今更YOLO11をやってみようー #1
雑談
最近珍しさで買った、ロイヤルミルクティー味のプロテインを飲んでるのですが、めちゃくちゃ美味しくてリピートしまくっています。
プロテインだけど普段から飲めるレベルに美味しい!
でも、飲み過ぎるとお腹壊すので悲しいです…
こんな感じで気になった食べ物とかに色々チャレンジして自分が美味しいと思えるものをたくさん発見しようーって思ってます。
あ、あとは英語の勉強をちゃんとしたいのですが、なんかいい感じの英会話の練習方法ありませんかね?
海外でも一人で旅できるくらいにはなりたい
何するの?
画像系のタスクを行う際に、物体検出アルゴリズムであるYOLOの知識は欠かせません。
最近、YOLOを使ってなくてYOLO11とはお友達になれてないため、ここでお友達になろうと思います。
なんかドキュメントを見てみると様々なタスクができるそうです。
その中でも、今回は物体検出と分類のタスクに焦点を当てて実装していきます。
ちょっと量多いかもなのでタスクごとにページを分けます。
- 物体検出
- 分類
お世話になる公式ドキュメント:
今回の技術的な内容
- YOLO11の物体検出の使い方
- 学習済みモデルの使用方法
- ファインチューニングの方法
YOLO11とは...
YOLO11は、Ultralyticsが開発した最新のリアルタイムオブジェクト検出モデルです。
YOLO11の主な特徴として、以下があげられます:
-
高精度・高効率
前バージョンのYOLOv8と比較して、パラメータ数を22%削減しながらより高い精度を実現 -
多様なタスクに対応
物体検出だけでなく、分類、インスタンスセグメンテーション、ポーズ推定など幅広いタスクをサポート -
改善されたアーキテクチャ
バックボーンとネック部分の構造が最適化され、より効率的な特徴抽出が可能
また、YOLO11nからYOLO11xまでの複数のモデルサイズが用意されており、用途に応じて選択できます。
エッジデバイスからクラウドプラットフォームまで幅広い環境での利用を想定して設計されているのもとても良いです!
他のモデルとの性能比較は以下の通りです!
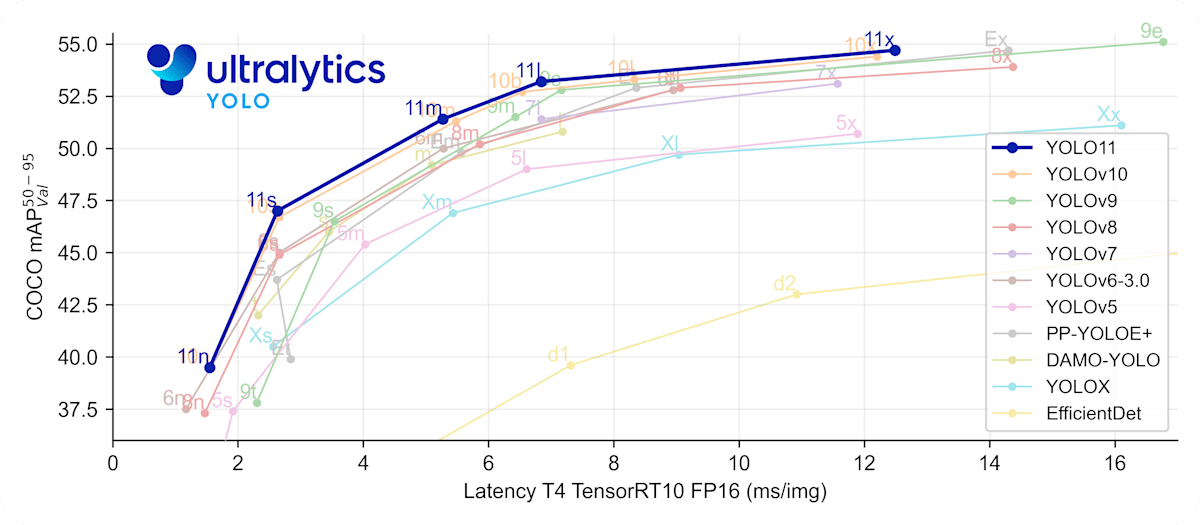
参考: 公式ドキュメント(https://docs.ultralytics.com/ja/models/yolo11/)
物体検出の実装
YOLO11は、複数のモデルサイズがあるが、今回は一番小さいYOLO11nを使用します。
このYOLO11は以下のデータで事前学習されているそうです。
- 分類タスク: ImageNetデータセット
- その他のタスク: COCOデータセット
実行環境
- M2 MacBook Air (24GBメモリ、10コアGPU)
- python 3.12.7
- ultralytics: 8.3.175 etc...
学習済みモデルの使用
COCO8データセットで学習済みのYOLO11nを使用してみる!
COCO8データセットはdatasetsとしてプロジェクトルートディレクトリにダウロードしてください! (付録に詳細あり)
コードは主に2つの要素だけでできています。めっちゃシンプルで良き。
- モデルの読み込み
- 物体検出の実行
でも、少し予測の際のパラメータが多いのでドキュメントを見るのをお勧めします!日本語のドキュメントがあって、他のに比べてめっちゃ読みやすいです。
(参考: https://docs.ultralytics.com/ja/modes/predict/)
主なコードは以下のようになります。なお、コード中の自作関数はgithubのコードを参照してください。
import os
import sys
from typing import List
from ultralytics import YOLO
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from dataloaders import load_coco8_image_path_list
from utils import save_result_to_json
# 保存先設定
RESULT_DIR_PATH = "results/detection/trained"
RESULT_BOXES_DIR_PATH = "results/detection/trained/boxes"
# 実行デバイス
DEVICE = "mps"
def pred_coco():
""" COCO8データセットに対する予測を行うメソッド """
# モデルの読み込み
model = YOLO("yolo11n.pt")
# COCO8の画像パス
image_path_list: List = load_coco8_image_path_list()
# 物体検出
results = model.predict(
# 画像パス
source = image_path_list,
# 予測設定
imgsz = 640, # 画像サイズ tupleでも指定可
conf = 0.25, # 検出の閾値
device = DEVICE, # 使用デバイス
# 保存設定
save = True, # 保存するかのフラグ
project = RESULT_DIR_PATH, # 結果の保存先のディレクトリ
name = "images", # 結果の保存先のサブディレクトリ名
exist_ok = True, # 結果の保存先が存在する場合は上書きする
)
# 結果の保存
for result in results:
save_result_to_json(result, RESULT_BOXES_DIR_PATH)
if __name__ == "__main__":
pred_coco()

物体検出の結果の一例
ファインチューニング
COCO8データセットで学習済みのYOLO11nをHomeObjects-3K データセットでファインチューニングしてみる!
HomeObjects-3K データセットとは、室内環境での物体検出に特化したデータセットであり、約3000枚の画像に、ベッド、ソファ、椅子、テレビ、ノートパソコンなど12種類の家庭用品がアノテーション付きで含まれている。このデータセットを使用する分野として、スマートホーム、ロボティクス、AR分野があります。
なんか、室内環境での物体検出というトピックが最近Geminiに物体検出の機能が追加されたときにロボット制御で話題になってたような気がします。
このページで一部紹介されているロボットアーム制御みたいな話
そんなことは置いといて、室内環境での物体検出をしたいとかではなく、約3000枚の画像の少量のデータセットであるということで、ローカルでも学習しやすいと思ったため使用します笑
ファインチューニングも主に3つの要素だけでできています。めっちゃシンプルで良き。
やっぱり、ライブラリは偉大です
- モデルの読み込み
- 学習
- 物体検出の実行
過学習防止や様々な環境に適応できるようにデータオーグメンテーションをしっかりとしようと思います!
(ただパラメータいじるだけですが...)
主なコードは以下のようになります! 学習済みモデルを使用するコードは付録を参照してください。
import os
from ultralytics import YOLO
# 保存先設定
RESULT_DIR_PATH = "results/detection/fine-tuning"
# 実行デバイス
DEVICE = "mps"
def fine_tuning() -> YOLO:
"""
モデルをHomeObjects-3Kでファインチューニングするメソッド
Returns:
YOLO: ファインチューニング済みモデル
"""
# モデルの読み込み
model = YOLO("yolo11n.pt")
# データオーグメンテーションの設定
data_augmentation_config = {
# カラー変換
"hsv_h": 0.01, # 色相調整
"hsv_s": 0.0, # 彩度調整
"hsv_v": 0.5, # 明るさ調整
# 幾何変換
"degrees" : 0.0, # 回転 (0.0 ~ 180)
"translate" : 0.25, # 画像をシフト
"scale" : 0.5, # 拡大縮小
"shear" : 5, # x軸とy軸の両方に沿って歪ませる
"perspective": 0.0, # 遠近法変換
# 反転
"flipud": 0.0, # 上下反転
"fliplr": 0.5, # 左右反転
# その他
"bgr" : 0.0, # カラーチャネルをRGBからBGRにスワップ
"mosaic": 1.0, # 4つのトレーニング画像を1つに結合
"mixup" : 0.0, # 与えられた確率で2つの画像とそのラベルをブレンド
"cutmix": 0.0, # ある画像から長方形の領域を切り取り、指定された確率で別の画像に貼り付け
}
# ファインチューニング
model.train(
# 画像データ
data="HomeObjects-3K.yaml",
# 訓練設定
epochs = 10, # エポック数
close_mosaic = 3, # モザイク処理を行うエポック数
batch = 16, # バッチサイズ
optimizer = "AdamW", # 最適化手法
dropout = 0.3, # dropout rate
imgsz = 640, # 画像サイズ tupleでも指定可
device = DEVICE, # 使用デバイス
# 保存設定
save = True, # 保存するかのフラグ
project = RESULT_DIR_PATH, # 結果の保存先のディレクトリ
name = "train", # 結果の保存先のサブディレクトリ名
exist_ok = True, # 結果の保存先が存在する場合は上書きする
# データオーグメンテーション
**data_augmentation_config
)
return model
if __name__ == "__main__":
model = fine_tuning()
model.save(os.path.join(RESULT_DIR_PATH, "fine-tuned_model.pt"))

物体検出の結果の一例
終わりに
やっぱりYOLOシリーズは簡単に物体検出ができてとても良い!
今回は10エポックのみでファインチューニングしましたが、まだ精度が悪いのでもっと学習させたいと感じました。
でも、ノートパソコンでこれだけちゃんと学習して予測できるのはすごい!
この記事がYOLO使ってみたいなっていう方々の役に立てれば嬉しいです!
参考ページ
YOLO11とは...
物体検出の実装
実際のコード
次のページ
現在実装中
付録
COCO8データセットのダウンロード
以下のコードを実行すると自然にダウロードできるはずです。
(違うディレクトリにダウンロードされる場合は、ライブラリのsetting.jsonを変更する必要あり)
from ultralytics import YOLO
# 実行デバイス
DEVICE = "mps"
def docs_train_demo():
""" ドキュメントの訓練コード """
# モデルの読み込み
model = YOLO("yolo11n.pt")
# COCO8での訓練
results = model.train(data="coco8.yaml", epochs=100, imgsz=640, device=DEVICE)
if __name__ == "__main__":
docs_train_demo()
参考: 公式ドキュメント(https://docs.ultralytics.com/ja/models/yolo11/)
ファインチューニング済みのモデルによる物体検出
import os
import sys
from typing import List
from ultralytics import YOLO
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from dataloaders import load_homeobjects_val_image_path_list
from utils import save_result_to_json
# 保存先設定
RESULT_DIR_PATH = "results/detection/fine-tuning"
RESULT_BOXES_DIR_PATH = "results/detection/fine-tuning/boxes"
# 実行デバイス
DEVICE = "mps"
def pred_homeobjects():
""" HomeObjects-3Kデータセットに対する予測を行うメソッド """
# モデルの読み込み
model = YOLO(os.path.join(RESULT_DIR_PATH, "fine-tuned_model.pt"))
# HomeObjects-3Kの画像パス
image_path_list: List = load_homeobjects_val_image_path_list(num_data=10)
# 物体検出
results = model.predict(
# 画像パス
source = image_path_list,
# 予測設定
imgsz = 640, # 画像サイズ tupleでも指定可
conf = 0.25, # 検出の閾値
device = DEVICE, # 使用デバイス
# 保存設定
save = True, # 保存するかのフラグ
project = RESULT_DIR_PATH, # 結果の保存先のディレクトリ
name = "images", # 結果の保存先のサブディレクトリ名
exist_ok = True # 結果の保存先が存在する場合は上書きする
)
# 結果の保存
for result in results:
save_result_to_json(result, RESULT_BOXES_DIR_PATH)
if __name__ == "__main__":
pred_homeobjects()
Discussion