OpenAIのAssistants APIなどを動かして関心するスレ
まずはここらへんの公式を眺めていく
OpenAI Dev Day の発表の概要をある程度読んで上で、GPT関連の新機能(特にAssistants API)を実務にどの様に利用するか妄想して関心するスレッドを連ねていきます。
Assistants APIの課金
ちなみに、料金形態はgptモデルのtoken課金とは別に Assistants APIのCode interpreterや Retrievalは別の方法で課金が走るらしい。
Code Interpreterでコード実行できるのいいね
Assistants APIでCode Interpreterが利用できることで下記あたりは公式でクリアしている。
数値計算や数を数えることができない問題一旦出来るものと思って機能を提案してよい。
- 正確な文字数カウント(Pythonで
len()をする) - 正確な単語の出現カウント(Pythondで
text.count("単語")をする) - 正確な計算(Pythonでコードを書いて計算する)
Thredsについて
スレッドとメッセージ履歴について
Assistants APIはスレッドという概念で会話の履歴を管理してくれるらしい。
今までは完全にステートレスだったけれど、公式がメモリ管理を行える仕組みを提供してくれた。
Threads and Messages represent a conversation session between an Assistant and a user. There is no limit to the number of Messages you can store in a Thread. Once the size of the Messages exceeds the context window of the model, the Thread will attempt to include as many messages as possible that fit in the context window and drop the oldest messages. Note that this truncation strategy may evolve over time.
履歴削除の感想
LangChain等で一定のラインを超えた時に会話の履歴を消す方法が提供されていたが、公式でも一定ラインを超えたら古いものから削除してくれるらしい。
個人的には、最初と直近が一番重要な情報を持っている事が多いので、最初と直近だけAPI送信時に渡す実装をしていたので、それに近い物を実現できると良いなと思っている。
例えば、「重要な設定の要約」みたいな履歴と、「直近の会話の履歴」みたいなのに分けて管理できたら嬉しいのにな〜という感想。まあ、あまり長い形式のチャットはToknesを沢山消費するので商用化でやりたくないから、欲しければ自分で実装しますって感じかな。
instructions parameterでアシスタントの性格・設定を指定できる
今までSystemMessageとして初期に渡していた設定項目を別に用意してくれている!
これなら履歴は直近だけでも十分にworkしそう。
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
model="gpt-4-1106-preview",
instructions="additional instructions",
tools=[{"type": "code_interpreter"}, {"type": "retrieval"}]
)
実際にAssistants APIを動かしてみる
発見
- threadsとassistantが完全に分離している。
- threads中にassistantを変える事もできそう
- GPTsではできないアプローチもできる!
- subscribe機能は現時点では提供されていない
- 近日中に公開予定と書いてある
- それまでは
whileでn秒ごとにループして取得するなどで対応
とりあえず動くコード
from openai import OpenAI
import config
import time
class AssistantsAPI:
def __init__(self):
self.client = OpenAI(
api_key=config.OPENAI_API_KEY
)
def call(self):
print("実行")
print("アシスタント作成")
assistant = self.client.beta.assistants.create(
name="Math Tutor",
instructions="You are a personal math tutor. Write and run code to answer math questions.",
tools=[{"type": "code_interpreter"}],
model="gpt-4-1106-preview"
)
thread = self.client.beta.threads.create()
print("メッセージ作成")
message = self.client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content="次の計算をして欲しい `3x + 11 = 14`. この式を解いてください。"
)
print("実行")
run = self.client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
instructions="Please address the user as Jane Doe. The user has a premium account."
)
# Runのステータスが「completed」になるまで繰り返し確認
while not run.status == "completed":
run = self.client.beta.threads.runs.retrieve(
thread_id=thread.id,
run_id=run.id
)
time.sleep(1) # 0.1秒待機
print(run.status) # 現在のステータスを表示
# スレッドに追加されたメッセージ全てを取得
messages = self.client.beta.threads.messages.list(
thread_id=thread.id
)
role_value = []
# 各メッセージのroleとcontentを取得
for thread_message in messages.data:
role = thread_message.role
for content in thread_message.content:
content = content.text.value
role_value.append((role, content))
# reverseメソッドでリストの順番を逆にする
role_value.reverse()
# メッセージの内容を表示
for role, value in role_value:
print(f"{role} : {value}")
RetrievalでLangChainやその他ツールでベクトル化していた検索が公式に!
Retrievalでナレッジベースとして上げておいたファイルから検索して応答させるのはとてもいい!
LangChainとその他ツールでテキストをchunkしてベクトル化してベクトル検索させていたものが公式でできる!
そして、ファイルはassistantに紐づけて、assistantから切り離す形で削除するんですね。参考
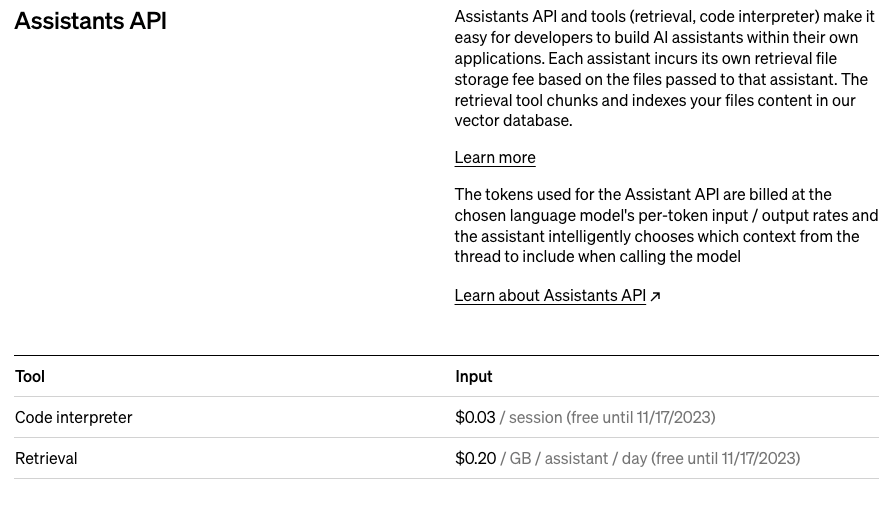
課金周り
Code Interpreter や Retrieval は利用しているモデルのtokensベースの課金とは別に発生する。
Code Interpreter
- sessionごとの課金(1セッション0.03$)
- 一度Code Interpreterを動かすと、assistantごとに1セッション発生する
- 1セッションは1時間有効
- 課金イメージ
- 1つのassistantが1時間に3回使えば、1セッション(0.03$)
- 2つのassistantが1時間に3回使えば、2セッション(0.06$)
- 1つのassistantが3時間で3回使い、有効時間が切れて、2セッション発生していれば(0.06$)
Retrieval
- 日数、アシスタント、ファイルサイズで計算される
複雑なので引用
検索料金は、アシスタント1人あたり1日1GBあたり0.20ドルです。アプリケーションが1日1GBのファイルを保存し、検索の目的で2人のアシスタント(たとえば、顧客対応アシスタント#1と社内従業員アシスタント#2)に渡す場合、この保存料は2回請求されます(2 * $0.20/日)。この料金は、特定のアシスタントから知識を検索するエンドユーザとスレッドの数によって変わることはありません。
有益な情報をありがとうございます。この課金周りについてと、制作案件でご相談したいことがあるのですが、どのようにコンタクトさせて頂ければ良いでしょうか?