルになります。パラメータ数が少ないため、必要なGPUメモリは少ないですが、生成精度があまり高くありません。
- Instruction Supervised Fine-Tuning(指示文付きの教師あり学習)を行ったものであり、入力された質問に対する回答を生成できます。
- 使用するプロセッサを選択します。文章の生成をGPUもしくはCPUの両方もしくはどちらかを使用するか設定します。今回は、"auto"を選択しました。特別な理由がない場合は、"auto"の使用を推奨します。
チェックボックスに表示される項目は、使用しているPCの環境に応じて自動的に設定されるようにしています。

"auto"とはどのような機能?
- 使用するPCの環境において使用するモデルが単一GPUに乗らない場合があります。
- その際に、LLMが効率的に動作するように、その他のGPUやCPUに自動でモデルのロードする重みを割り振ってくれる機能です。
- この機能を使用するためには、accelerateというパッケージが必要です。
GPUとCPUのどちらを使うべきか?
- 基本的には、GPUを使用してください。文章の生成が格段に早いです。
- モデルの容量が大きすぎるため、GPUだけでは、どうしてもメモリが足りない場合のみCPUの使用も選択肢に出てきます。
OSと使用できるプロセッサの関係
- WindowsとLinuxの場合は、GPUとしてCUDAが使用できます。CUDAの設定ができていない場合は、autoとCPUのみが表示されます。
- mac(Apple silicon)の場合は、GPUとしてCUDAの代わりにMPSが使用できます。
-
モデルをロードする際のビットサイズを選択します。今回は、float32を選択しました。使用するPCのメモリに余裕があれば、float32で良いですが、足りない場合は、bfloat16や8bit量子化を選択します。

-
全ての選択を行った後、モデルデータの送信ボタン(5. submit model data)をクリックし、設定を読み込ませます。初めてのモデルを使用する場合は、ダウンロードが行われるため、読み込みまでに時間がかかります。進捗は、ターミナルの方を確認してください。

-
右のテキストボックスに、ログとしてモデルの情報が表示されます。"Model loading is complete. Let's start a conversation."が表示され、モデルの読み込みが完了するまで待ちます。以下の画面は、読み込み完了後の状態です。

-
モデルの読み込みが完了しました。
ローカルLLMと会話する
-
上のchatbotタブを選択し、以下の画面に切り替えます。テキストボックスに質問を入力します。今回は、「有限要素法とは?」という質問をしました。

-
少し時間がかかりますが、質問に対する回答が自動で生成されます。回答の精度は、モデルごとに異なります。

-
いくつか質問を繰り返し、モデルと会話を行うことができます。
補足情報
- simple-text-generative-AIのgithub
- Instruction Tuningにより対話性能を向上させた3.6B日本語言語モデルを公開します
- 最近のLLMの学習法のまとめ - SFT・RLHF・RAG
まとめ
- simple-text-generative-AIを用いてローカルLLMとの会話を行うところまでのフローを説明しました。
- 他のモデルもすぐに使用できるため、モデルごとの性能比較といった検討ができます。自身の目的に合うモデルを選ぶことができます。
- モデルをロードする際のビットサイズのパラメータスタディも簡単にでき、ローカルLLMへの理解が深まると思います。
- ぜひ、様々なモデル、条件で試してみてください。また、開発へフィードバックさせますので、使用感など感想をいただけたら幸いです。
Discussion