Open6
Apache Icebergの仕組みを追ってみる
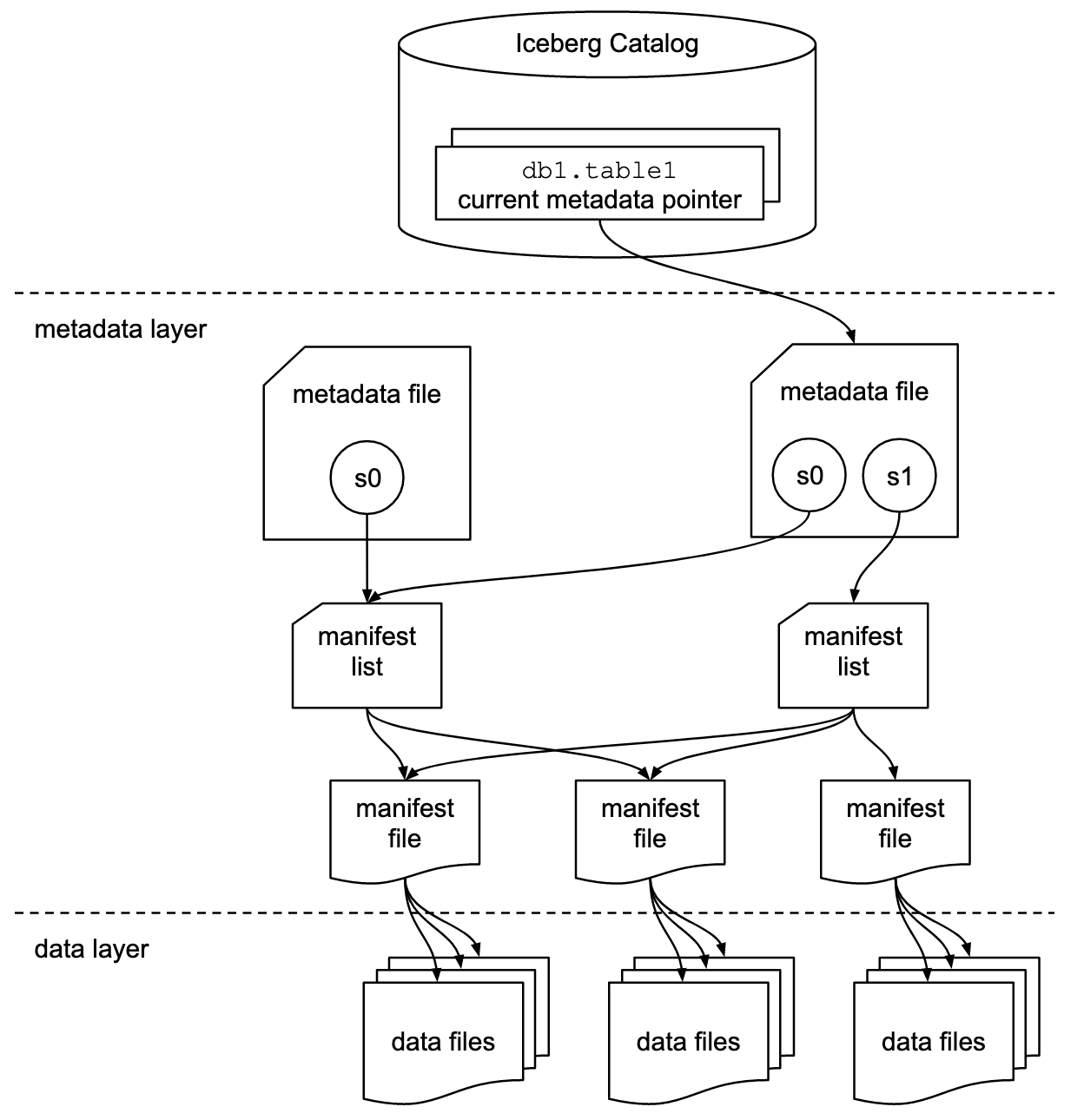
Apache Iceberg の全体図
3種類のファイルからなる木構造.
metadata file→manifest file→data filesと辿ることでデータを取得することができる.
各ファイルの仕様はこちら.
- metadata file
- manifest file
- data files
環境構築
下記 URL の docker-compose.yaml を使用して環境構築。
- Jupyter Notebook
- PySpark
- Apache Iceberg
- minio(S3互換のストレージ)
warehouse という空のバケットが作成される.

テーブル作成
以下,Jupyter Notebookで作業を進める.
table_typeにICEBERGを指定し,テーブルを作成する.
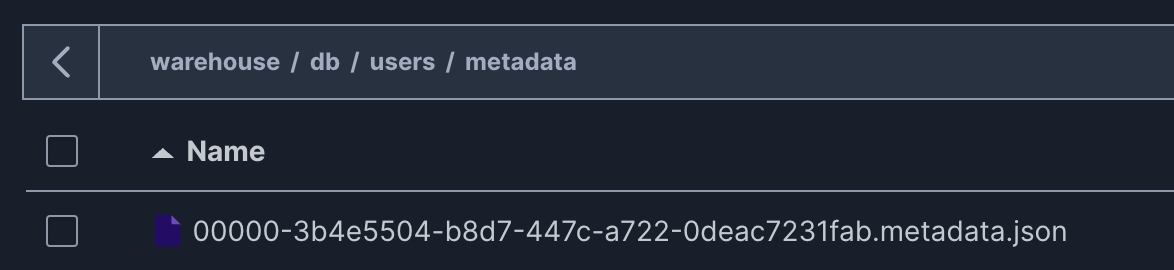
すると,バケットのdb/users/metadata/にmetadata file(00000-3b4e5504-b8d7-447c-a722-0deac7231fab.metadata.json)が作成される.
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Jupyter").getOrCreate()
spark
%%sql
CREATE TABLE demo.db.users
(
id bigint,
name VARCHAR(20)
)
TBLPROPERTIES ('table_type' ='ICEBERG')
metadata file
先ほど作成された metadata file は以下の通りである.
例えば以下のような情報が含まれている.
- テーブルの場所(location)
-
CREATE TABLEで作成したテーブルのスキーマ(schemas) - スナップショット
- ※ データがないので空配列
{
"format-version": 2,
"table-uuid": "a8bfeadc-2e40-4b7b-9d26-4582e3139fd7",
"location": "s3://warehouse/db/users",
"last-sequence-number": 0,
"last-updated-ms": 1739893865199,
"last-column-id": 2,
"current-schema-id": 0,
"schemas": [
{
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "id",
"required": false,
"type": "long"
},
{
"id": 2,
"name": "name",
"required": false,
"type": "string"
}
]
}
],
"default-spec-id": 0,
"partition-specs": [
{
"spec-id": 0,
"fields": []
}
],
"last-partition-id": 999,
"default-sort-order-id": 0,
"sort-orders": [
{
"order-id": 0,
"fields": []
}
],
"properties": {
"owner": "root",
"write.parquet.compression-codec": "zstd",
"table_type": "ICEBERG"
},
"current-snapshot-id": null,
"refs": {},
"snapshots": [],
"statistics": [],
"partition-statistics": [],
"snapshot-log": [],
"metadata-log": []
}
データの追加
%%sql
INSERT INTO demo.db.users
VALUES (1, 'bob'),(2, 'tom')
SELECT *
FROM demo.db.users
データを追加すると,db/users/metadata/配下に3つのファイルが新規追加される.
※ テーブル作成時にできた metadata file もそのまま残っている
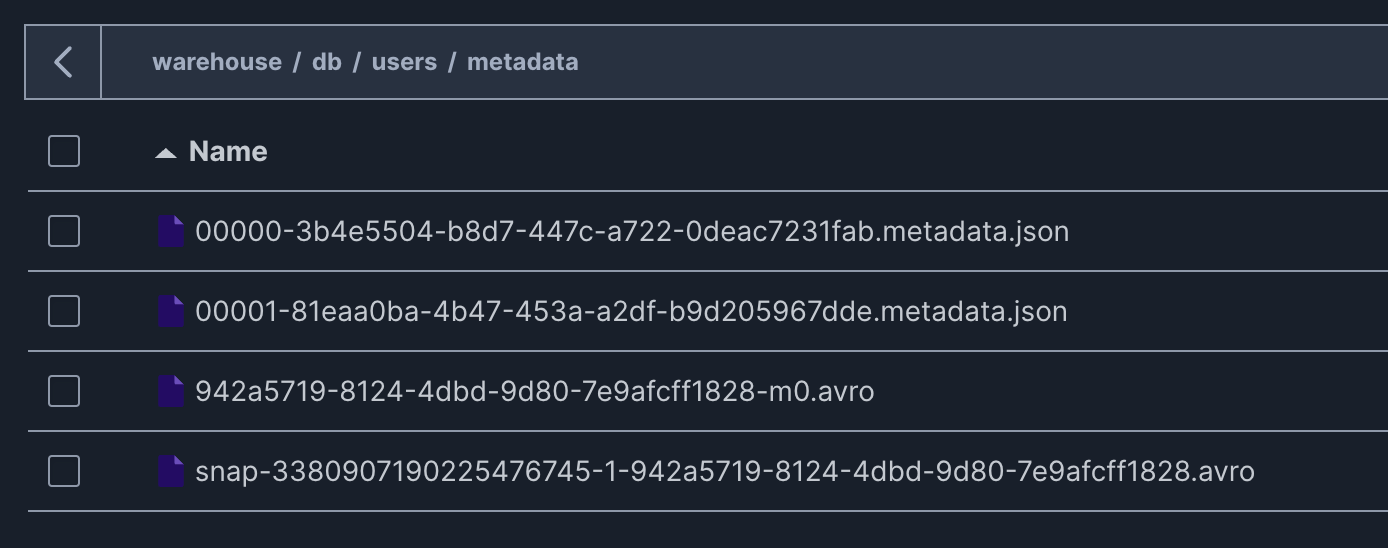
また,追加したデータはdb/users/data/配下にparquet形式のファイルで書き込まれている.