オハイオリージョンのBedrockが速くなったそうなので、実際に試してみた



Monday Night Live with Peter DeSantisで「オハイオリージョンのBedrockが速くなったよ」と言ってたので、実際に試してみました。
事前準備
- オハイオリージョンの
Claude 3.5 Haikuを有効化 - オハイオリージョンの
Llama 3.1 405Bを有効化 - オハイオリージョンの
Llama 3.1 70Bを有効化
Latency Optimizedとは
Latency Optimizedについて、ドキュメントから引用してきました。
Latency-optimized inference for foundation models in Amazon Bedrock delivers faster response times for models and helps improve responsiveness for your generative AI applications. You can use the use latency-optimized inference for Anthropic's Claude 3.5 Haiku model, and Meta's Llama 3.1 405B and 70B models. As verified by Anthropic, with latency-optimized inference on Amazon Bedrock, Claude 3.5 Haiku runs faster on AWS than anywhere else. Additionally, with latency-optimized inference in Bedrock, Llama 3.1 405B and 70B runs faster on AWS than any other major cloud provider. Learn more here.
要するに、オハイオリージョンのClaude 3.5 Haiku, Llama 3.1 405B, 70Bが、他のどの主要クラウドプロバイダーより高速に実行できます。
検証方法
プレイグラウンドのChatを使用。オハイオリージョン(Latency Optimizedを有効化)とオレゴンリージョンでモデルを比較し、どれだけレイテンシーを削減できたかを調査。
実際に触ってみた
Claude 3.5 Haiku
Latency Optimizedを使用するには、設定のLatency Optimizedを有効化します。
bedrockについて教えてください。と質問してみました。
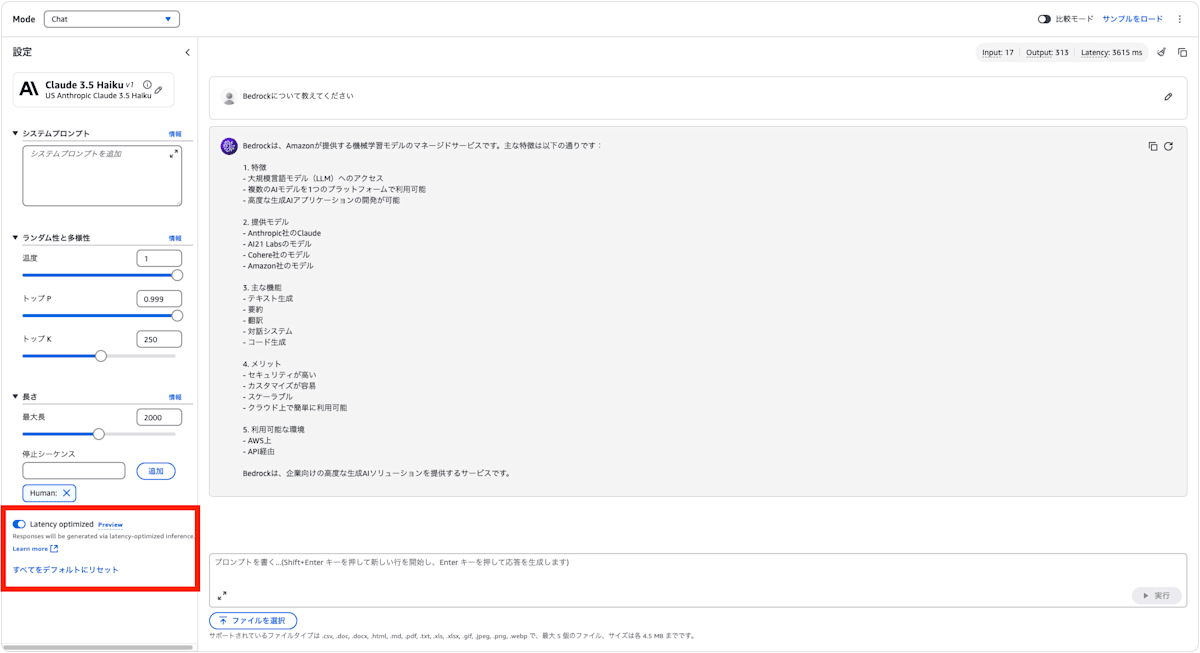
Latency Optimized 有効化
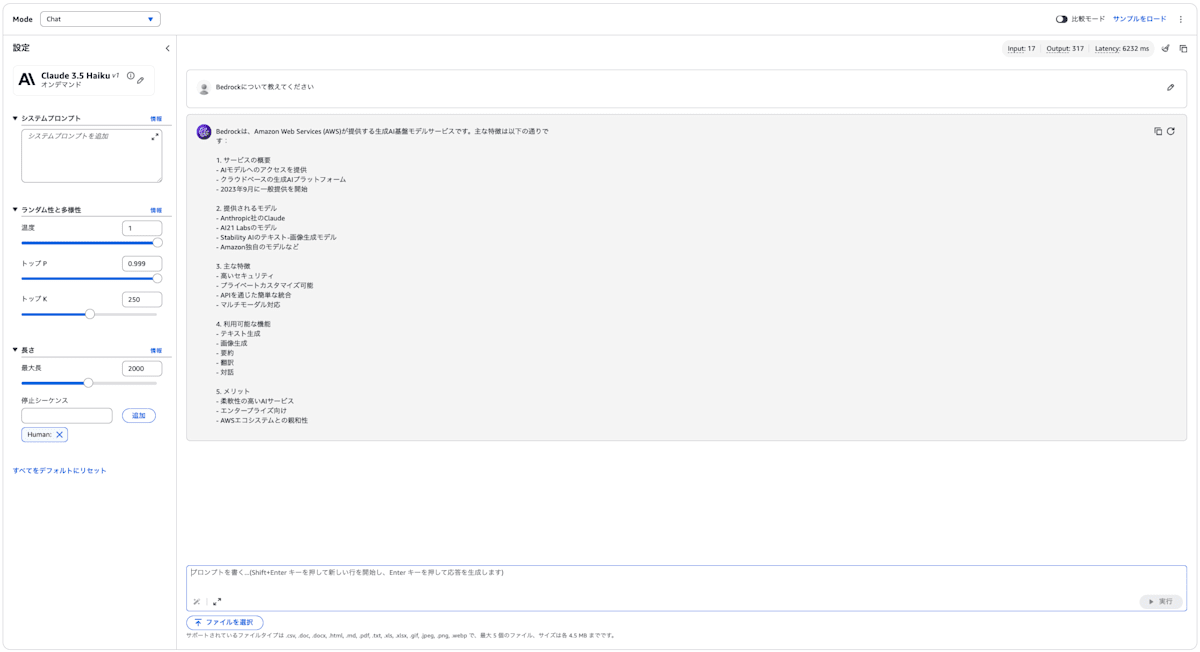
Latency Optimized なし
上記画像からそれぞれのレイテンシーは以下のとおりです。
- Latency Optimizedあり:3615ms
- Latency Optimizedなし:6232ms
Latency Optimizedを有効化すると、レイテンシーを約42%削減できました。
Llama 3.1 405B
Claudeだけではなく、Llama 3.1 405Bでも見てみましょう。
Llama3.1はBedrockについて知らなかったので、AWSについて教えてくださいに質問を変更しました。
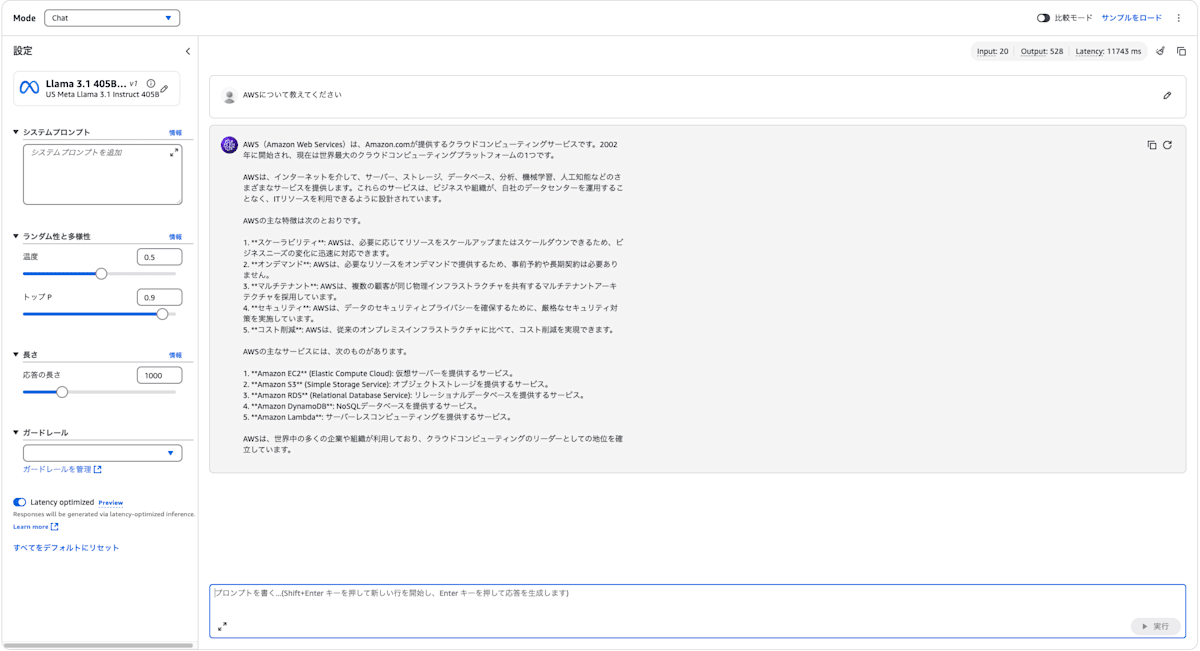
Latency Optimized 有効化
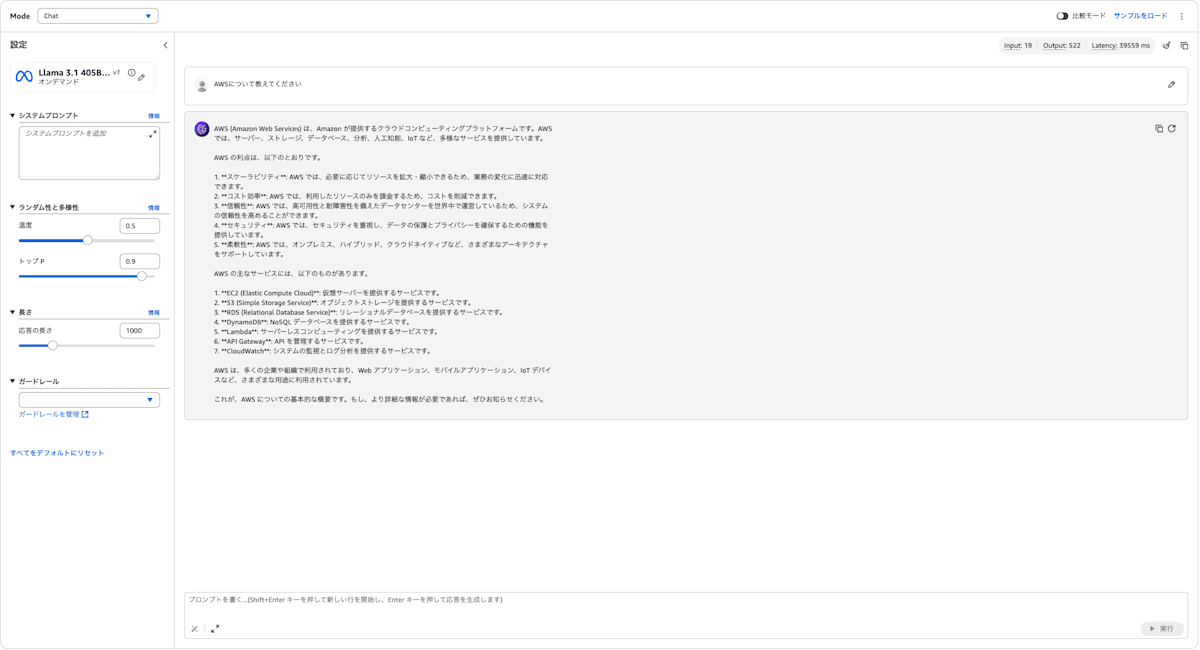
Latency Optimized なし
上記画像からそれぞれのレイテンシーは以下のとおりです。
- Latency Optimizedあり:11743ms
- Latency Optimizedなし:39559ms
Latency Optimizedを有効化すると、レイテンシーを約70%削減できました。
Llama 3.1 70B
次にLlama 3.1 70Bを見ていきます。
先ほど同様、AWSについて教えてくださいと質問してみました。
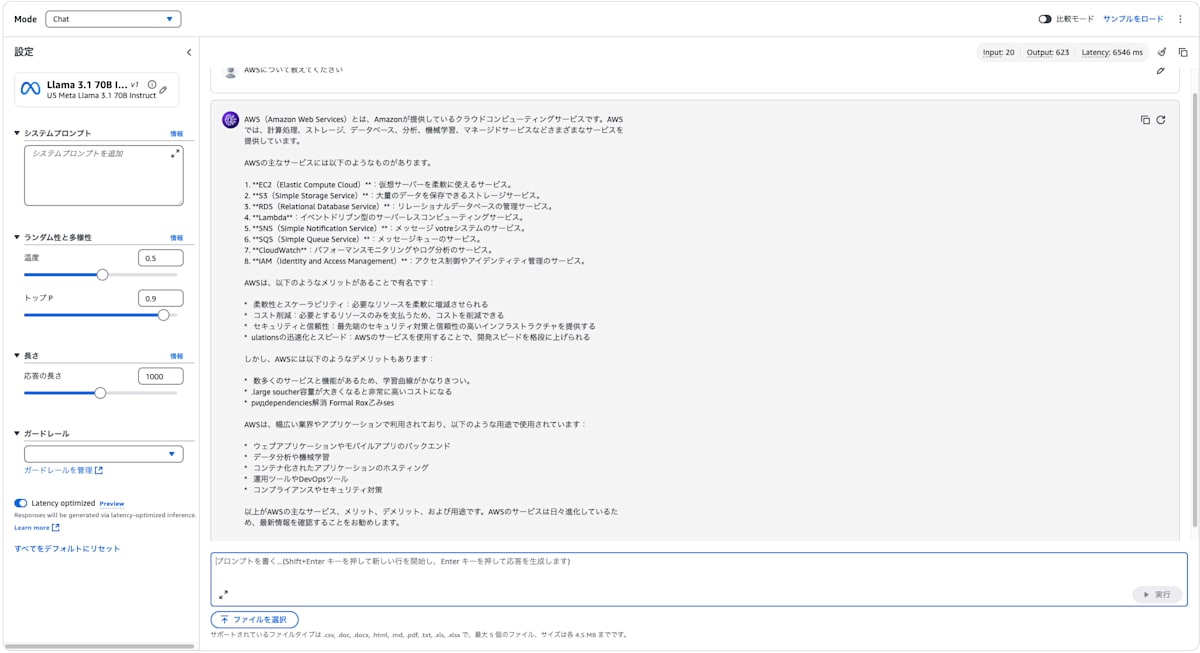
Latency Optimized 有効化

Latency Optimized なし
上記画像からそれぞれのレイテンシーは以下のとおりです。
- Latency Optimizedあり:6546 ms
- Latency Optimizedなし:14505 ms
Latency Optimizedを有効化すると、レイテンシーを約55%削減できました。
検証まとめ
上記の結果を表でまとめてみました。
| モデル | Latency Optimized | レイテンシー | 削減率 |
|---|---|---|---|
| Claude 3.5 Haiku | あり | 3,615ms | 42% |
| なし | 6,232ms | - | |
| Llama 3.1 405B | あり | 11,743ms | 70% |
| なし | 39,559ms | - | |
| Llama 3.1 70B | あり | 6,546ms | 55% |
| なし | 14,505ms | - |
検証状況により多少レイテンシーのばらつきはありますが、かなりのレイテンシーを削減できたことがわかると思います。
APIで呼び出してみる
下記のドキュメントを見る感じ、Bedrock runtime APIから呼び出せるとのことですが、まだ反映できていないのか2024/12/3 15時時点では使用することができません。
2024/12/3 17時時点で使用できるようになったので、Bedrock runtime APIを使用します。
import boto3
import json
import time
region = "us-east-2"
modelId = "us.anthropic.claude-3-5-haiku-20241022-v1:0"
model_package_arn = f'arn:aws:bedrock:{region}:{アカウントID}:inference-profile/{modelId}'
client = boto3.client('bedrock-runtime', region_name=region)
start_time = time.time()
response = client.invoke_model(
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Bedrockについて教えてください"
}
]
}
],
}),
modelId=modelId,
performanceConfigLatency="optimized", # Latency Optimizedを有効化する
)
end_time = time.time()
print(f"API呼び出し時間: {end_time - start_time}秒")
検索結果は同じなので、処理時間を下記に記載します。
# Latency Optimized あり
API呼び出し時間: 4.792994022369385秒
# Latency Optimized なし
API呼び出し時間: 7.693296909332275秒
APIを使用した場合でも、きちんとレイテンシーが削減されていることがわかりました。
まとめ
基調講演で6割レイテンシー削減と言っており半信半疑でしたが、かなりのレイテンシーを削減できたのではないかと思います。料金に関しては特に見当たりませんでしたが、他のリージョンでも使用できるようになると世界が変わりそうです。
Discussion