Open5
OSS-DB Sivver 受験までに学んだことの雑メモ
教科書に従い、知識は
- 実行環境の構築方法
- SQLによるデータベースの操作
- データベース定義
- ユーザー
- パフォーマンスチューニング
- バックアップとリストア
に分けてみる
1日目
こちらでインプット
様々なパラメータについて、意味・定義と、そのパラメータがシステムに与える影響まで理解すること
データベース定義
-
\dでデータベース定義が見れる -
\?でマニュアル見れる - tablespace ってなんだ
-
PostgreSQLでは、固定⻑⽂字列を選択することによるメリットはない。
- これめちゃ意外だった
-
必要以上にnumeric型を使⽤しない。特にOracleからの移⾏において、選択されるケースが多いがnumeric
型はデータサイズが⼤きく、処理速度が他の数値型に劣る点には注意が必要。 - CONCURRENTLYオプションてのがある
- DB のロックを発生させずに行えるらしい
- 処理時間が伸びる. ロングトランザクションがあると、なかなか終わらない
- 処理時間が長いということは、マシンに負担がかかるということ。ロックが発生しないとはいえサービスの質に影響が出る
- index 作成に失敗したら使えないindex が生まれる
- 適用範囲を指定して index を貼ることもできるらしい
- インデックスサイズを抑えて、パフォーマンスが向上する
- table space
-
IOが集中するテーブルやインデックスを⾼速・⾼可⽤なディスク配置することや、ディスクを分離し
てIO負荷を分散させるかどうかがポイントなる。
-
- XID なるものがあり、トランザクションの ID. 使い切ると DB が停止しかねないらしい
-
SELECT datname,age(datfrozenxid) FROM pg_database;で確認可能 -
VACUUM FREEZEでリセット -
VACUUMでも裏で FREEZE 処理は実行されているらしい - autovacume が ON なら自動で行う
-
パフォーマンスチューニング
- Explain で実行計画が見れる
- TODO: EXPLAIN の中身を知る
- index には種類がある
- btree
- hash
- gist
- sp-gist
- gin
- brin
- vacume ってのがある
- vacume と vacume full
- vacume を実行しただけでは、ファイルサイズ自体は変更されず、再利用箇所が残るので、追加データがあってもファイルサイズが増えにくい
-
select n_dead_tup from pg_stat_user_tables;で不要領域のサイズを確認できる
- analyze ってのがある
- 自動バキュームデーモンはデフォルトで起動する
バックアップ
- pg_dump, pg_dumpall
- pg_dump :
指定したデータベースや表だけをバックアップ - pg_dumpall :
すべてのデータベース、作成したユーザーなどの情報をまとめてバックアップ
- pg_dump :
2日目
インストール方法
- initdb はローカルホストのみ可能
- initdb 後はクラスタ作成者から様々なコマンドを受け付ける => セキュリティに弱い状態なので、ローカルマシンからに縛ることでセキュリティが向上する
標準付属ツールの使い方
createdb
dropuser
pg_ctrl
-m [f, i, s]
-
f: fast -> 処理を中断, クライアントを全て強制終了. トランザクションはロールバックする (デフォルト)
-
i : immidiate -> 処理を強制中断, クライアントを全て強制終了. 次回起動時に回復処理
-
s : smart -> 全てのクライアントが切断されてから終了. 全ての処理は正常に終了される
-
PostgreSQL 管理ユーザーのみが実行可能
createuser
- 小文字のオプションに対し、大文字のオプションは否定オプションになる関係
オプションとかいちいち覚えてられなくね
| command | |
|---|---|
| \l | 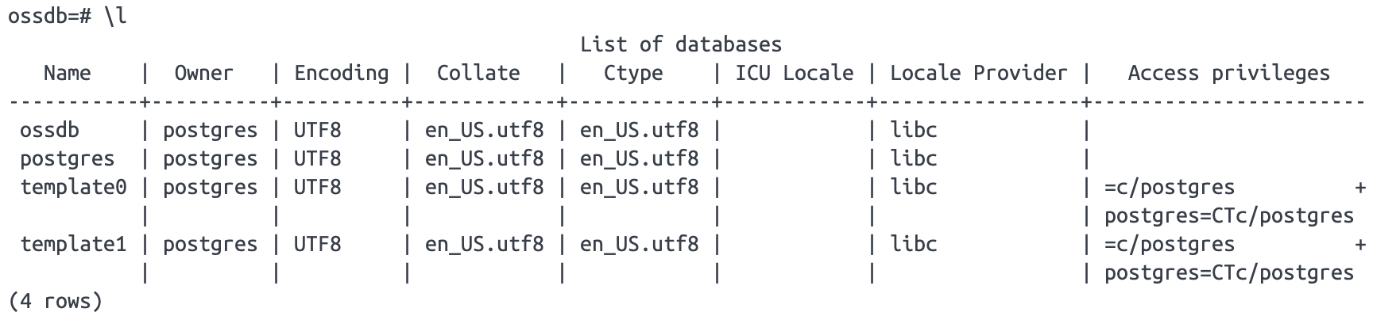 |
| \d |  |
| \dt |  |
| \du |  |
| \z, \dp |  |
| ? | メタコマンド一覧 |
\h |
SQL コマンドヘルプ |
\! [OSコマンド] |
[OSコマンド] 実行 |
SQL
- シーケンス
- マイナスを指定可能. 減らして連番を振る
- 最初に
nextval()を実行する必要がある
- プロシージャ
- SQL の結果をインターネット経路を経由せずに DB サーバーで処理できるので、ネットワーク負荷や処理速度が改善する
- ただし、乱用すると DB サーバーの負荷が高くなる
- 関数と違い、コミットやロールバックが可能
-
CALLで呼び出す
- 関数
-
https://www.postgresql.jp/docs/9.4/sql-createfunction.html
- TODO: いくつかの例でチェック
-
https://www.postgresql.jp/docs/9.4/sql-createfunction.html
3日目
OSS-DBの一般的特徴
- サポート期限
- メジャーバージョンの最初のリリースから 5年間
- ライセンス
- 再配布する際には、著作権とライセンス条文、無保証であることをドキュメントに記載すること
- BSD ライセンス.(Berkeley Software Distribution License) をベースにしている
SQL コマンド
- large オブジェクト
- 最大4TB
- pg_largeobject テーブルに格納され、OID で管理
- bytea と比較して、ストリームアクセスが可能で、部分的な読み書きが可能
- ただし、
lo_openなど専用の操作が必要であったり、孤立オブジェクトが発生しやすい
- using
- using を用いた取得結果は、それらの句が左に来るらしい
標準付属ツール
-
wal とは
-
pg_resetwal
- WAL の破損などによりサーバーが起動できなくなった時に利用
- WAL を破棄するので、実行後はデータ不整合が起きている可能性がある
-
psql
-
-U: ユーザー名 -
-h: ホスト名 -
-d: データベース名 -
-l: 全てのデータベースのリストを表示して終了する -
-c: コマンド実行結果表示して終了する -
-1 | --single-transaction: 複数のコマンドを1つのトランザクションとして実行
-
-
pg_ctrl
- ネットワーク経由で他のホストからは実行できない
-
pg_ctl stop
- デフォルトでは待ち時間は60秒
-
pg_ctl reload
-
-Dでクラスタ指定が必須
-
-
pg_ctl kill
- TERM : pg_ctl stop -m smart と同じ
- INT : pg_ctl stop -m fast
- QUIT : pg_ctl -m immediate
- HUP : pgctl reload
-
pg_config
- インストールされている PostgreSQL に関する情報を表示
-
pg_controldata
- initdb で初期化された DB クラスタ全体の制御情報を表示
-
pg_isready
- 接続状態の確認
-
createdb
- エンコーディング,ロケールを変更したいときは template0 を指定しないといけない. template0 にはこれらの設定が含まれていないため、ここから指定を行う
- 理由として腑に落ちん
-
メタコマンド
-
\d: テーブル,ビュー,シーケンス -
\dp | \z: テーブル, ビュー, シーケンス (アクセス権限付き) -
\dt: テーブル -
\l: データベース
-
設定ファイル
クラスタごとに作成される
pg_hba.conf
- クライアント認証
- データベースごとの設定可能
- カンマ区切りで複数の接続先データベースを指定できる
postgresql.conf
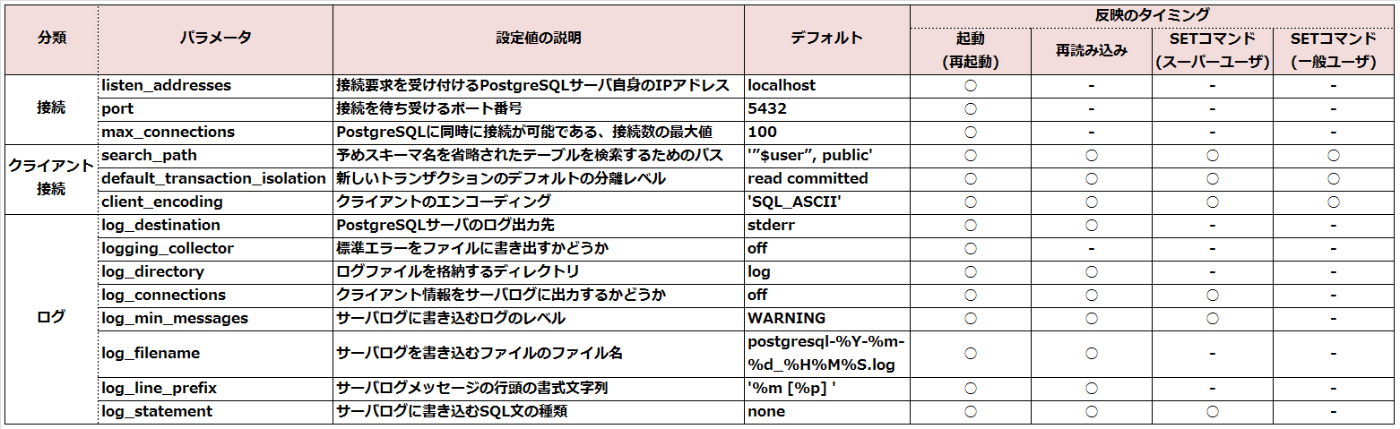
- コアとなる設定
- ログが出力されないのが初期値なので、実運用前に変更の必要がある
4日目
設定ファイル
postgresql.conf
- log_filename
- サーバーログを書き込むファイル
- log_line_prefix
- サーバーログの行頭につける情報
- logging_collector
- 標準エラーを出力するかどうか
- log_connections
- クライアントログを出力するかどうか
pg_hba.conf
- 上から順に評価される
- 後半に reject とかがあっても判定に使われない
{local | host} {database_name} {user_name} ...
pg_settings
-
SET- 設定値を変更するためのものらしい
- たしかに、更新は
UPDATE {} SET ...か。 なんか違和感あったけど、SET で始める構文はパラメータ更新らしい -
SET SESSION: postgresql サーバーへの接続セッション内だけ -
SET LOCAL: トランザクション内だけ
-
ALTER SYSTEM- 設定ファイルに書き込まれて永続化する
- スーパーユーザーのみ実行可能
-
SHOWSHOW {パタメータ名 | ALL}- 設定値を確認できる. MySQL の show とややこしいぜ
-
postgresql.auto.conf-
ALTER SYSTEMで変更した際はこちらのファイルに変更が入る - 「手動で書き換え」と「SQLで書き換え」の棲み分けができる
-
- view
- context カラム : パラメータ反映に必要な動作
- internal : クラスタ構築後は変更できない
- postmaster : サーバーの起動・再起動
- sighup : postgresql.conf の再読み込み
- superuser-backend : スーパーユーザーで新しいセッション開始
- backend : 一般ユーザーで新しいセッション開始
- superuser : スーパーユーザーで SET コマンド実行
- user : 一般ユーザーで SET コマンド実行
- 反映タイミングざっくり
- 接続:再起動必要
- クライアント接続:いつでも誰でも
- ログ:まちまち
- ログレベル
- INFO…ユーザから出力を要求された情報
- NOTICE…ユーザにとって役立つ情報
- WARNING…不適切なコマンド使用等に対するユーザへの警告
- ERROR…特定のコマンドを中断させたエラー
- LOG…データベース管理者にとって役立つ、パフォーマンスや内部の処理に関する情報
- FATAL…特定のセッションを中断させたエラー
- PANIC…全てのセッションを中断させた致命的なエラー
- INFO…ユーザから出力を要求された情報
- トランザクション分離レベル
- read uncomitted
- read committed [default]
- repeatable read
- serializable
基本的な運用管理方法
- 情報スキーマ
- データベースクラスタに関する情報の確認に使用する仕組み
- スーパーユーザが所有
information_schema- view と table のグループ
- 参照に特別な設定や権限は不要
- SQL 標準規格
- システムカタログ
- データベースの内部情報を格納したPostgreSQL固有のテーブル
pg_catalog- 情報スキーマより詳細を確認する際に利用
- SQL 標準規格ではない
- REINDEX
- インデックスを作り直し、インデックス内に生じた空領域を解消するコマンド
- CLUSTER
- インデックスを使用して、テーブルのデータを物理的に並び替えるコマンドです。これにより、データの検索処理が効率化されます
- システム情報関数・日付時刻関数
- postgresql としては「関数」なので、基本
()をつけたいところだが、SQL 標準がつけないので、しゃーなし()をつけないものがある。クソ -
current_user,current_timesamp,current_date,current_time, ...
- postgresql としては「関数」なので、基本
role
-
GRANT権限ON {テーブル名 | DATABASE データベース名 | SCHEMA スキーマ名} TO {ユーザー名 | PUBLIC}- 権限
- ALL : テーブル
- SELECT : テーブル
- INSERT : テーブル
- UPDATE : テーブル
- DELETE : テーブル
- TRUNCATE : テーブル
- REFERENCES : テーブル
- TRIGGER : テーブル
- CONNECT : データベース
- CREATE : データベース、スキーマ
- PUBLIC
- 全てのユーザーに付与する
- 権限
-
\zでAccess privilegesが見れる-
privilege: 特権 - r : SELECT
- w : UPDATE
- a : INSERT
- なぜ a ?
- d : DELETE
- D : TRUNCATE
- x : REFERENCES
- t : TRIGGER
-
vacuum
- autovacuum
- パラメータ変更は postgresql.conf の再読み込みが必要
- 統計情報の収集を無効に設定すると、autovacuum は使用できない
-
vaccumedb--all-
--full- 排他ロックがかかる
-
--analyze|-z -
--analize-only|-Z- 不要領域の回収はせず、統計情報の収集・更新のみ
関数
- 文字列検索
- LIKE : パターンマッチング
- ILIKE : 大文字小文字区別しない
-
%,_を使用 - 文字列全体
- SIMILAR TO : 正規表現
- 文字列全体
- POSIX
-
~: 大文字小文字区別,*: 大文字小文字区別しない,!: 否定 - 部分文字列
-
- LIKE : パターンマッチング
- 日時・タイムスタンプの関数
- extract (フィールド from {タイムスタンプ値 | インターバル値} )
- date_part ('フィールド', {タイムスタンプ値 | インターバル値} )
- age (日付, 日付)
トランザクション
- トランザクションのモード
- テーブルロック
- LOCK [TABLE] テーブル名 IN ロックモード MODE;
- EXCLUSIVE: 他のトランザクションに対して、読み取りのみ許可する
- ACCESS EXCLUSIVE [デフォルト] : 全ての処理をブロック
- 行ロック
- SELECT カラム名 FROM テーブル名 WHERE 条件 FOR { UPDATE | SHARE};
- 排他ロック : 全て禁止
- 共有ロック : 読み取りのみ
- テーブルロック
- 分離レベル
-
READ UNCOMMITTED: 🚫 -
READ COMMITTED[default] : ✅ Diry Read -
REPEATABLE READ: ✅ Diry Read ✅ Fazzy Read -
SERIALIZABLE: ✅ Diry Read ✅ Fazzy Read ✅ Fantom Read
-
- [質問] 分離レベルの指定って、書き込み側が注意して行うの?読み取り側が注意して行うの?
- ABORT
- ROLLBACK と同じ
- SAVEPOINT [name]
- 同じ [name] で SAVEPOINT を宣言すると、上書きされる。ただし、古い SAVEPOINT は残っていて、
RELEASE SAVEPOINT [name]すると、上書き前に戻る
- 同じ [name] で SAVEPOINT を宣言すると、上書きされる。ただし、古い SAVEPOINT は残っていて、
- SET
- トランザクション内での
SETは、セッションの設定として保存される. 意外だ - でも
SETの振る舞いが、トランザクション内外で変化するほうが不自然か
- トランザクション内での
- トランザクションコマンド
-
BEGINorSTART TRANSACTION -
COMMITorEND -
ROLLBACKorABORT
-
postgresql 関係ないやつ
- syslog
- すでに経験しているのかしら。