生成AI基礎
LLM(Large Language Model)
-
ELMo(Embeddings from Language Models)
・2018年に発表
・2層のLSTM(Long Short Term Memory)をベースとしたモデル
・文章を正順と逆順で伝播させ、双方向の文脈を判断できるようになった
・ELMoのイメージ(BERTの論文より引用)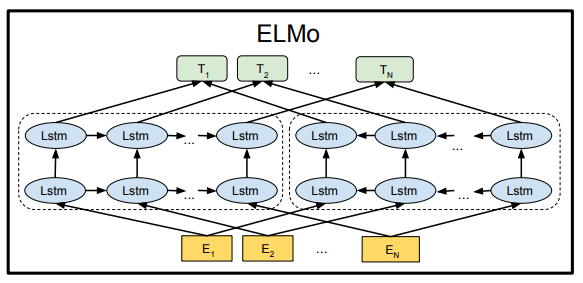
-
BERT(Bidirectional Encoder Representations from Transformers)
・2018年にGoogleが開発
・双方向性(文の前後を考慮した文脈理解が可能)が大きな特徴
・ELMoではLSTMだが、BERTではTransformerを利用)
・エンコーダのみを利用したモデル(Encoder-Only)
・ 「Masked LM(Language Modeling)」と「Next Sentence Prediction」の2つの学習の工夫をしている
・Masked LM:入力文章の1部をMASKや別の単語に置き換えてMASKの単語を予測させる
・Next Sentence Prediction:2文を入力とし、50%で意味的につながりのある文章、50%で意味的につながりのない文章にして、つながりの有無を予測させる -
Gemma
・2024/2/21にGoogleが開発したオープンソースモデル
・イタリア語から派生した名前で「宝石」のような意味がある
・Geminiと比べると小さいなサイズのモデル(2Bと7Bがある)
・GeminiはChatGPTに対抗して作られたモデルであるが、Gemmaは特定のタスクに向いているモデル
・2024/6時点でGemma2が公開されている -
Claude
・Anthropicが開発したモデル- Claude 3.5 Sonnet
・2024/6に登場したClaude 3の中位モデル(Haiku < Sonne < Opus)Sonnetを進化させたもの
・Claude 3 Opusを上回る性能だった
・Artifacts機能が画期的で、対話中にリアルタイムで視覚的なコンテンツを生成して表示・編集することができる
・Calude 3 と 3.5の比較(引用:Claude 3.5 Sonnetとは?使い方や料金、新機能を徹底解説!)
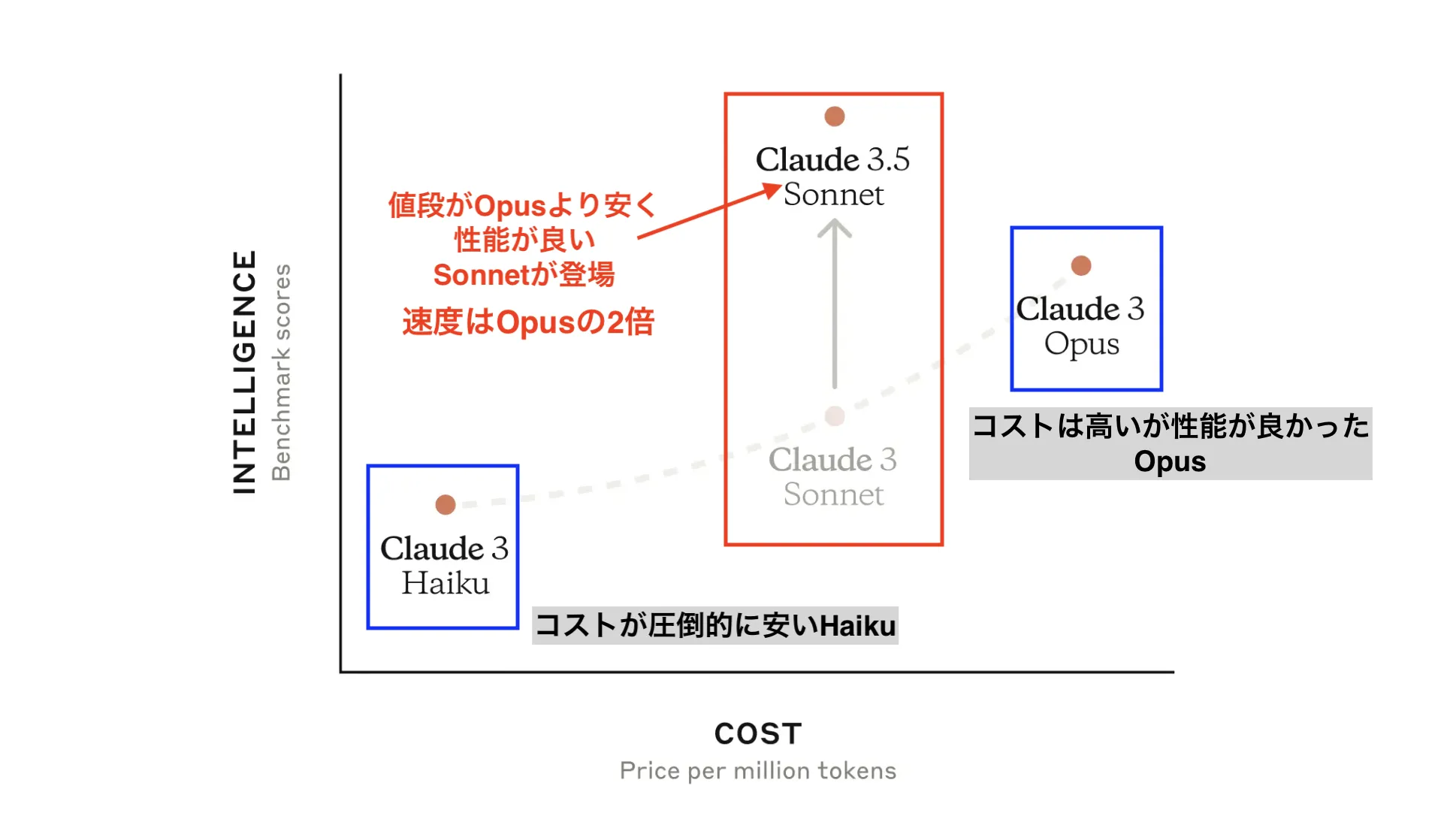
- Claude 3.5 Sonnet
-
LLaMa
・Metaが開発したオープンソースモデル
Diffusion Model
-
Diffusion-Model
・画像そのものを拡散・逆拡散過程にかける
・画像そのものなので、計算リソースが膨大になってしまうデメリットがあった
・逆拡散過程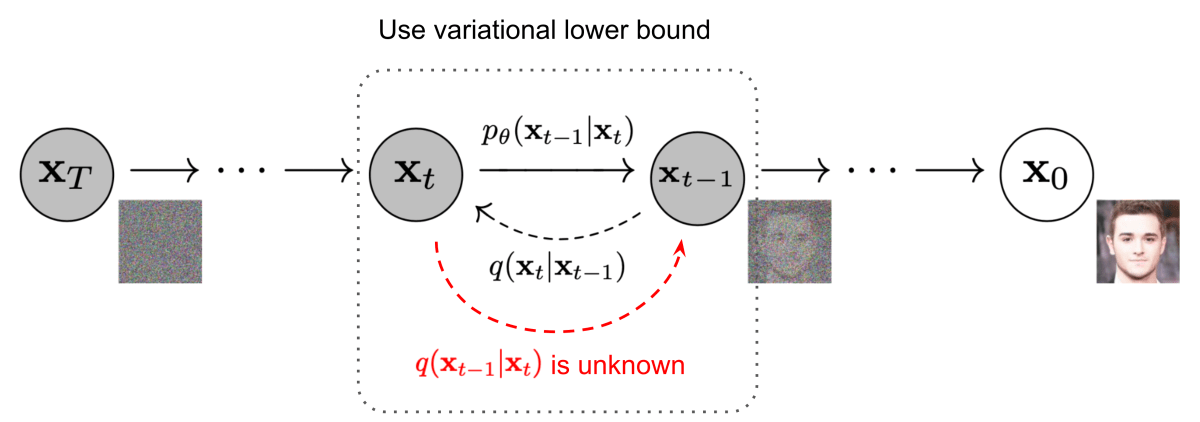
-
Latent-Diffusion-Model
・画像をVAE(Variational AutoEncoder)で滞在空間(latent space)に落とし込んだ特徴量を拡散・逆拡散過程にかける
・この過程によって計算リソースを抑え、効率的な学習が可能となった-
Stable-Diffusion
・モデルの構造そのものではなく、Latent-Diffusion-Modelベースのモデルととあるデータセットで学習された事前学習モデルのこと?(例:Stable-Diffusion-v1-2)
-
Stable-Diffusion
Learning Methods
-
LoRA(Low-Rank Adaptation)
・2021年に発表された技術
・w_new = w_old + (AB)
・w_new:更新後の重み行列(d × x)
・w_old:更新前の重み行列(d × x)
・A:学習対象の重み(d × r)
・B:学習対象の重み(r × x)
・↑の更新式によって、学習させる重みを大きく削減することができた
・全パラメーターをfine-tuningしたモデルとほぼ同等、または上回る精度であった
・LoRAのイメージ(論文より引用)

Generation Methods
-
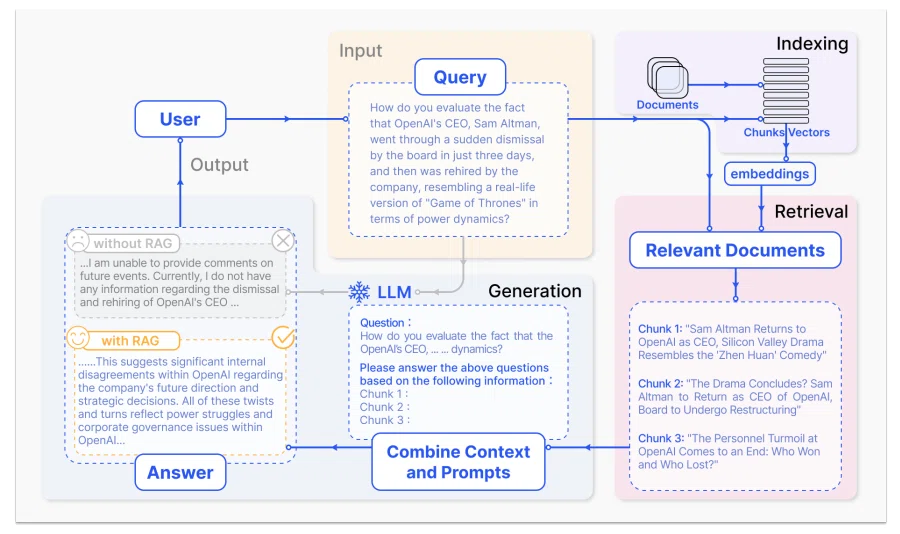
RAG(Retrieval-Augmented Generation)
・回答を生成するLLMの学習は不要
・一般的なLLMは「質問→回答生成」だが、RAGを導入すると「質問→文書検索(Retrieval:検索)→質問に文書検索で引っかかった情報を付与する(Augmented:拡張)→回答生成」になる
・内部の知識(LLM本体)だけでなく外部の知識(社内ドキュメントなど)も使うため、安全にかつ正確に文章生成を行うことができる
・RAGプロセス(論文より引用)