PythonとSeleniumでSBI証券の配当金履歴を自動取得する方法
はじめに
本記事ではwindows上でpython seleniumを使用してSBI証券の口座にログイン、配当金履歴を取得するpythonコードについて解説します。
コードは生成AIが書いてくれる時代ですが、認証を挟むサイトのRPAは出力させにくいタイプと思うため本記事を残します。
きっかけ
2024年になり新NISAが始まりました。私は高配当銘柄によく投資しているため配当金をもらう機会が多く、新NISAでさらに増えることと思います。
しかし、配当金がもらえると配当金込みの損益が知りたくなります。ただ、配当金込みで損益管理できるサービスはあまりありません。自前で資産管理アプリをつくったものの配当金の登録がめんどくさい、、、ということで今回はseleniumを使ってSBI証券から配当金履歴取得をします。
環境
下記のような環境で実施しました。
- windows 11 23H2
- Edge 120.0.2210.9
- python 3.11.3
- selenium 4.16.0
- pandas 2.1.4
- beautifulsoup4 4.12.2
- webdriver-manager 4.0.1
また、SBI証券のサイトは2024年1月の状態です。
コード全体
コードの流れは下記になります。
コードの全体は下記に記載しておきます。
get_dividend.py
import datetime
import os
import time
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.edge.service import Service
from webdriver_manager.microsoft import EdgeChromiumDriverManager
def sbi_login(SBI_USER, SBI_PASS):
# Edge用のオプション設定
edge_options = webdriver.EdgeOptions()
edge_options.use_chromium = True # ChromiumベースのEdgeを使う設定
edge_options.add_argument("--log-level=3") # ログレベルを設定
# ドライバーのサービス設定(ログ出力先を指定)
service = Service(EdgeChromiumDriverManager().install())
service.log_path = os.devnull # ログを抑制
# ブラウザを起動
driver = webdriver.Edge(service=service, options=edge_options)
# SBI証券のページへ遷移
url = "https://www.sbisec.co.jp/ETGate"
driver.get(url)
driver.implicitly_wait(60) # 追加
# ユーザーネームとパスワードを定義
username_value = SBI_USER
password_value = SBI_PASS
# ユーザーネームを入力
username = driver.find_element(By.NAME, "user_id")
username.send_keys(username_value)
# パスワードを入力
password = driver.find_element(By.NAME, "user_password")
password.send_keys(password_value)
# ログインボタンをクリック
driver.find_element(By.NAME, "ACT_login").click()
driver.implicitly_wait(60) # 追加
return driver
def sbi_get_dividend(driver, from_date, to_date):
# 口座管理ページへ遷移
driver.find_element(By.CSS_SELECTOR, "img[title='口座管理']").click()
driver.implicitly_wait(60)
# 現在のウィンドウのハンドルを取得
current_window_handle = driver.current_window_handle
# My資産ページへ遷移(新しいタブが開かれる)
driver.find_element(By.CSS_SELECTOR, "img[alt='My資産']").click()
driver.implicitly_wait(60)
# 全てのタブのハンドルを取得
all_window_handles = driver.window_handles
# 現在のタブと異なるハンドルを見つける
new_window_handle = None
for handle in all_window_handles:
if handle != current_window_handle:
new_window_handle = handle
break
# 新しいタブに切り替える
driver.switch_to.window(new_window_handle)
# 配当金ページへ遷移
driver.find_element(By.LINK_TEXT, "配当金・分配金履歴はこちら").click()
driver.implicitly_wait(60)
start_date = driver.find_element(By.XPATH, '//*[@id="search-condition"]/div[1]/div/div[1]/div[1]/div/div/input')
end_date = driver.find_element(By.XPATH, '//*[@id="search-condition"]/div[1]/div/div[1]/div[2]/div/div/input')
# 日付フィールドをクリアする
clear_input(start_date)
clear_input(end_date)
# フィールドに新しい日付を入力
start_date.send_keys(from_date.strftime("%Y/%m/%d"))
end_date.send_keys(to_date.strftime("%Y/%m/%d"))
# JavaScriptの処理が入力に干渉するのを避けるために、少し待つことも有効かもしれない
time.sleep(1)
# ボタン名の「照会」で検索
driver.find_element(By.XPATH, '//*[@id="search-condition"]/button').click()
# 空のDataFrameを作成。ここに列名を入れる
df = pd.DataFrame(columns=["受渡日", "口座", "商品", "銘柄名", "シンボル", "数量", "受取額"])
is_next_page_available = True
while is_next_page_available:
# ページのHTMLを取得
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
# テーブルの各行を取得
rows = []
rows = soup.find_all("li", class_="table-row css-1qty612")
# 各行からデータを取得
for row in rows:
data = []
# 受渡日、口座、商品のデータを取得
date, account_type, stock_type = row.find_all("div", class_="table-item")[:3]
data.extend([date.text.strip(), account_type.text.strip(), stock_type.text.strip()])
# 会社名とシンボルのデータを取得
company_info = row.find("div", class_="lg-wd-1-3 p-x-1 left none table-item")
company_name, symbol = company_info.find_all("p")
data.extend([company_name.text.strip(), symbol.text.strip()])
# 数量と受取額(税引後)のデータを取得
quantity = row.find("div", {"data-label": "数量"}).text.strip()
amount_received = row.find("div", {"data-label": "受取額(税引後)"}).text.strip()
data.extend([quantity, amount_received])
# DataFrameに行を追加
df = pd.concat([df, pd.Series(data, index=df.columns).to_frame().T], ignore_index=True)
if soup.find("span", string=">"):
if soup.find("span", role="presentation", class_="page-link disabled", string=">"):
is_next_page_available = False
else:
driver.find_element(By.XPATH, '//*[@id="search"]/div[1]/div/div[2]/div[2]/span').click()
driver.implicitly_wait(60)
time.sleep(10)
else:
is_next_page_available = False
df["受取額"] = df["受取額"].apply(lambda x: int(str(x).replace("円", "").replace(",", "")))
df["受渡日"] = df["受渡日"].apply(lambda x: pd.to_datetime(str(x), format="%Y/%m/%d").strftime("%Y/%m/%d"))
return df
# 入力フィールドにフォーカスを当ててから、値をDELETE
def clear_input(element):
element.click()
element.send_keys(Keys.CONTROL + "a")
element.send_keys(Keys.DELETE)
# 開始日、終了日を設定
to_date = datetime.datetime.now()
from_date = datetime.datetime.now() - datetime.timedelta(days=365 * 2)
print(
f"開始日: {from_date.strftime('%Y/%m/%d %H:%M:%S')}, 終了日: {to_date.strftime('%Y/%m/%d %H:%M:%S')} - 配当金データの取得を開始します。"
)
# ユーザID、パスワードを設定
username = (os.environ.get("SBI_USER"),)
password = os.environ.get("SBI_PASS")
print("ログイン処理を開始します。")
driver = sbi_login(username, password)
print("配当金データの取得を開始します。")
sbi_dividend_data = sbi_get_dividend(driver, from_date, to_date)
driver.quit()
print("配当金データの内容を表示します。")
print(sbi_dividend_data)
print("SBI証券からの配当金データ取得が完了しました。")
requirements.txt
selenium
pandas
beautifulsoup4
requests
webdriver-manager
.env
# 適宜自分の情報に書き換えてください。
SBI_USER=<ユーザID>
SBI_PASS=<パスワード>
各ステップの解説
ライブラリの準備
前提
python,pipはインストール済みとします。
ライブラリのインストール
下記コマンドを実行しライブラリのインストールをおこないます。
pip install requirements.txt
requirements.txtに記載されたライブラリが自動的にインストールされます。バージョンは最新が自動でインストールされます。
事前情報の定義
開始日、終了日の定義
配当金履歴の画面では配当金データの開始日、終了日が設定できます。今回は2年分とします。
# 開始日、終了日を設定
to_date = datetime.datetime.now()
from_date = datetime.datetime.now() - datetime.timedelta(days=365 * 2)
print(
f"開始日: {from_date.strftime('%Y/%m/%d %H:%M:%S')}, 終了日: {to_date.strftime('%Y/%m/%d %H:%M:%S')} - 配当金データの取得を開始します。"
)
ユーザID,パスワードの取得
ユーザIDとパスワードを直接コードに書いてしまうと、コードをgit管理するときにユーザIDとパスワードまで一緒にリモートリポジトリにpushされてしまいます。
そのため、ユーザIDとパスワードは.envファイルで環境変数として定義し、コード内で環境変数から読み込むようにします。
# ユーザID、パスワードを設定
username = os.environ.get("SBI_USER")
password = os.environ.get("SBI_PASS")
このように人に見せたくない情報は別ファイルに格納し、.envはgit管理から除外するようにすればユーザID、パスワードをリモートリポジトリにpushすることはなくなります。
git管理から除外するには.gitignoreに設定すればよいです。
.env
SBI証券へのログイン
SBI証券へのログインについては下記サイトが大変参考になりました。
ログイン部分に関しては上記サイトと基本的に同じ内容になりますので、異なる部分のみ解説します。
ログイン処理は関数化しているため、sbi_login関数を呼び出します。
print("ログイン処理を開始します。")
driver = sbi_login(username, password)
sbi_login内では最初にEdge用のオプションを設定します。
def sbi_login(SBI_USER, SBI_PASS):
# Edge用のオプション設定
edge_options = webdriver.EdgeOptions()
edge_options.use_chromium = True # ChromiumベースのEdgeを使う設定
edge_options.add_argument("--log-level=3") # ログレベルを設定
次にドライバーの設定をします。ここではwebdriver-managerを使用しています。
下記部分でドライバーのインストールをします。
# ドライバーのサービス設定
service = Service(EdgeChromiumDriverManager().install())
また標準ではドライバーのログが多くprint文が見えづらくなるため、下記でログ出力も抑制しています。
service.log_path = os.devnull # ログを抑制
以下の部分は先ほど紹介したブログと似た内容になりますので、解説は割愛しコードだけ記載します。
# ブラウザを起動
driver = webdriver.Edge(service=service, options=edge_options)
# SBI証券のページへ遷移
url = "https://www.sbisec.co.jp/ETGate"
driver.get(url)
driver.implicitly_wait(60)
# ユーザーネームとパスワードを定義
username_value = SBI_USER
password_value = SBI_PASS
# ユーザーネームを入力
username = driver.find_element(By.NAME, "user_id")
username.send_keys(username_value)
# パスワードを入力
password = driver.find_element(By.NAME, "user_password")
password.send_keys(password_value)
# ログインボタンをクリック
driver.find_element(By.NAME, "ACT_login").click()
driver.implicitly_wait(60)
return driver
下記サイトからユーザID、パスワードを入力し

SBI証券のログイン画面
ログインボタンを押すと下記画面が開きます。
ログイン後の画面
My資産タブを開く
次に損益額推移や受取配当金が管理されている「My資産」を開きます。処理はsbi_get_dividend関数にまとめています。
ログインの時に開いたブラウザをそのまま使うためdriverを引数として渡しています。また、フィルタで配当金データの開始日/終了日を指定するためそれも渡しています。
print("配当金データの取得を開始します。")
sbi_dividend_data = sbi_get_dividend(driver, from_date, to_date)
ここからsbi_dividend_data関数の紹介です。まずはMy資産のリンクがある「口座管理」ページを開きます。開発者ツールを見てみると「口座管理」ボタンはimg形式のリンクになっているのでimgのtitleで指定します。

口座管理ボタン
def sbi_get_dividend(driver, from_date, to_date):
# 口座管理ページへ遷移
driver.find_element(By.CSS_SELECTOR, "img[title='口座管理']").click()
driver.implicitly_wait(60)
そのあと、現在のウィンドウのハンドルを取得します。これはこの後わかるのですが、My資産タブは現在のタブとは別タブで開きます。タブを移動するときにはどのタブに移動するかを指定しなくてはなりませんが、今回は最初からある方のタブ ではない方 という指定をするためここで現在のタブ情報を取得します。
# 現在のタブのハンドルを取得
current_window_handle = driver.current_window_handle
タブのハンドルを取得したら「My資産」ボタンを押します。今回はtitleの設定がなかったのでaltで指定します。
# My資産ページへ遷移(新しいタブが開かれる)
driver.find_element(By.CSS_SELECTOR, "img[alt='My資産']").click()
driver.implicitly_wait(60)

新規タブが開く
ここで開いているすべてのタブのハンドルを取得します。
# 全てのウィンドウのハンドルを取得
all_window_handles = driver.window_handles
そして、「すべてのウィンドウ」から「最初から開いてるタブ」ではない方のタブを選択して切り替えます。
# 現在のウィンドウと異なるハンドルを見つける
new_window_handle = None
for handle in all_window_handles:
if handle != current_window_handle:
new_window_handle = handle
break
# 新しいタブに切り替える
driver.switch_to.window(new_window_handle)
これで無事にMy資産画面を開くことができました。

My資産
配当金履歴からフィルタ設定しデータ取得する
いよいよ配当金データを取得します。引き続き同じsbi_dividend_data関数内での処理が続きます。
まず、「配当金・分配金履歴」のページを開きます。ここでは素直に「配当金・分配金履歴はこちら」のリンクテキストを検索しクリックしています。
# 配当金ページへ遷移
driver.find_element(By.LINK_TEXT, "配当金・分配金履歴はこちら").click()
driver.implicitly_wait(60)
下記画面が開きます。

配当金・分配金履歴
画面が開くと配当金履歴検索のためのフィルタ条件を入力できます。今回は引数で取得している日付を入力したいため、まずは開始日と終了日のフォームを探します。
しかし、開始日フォームと終了日フォームはどちらも同じHTMLコードになっているため、今までの方法では両者を区別できません。そのため、ここではクロスパスで指定します。
ただし、
- コードが複雑が長くなってしまうこと
- 厳密に指定しすぎるがゆえにWebページの変更に弱い
こともあるので私はどうしようもないとき以外は使わないようにしています。
start_date = driver.find_element(By.XPATH, '//*[@id="search-condition"]/div[1]/div/div[1]/div[1]/div/div/input')
end_date = driver.find_element(By.XPATH, '//*[@id="search-condition"]/div[1]/div/div[1]/div[2]/div/div/input')
開始日と終了日フォームにはデフォルトの日付が入っているのでこれを削除します。このまま値を上書きしてもよさそうですが、私の環境ではデフォルトの値に続く形で値が入ってしまうため、先にデフォルトの日付を削除しています。
# 日付フィールドをクリアする
clear_input(start_date)
clear_input(end_date)
clear_input関数は別で定義しており下記内容です。引数で取得したエレメントに対してCtrl+AのあとにDELETEキーを押して値を削除します。
# 入力フィールドにフォーカスを当ててから、値をDELETE
def clear_input(element):
element.click()
element.send_keys(Keys.CONTROL + "a")
element.send_keys(Keys.DELETE)
そのあとは開始日/終了日にそれぞれ日付を入力します。デフォルトのフォーマットと同じYYYY/mm/dd形式で入力します。
# フィールドに新しい日付を入力
start_date.send_keys(from_date.strftime("%Y/%m/%d"))
end_date.send_keys(to_date.strftime("%Y/%m/%d"))
私の環境ではうまく自分が入力したい日付で更新できなかったため、1秒sleepする処理を入れています。この日付フォームに日付を入力するところはもっとも試行錯誤したところで、完成までにいろいろなコードを追加しました。ここもその1つであり、ひょっとするとこれは不要かもしれません。
# JavaScriptの処理が入力に干渉するのを避けるために、少し待つことも有効かもしれない
time.sleep(1)
フィルタの設定ができたので「照会」ボタンを押します。id = search-conditionのbuttonを探しクリックします。
# ボタン名の「照会」で検索
driver.find_element(By.XPATH, '//*[@id="search-condition"]/button').click()
ここでようやく配当金履歴データが表示されます。

配当金データ
先にデータを格納するフレームワーク変数を定義しておきます。取得する項目は表示されている項目と同じものとします。
# 空のDataFrameを作成。ここに列名を入れる
df = pd.DataFrame(columns=["受渡日", "口座", "商品", "銘柄名", "シンボル", "数量", "受取額"])
あとはデータを取得すればいいだけなのですが、配当金履歴データは件数が多いと複数ページに表示が分かれてしまいます。その対策として、ここでis_next_page_availableという変数を定義しておきます。
is_next_page_available = True
ページからデータを取得する処理はis_next_page_availableがtrueのときのみ実行します。各処理の最後で次のページが存在するかを確認し、存在するときはし次ページを開きis_next_page_availableはtrueのまま、ないときはis_next_page_availableをfalseに設定します。この処理を繰り返すことで複数ページからデータを取得します。
while is_next_page_available:
ここで表示されたHTMLの内容を読み取ります。HTMLの内容を読み取るためBeautifulSoupライブラリを使用しています。
まずはページ全体のhtmlを取得します。
# ページのHTMLを取得
html = driver.page_source
soup = BeautifulSoup(html, "html.parser")
次に取得したHTMLデータから<li>要素を取得しデータを行ごとに取得します。
# テーブルの各行を取得
rows = []
rows = soup.find_all("li", class_="table-row css-1qty612")
行のデータから各列の要素を取得します。
# 各行からデータを取得
for row in rows:
data = []
# 受渡日、口座、商品のデータを取得
date, account_type, stock_type = row.find_all("div", class_="table-item")[:3]
data.extend([date.text.strip(), account_type.text.strip(), stock_type.text.strip()])
# 会社名とシンボルのデータを取得
company_info = row.find("div", class_="lg-wd-1-3 p-x-1 left none table-item")
company_name, symbol = company_info.find_all("p")
data.extend([company_name.text.strip(), symbol.text.strip()])
# 数量と受取額(税引後)のデータを取得
quantity = row.find("div", {"data-label": "数量"}).text.strip()
amount_received = row.find("div", {"data-label": "受取額(税引後)"}).text.strip()
data.extend([quantity, amount_received])
事前に作成しておいたデータフレームに格納します。
# DataFrameに行を追加
df = pd.concat([df, pd.Series(data, index=df.columns).to_frame().T], ignore_index=True)
最後に、まだ次のページがあるかどうかを確認します。ここではページを遷移するための>のマークがあるかで判断しています。>が見つからないときや、表示されていても押せない状態になっているときはis_next_page_availableをfalseにします。
逆に>があるときはクリックしてis_next_page_availableは設定しません。(もとからtrueが設定されているため)
if soup.find("span", string=">"):
if soup.find("span", role="presentation", class_="page-link disabled", string=">"):
is_next_page_available = False
else:
driver.find_element(By.XPATH, '//*[@id="search"]/div[1]/div/div[2]/div[2]/span').click()
driver.implicitly_wait(60)
time.sleep(10)
else:
is_next_page_available = False
ここで「受渡日」と「受取額」の変換をおこないます。どちらもテキスト形式で取得されるため、それぞれ日付型、整数型に変換します。
df["受取額"] = df["受取額"].apply(lambda x: int(str(x).replace("円", "").replace(",", "")))
df["受渡日"] = df["受渡日"].apply(lambda x: pd.to_datetime(str(x), format="%Y/%m/%d").strftime("%Y/%m/%d"))
データの取得が終わったのでブラウザを閉じます。driver.quitで実行しています。driver.closeだと複数開いているタブのアクティブタブしか閉じることができないためquitを使っています。
driver.quit()
最後に取得した内容を表示して終了です。
print("配当金データの内容を表示します。")
print(sbi_dividend_data)
print("SBI証券からの配当金データ取得が完了しました。")
あとはこれを自身が管理する媒体に適宜登録しましょう。
出力結果
printによるターミナルへの出力結果例を表示します。
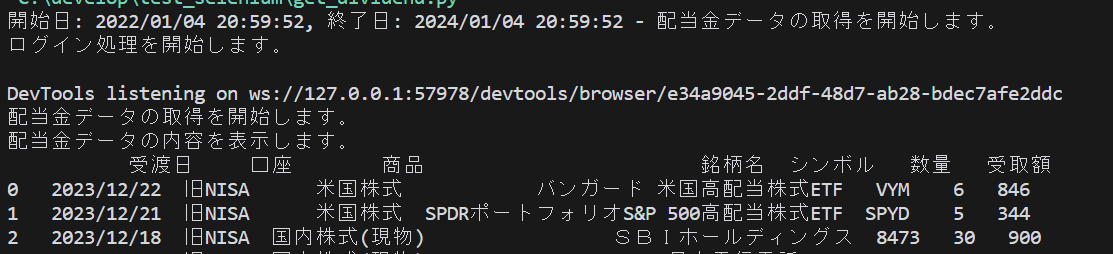
出力結果
米国株式も国内株式もどちらもきちんと取得できています。
まとめ
いかがでしたでしょうか。
私はpythonの知識がほとんどない状態で 生成AIありき でpythonを始めました。そのため今回のような生成AIが出力しづらいコード(サイト情報を丸々AIに食べさせるのに忌避感があるとき)はなかなか苦戦することになりました。
新NISAによる初心者投資家の増加 + 生成AIによる初心者プログラマーの増加、この時代の変化に本記事が少しでも役立てば幸いです。
Discussion