FizzBuzz.txt(8エクサバイト)
FizzBuzzFS
FizzBuzz問題といえば定期的にSNSで話題になっては変な解法が発明されることでおなじみですが(?)、ファイルシステムを使った事例が見当たらなかったのでやってみました。

まあ見ての通りというか…… /mnt/FizzBuzz に FizzBuzz.txt(8エクサバイト)があって、FizzBuzzが書いてあります。

どこまでも……

容量の続く限り……
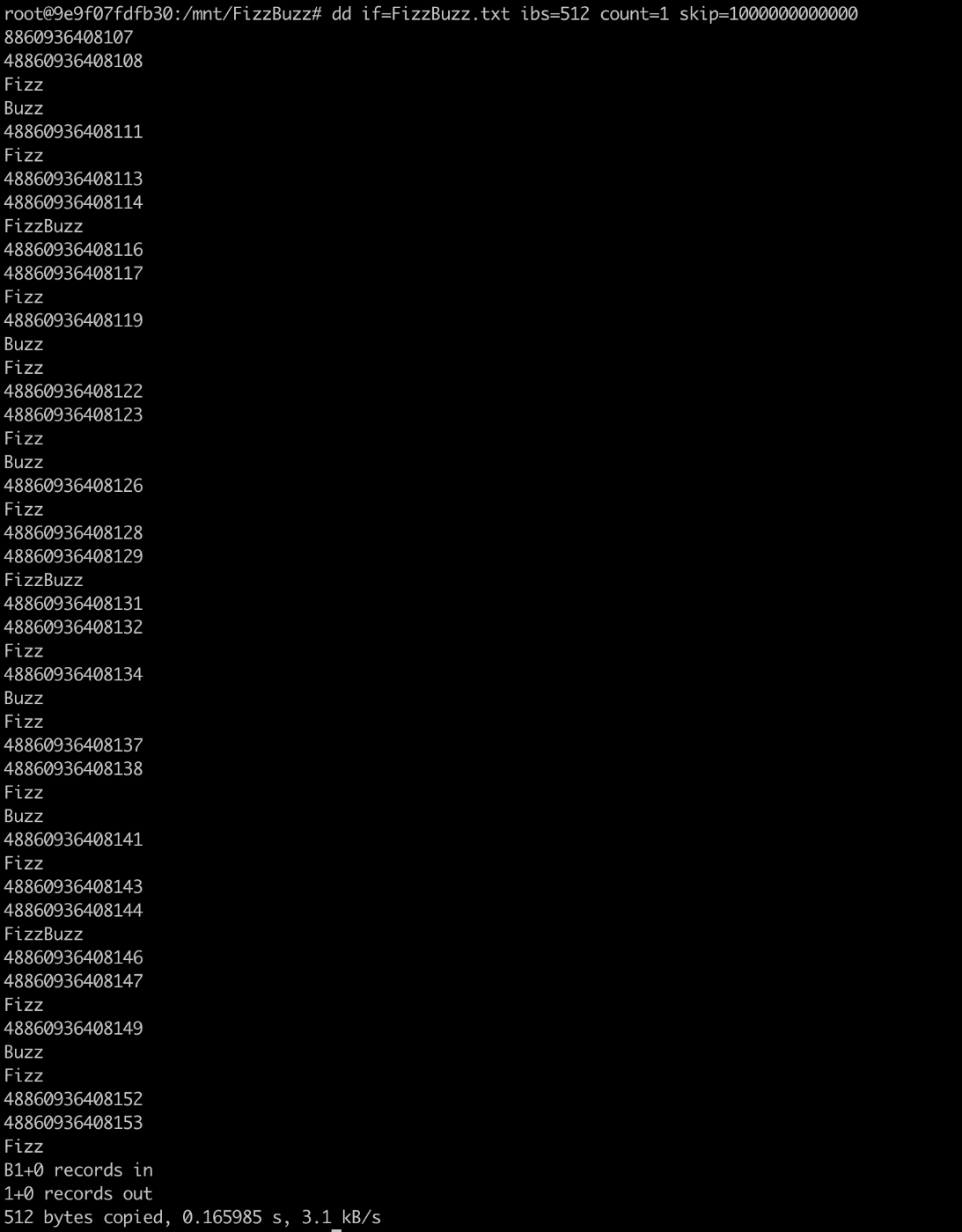
以上!!!!!!!
技術解説
FUSE
FUSE(Filesystem in USEr space)というソフトウェアを使うことで、簡単に新しいファイルシステムを実装することが可能です。
Rustにおいては、fuse crateの更新が停止した結果フォークが複数存在するようですが、利用者数と更新頻度的にfuser crateを使うのがよさそうです。
FileSystem traitが実装された値をmount2関数に渡せばとりあえずファイルシステムが完成。全メソッドにデフォルト実装が提供されているため、最小構成は非常にシンプル。
use fuser::{Filesystem, MountOption};
use std::env;
struct NullFS;
impl Filesystem for NullFS {}
fn main() {
env_logger::init(); // これはなくてよい
let mountpoint = env::args_os().nth(1).unwrap();
fuser::mount2(NullFS, mountpoint, &[MountOption::AutoUnmount]).unwrap();
}
これだけでマウント可能なファイルシステムとして動作します。マウント以外のことはできないが……
今回必要な機能は
-
lsでファイル一覧を取得できる -
FizzBuzz.txtの内容を取得できる
ですが、公式サンプルのhello.rsを参照すれば事足ります。
実装すべきメソッドは
-
lookup: 名前を元にファイルのメタデータを返す -
getattr: inode番号を元にファイルのメタデータを返す -
read: inode番号と位置からファイルの内容を返す -
readdir: inode番号からディレクトリの内容を返す
で、read以外はほぼサンプルそのまま。readについては、ファイルの位置を指定して内容を返す関数char_at(pos)を用意して
let mut buf = Vec::new();
for i in offset..(offset.saturating_add(size as i64)) {
buf.push(char_at(i));
}
reply.data(&buf)
するだけ。
FizzBuzz.txtの任意の位置の内容を計算する関数
8エクサバイトぶんのFizzBuzzを計算するわけにもいかないので、位置が指定された時点でその部分の内容だけを計算する方針で行きます。AtCoder ABCのD問題くらいの難易度じゃないだろうか。私は一日かかりましたが……
- FizzBuzz.txtのn行目までのバイト数を求める関数
fizz_buzz_length(n)を書く - 指定された位置がFizzBuzz.txtの何行目に相当するかを、
fizz_buzz_lengthを使った二分探索で求める - 当該行の内容を計算し、指定された位置の文字を返す
という方針でいきます。一文字ずつ計算するのは非効率なんだけど、実用上問題ないのでまあいいや。
まず fizz_buzz_length(n) ですが、本当に汚いのであまり見ないでほしい。0-9, 10-99, 100-999, ... の区間ごとに「数字の行数」「Fizzの行数」「Buzzの行数」「FizzBuzzの行数」を計算して、それぞれの文字数を足してやれば全体の文字数が出る。汚い!!!
pub fn fizz_buzz_length(n: i64) -> u128 {
assert!(n >= 0);
let n = n as u128;
let zero = 0u128;
let mut num_len_sum = zero;
let mut num_count = zero;
let mut fizz_count = zero;
let mut buzz_count = zero;
let mut fizz_buzz_count = zero;
let max = (i64::MAX / 10 + 1) as u128;
let mut i = 10u128;
let mut digits = 1;
while i <= n {
let fizz_buzz_count0 = (i - 1) / 15 - fizz_buzz_count;
let fizz_count0 = (i - 1) / 3 - fizz_buzz_count0 - fizz_count - fizz_buzz_count;
let buzz_count0 = (i - 1) / 5 - fizz_buzz_count0 - buzz_count - fizz_buzz_count;
fizz_buzz_count += fizz_buzz_count0;
fizz_count += fizz_count0;
buzz_count += buzz_count0;
let num_count0 = i - fizz_count - buzz_count - fizz_buzz_count - num_count;
num_count += num_count0;
num_len_sum += (digits + NEWLINE_LEN) * num_count0;
assert_eq!(num_count + fizz_count + buzz_count + fizz_buzz_count, i);
digits += 1;
if max <= i {
break;
}
i *= 10;
}
let fizz_buzz_count0 = n / 15 - fizz_buzz_count;
let fizz_count0 = n / 3 - fizz_buzz_count0 - fizz_count - fizz_buzz_count;
let buzz_count0 = n / 5 - fizz_buzz_count0 - buzz_count - fizz_buzz_count;
fizz_buzz_count += fizz_buzz_count0;
fizz_count += fizz_count0;
buzz_count += buzz_count0;
let num_count0 = n + 1 - fizz_count - buzz_count - fizz_buzz_count - num_count;
num_count += num_count0;
num_len_sum += (digits + NEWLINE_LEN) * num_count0;
assert_eq!(fizz_count + buzz_count + fizz_buzz_count + num_count, n + 1);
// 1 + NEWLINE_LEN for "0\n"
num_len_sum
+ fizz_count * (4 + NEWLINE_LEN)
+ buzz_count * (4 + NEWLINE_LEN)
+ fizz_buzz_count * (8 + NEWLINE_LEN)
- (1 + NEWLINE_LEN)
}
n行目の内容を計算するのは普通にFizzBuzzするだけ。Cow使えるとなんか嬉しいですね。
pub fn line_at(n: i64) -> Cow<'static, [u8]> {
if n % 15 == 0 {
Cow::from(b"FizzBuzz\n" as &'static [u8])
} else if n % 3 == 0 {
Cow::from(b"Fizz\n" as &'static [u8])
} else if n % 5 == 0 {
Cow::from(b"Buzz\n" as &'static [u8])
} else {
let s = format!("{}\n", n);
let v = Vec::from(s.as_bytes());
Cow::from(v)
}
}
上記ふたつの関数を使ってindexバイト目の内容を求める関数。
lはindexより手前の行のインデクス、rはindexを含むかそれ以降の行のインデクス。という条件で二分探索。探索が終了したときのrは、indexを含む行のインデクスになる。
pub fn char_at(index: i64) -> u8 {
assert!(index >= 0);
let index = index as u128;
let mut l = 0;
let mut r = i64::MAX;
while l + 1 < r {
let mid = l + (r - l) / 2;
let v = fizz_buzz_length(mid);
if v <= index {
l = mid;
} else {
r = mid;
}
}
let base = fizz_buzz_length(r - 1);
let line_index = (index - base) as usize;
let line = line_at(r);
line[line_index]
}
というわけで8エクサバイトのどの部分でも読めるようになりました。良かったですね。
Discussion