BigQueryの課金を抑えるために
はじめに
データエンジニアリング領域を業務で触るようになり、今まで気にすることのなかった様々なコストを気にするようになりました。
ETLパイプラインを使用して定期的にBigQueryへデータを取得していると、塵積でとんでもないコストがかかっていたりします。
今回は、ETLパイプライン運用など、定期でBigQueryへクエリが発生する状態を想定して、お金のコストを抑えるためのポイントを書き留めます。
BigQueryの課金体系
BigQueryの課金体系には大きく2つの要素があります。
- 分析料金
- ストレージ料金
ストレージ料金に関しては、必要なデータをわざわざ削ることでコストを抑える選択はしないでしょう。
効果的に改善できる余地があるのは分析料金のため、この記事では分析料金にフォーカスします。
分析料金
公式ドキュメントによると、
クエリの処理にかかる費用です。SQL クエリ、ユーザー定義関数、スクリプト、テーブルをスキャンする特定のデータ操作言語(DML)とデータ定義言語(DDL)のステートメントなどが含まれます。
とあり、要するにBigQueryにあるデータに操作を行うときにかかる料金です。
料金モデルがオンデマンド、LocationがTokyo (asia-northeast1)の場合、クエリでスキャンされたデータ1TBにつき$6.00となっています。(毎月 1 TB までは無料です。)
スキャン量はダイレクトにコストに影響するため、スキャン量を改善することでコストを抑えることができます。
スキャン量を減らすには
selelt * を使わない
シンプルな話ですが、SQLでスキャン範囲を決めるのはレコード数だけでなくカラムも含まれます。
select *を使うと、テーブルの全てのカラムをスキャンすることになります。
特定のカラムしか使用しない場合は、都度そのカラムだけを指定するようにしましょう。
クラスタ化テーブル
テーブルに対してクラスタ化テーブルを有効にすると、指定したカラムに基づいてテーブルのデータを物理的に並べ替えることができます。
ただ並び替えただけでなく、クエリのスキャン範囲を絞る仕組みができます。
以下は、クラスタされてないテーブル、Countryでクラスタされたテーブル、CountryとSratusでクラスタされたテーブルの例です。
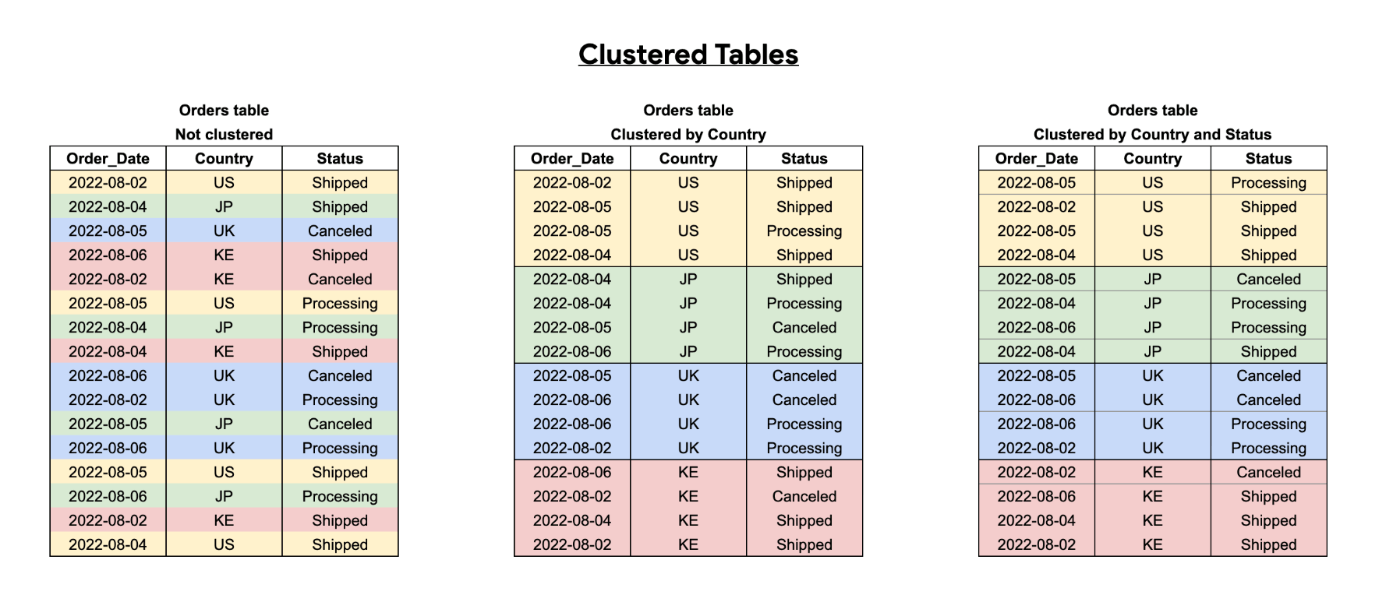
Countryでクラスタ化されたテーブルでは、Countryの値に基づいてストレージブロックという単位に内部的に分割されます。
例えばこのテーブルに対して、
Where Country = 'JP'
というフィルターのクエリを発行したとき、フィルターに一致するストレージブロック(つまりCountry='JP'のストレージブロック)のみスキャンが発生して、全量スキャンする必要がなくなります。
スキャン量が絞られることで、コストが下がるだけではなくクエリの高速化も期待できます。
クラスタ化テーブルを検討する際の注意点
効果的なクラスタ化テーブルを作るには以下の点を考慮する必要があります。
- クラスタするカラムは、一意の値が多く(カーディナリティが高い)ものを選ぶと良い
- テーブルサイズが1GBより小さい場合、パフォーマンスの大きい向上は見込めません
パーティション
こちらもテーブルを内部的に分割する仕組みです。
パーティションを設定すると、テーブルをパーティションと呼ばれるセグメントに分割されます。
クエリのパフォーマンスを高めることや、クエリによって読み取るバイト数を減らしてコストを抑えることができます。
一例として、時間単位列パーティショニングを説明します。
これはテーブルの DATE、TIMESTAMPまたはDATETIME列を選択することで分割できます。テーブルにデータを書き込むと、列の値に基づいて、自動的に正しいパーティションに分割されます。
実際にBigQueryにDATETIMEとINTEGERのカラムを持つテーブルを作成します。

パーティションの設定項目で、パーティションとして使用するカラムを選択します。

次にパーティショニングタイプを選択します。

DATEIMEカラムをどの粒度でパーティショニングをするかを決定します。
気をつけるポイントは、パーティションは4,000を超えるとクエリを発行することができなくなります。つまり4,000を超える期間を見積もってパーティショニングタイプを決定する必要があります。
例えば、日次にした場合、1年で365つのパーティションテーブルが作成され、約11年で上限に到達します。
クラスタ化テーブルとパーティションの違い
クラスタ化テーブルとパーティションはどちらも内部的にデータ領域を分割する仕組みです。
どちらもスキャン範囲を絞ることで、コストを抑えることができますが、使用するクエリやデータ量によって適切な方法を選択する必要があります。
以下の公式ドキュメントに則って、各々の状況と照らし合わせて検討すると良いでしょう。
参考
Discussion