2023前半kaggle参戦記
はじめに
今年開催された2つのテーブルコンペであるGoDaddy、PSPにて、それぞれソロ参加で銀メダル(152/3547位、49/2051位)を獲得し、Competitions Expertに昇格しました。この記事ではコンペで得られた知見や、自分がどのように戦ったかなどをまとめていきたいと思います。Expertを目指して頑張っている方や、機械学習コンペに興味を持っている方などの参考になれば幸いです。
目次
誰ですか?
はじめまして、tonicと申します。人生初記事投稿なので軽く自己紹介しようと思います。僕は普段フリーランスとしてデータサイエンティストやら機械学習エンジニアやらをやりつつ、kaggleのコンペに参加したり勉強したりといった生活をしています。kaggleでは主にテーブルコンペをやっています。今までいろんな方の有益な記事に支えられてきたので、自分も先輩方にならってアウトプットしていこうと思い立ちました。誰かのお役に立てたらいいな。
書くこと
- コンペ中の自分の立ち回り
- 公開情報(Discussion、Code、過去コンペ解法)の使い方
- 得られた知見
...etc
書かないこと
- 詳細な解法
コンペ概要
GoDaddy
GoDaddyの課題はMicrobusiness Density(中小企業密度、以下ターゲット)というホストが定義した指標の将来の値を予測するというものでした。この指標はアメリカの各郡ごとの単位人口当たりの中小企業数として計算されます。中小企業の数はWebのドメイン数で測っているようです。ターゲットは各郡ごと、月ごとに時系列で与えられており、下図のように群ごとの将来の推移を予測します。
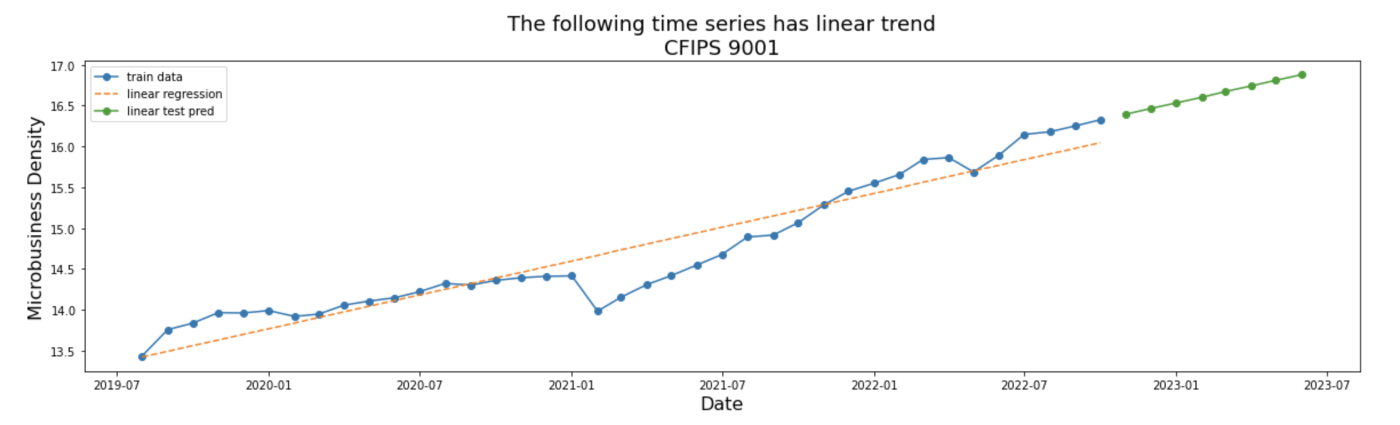
評価指標はSMAPEという珍しい指標でした。学習データの群数は3135、月数は41であり、130,000行程度の単変量データですので、リソースを気にせず手軽に参加できるコンペだったと思います。このコンペの特徴は外部データの利用が自由だったことであり、ホストも外部データを積極的に利用することを推奨していました。コンペのデータにはそのようなデータ活用の一助として、人口などの年次データが少しだけ含まれていました。また、時系列データを扱っているもののコードコンペではなく、コンペ終了後3ヶ月間の予測値を一気にcsvで提出する仕様でした。
時系列データを扱うコンペでは往々にしてPublicLBがあてにならず、最終的なPrivateLBも運ゲー感が否めませんが、本コンペも例外ではなく、1000位以上のshake downがあちこちで観測されていました(自分もPublic1289位→Private152位でした)。
開催期間は2022/12中旬~2023/03中旬であり、評価期間は2023/03~2023/05でした。僕は2月の頭から参戦したので、約1.5ヶ月間コミットしていました。
PSP
PSPの課題は小学生向けオンライン教育ゲームのプレイログから、ゲーム中で出題される問題に正解できるかどうかを予測するというものでした。どこをクリックした、誰と会話したといった情報が1行のログとして記録され、時系列で1ユーザ当たり数百~数千程度のログが与えられました。問題は全部で18問あり、出題されるタイミングまでのログを用いて正答/誤答を予測します。このような時系列性のため、本コンペはコードコンペでした。また、評価指標はmacro F1でした。学習データのユーザ数は23,000程度であり、(GoDaddyほどではありませんが)こちらもリソースをそこまで気にすることなく参加できるコンペだったと思います。
開催期間は2月頭~6月末まであり、僕は4月頭から参戦したので、約3ヶ月間戦ってました。途中でsubmit APIの仕様がコロコロ変わり、その度にAPIにバグが混入しPublicLBがバグり散らかし、阿鼻叫喚の中締め切りだけが伸びていくという忍耐が要求されるはっきり言ってクソコンペでした。
参戦前の筆者のスペック
元々機械学習を用いた金融市場予測に興味があり、個人的に細々と研究を続けていました。たまたま去年の4月にkaggleで日本株の値動き予測のコンペが開催されたので、そこでkaggleデビューしました。最終的にはまぐれで17位の銀でしたが、当時はエラーなくsubmitするので精いっぱいで、Discussionをじっくり読むなどといった余裕は全くありませんでした。
コンペに参加したのはこの1回だけだったので、GoDaddyはDiscussionやCodeの読み方もよくわからん、という状態からスタートしました。
参戦記
GoDaddy
序盤(~2週間)
DiscussionやCodeを全部読めというのはそこら中で聞いていたので、まずこれをやろうと思いました。さすがにすべては無理だったので、この時点でvote数が10以上のものにすべて目を通し、Notionにまとめていきました。コンペ後半からの参戦だったので、良質なベースラインや適切な前処理の方法など、リッチな情報がたくさん得られました。まわりの参加者は当然こういった良質な情報の上で戦っていますから、これらにくまなく目を通すのは基本中の基本なんだなと思いました。
一通り公開情報に目を通した段階で、思いついたアイディア一覧とその実装スケジュールをまとめました。前回できなかった実験管理を余裕を持ってちゃんとやろう、という意気込みです。ちなみにこれもNotionのデータベースでまとめました。もうNotionがないと生きられない。
↑こんな感じでスケジュールまとめてました。カレンダー表示もできるし、ほんと重宝してます。
この後はまずベースラインを作りました。ここではかなり時間をかけてパイプラインとして前処理、特徴量、モデルなどを分けて設計しましたが、これが非常に良かったです。のちの実験でどこを変更すればいいかが明快になり、実験管理が楽になりました。また、ローカルからkaggle APIを利用してsubmitまでできるようにしたため、kaggle notebookを使う必要なく、ローカルで実験が完了できるようになりました。なお、実験管理はmlflowを使っています。こちらもpythonライブラリがありますので、実験ごとに自動で記録していくことができます。
このとき作成したパイプラインは後述のPSPでも流用しており、githubで公開していますが、Readmeもなくただ公開しているだけという感じになってます。もしご要望がありそうなら他の方にも使ってもらえるよう整備しようかなと思っています。
中盤~終盤
一度立てたスケジュールに沿って実装、実験を行っていき、予定通りすべてのスケジュールを完了することができました。PublicLBに意味を見出していなかったので、ひたすらCVの改善を手元で頑張っていました。ちなみに、CVの分割方法としてはshuffle=Falseの通常のKFoldを用いています。つまり、時刻順にデータを並べて、それらを期間で均等に分割しました。これは時系列データで一般的に使われる手法ではなく、リークするのでは?と思った方もいらっしゃると思います。過去データをvalidationに持ってくるfoldがありますからね。この方法はsignateでJPXが主催していた金融市場予測コンペで1位の方が使っていた手法でした。各foldにおける評価指標の値に差がないのであれば影響はない、とおっしゃっていたので、今回試してみました。実際、過去データをvalidationにしたfoldの評価が良い、ということはなく、問題なく評価できました。
話がそれましたが、アイディアをスケジュール通り実装できたのは良かったものの、反省点が一つあります。それは一度立てたスケジュールを全く変えず、DiscussionやCodeも最初にまとめて見たあとは全く見なかったことです。もしかしたら新しい知見が共有されていたかもしれないですし、アイディアについてもどういったものが効果的かによって、方向性を柔軟に変えていくべきでした。
ともあれ、最終的にCVを信じ、Public1289位というクソ雑魚スコアで戦いを終えました。
最終的なモデルは以下のような感じです。ターゲットに関する前処理は公開ベースラインのものをそのまま使いました。
- Discussionで共有されていた外部データを利用し、ラグや移動平均など基本的な時系列特徴量を数百程度用意
- ターゲットを変化率に変換
- ターゲットの外れ値を平滑化
- 1D-CNNを、異なるラグで複数学習(3ヶ月先を予測するモデル、4ヶ月先を予測するモデル、など)
- モデルの出力をそれぞれ対応する月の予測値に割り当ててsubmit
結果
なんとPrivateでは1000位以上shakeし152位、銀圏でした。CVをひたすら信じ切ることの重要性を身をもって感じました。ただし、賞金圏内(~5位くらい)はあまりshakeしておらず、特に1位の方はPublicでも1位でした。これには驚きましたが、よくよく考えれば不思議なことでもないなと思いました。というのも、本コンペでは学習データが~2022/12、PublicLBが2023/01、PrivateLBが2023/02~2023/05でした。また、ターゲットを直接予測するのではなく、その変化率を予測して推論時に復元する、というやり方が主流になっていました。つまり、probingなどによって12月→1月の平均変化率にあたりが付けば、2月以降の予測値をうまく補正することができたのです。僕はPublicLBの精度は完全に無視していましたが、PublicLBを最適化することには構造上の意味があったということでした。これは大きな反省点でした。問題設計をくまなく理解することはそれを解くうえで最も重要な要素の一つです。今回の問題設計では、学習データ、Public、Privateに時間的な連続性があるということを理解し、Publicの情報も貪欲に用いるというのが重要な要素の一つでした。
また、問題を様々な視点から定式化する、というのも重要だと感じました。恐らく僕を含め多くの参加者は外部データを集め、特徴量エンジニアリング+GBDTという形を取っていたと思いますが、3位の方は単変量GRUをエレガントに使っていました。単変量時系列解析の視点からこの問題を解くということなど正直考えもしませんでした。頭が凝り固まっているのはよくないですね。もっと柔軟に問題を捉えていきたいと思います。
PSP
3月中旬にGoDaddyを終え満身創痍でしたが、面白そうなテーブルコンペがあったので戦いを決意しました。この時点ではGoDaddyのメダルが確定していなかったので、メダルに飢えていたんでしょうね…
序盤(~3週間)
いつも通り、CodeとDiscussionのサーベイから始めました。Discussionはほとんどすべてに目を通したのですが、前回と異なりCodeは目を通すものを絞りました。前回Codeを全部読んでいて思ったことなのですが、これに関しては結構質の差が激しいです。vote数上位であっても、ほとんど他のCodeのパクリであったり、中身のあまりないEDAもどきだったりします。なので、一旦流し読みして価値がありそうなものやscoreが高いものなどを中心にピックアップして読みました。これはこの方針で良かったと思います。
また、今回は過去の類似コンペの上位解法も調べました。特にRiiidコンペについてかなり調べました。やはり上位解法は知見の宝庫ですね。とても勉強になりましたし、流用できるアイディアもいくつか見つかりました。
サーベイが完了したら、ベースライン作りとアイディア、特徴量のブレストを行い、スケジュールを組み立てました。前回の反省を活かして柔軟に立ち回れるよう、アイディアの優先順位も大まかに決めておきました。また、ベースラインを作っていて、今更ではありますが分類タスクにおける評価指標の理解が深まりました。今までAUCやF1といった指標は知識だけはあったのですが、使いどころがよく分かっていませんでした。今回のコンペではAUC等閾値の必要ない指標を学習中のメトリクスにして、最終的なOOF予測値に対して閾値を最適化してCVスコアを計算していましたが、そういった使い分けがとても勉強になりました。
中盤(~締め切り3週間前)
今回のコンペでは、参加者のアプローチは大きくGBDTとNNに分かれており、両者ともにそれなりに強いベースラインが1つずつ公開されていました。ただ、多勢なのはやはりGBDTだったと思います。そこで僕は敢えてNNモデルにフォーカスして実験を重ねました。周りと同じことをしていては上位にいけないと思ったからです。公開ベースラインのスコアがどんどん上がっていく中で、ひたすら自分を信じて実験を重ねるのは大変でした。特に単独のNNモデルは僕の力ではそこまで強いスコアを出せず、苦しい思いをしました。しかし、後述しますが、アンサンブルではNNが本領を発揮し一気にスコアを押し上げることができたため、努力が報われる形となりました。
また、前回の反省を踏まえ、今回はコンペ中常にCodeとDiscussionを監視していました。Discussionはhotnessでソートして最初のページを毎日追っていましたが、それで十分だったように思います。CodeについてはPublicLBのbest scoreのものだけ追っていました。こうすることでコンペ中に新たに共有された知見を取り入れることができますし、それをもとに新しいアイディアが浮かぶこともあったので、これらには取り組む価値があったと思います。それに1日の更新量はそんなに多くないので、毎日追っていれば1日当たりの作業量はそれほど負担になりませんでした。
一方でコンペ自体は大荒れでした。本コンペではコードコンペのためSubmit用の時系列APIを利用する必要がありましたが、この仕様が幾度となく変更され、そのたびにバグを織り込んでLBがクラッシュしており、まさに地獄絵図でした。(テストぐらいなぜやれんのか?)
当然僕も原因不明のSubmit errorやCVとの異常な乖離に翻弄されました。kaggleのコードコンペはデバッグが本当に難しく、かなり精神がすり減ります。特に、デバッグ環境で渡されるテストデータのサンプルと、本番実行時のデータの構造が違うと本当に厳しいです。今回のコンペでも恐らくそういったデータがテストデータに紛れていました。この問題は結局最後まで解決せず、無理やりtry catchで無視するほかありませんでした。ここで一気に体力と気力を持っていかれ、本当に脱落寸前といった感じでした。
終盤(締め切り3週間前~)
それでも何とか自分を奮い立たせ、終盤はアンサンブルに取り組んでいました。GBDTの公開ベースラインに少し特徴量を加えたものとNNのアンサンブルが非常にうまくいき、スコアを一気に伸ばすことができました。アンサンブルでは単純平均の他、スタッキングに初めて挑戦しました。スタッキングの実装はスコア向上に寄与しただけでなく、OOF特徴量について深く理解できたので非常に良かったです。また、スタッキング2段目のモデルはGBDTではなく線形モデルの方が精度が良く、単純なモデルにも使いどころがあることがわかり勉強になりました。一方GBDTについてもかなり知見が得られました。最終的に僕が使っていた特徴量は2,000程度で、特徴量選択はせずすべて突っ込んだ方が精度が良かったです。データ数は23,000程度だったので、その1/10も特徴量を作って良いというのは驚きでした。機械的に作っている特徴量が大半だったので意味のない特徴量が結構混じるだろうと思っていたのですが、わずかなシグナルでもちゃんと拾ってくれるんですかね。GBDTはノイズ特徴量に影響を受けにくいことは知っていましたが、まさかここまでとは思いませんでした。何事も経験ですね。
また、最後まで手元のCVを信じ切るのもかなり精神力が必要でした。終盤にかけて公開NotebookのPublicLBはどんどん上がっていき、最終的に自分の最終提出モデルより高いスコアだったからです。これらはCVによる精度検証を行っておらず、ひたすらPublicLBにオーバーフィットしている感じでした。実際に手元でCVを実装してみましたが、やはり精度は大幅に劣化していました。しかし、それが分かっていても公開ベースラインをコピーした他の参加者にどんどん抜かれていくのは精神衛生上よくないです。最終的にPrivateではこれらの参加者は大幅にshake downすることになり、僕の忍耐は報われることになります。
結果
前述の通り、とにかくCVを信じていたため、PublicLBは258位と銅メダルすら余裕で圏外でしたが、Privateでは49位まで浮上し銀メダルでした。ここまで上がるとは思っていなかったので、本当に嬉しかったです。今まで時系列データのコンペしか経験がなかったため、そもそもPublicLBが機能しているコンペに出たのは初めてだったのですが、それでも手元で信頼できるCVを構築することの重要性を再認識することになりました。ただ、やはりPublicで金圏にいた方々はあまりshakeしておらず、そもそも手元でもLBでも強い人は強いということがわかりました…。まだまだつよつよな方々には遠く及びませんね。
しかし、同時に確実に力が付いてきていることも認識できました。上位解法を見ていると自分の解法同様GBDT+NNというアプローチが大半で、細かい解法についても理解できないものはほぼなく、自分で思いついていたものもありました。上位解法が呪文のように思えて全く理解できなかったころからすれば大きな大きな成長です。金はもはや全く手の届かない存在ではなくなっているのかもしれない…そう思える嬉しい気付きでした。
なお、解法は49th Place SolutionとしてkaggleのDiscussionにまとめています。LightGBMと1DCNN+Transformer Encoderの線形モデルによるスタッキングです。正直上位の方々の解法の方が明らかに有益ですが、もし気になる方がいればご覧ください。
金を取るために
さて、銀メダルが2枚以上になったので、あと金を一枚取れれば人生の目標の一つであるMasterになれます。さすがに疲弊したので8月いっぱいくらいはゆっくり休もうかと思っていますが、金を取るために何が足りていないか、何をすればよいかについての今のところの仮説をまとめておきたいと思います。
- チームを組む
今まではチームを組むのがなんとなく怖くて避けてきましたが、正直今の実力ではソロ金なんて夢のまた夢です。明らかにチームを組んだ方がMasterへの近道になるはずです。では、チームを組むためにはどうすればいいでしょうか? - 序盤からフルコミットしてPublic上位に上がり、チームマージの機会を得やすくする
今までは公開情報がある程度溜まって、それを利用できる後半から参戦する形を取っていました。その方が問題を理解する効率は上がりますし、ベースラインとなる解法も大体公開されているため、それを加工する形で戦えばよいのでやりやすいです。ただし、僕に短期間で上位に上がれるほどの実力がないことを考えると、それに甘えているようでは永遠に金にはたどり着けない気がします。一方で情報の少ない序盤では自身で解法を切り開いていく力が求められますが、そこで人の少ない早期のうちにある程度上位に食い込み、情報発信も積極的に行っていくことで、チームマージしてもらえる機会を得やすくなるのではないかと思っています。そうでなくても、自分で考えて解法を1から作っていく作業自体が確実に力になるはずなので、挑戦する価値は大いにあると思います。 - probingをちゃんとやる
probingについてはなんとなくいい気分がしないので避けていましたが、上位陣に食い込むにはどうしても必要ですね…。これに関してはコンペ以外で役に立つスキルとは言えませんが、分析対象を徹底的に理解するためにすべてのことをやり尽くす姿勢自体は、そこまで忌避しなくても良いのではないかと考えるようになりました。 - データをもっとよく見る
EDAにはどうしても苦手意識があり、公開Notebookに毛が生えた程度のことしかできずにいますが、ここは徹底的に鍛えるべきポイントだと思います。データをくまなく理解することでしか精度向上はあり得ませんから、もっともっと練習していきたいと思います。
まとめ
今までいろんな方の有益な発信にお世話になった分、自分もアウトプットして還元したいとずっと思っていましたが、ようやく最初の記事を書き切ることができました。この記事がほんの少しでも誰かのお役に立てればいいなと思っています。これからも少しづつ発信を続けていきたいと思っています。そういえばPSPのホストが数ヶ月後に次なるコンペを開催するとアナウンスしていますので、次はそこで戦おうかなと思っています。チーム組んでくれる方がいらっしゃればぜひ一緒に戦いましょう!
Discussion