VisionフレームワークとFoundation Modelフレームワークを活用してAI単語カードアプリを開発した話
こんにちは。iOSエンジニアのTomo🍎です。
最近、Foundation Modelsフレームワークに関する技術記事を執筆する機会がありました。この記事は技術書典で今後公開される予定です。 せっかくなので、技術記事を執筆するだけでなく実際に手を動かしてみようと思い、Foundation Modelsを活用したアプリを開発しリリースしました。本ブログでは、どのような技術スタックを使ってアプリを開発したか、実装の詳細をお話しします。
リリースしたアプリ
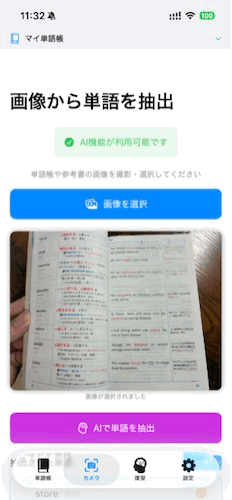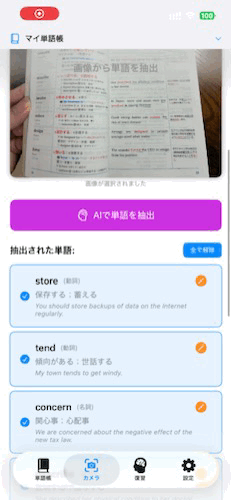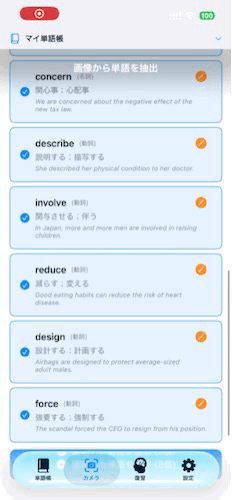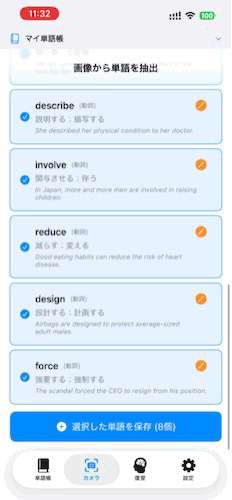
技術スタック
カメラで撮影した画像からテキストを抽出します。その後Foundation Modelsを使用してテキストから単語データを自動生成します。
- OCR(テキスト認識): Visionフレームワークによる文字認識
- AI単語抽出: Foundation Modelsによる英単語の自動分類と意味抽出
VisionフレームワークとFoundation Modelフレームワーの実装部分のみGithubで公開しています。
必要要件
- iOS 26.0以降
- Apple Intelligence対応デバイス
- Apple Intelligenceが有効になっていること
プロジェクト構成
VisionFoundationModel/
├── VisionFoundationModelApp.swift # アプリエントリーポイント
├── AvailabilityView.swift # Foundation Models可用性チェック
├── MainView.swift # メインUI
├── MainViewModel.swift # ビジネスロジック
├── ImagePickerCoordinator.swift # カメラ撮影
├── VisionTextRecognitionService.swift # OCRサービス
└── FoundationModelsService.swift # AI処理サービス
動作フロー
-
起動時:
AvailabilityViewでFoundation Modelsの可用性を確認 -
カメラ権限:
MainViewModelでAVFoundationを使用して権限をリクエスト -
写真撮影:
ImagePickerでカメラを起動し画像をキャプチャ -
OCR処理:
-
VisionTextRecognitionServiceが画像を前処理 -
VNRecognizeTextRequestでテキストを認識 - 日英混在テキストを正確に抽出
-
-
AI処理:
-
FoundationModelsServiceが認識テキストを受け取り -
LanguageModelSessionに構造化生成リクエストを送信 - AIが単語を分析・分類し、
VocabularyDataを生成
-
- 結果表示: 抽出された単語、意味、品詞、例文をUIに表示
Visionフレームワークによるテキスト検出の仕組み
Visionフレームワークとは
iOS11以降で利用可能なApple標準の画像解析フレームワークです。
OCR以外にも顔認識、物体追跡、画像分類など様々な分野で活用できます。
1. VNRecognizeTextRequestの設定
VisionフレームワークのVNRecognizeTextRequestを使用してテキストを認識します:
let request = VNRecognizeTextRequest { request, error in
// 認識結果の処理
}
request.recognitionLevel = .accurate
request.usesLanguageCorrection = true
request.revision = VNRecognizeTextRequestRevision3
request.automaticallyDetectsLanguage = false
request.recognitionLanguages = ["ja-JP","en-US"]
設定パラメータの詳細:
-
recognitionLevel = .accurate:
- 高精度モードを使用(
.fastより精度が高いが処理時間は長い) - 複雑なフォントや小さな文字でも正確に認識
- 高精度モードを使用(
-
usesLanguageCorrection = false:
- スペル自動修正を無効化
- 単語帳の情報を正確に読み取るため、OCRの生の結果を使用
- 誤修正による意図しない単語変更を防止
-
revision = VNRecognizeTextRequestRevision3:
- 最新のアルゴリズムを使用
- より高い認識精度と多言語サポート
-
recognitionLanguages = ["ja-JP","en-US"]:
- 日本語と英語を認識対象に設定
- 混在したテキストでも正確に認識
2. テキスト認識の実行
let handler = VNImageRequestHandler(cgImage: cgImage, options: [:])
try handler.perform([request])
3. 認識結果の取得
guard let observations = request.results as? [VNRecognizedTextObservation] else {
return
}
var recognizedStrings: [String] = []
for observation in observations {
guard let topCandidate = observation.topCandidates(1).first else {
continue
}
recognizedStrings.append(topCandidate.string)
}
let recognizedText = recognizedStrings.joined(separator: "\n")
VNRecognizedTextObservation:
-
topCandidates(n): 信頼度が高い上位n個の認識候補を取得- 引数
nは取得する候補の数を指定(topCandidates(1)で最も信頼度の高い1つの候補を含む配列を返す) -
.firstで配列から単一のVNRecognizedTextオブジェクトを取得
- 引数
Foundation Modelsによる単語分類の仕組み
Foundation Modelフレームワークとは
Foundation Modelフレームワークは、オンデバイスで動作する自然言語処理フレームワークです。iOS26.0以降で利用可能で、ユーザーのプライバシーを保護しながら、テキストの要約、抽出、分類などのタスクを高精度に実行できます
1. 構造化データモデルの定義
@Generableマクロを使用して、AIが生成すべきデータ構造を定義します:
@Generable(description: "Extracted vocabulary data from text")
struct VocabularyData {
@Guide(description: "List of vocabulary entries extracted from the text")
var entries: [VocabularyEntry]
}
@Generable(description: "A single vocabulary entry with word, meaning, and example")
struct VocabularyEntry {
@Guide(description: "The English word or phrase")
var word: String
@Guide(description: "The meaning or definition of the word in Japanese")
var meaning: String
@Guide(description: "An example sentence using the word in English")
var exampleSentence: String
@Guide(description: "Part of speech (e.g., 名詞, 動詞, 形容詞) in Japanese")
var partOfSpeech: String?
}
@Generableマクロの役割:
- AIに生成すべきデータ構造を明示的に指示
- 型安全性を保証しながら構造化出力を実現
-
@Guideで各フィールドの意味をAIに説明
2. インストラクション
let instructions = """
あなたは英語学習を支援するAIアシスタントです。
与えられたテキストから英単語とその意味、例文を抽出して単語帳データを作成してください。
重要:以下のルールに厳密に従ってください:
1. 英単語は基本形(原形)を使用する
2. 意味は日本語で簡潔に説明する
3. 例文は必ずテキスト内から抽出すること。新しく例文を作成してはいけない。テキストに含まれている英文をそのまま使用すること。
4. テキスト内に例文がない単語は、exampleSentenceを空文字列("")にすること
5. 品詞は日本語で記載する(名詞、動詞、形容詞 など)
6. 重複する単語は除外する
7. 一般的でない固有名詞は除外する
8. 最大10個の単語まで抽出する
"""
インストラクションの設計ポイント:
- 役割定義: AIの目的と責任を明確化
- 具体的な制約: 出力形式と品質基準を指定
- エラー防止: 望ましくない動作(例文の創作など)を明示的に禁止
- データ品質管理: 重複排除や固有名詞のフィルタリング
3. プロンプトの構成
let prompt = """
以下のテキストから英単語とその関連情報を抽出してください:
\(text)
重要な注意事項:
- 例文は必ずテキスト内に実際に存在する英文を使用してください
- 例文を新しく作成してはいけません
- テキスト内に例文がない場合は、exampleSentenceを空文字列("")にしてください
テキスト内の英単語を分析し、学習に適した単語を選んで単語帳データとして整理してください。
"""
プロンプトエンジニアリングの技法:
- OCRで認識したテキストを直接挿入
- 重要な制約を繰り返し強調(例文の扱いなど)
- タスクの最終目標を明確に記述
4. LanguageModelSessionによる処理
let session = LanguageModelSession(instructions: instructions)
let response = try await session.respond(
to: prompt,
generating: VocabularyData.self
)
return response.content
Foundation Modelsの処理フロー:
-
セッション初期化:
-
instructionsでAIの動作モードを設定 - コンテキストとして全体的なルールを保持
-
-
構造化生成リクエスト:
-
generating: VocabularyData.selfで出力型を指定 - AIは
@Generable定義に従ってJSONスキーマを認識
-
-
構造化データ生成:
-
VocabularyEntryの配列を作成 - 各フィールドに適切な値を設定
- 制約(最大10個、重複排除など)を適用
-
まとめ
本記事では、VisionフレームワークとFoundation Modelsフレームワークを組み合わせた英単語学習アプリの実装を解説しました。
現状、Foundation Modelsはオンデバイスで動作する特性もあり、要約、抽出、分類などの限られたタスクに対して高精度で実行できますが、高度な推論は得意ではありません。しかしながら、今後Apple Intelligenceの進化により、Foundation Modelsフレームワークでできることが増えていくのではないかと筆者は考えています。より複雑な推論タスクや多様なユースケースへの対応が進むことで、オンデバイスAIの可能性がさらに広がって欲しいと思っています。
以上、最後まで読んでいただきありがとうございました。
Discussion