はじめに
本日(2025/06/25)、Swallow ProjectよりLlama-3.1-Swallow-8B-Instruct-v0.5、Llama-3.1-Swallow-8B-v0.5をリリースさせていただきました。
チャットボット等の用途で利用される場合は-InstructとついているLlama-3.1-Swallow-8B-Instruct-v0.5を利用してください。
今回のモデルもこれまでのSwallowシリーズのモデルと同様にLlama-3.1 LicenseおよびGemmaライセンスに抵触しない限り商用利用可能なモデルとなっています。

本モデルの開発は、産総研、東京科学大学 岡崎研究室、横田研究室の合同プロジェクトにて行われました。
今回リリースされたLlama-3.1-Swallow-8B-v0.5は、Open LLMとして競争力のあるモデルのうちの1つであるQwen-3-8Bよりも日本語生成能力(few-shotタスク)の平均で1ポイント弱低い性能となっています。しかしながら、Qwen-3-8Bは、36Tトークン学習を行っているのに対し、我々のモデルは昨年Meta社より公開されたLlama-3.1-8B-Instructより約210Bトークンの継続事前学習(Continual Pre-Training)を行うことで、この性能を達成しています。
以下では、Llama-3.1-Swallow-8B-v0.5をどのように開発したのかについて解説を行います。
リリースモデル概要
ベースモデル
日本語性能
以下に示すように、オープンなLLMとして競争力を有するQwen-3-8Bよりもやや低い(1ポイント弱)ものの日本語スコアの平均(Ja Avg)では、Llama-3.1-Swallow-8B-v0.5はかなり高い水準を達成しています。
しかしながら、MGSM(算術推論)、JMMLU、JHumanEval(コード生成)においてはQwen-3-8Bとの差が顕著になっています。
MGSM、JHumanEvalについては、後述するように今回のモデルで取り入れた数学、コードコーパスの改善が、英語で書かれた数学データ、英語でコメントが記述されているコードデータを中心にしていたため、日本語における数学、コード能力が十分に強化できなかったことがこのような結果の要因の1つとして考えられます。
| Model | JCom. | JEMHopQA | NIILC | JSQuAD | XL-Sum | MGSM | WMT20-en-ja | WMT20-ja-en | JMMLU | JHumanEval | Ja Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4-shot | 4-shot | 4-shot | 4-shot | 1-shot | 4-shot | 4-shot | 4-shot | 5-shot | 0-shot | ||
| EM acc | Char-F1 | Char-F1 | Char-F1 | ROUGE-2 | EM acc | BLEU | BLEU | EM acc | pass@1 | ||
| Qwen2.5-7B | 0.924 | 0.459 | 0.426 | 0.907 | 0.216 | 0.616 | 0.229 | 0.199 | 0.634 | 0.507 | 0.512 |
| Llama 3.1 8B | 0.845 | 0.461 | 0.405 | 0.895 | 0.179 | 0.356 | 0.221 | 0.210 | 0.479 | 0.320 | 0.437 |
| Qwen3-8B-Base | 0.927 | 0.537 | 0.475 | 0.912 | 0.207 | 0.716 | 0.241 | 0.215 | 0.689 | 0.595 | 0.551 |
| Llama 3.1 Swallow 8B v0.2 | 0.911 | 0.510 | 0.627 | 0.892 | 0.198 | 0.464 | 0.296 | 0.233 | 0.525 | 0.336 | 0.499 |
| Llama 3.1 Swallow 8B v0.5 | 0.952 | 0.513 | 0.657 | 0.910 | 0.217 | 0.572 | 0.294 | 0.232 | 0.590 | 0.491 | 0.543 |
英語性能
Llama-3.1-Swallow-8B-v0.5の英語平均スコアは、Llama-3.1-8BやLlama-3.1-Swallow-8B-v0.2よりも高く日本語能力だけでなく、英語能力についても強化することに成功しています。
特に、数学とコード能力については、大幅に改善されており、GSM8K(算術推論)ではv0.2より17.8ポイント改善、HumanEval(コード生成)ではv0.2より19.1ポイントの改善がなされています。
HumanEvalに至ってはQwen-2.5-7Bと並ぶ性能を示しており、後述する数学とコードデータセットの高品質化の成果が確認できます。
しかしながら、非常に競争力があるQwen3-8B-Baseと比較するとMMLU、GSM8K, MATH, HumanEvalにおいて依然として差があり、トップのOpen modelとの差分があらわになっています。
| Model | OpenBookQA | TriviaQA | HellaSWAG | SQuAD2.0 | XWINO | MMLU | GSM8K | MATH | BBH | HumanEval | En Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 4-shot | 4-shot | 4-shot | 4-shot | 4-shot | 5-shot | 4-shot | 4-shot | 3-shot | 0-shot | ||
| Acc | EM acc | Acc | EM acc | Acc | Acc | EM acc | CoT EM Acc | CoT EM Acc | pass@1 | ||
| Qwen2.5-7B | 0.392 | 0.601 | 0.600 | 0.618 | 0.888 | 0.742 | 0.832 | 0.510 | 0.562 | 0.554 | 0.630 |
| Qwen3-8B-Base | 0.382 | 0.618 | 0.594 | 0.602 | 0.903 | 0.765 | 0.855 | 0.622 | 0.655 | 0.669 | 0.667 |
| Llama 3.1 8B | 0.380 | 0.702 | 0.609 | 0.503 | 0.907 | 0.651 | 0.507 | 0.214 | 0.616 | 0.364 | 0.545 |
| Llama 3.1 Swallow 8B v0.2 | 0.382 | 0.651 | 0.596 | 0.513 | 0.904 | 0.622 | 0.521 | 0.228 | 0.605 | 0.366 | 0.539 |
| Llama 3.1 Swallow 8B v0.5 | 0.372 | 0.665 | 0.597 | 0.536 | 0.900 | 0.666 | 0.699 | 0.390 | 0.589 | 0.557 | 0.597 |
改善点
数学 & コード
実は今回のモデルの数学とコード能力の改善は1ヶ月ほど前(2025/5中旬)にRewriting Pre-Training Data Boosts LLM Performance in Math and Codeという題名で論文を公開させていただいた手法により高品質化したコード、数学データを利用して学習することで達成されています。
こちらの論文解説については別途解説ブログを書く予定ですが、ここでは非常に簡単に解説を行います。
従来のOpen Codeデータセットは品質フィルター等でコードデータをフィルタリングすることが主でした。また、LLMを使ってデータを生成するということは行われていても、Pre-Trainingデータで用いられるような数Bトークン程度の量を作ろうとするとseedや生成時のパラメータ、生成に使うLLMを変えるといった程度では、データの多様性が担保できずPre-Trainingで利用する意味での実用水準に達していませんでした。
そこで、我々は、フィルタリングによりある程度キレイなコードデータを収集した後、LLMに"キレイな"コードに書き直すようにStype-Basedなコードの書き直し(Rewriting)を行わせ、さらにアルゴリズム等を考慮した効率化されたコードに書き直すように2段階で指示を与えることで、高品質化を行いました。
ここで、重要なのは、元のコードデータが十分に多様な背景、用途にあわせて記述されているため、単に合成データを作る場合とは異なり、十分な多様性が担保されるということです。
詳細は論文を参照いただく必要がありますが、我々の手法を使うことで以下のように、同条件で比較するとLLMのコード能力を飛躍的に向上させるコーパスを構築することができます。
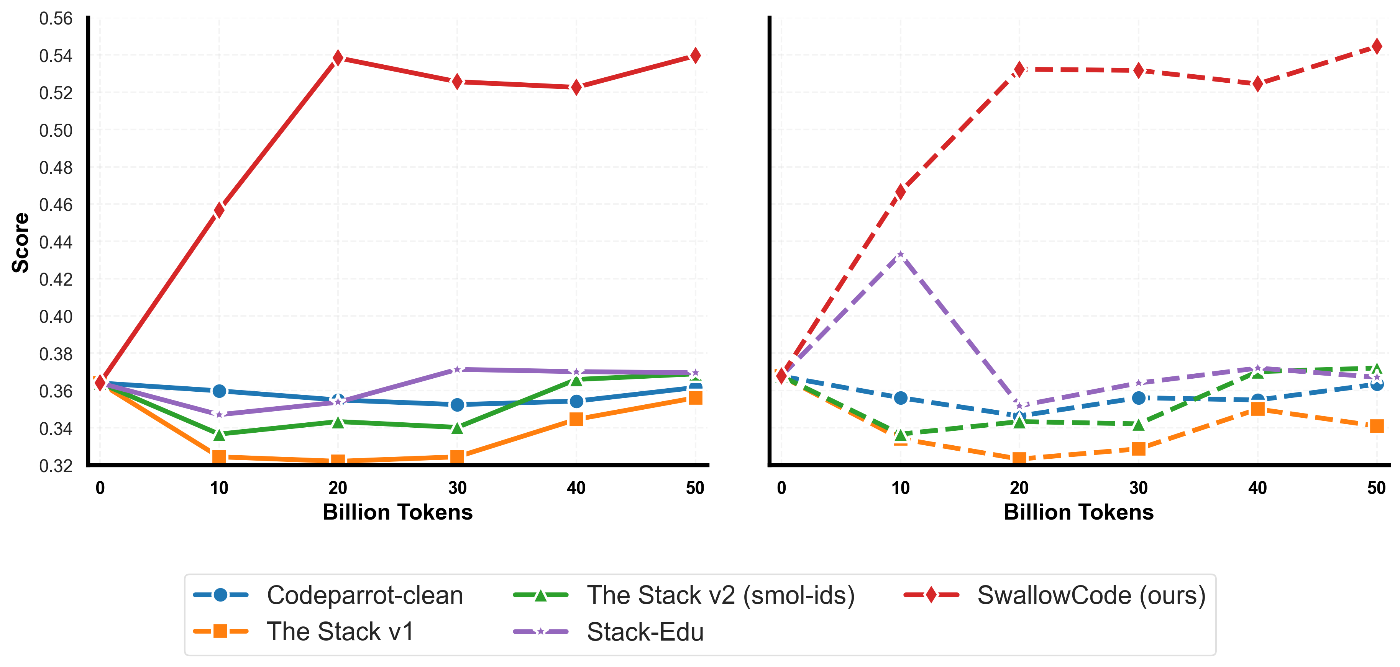
この手法により構築したコーパスを我々は誰でも利用できるように、SwallowCode, SwallowMathとして公開しています。
日本語能力
Llama-3.3-Swallow-70B-v0.4で採用したように、以下の3種類のSwallowCorpus-v2を利用しました。
- Swallow Corpus v2 Wikipedia分類器 Top10%
- Swallow Corpus v2 Llama 3.1自動アノテーション分類器 Top10%
- Swallow Corpus v2 Gemma-2-27b-it によるQA形式合成
詳細は以下の論文をご覧ください。
Swallow コーパス v2: 教育的な日本語ウェブコーパスの構築
また、Llama-3.3-Swallow-70Bのプロジェクトページにも記載があります。
学習環境
学習設定
以下に実験で利用した学習設定を記します。
| LR | minLR | Global Batch Size | grad clip | weight decay |
|---|---|---|---|---|
| 2.5E-5 | 2.5E-6 | 1024 | 1.0 | 0.1 |
| AdamW beta1 | AdamW beta2 | AdamW epsilon |
|---|---|---|
| 0.90 | 0.95 | 1E-8 |
学習ログ
Llama-3.1-Swallow-8B-v0.5の継続事前学習(210Bトークン)における学習ログを抜粋して記します
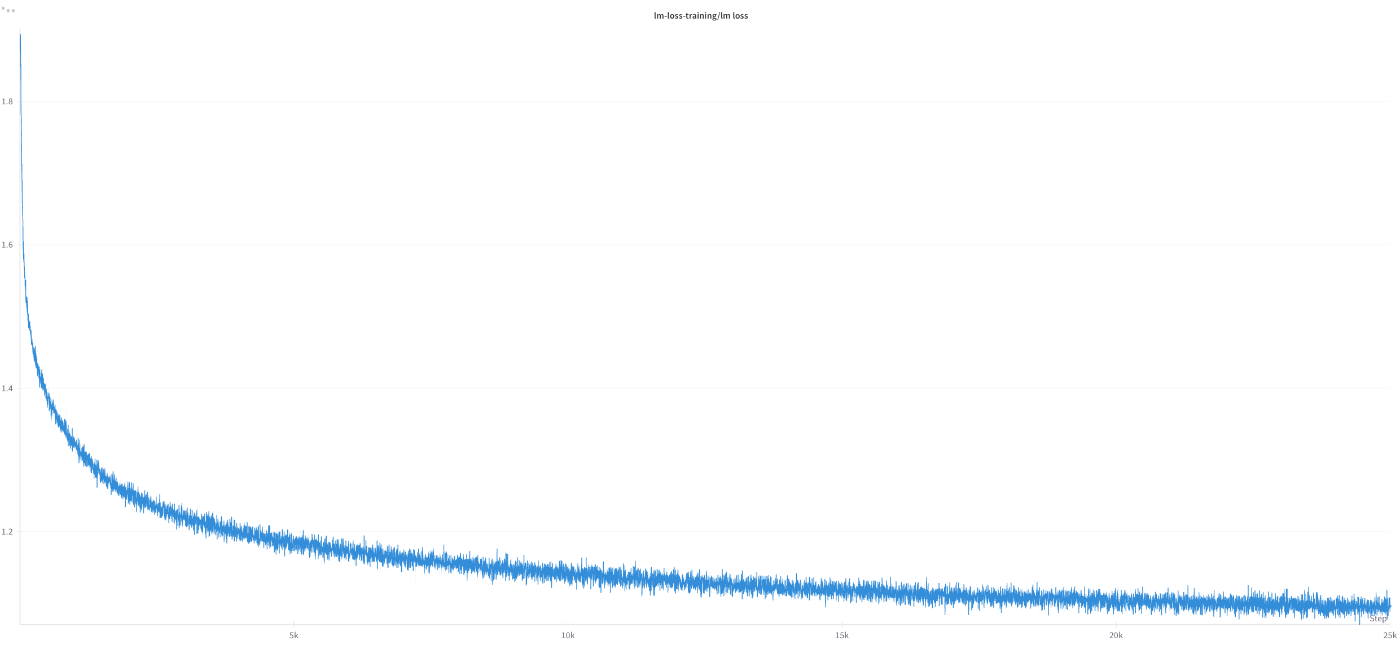
Training Lossの推移

Gradient Normの推移
予備実験
採用するコーパスの検討や、ライブラリの整備等に以下の2つの環境を利用しました。
- 東京科学大学 TSUBAME 4.0 H100(94GBx4)
- ABCI 3.0 H200(141GBx8)
スパコンの運用、整備に携わっていただいている方々にこの場を借りて、お礼申し上げます。
本実験
Llama-3.1-Swallow-8B-v0.5の継続事前学習には、AWS Sagemaker HyperPod p5e.48xlarge(H200 Instance)を利用しました。
Sagemaker HyperPodは、TSUBAMEやABCIのような環境を簡単に構築することが可能なサービスであり、非常に簡単に環境の構築、運用を行うことができました。
前回リリースを行いました Llama-3.3-Swallow-70B-v0.4の開発の際もAWS Sagemaker HyperPodを利用させていただいたのですが、その際の知見をAWSさんの方からブログとして公開いただきましたのでこちらもあわせてどうぞ (英語です)
今後の開発計画
Llama-3.1-Swallow-8B-v0.5の開発自体は2025年4月時点で完了していたこともあり、現在v0.6(仮名称)に向けて検証を進めています。
v0.6では引き続き、複雑な推論(Reasoning) に欠かせないとされる数学とコード能力の確保を中心にQwen-3を超える日本語性能の実現とより高い英語性能獲得に向けて開発を進めています。
すでに数学とコードについては改善の見込みがある程度立っており、できるだけ早くリリースすることができるように実験を行っています。
また、Swallowの産業用利用を見据えて、ドメイン知識を継続事前学習時点から入れる試みを検討しています。
加えて、将来的なモデルパラダイムの変化に順応するためにTransformer Denseアーキテクチャにとらわれず、他のアーキテクチャでの予備実験を小規模に行っています。
(世の中に流行りに流さないよう、慎重に検証を行っています)
今後も商用利用可能なオープンモデルをリリースしていきますので、Swallow Projectをよろしくお願いいたします。

Discussion