【My秘書】chatGPT×EDINET×LINEで保有銘柄の決算要約してくれるお姉さん
はじめに
StableDiffusionで作成したアニメ絵のイラスト、せっかくだから何かに使えないか?
いろいろ考えた結果、今回は保有銘柄の決算が出たらLINEで要約教えてくれる秘書のお姉さんにしよう!と思いつきました。保有銘柄の決算報告書が新規アップロードされていないかEDINETで確認し、あればchatGPTで要約してLINEに通知します。
NISAで調子に乗って銘柄数を増やしすぎた投資初心者の私には願ってもない機能です。
今回実現したいこと
EDINET APIを利用してウォッチリストの銘柄の半期報告書、四半期報告書が新規に提出されていないかを確認します。提出されている場合はここから半期報告書、または四半期報告書を取得し経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析の欄の内容をchatGPTで要約、内容をLINEに通知します。
大まかな流れを以下の図に表しました。
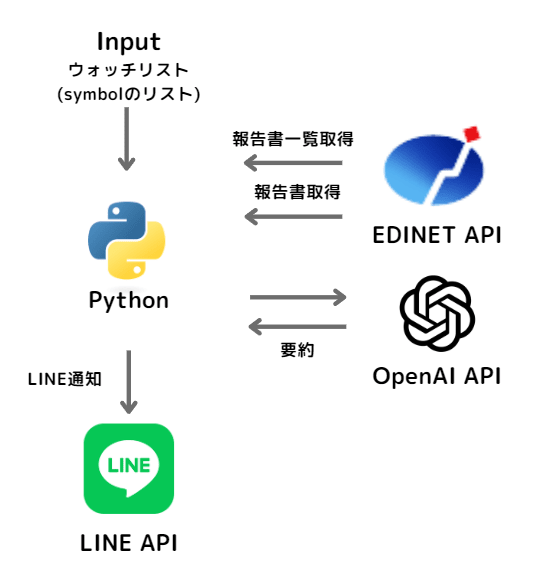
構成図
コードはGitHubで公開しています。
ご注意
筆者は投資初心者です
無暗に銘柄数を増やしすぎて管理できなくなるような初心者の記事です。要約内容もお察しなので本格的にファンダメンタル分析をする人は適切な要約内容を自分で考える必要があります。
chatGPTとLINEはキャラ付けされています
画像生成でつくった自分好みの画像を活用したい、がスタートです。そのため、LINEもchatGPTもお姉さん風にキャラ付けされています。受け付けない人いたら申し訳ありません。
決算報告書について
対象は四半期報告書と半期報告書のみです。有価証券報告書は入っていません。直近の四半期決算を乗り切るために本プログラムを書きましたが、有価証券報告書は実装が間に合っていません。
日次実行について
このプログラムは日次実行されることを想定していますが、本記事では日時実行する部分については触れませんので各自で実装する必要があります。
前提事項
事前準備
各API実行に必要なkey,tokenを取得済みである必要があります。
- OpenAI API Keyが取得済みであること
- EDINET API Keyが取得済みであること
- LINE Messaging APIのプロバイダー、チャンネルを作成していること
- LINE投稿用のtokenを取得していること
こちらのやり方は本記事では割愛します。以下のリンク先が参考になるかもしれません。
取得したkey,tokenは.envファイルに以下のように設定しておいてください。
EDINET_API=<EDINETのAPI key>
OPENAI_API=<OpenAIのAPI key>
line_userId=<作成したLINEプロバイダーのユーザID>
line_token=<作成したLINEチャンネルのtoken>
コードをgit管理するときは.envファイルがリモートにpushされないように.gitignoreファイルに.envファイルを書いておくのを忘れないようにしてください。
.env
環境
今回は下記環境で実施しました。
- Python 3.11.3
- requests 2.30.0
- EDINET API Version2
プログラム
プログラム概要
主に下記6つの関数で構成されています。
| No | 処理内容 | 関数 |
|---|---|---|
| 1 | EDINETから決算報告書リストの取得 | get_edinet_list |
| 2 | ウォッチリスト銘柄の報告書フィルタリング | filter_edinet_list |
| 3 | 報告書のダウンロード | download_edinet_documents |
| 4 | 報告書から内容を抽出 | extract_content_from_csv |
| 5 | ChatGPTによる決算情報の要約 | summarize_financial_reports |
| 6 | LINE通知 | send_financial_summary |
導入部分
まずは導入部分です。inputとしてwatchlistを用意しています。watchlistは自分が決算内容を確認したい企業の証券コードです。各自設定してください。
if __name__ == "__main__":
# ウォッチリスト銘柄のシンボルを登録しておく
watchlist = ["2531", "8117"]
JST = timezone(timedelta(hours=+9))
date = datetime.now(JST).strftime('%Y-%m-%d')
①EDINETから決算報告書リストの取得
当日提出された決算報告書リストの一覧を取得するためにget_edinet_list関数を実行します。
edinet_list = get_edinet_list(date)
print(f"{date}のEDINETリストを取得しました") # デバッグ用のコメント
get_edinet_list関数の中ではos.environ.getで.envファイルからEDINETのAPI Keyを取得しています。APIのリクエストに関してはマニュアルに記載の通りです。
# 指定された日付でEDINETから文書一覧を取得する
def get_edinet_list(date):
api_key = os.environ.get("EDINET_API")
url = f"https://api.edinet-fsa.go.jp/api/v2/documents.json?date={date}&type=2&Subscription-Key={api_key}"
response = requests.request("GET", url)
return json.loads(response.text)
マニュアルは以下からダウンロードができます。今回はversion2を使用しています。後で出てくるEDINETのAPIも同じマニュアルです。
②ウォッチリスト銘柄の報告書フィルタリング
取得した一覧内にウォッチリスト銘柄の報告書がないか確認します。filter_edinet_list関数では先ほど取得した一覧からウォッチリスト銘柄についてのシンボル、企業名、ドキュメントID、ドキュメントタイプをjson形式で返します。ドキュメントタイプは140、160などの数字で半期報告書、四半期報告書などのドキュメントタイプを示します。リターンのjsonが空の時はウォッチリスト銘柄の報告書提出はないため処理を終了します。
watchlist_docs = filter_edinet_list(edinet_list, watchlist)
if not watchlist_docs:
print("ウォッチリストの報告書はありませんでした。処理を終了します。")
exit()
else:
print("ウォッチリストの報告書が新規アップロードされています。後続の処理を実行します。")
# watchlist_docのfilerNameの値のみprintする
print(f"対象銘柄: {[watchlist_doc['filerName'] for watchlist_doc in watchlist_docs]}")
filter_edinet_list関数は以下のような処理です。
# EDINETリストから特定のシンボルリストに一致する文書をフィルタリングする
def filter_edinet_list(EDINET_LIST, symbol_list):
watchlist_docs = []
for result in EDINET_LIST["results"]:
if result["secCode"] and result["secCode"][:-1] in symbol_list:
if result["docTypeCode"] in ["140", "160"]:
watchlist_docs.append(
{
"secCode": result["secCode"][:-1],
"filerName": result["filerName"],
"docID": result["docID"],
"docTypeCode": result["docTypeCode"],
}
)
return watchlist_docs
secCodeにはシンボルが格納されています。このシンボルはよく使われる4桁の証券コードに対し末尾に0を足したものが使われているため末尾の1桁を除いています。
また、今回は四半期報告書と半期報告書のみを対象としているため、docTypeCodeは140、160のみを指定しています。
③報告書のダウンロード
次に前回取得したドキュメントIDのドキュメントをEDINET APIでダウンロードします。ここからはfor文で各ドキュメントごとに処理をおこなっていきます。
for watchlist_doc in watchlist_docs:
download_edinet_documents(watchlist_doc)
print(f"{watchlist_doc['filerName']} >> ドキュメントをダウンロードしました。") # デバッグ用のコメント
取得したファイルはカレントディレクトリの下に./document/<企業名>というフォルダを作成しその下に保存します。edinetではいくつかのフォーマットでドキュメントをダウンロードできますが、今回はpdf版とcsv版をダウンロードします。csv版はzipでダウンロードされるので解凍処理をしています。
def download_edinet_documents(watchlist_docs):
api_key = os.environ.get("EDINET_API")
docID = watchlist_docs["docID"]
filer_name_dir = os.path.join("documents", watchlist_docs["filerName"])
os.makedirs(filer_name_dir, exist_ok=True)
# EDINETからpdfを取得
url = f"https://api.edinet-fsa.go.jp/api/v2/documents/{docID}?type=2&Subscription-Key={api_key}"
response = requests.request("GET", url)
with open(os.path.join(filer_name_dir, f"{docID}.pdf"), "wb") as f:
f.write(response.content)
# EDINETからzipを取得
url = f"https://api.edinet-fsa.go.jp/api/v2/documents/{docID}?type=5&Subscription-Key={api_key}"
response = requests.request("GET", url)
# ZIPファイルを解凍する
with zipfile.ZipFile(io.BytesIO(response.content)) as z:
z.extractall(filer_name_dir)
return
処理としてはcsv版だけでも問題ないです。pdf版も取得しているのは、要約項目を検討するときにpdfの方が見やすいのでついでにダウンロードしているだけです。
④CSV抽出
ダウンロードしたファイルから四半期会計期間、表紙と経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析の欄の内容を取得します。経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析はこの後chatGPTに要約させます。四半期会計期間、表紙は会計期間などの情報が書かれた報告書の表紙(タイトル)です。要約はしませんがLINE通知するときにそのまま挿入したいので取得します。
content_data = extract_content_from_csv(watchlist_doc)
print(f"{watchlist_doc['filerName']} >> CSVからコンテンツデータを抽出しました。") # デバッグ用のコメント
extract_content_from_csv関数は最初に./document/<企業名>/XBRL_TO_CSVからcsvを取得します。zipファイルは./document/<企業名>フォルダに保存しますが、zipを解凍するとXBRL_TO_CSVができます。
# ダウンロードした文書から必要な情報をCSVファイルから抽出する
def extract_content_from_csv(watchlist_docs):
content_data = {}
filer_name_dir = os.path.join("documents", watchlist_docs["filerName"])
# 解凍したzipのXBRL_TO_CSVフォルダ内のjpcrpから始まるcsvファイルを解析する
for file in os.listdir(os.path.join(filer_name_dir, "XBRL_TO_CSV")):
また、XBRL_TO_CSVの下にはいくつかのcsvファイルがあります。報告書の内容に追加して監査系の情報が書かれたファイルもあるようです。今回はjpcrpから始まるファイルを指定します。
if file.startswith("jpcrp") and file.endswith(".csv"):
csv_path = os.path.join(filer_name_dir, "XBRL_TO_CSV", file)
with open(csv_path, "r", encoding="utf-16") as csv_file:
reader = csv.reader(csv_file, delimiter="\t")
csvの中では1行ずつデータが入っているので該当する行のデータを取得します。
-
経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析-
jpcrp_cor:ManagementAnalysisOfFinancialPositionOperatingResultsAndCashFlowsTextBlockの行に格納されています。
-
-
四半期会計期間、表紙-
jpcrp_cor:QuarterlyAccountingPeriodCoverPageの行に格納されています。
-
これらをcontent_dataというjsonにまとめて返します。
for row in reader:
if (
row[0]
== "jpcrp_cor:ManagementAnalysisOfFinancialPositionOperatingResultsAndCashFlowsTextBlock"
):
content_data["management_analysis_content"] = row[8]
elif row[0] == "jpcrp_cor:QuarterlyAccountingPeriodCoverPage":
content_data["quarterly_accounting_period_content"] = row[8]
return content_data
⑤ChatGPTによる決算情報の要約
いよいよchatGPTによる要約です。ドキュメントの情報であるwatchlist_docとcsvから取得したcontent_dataを引数として渡します。
print(f"{watchlist_doc['filerName']} >> chatGPTで要約を取得します...")
chat_response_data = summarize_financial_reports(content_data, watchlist_doc)
print(f"{watchlist_doc['filerName']} >> 財務報告の要約を取得しました。") # デバッグ用のコメント
summarize_financial_reports関数では最初にurlやtokenなど必要事項を設定した後、システムプロンプトを設定しています。先に説明したようにお姉さん風にキャラ付けしているのでご容赦ください。
# chatGPTを使用して財務報告の内容を要約する
def summarize_financial_reports(content_data, watchlist_doc):
# chatGPTで内容を要約する
url = "https://api.openai.com/v1/chat/completions"
token = os.environ.get("OPENAI_API")
system_prompt = (
"あなたは20代後半の私の幼馴染のお姉さんです。企業の決算を要約して教えてくれます。「~かしら」「~ね」「~わ」といったお姉さん口調のため口で話します。たまにちょっとからかうようなことも言ってきます。"
)
本題のユーザプロンプトです。主に命令文、入力文、出力文の3項目で成り立っています。
user_pronmpt = (
"# 命令文"
"あなたは証券アナリストです。{{ 企業名 }}の{{ 会計期間 }}の決算書の内容を読み、業績、マクロの業績変動要因、市場の業績変動要因、会社の業績変動要因のサマリと今後の展望を解説してください。"
"# 入力文"
f"企業名:{watchlist_doc['filerName']}"
f"会計期間:{content_data['quarterly_accounting_period_content']}"
"# 出力文"
"下記項目とスキーマ、文字数の対応でjson形式で出力してください。"
"業績サマリ summary 200文字以内"
"マクロの業績変動要因 macro_factor 50文字以内"
"市場の業績変動要因 market_factor 50文字以内"
"会社の業績変動要因 company_factor 50文字以内"
"今後の展望 outlook 300文字以内"
)
プロンプトについて解説します。
命令文に関して
企業名(EDINETのドキュメント一覧で取得した企業名)と会計期間(ドキュメントから取得した四半期会計期間、表紙の内容)を変数としています。chatGPTへの要約依頼はドキュメントごとにfor文で繰り返し実行しています。こうすることでループごとに変数を変えつつプロンプト再利用できます。
入力文に関して
「命令文」に入れる変数の値を指定しています。
出力文に関して
下記5項目について見解を出してもらっています。
- 業績サマリ
- マクロの業績変動要因
- 市場の業績変動要因
- 会社の業績変動要因
- 会社の展望
LINEに通知仕様上、文字数制限も持たせています。
次の部分の解説に移ります。リクエストのプロンプト以外の部分です。
payload = json.dumps(
{
"model": "gpt-4-1106-preview",
"max_tokens": 1024,
"temperature": 0.5,
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_pronmpt},
],
"response_format": {"type": "json_object"},
}
)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {token}",
}
response = requests.request("POST", url, headers=headers, data=payload)
response_json = response.json()
chat_response_content = response_json["choices"][0]["message"]["content"]
chat_response_data = json.loads(chat_response_content)
return chat_response_data
モデルはgpt-4-1106-previewを設定しています。要約なので言語性能が高いものを選択しています。
また"response_format": {"type": "json_object"}の部分も重要です。いわゆるjsonモードと呼ばれるものを使っています。これを設定することで回答内容がjson形式であることが保証されます。これを設定しないと回答内容が1つのコードブロックとして返ってしまうなどがおき、取り扱いの難しいデータとなってしまいます。
⑥LINE通知
最後にLINEに通知します。LINEにはLINE notifyと呼ばれるシンプルなテキスト形式の通知をするサービスがありますが、今回はこれではなくLINE Messaging APIというサービスを使います。
今回はMy秘書のために独自のアイコンを設定したかったこと、決算内容という長文コンテンツのスタイリングのためこちらを選びます。
引数にはこれまで取得したwatchlist_doc、content_data、chat_response_dataを引数としてわたします。
send_financial_summary(watchlist_doc, content_data, chat_response_data)
print(f"{watchlist_doc['filerName']} >> 財務サマリーをLINEに送信しました。") # デバッグ用のコメント
まずは導入の部分です。ほかのAPIと同様にtokenの読み込みをするほか、userIDも読み込みます。
# LINE APIを使用して財務サマリーを送信する
def send_financial_summary(watchlist_doc, content_data, chat_response_data):
token = os.environ.get("line_token")
userId = os.environ.get("line_userId")
lineMessageApi = "https://api.line.me/v2/bot/message/push"
headers = {"Authorization": "Bearer " + token, "Content-Type": "application/json"}
summary = chat_response_data["summary"]
macro_factor = chat_response_data["macro_factor"]
market_factor = chat_response_data["market_factor"]
company_factor = chat_response_data["company_factor"]
outlook = chat_response_data["outlook"]
次は投稿するレイアウトの設定をします。投稿内容のレイアウトはjson形式で定義します。設定の仕方はLINEがシミュレーションを提供しているので参考にしてください。
レイアウトについての詳細説明は割愛します。投稿イメージは最後の実行結果の章を確認してください。
投稿内容レイアウト部分
content = {
"type": "bubble",
"body": {
"type": "box",
"layout": "vertical",
"contents": [
{"type": "text", "text": "決算概要", "weight": "bold", "color": "#1DB446", "size": "sm"},
{
"type": "text",
"text": watchlist_doc["filerName"],
"weight": "bold",
"size": "xxl",
"margin": "md",
},
{
"type": "text",
"text": content_data["quarterly_accounting_period_content"],
"size": "xs",
"color": "#aaaaaa",
"wrap": True,
},
{"type": "separator", "margin": "xxl"},
{
"type": "box",
"layout": "vertical",
"margin": "xxl",
"spacing": "sm",
"contents": [
{"type": "text", "text": "業績", "weight": "bold"},
{"type": "text", "text": summary, "wrap": True},
{"type": "separator", "margin": "xxl"},
{"type": "text", "text": "業績変動要因", "weight": "bold", "margin": "none"},
{"type": "text", "text": "- マクロ"},
{"type": "text", "text": macro_factor, "wrap": True},
{"type": "text", "text": "- 業界"},
{"type": "text", "text": market_factor, "wrap": True},
{"type": "text", "text": "- 会社"},
{"type": "text", "text": company_factor, "wrap": True},
{"type": "separator", "margin": "xxl"},
{"type": "text", "text": "今後の展望", "weight": "bold"},
{"type": "text", "text": outlook, "wrap": True},
],
},
],
},
"styles": {"footer": {"separator": True}},
}
続きです。altTextの部分にはスマホの通知画面で見るときのメッセージを設定します。企業名を含めたメッセージにしておきます。
flexMessage = {
"type": "flex",
"altText": watchlist_doc["filerName"] + "の決算が出たみたいね",
"contents": content,
}
data = {"to": userId, "messages": [flexMessage]}
最後にLINEにリクエストを送信します。LINEへのリクエストは文字数制限がありちょこちょこエラーになったためエラーハンドリングをいれました。
try:
response = requests.post(lineMessageApi, headers=headers, data=json.dumps(data))
response.raise_for_status()
except requests.exceptions.RequestException as e:
print("Error occurred while sending message: ", str(e))
else:
if response.status_code == 200:
print("Message sent successfully.")
else:
print(f"Failed to send the message. HTTP status code: {response.status_code}")
print("Response body: ", response.text)
実行結果
最後に実行結果を添付します。ターミナル出力は下記のようになります。ウォッチリストにはDCMホールディングスのみを設定しました。

ターミナル出力
スマホでの通知メッセージは以下のようになります。
通知画面
最後にLINEでの投稿内容です。Flex Messageで設定したレイアウトで表示されています。きちんと要約内容が表示されています。

LINE画面
無事に動作しました!
課題点
いったん動くようになりましたが、課題はモリモリあります。
要約関連
- chatGPTに抽出させる内容の選定
- チューニング次第でもっと有益な内容を出せるはずです。
- 「業績サマリ」と「会社の展望」は重複した内容が書かれることも多いです。
- 「マクロの業績変動要因」「市場の業績変動要因」「会社の業績変動要因」に関してはだいたい1フレーズくらいで返ってきます。シンプルがゆえにほかの銘柄と似た内容になってしまい価値が薄くなります。
- チューニング次第でもっと有益な内容を出せるはずです。
- chatGPTのtemperature設定
- 全体的に要約内容が当たり障りのない内容で刺激に欠けます。
- 正直、見解は外れてもいいのでもっと攻めたことを言ってほしいです。この辺はtemperatureを上げると改善するかもしれません。
- 全体的に要約内容が当たり障りのない内容で刺激に欠けます。
報告書関連
- csvから抽出する内容の設定
-
経営者による財政状態、経営成績及びキャッシュ・フローの状況の分析以外の箇所も検討してもよさそうです。- 本格的に分析するのであれば数値は必要かと
-
- 有価証券報告書への対応
- やはり一番大事な有価証券報告書がないのは痛いです。
- 報告書のリアルタイム性
- そもそもEDINETのへの報告書提出タイミングは決算発表タイミングとは異なります。
- リアルタイム性を求めるのであれば「決算短信」を要約したいところです。
- 機械的な取得方法がわからず今回は断念しています。
その他関連
-
一度に大量の銘柄の更新があったときの挙動
- 現状だとLINEに連続投稿になります。
- 銘柄数が多いと動作が不安です。
- カルーセルにして1投稿に複数銘柄の要約を載せることも考えましたが、その場合は1投稿あたりの上限が問題になります。
- 現状だとLINEに連続投稿になります。
-
お姉さんの口調
- プロンプトでは
たまにちょっとからかうようなことも言ってきます。とか設定していますが、文字数的にこの設定が生きる機会があまりないです。寂しい。
- プロンプトでは
まとめ
いかがでしたでしょうか。改善点の多さにびっくりしました。
しかし、My秘書というにはまだまだで改善点は多いものの、一応動くようになりました。個人的な構想としては用途別のMy秘書を複数つくり、LINEの通知欄がMy秘書の投稿で溢れたらおもしろいなと思っています。
応用次第でかなり可能性を感じる分野だと思うので皆さんの参考になれば幸いです。
Discussion