激安高性能LLMのDeepseek V3を実装してみる
1. はじめに

DeepSeekが2024年12月に発表した大規模言語モデル「DeepSeek-V3」について、実際に使ってみた経験をベースに共有したいと思います。
このモデルの主な特徴として、671Bパラメータを持つMoEモデル(実際にアクティブなのは37Bパラメータ)で、14.8Tトークンでの事前学習を行い、生成速度も従来の3倍(60トークン/秒)になっています。また、OpenAI互換のAPI形式を採用しているのが大きな特徴です。
個人的に使ってみて特に印象的だったのは、激安なのにGPT-4やClaude-3.5-Sonnetと同等の性能を持っているということです。具体的には以下の分野で優れた性能を示していました。
- 知識:Claude-3.5-Sonnetと同じくらいの知識ベース
- 長文処理:DROP、FRAMES、LongBench v2などでかなり良い性能
- コーディング:アルゴリズム問題での高い精度
- 数学:米国数学競技会(AIME 2024, MATH)での優位性
- 中国語:教育系評価やC-SimpleQAで高いスコア
DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。(https://api-docs.deepseek.com/zh-cn/news/news1226)
実装面では、OpenAIのSDKを使ってラッピングできるので、既存のコードを流用できて負担が少ないのが魅力でした。特に、既存のAIアプリケーションで精度とスピードが求められるケースでは、かなり使い勝手が良いと感じています。
ただし、いくつか注意点もあります。特にプライバシーポリシーについては、中国のAIモデルということもあってか、データ保持や廃棄に関する記載が見当たらず、プロダクションでの使用を検討する際は顧客説明が必要な場合は慎重な判断が必要だと思いました。おそらく中国側の規制の問題がありそうです。
この記事では、実際の実装経験を踏まえて、DeepSeek-V3の特徴、利点、注意点について詳しく解説していきます。特に、既存のOpenAIベースのアプリケーションからの移行を考えている開発者の方々に役立つ情報を提供できればと思います。
ここからは、より具体的な技術的特徴と実装方法について見ていきましょう。
*DeepSeekの企業戦略の分析はこちらの記事をぜひご参考ください。
2. DeepSeek V3の概要と特徴
DeepSeek V3は2024年12月にリリースされた最新の大規模言語モデルです。使ってみた経験から、特に技術面での特徴をいくつか挙げていきたいと思います。
2.1 モデル構造と性能
ポイントとしては、モデルアーキテクチャは671Bパラメータを持つMoEモデルで、実際にアクティブなのは37Bパラメータです。14.8Tトークンで事前学習を行っているみたいです。
生成速度が従来の20TPSから60TPSまで大幅に向上していて、V2.5モデルと比べて3倍速くなっていました。実際に使ってみても、レスポンスの速さは体感できました。
DeepSeek-V3は自研MoEモデルで、671Bパラメータ、激活37B、在14.8T tokenで進行了預訓練。(https://api-docs.deepseek.com/zh-cn/news/news1226)
通过算法和工程上的创新,DeepSeek-V3的生成吐字速度从20 TPS大幅提高至60 TPS,相比V2.5模型实现了3倍的提升。(https://api-docs.deepseek.com/zh-cn/news/news1226)
2.2 主な性能指標
GPT-4やClaude-3.5-Sonnetと比較しても遜色のない性能を示していて、特に以下の分野で印象的でした。
-
知識ベース面:
- Claude-3.5-Sonnetと同等レベルの知識量
- MMLU、MMLU-Pro、GPQAなどの知識タスクでかなり良い成績
-
長文処理:
- DROP、FRAMES、LongBench v2でかなりいい感じのパフォーマンス
- コンテキストウィンドウは64Kトークンまでサポート(ただし、これはそこまで高くないので注意が必要です)
-
コーディング:
- アルゴリズム系のコードタスク(Codeforces)で、非o1系のモデルの中ではトップクラスの性能
DeepSeek-V3在算法类代码场景(Codeforces),远远领先于市面上已有的全部非o1类模型。(https://api-docs.deepseek.com/zh-cn/news/news1226)
-
数学:
- AIME 2024や全国高校数学コンテストで高いスコア
- 数学関係の問題も結構うまく解けています
2.3 技術的な特徴
気になった点をいくつか挙げると、
-
FP8トレーニング:
- FP8訓練を採用していて、原生のFP8ウェイトもオープンソースで提供されています
- SGLangやLMDeployでFP8推論がサポートされている
DeepSeek-V3採用FP8訓練,並開源了原生FP8権重。(https://api-docs.deepseek.com/zh-cn/news/news1226)
-
デプロイメントオプション:
- TensorRT-LLMとMindIEでBF16推論の実装
- FP8からBF16への変換スクリプトも提供されているので、必要に応じて使い分けられます
-
オープンソース:
- Hugging Faceでモデルウェイトが公開されています
- コミュニティのサポートも活発で、実装時に困ったことがあれば結構すぐに解決策が見つかりそう
"以開源精神和長期主義追求普惠AGI"是DeepSeekの一貫した信念。(https://api-docs.deepseek.com/zh-cn/news/news1226)
実際に使ってみて、商用利用からリサーチまで幅広く使えそうな印象を受けました。ただし、プロダクションでの利用を考える場合は、プライバシーポリシーやレートリミットなど、いくつか注意点もあるので、それらについては後のセクションで詳しく触れていきたいと思います。
3. 実装の容易さ
DeepSeek V3の一番の魅力は、個人的にはOpenAI互換のAPI形式を採用していることだと思います。使ってみた感想としては、既存のOpenAIベースのアプリケーションからの移行がすごく楽でした。
DeepSeek APIはOpenAIと互換性のあるAPI形式を使用しており、設定を変更するだけでOpenAI SDKを使用してDeepSeek APIにアクセスしたり、OpenAI APIと互換性のあるソフトウェアを使用したりすることができます。(https://api-docs.deepseek.com/)
3.1 OpenAI SDKとの互換性
基本的な設定はこんな感じです:
from openai import OpenAI
client = OpenAI(
api_key="your-api-key",
base_url="https://api.deepseek.com/v1" # OpenAI互換エンドポイント
)
これだけで、既存のコードを流用する形で自走できるので、そこまで実装の負担を感じませんでした。
3.2 主要な機能のサポート状況
実装してみて気づいた主な機能のサポート状況を共有すると、
-
Chat Completion API
普通のチャット形式での対話は問題なく動きます。ストリーミング出力もサポートされているので、既存のOpenAIベースのアプリと同じような使い勝手です。 -
JSONモード出力
ただし、ここで注意が必要なのが、DeepSeek V3にはstructured outputがないんですよね。なので、代わりにJSONモードで出力する必要があります。"type": "json_object"を指定することで実現可能です。
response = client.chat.completions.create(
model="deepseek-chat",
response_format={"type": "json_object"},
messages=[{"role": "user", "content": "JSONで出力してください"}]
)
-
System prompt
DeepSeek Chatでは問題になりませんが、DeepSeek Reasonerを実装する場合は、System promptは受けられないため、メッセージの先頭に入れる工夫が必要です。送信前後で、R1モデルかどうかでシステムプロンプトの位置を操作するのがいいかもしれません。
3.3 実装時の注意点
いくつか気をつけた方がいい点があります。
-
コンテキストウィンドウ
APIのコンテキストウィンドウは64,000トークンとそこまで高くないです。より大きなコンテキストが必要な場合は、オープンソース版を使う必要があります。あるいは、Redditでみかけたんですが、OpenRouterみたいなLLMを選べるAPIツールを使うと、オープンソース版で拡張できたりするみたいです。 -
レートリミット
これが結構厄介で、特に明確な記載がないんですよね。おそらく混雑したら少しずつカットしていく感じだと思うんですが、逆に想像しづらいです。なので、プロダクションで使うならフォールバックの処理は必須だと思います。
The rate limit exposed on each account is adjusted dynamically according to our real-time traffic pressure and each account's short-term historical usage.(https://api-docs.deepseek.com/faq)
def on_error_callback(error):
if error.status_code == 429: # Rate limit error
time.sleep(60) # 1分待機
return True # リトライ
return False
client = OpenAI(
# ... other settings ...
on_error=on_error_callback
)
3.4 実装のベストプラクティス
実際に使ってみて、こんなイメージの実装がおすすめです。
-
エラーハンドリング
レートリミットのフォールバックは必ず実装しておいた方がいいです。プロダクションで使う場合は特に重要です。 -
JSONの場合の出力形式の統一
response = client.chat.completions.create( model="deepseek-chat", response_format={"type": "json_object"}, messages=[{ "role": "system", "content": "常にJSON形式で応答してください" }] ) -
ストリーミング処理
for chunk in client.chat.completions.create( model="deepseek-chat", messages=[{"role": "user", "content": "こんにちは"}], stream=True ): if chunk.choices[0].delta.content: print(chunk.choices[0].delta.content, end="")
結論としては、既存のOpenAIベースのアプリケーションからの移行は比較的スムーズにできると思います。ただ、いくつか制限事項もあるので、それらを理解した上で実装を進めていくのがいいかなと思います。
4. パフォーマンスと精度
実際に使ってみて、GPT-4やClaude-3.5-Sonnetと同等のパフォーマンスを実現しているのは本当に驚きでした。ここではパフォーマンスと精度について、実際に試してみた感想を共有したいと思います。
4.1 モデルの基本性能
まず、基本的なスペックとしては、
- 671Bパラメータ(MoEモデル)で、そのうち37Bがアクティブ
- 14.8Tトークンで事前学習を実施
- 生成速度は60トークン/秒で、これはV2の3倍速いです
実際に使ってみて、コンテキストが狭いですが、GPT-4やClaude-3.5-Sonnetと比べても、まったく遜色ないパフォーマンスを感じました。
4.2 生成速度
処理速度については、かなり改善されていて、従来の20TPSから60TPSまで大幅アップしているようで、実際の使用感としても、レスポンスの速さは体感できました。
通过算法和工程上的创新,DeepSeek-V3的生成吐字速度从20 TPS大幅提高至60 TPS,相比V2.5模型实现了3倍的提升。(1)
4.3 出力トークン数の制限
ちなみに、出力トークンについては、標準設定だと通常の最大出力トークン数が4Kであり、手動で設定すれば8192までいけるので、プロンプトに応じて条件分岐させても良いと思います。
The 8K output tokens limit of the Chat Completion API is in Beta and requires user to set
base_url="https://api.deepseek.com/beta".(https://api-docs.deepseek.com/quick_start/pricing)
結論としては、GPT-4oの代替として十分な性能を持っていると感じました。特に生成速度の向上は、実用面で大きなメリットになると思います。ただし、プロダクションでの利用を考える場合は、やはりいくつかの注意点もあるので、それらを踏まえた上で判断する必要がありそうです。
5. コストと料金体系

コストに関して、個人的にDeepSeek V3の面白いところは、GPT-4oと同等の精度を持ちながら、結構柔軟な料金設定になっているところです。実際に使ってみた経験から、コストと性能のバランスについて共有したいと思います。
5.1 料金体系
現在、Deepseek V3 Chatは期間限定のキャンペーン価格を提供していて、2025年2月8日までは以下の料金になっています:
- 入力(キャッシュヒット):$0.07/Mトークン
- 入力(キャッシュミス):$0.27/Mトークン
- 出力:$1.10/Mトークン
GPT-4o-miniと同じくらいの値段なのに、GPT-4oと同等の精度があるというのが魅力的ですね。
即日起至2025年2月8日,DeepSeek-V3的API服务价格仍然会是大家熟悉的每百万输入tokens 0.1元(缓存命中)/ 1元(缓存未命中),每百万输出tokens 2元(https://api-docs.deepseek.com/zh-cn/news/news1226)
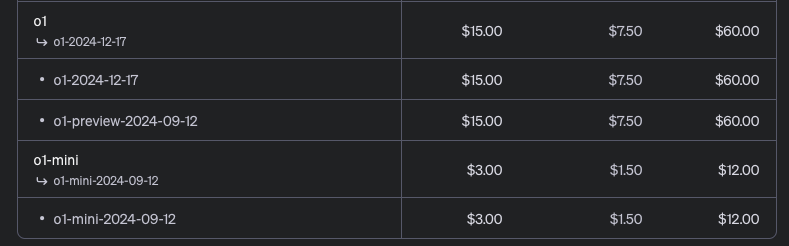
ちなみにDeepseek V3 Reasonerについては、以下の価格になっています。入力トークンの価格は、キャッシュミス時に100万トークンあたり0.55ドル、キャッシュヒット時に0.14ドルとなっています。一方、出力トークンは100万トークンあたり2.19ドルです。

これはOpen AI O1と比較すると、18倍くらいの差があるということになります。同レベルの性能のモデルがここまで安く使えるというのは非常に魅力的ですね。
5.2 利用開始のハードル
決済に関しては、最小利用額が2ドルからスタートできます。今はどうやら期間限定でクレジットが安いみたいです。そこまで本格的に利用を検討していない場合は、まず2ドルで決済して、そこから実装していく形がいいと思います。
自動で決済される仕組みはなく、アラート形式で追加で手動決済する必要があります。ここもプロダクションで使うなら要注意です。
5.3 キャッシュシステムの活用
コストを抑えるポイントとして、キャッシュシステムの活用があります。
- 同じようなプロンプトを繰り返し使う場合は、キャッシュヒット率が上がってコストが下がります
- キャッシュヒットの場合は、入力コストが大幅に削減されます($0.07/Mトークン)
- 特に追加料金なしでキャッシュを使えるのも魅力的です
Users can save up to 90% on costs with optimization for cache characteristics. Even without any optimization, historical data shows that users save over 50% on average.(https://api-docs.deepseek.com/news/news0802)
The service has no additional fees beyond the $0.014 per million tokens for cache hits, and storage usage for the cache is free.(https://api-docs.deepseek.com/news/news0802)
5.4 コスト最適化のポイント
実際に使ってみて、以下のような工夫でコストを抑えられそうです:
-
キャッシュの効率的な利用
- できるだけ同じようなプロンプトを使う
- システムプロンプトを工夫して再利用性を高める
多種应用能从上下文硬盘缓存中受益:
- 具有长预设提示词的问答助手类应用
- 具有长角色设定与多轮对话的角色扮演类应用(https://api-docs.deepseek.com/zh-cn/news/news0802)
-
トークン使用量の管理
- コンテキストウィンドウは64,000トークンまでですが、必要以上に長くしないように注意
- 不要な繰り返しを避ける
-
段階的な導入
- 最初は2ドルからスタートして、徐々にスケールアップしていく
- 開発フェーズでの使用量を見ながら、本番環境での予算を検討する
このような柔軟な料金体系のおかげで、小規模なプロジェクトから始めて、徐々にスケールアップしていけるのが良いところだと思います。特にキャッシュシステムをうまく活用すれば、かなりコストを抑えられそうです。
6. プライバシーとセキュリティ
プライバシーとセキュリティについては、実際に使ってみて結構気になる点がありました。特に企業での利用を考えている人は、注意深く検討した方がいいと思います。
6.1 プライバシーポリシーの懸念点

まずプライバシーポリシーの重要な点として、DeepSeekのすべてのデータは中国のサーバーに保存されることを認識しておく必要があります。これは単なるチャット内容だけでなく、APIを通じて送信されるすべての情報も含まれます。
また、技術的な観点から見ると、DeepSeekは非常に広範なデータを収集しています。特に気になるのは、キーストロークのパターンやリズムまでも収集対象となっていることです。これはAPI利用時には適応できないものだと思いますが、通常のウェブサービスとして利用する際にも注意が必要ですね。
プライバシーポリシー関連の問い合わせについては専用のメールアドレス(api-service@deepseek.com)が用意されていますが、データの削除のオプトアウトや、完全な削除を保証する明確な規定がないことも気になります。
これらの要因を総合的に考えると、特に機密性の高いビジネスデータを扱う企業がAPIを利用する場合は、十分なリスク評価とセキュリティ対策が必要だと感じます。場合によっては、より厳格なデータ保護ポリシーを持つ代替サービスの検討も視野に入れるべきかもしれません。
6.2 キャッシュシステムについて
キャッシュに関しては、一応セキュリティ対策がされているみたいです。
- ユーザーごとにキャッシュが分離されている
- 長期間使用していないキャッシュは自動的に削除される
- 他の用途には使用されないとのこと
每个用户的缓存是独立的,逻辑上相互不可见,从底层确保用户数据的安全和隐私。(1)
长时间不用的缓存会自动清空,不会长期保留,且不会用于其他用途。(1)
6.3 現実的な使用方法
実際の運用を考えると、こんな感じの方針がいいかもしれません。
-
段階的な導入
- まずは非センシティブなデータで試す
- 徐々にユースケースを広げていく
- 実運用データでよく確認する
-
代替手段の検討
- OpenRouterの活用
- OSSのホスティング
- センシティブ/非センシティブで使い分け
- 必要に応じてオンプレミス版の検討
結論として、DeepSeek V3は技術的にはすごく良いモデルなんですが、プライバシーとセキュリティの観点からは慎重に判断する必要がありそうです。特にプロダクション環境での利用を考えている場合は、OpenRouterのような追加のセキュリティレイヤーを検討するか、 あるいは用途を限定するなどの対策が必要かもしれません。
ちなみに、OpenRouterの他にも、Fireworks、Together、HyperbolicでもAPIが公開されています。Hyperbolicで使った様子は以下のとおりです。どうしても本家に比べるとスピードが劣ってしまうようです。
7. まとめ
実際にDeepSeek V3を使ってみた経験から、GPT-4の代替として検討する価値は十分にあると感じましたが、いくつか気をつけるべき点もありました。
7.1 良かった点
-
実装のしやすさ
- OpenAIのSDKを使ってラッピングできる
- 既存のコードを流用できるので、実装の負担が少ない
- Chat Completionやストリーミングがサポートされている
-
性能面
- GPT-4oと同等の精度がある
- 特に精度とスピードが求められるところで便利
- 生成速度が従来の3倍になっている
-
コスト面
- GPT-4oと同じくらいの値段で同等の精度
- 2ドルから始められる
- 今は期間限定でクレジットが安い
7.2 注意が必要な点
-
プライバシーとセキュリティ
- データ破棄のオプトアウトや記載がない
- プロダクションでの使用は慎重な判断が必要
-
技術的な制限
- Structured outputがない(JSONモードで代替が必要)
- コンテキストウィンドウが64,000トークンとそこまで高くない
- レートリミットが不透明で、混雑時の挙動が想像しづらい
結論としては、DeepSeek V3は技術的には非常に優れていて、特に既存のOpenAIベースのアプリケーションからの移行が容易な点は魅力的です。ただし、プロダクションでの利用を考える場合は、プライバシーポリシーやレートリミットなどの制限事項をよく理解した上で、適切な対策を講じる必要がありそうです。
ちなみにDiscordでは以下のような会話もされていますが、今後に期待です。

ご提案とフィードバックをありがとうございます。ご要望を承りました。現在、すべてのAPIデータを一律で匿名化・非識別化しています。ただし、個別ユーザーのオプトイン機能については、大規模な開発が必要なため、まだ実装できていません。プライバシー保護の機能と基準の向上に取り組んでおり、関連機能は今後の計画に含まれる予定です。より厳格なデータプライバシーが必要な場合は、データを完全に制御できるオープンソースモデルもご検討ください。
DeepSeekV3のAPIモードはDeskrexでもさわれるのでぜひお試しください。
About me
現在、市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai
ぜひお気軽にチャットしましょう!Devinもいます。
生成AIデスクリサーチサービス Deskrex | サービスページ
生成AIデスクリサーチエージェント Deskrex App | アプリケーションサイト
DeskrexAIリサーチ | メディア
株式会社Deskrex | 会社概要
Deskrex | Xページ
- 会社概要:https://www.deskrex.ai/
- Deskrex App:https://app.deskrex.ai/
- サービスページ:https://lp.deskrex.ai/
- メディア:https://media.deskrex.ai/
- X:https://x.com/deskrex
Discussion