Decision Transformer: Reinforcement Learning via Sequence Modeling
Transformerで強化学習
従来と強化学習の扱い方を変えて、状態・行動・報酬の同時確率分布を自己回帰モデルとして扱う枠組みを提案
オフライン強化学習でSOTA
Decision Transformer architecture
- State, Action, Return(embed) + positional timestep encodingを入力
- トークンをGPTアーキテクチャへ入力し、Actionを予測
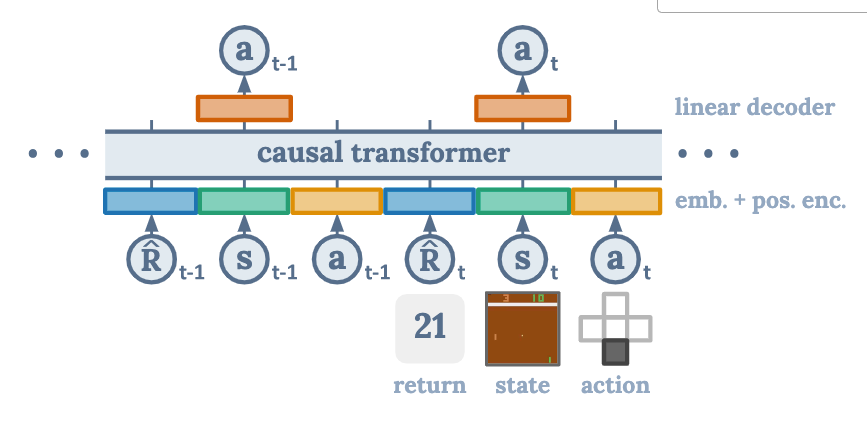
Figure 1
イントロ
-
近年Transformerは高次元な意味的な概念を学習できていることが示されている
-
TD法がRLでは主流
- 我々はてシーケンスモデリングを使ってエピソードを集めモデルを訓練する
-
TD法で用いられている将来の報酬の割引を行う必要がないため、近視眼的な行動をとらなくなる
-
Transformerはself-attentionによって直接割当ができるため、ベルマン方程式より報酬の伝搬が早い
- 報酬のノイズにロバスト
-
Offline RLでは誤差の累積と価値関数のオーバーフィットが課題
イラスト例
Shortest path問題

ゴールにたどり着いたら報酬0
それ以外は−1
- ランダムウォークのデータからのみ学習
- GPTはreturn-to-go(ある時刻以降に得られる報酬)のトークンのシーケンスを予測
- State, Action, Returnは1つのトークン
評価は現時刻の状態と、目的の報酬、過去の状態から次に行くべきノードを予測させる
-
その結果、与えた状態に対応する行動のシーケンスを出力でき、更に最短距離を出力できた(初期状態と、最も高いreturnの2つで条件付けた結果)
-
Atari, Gym, Key-to-doorで評価
-
特に長期タスクでは良い性能
Method
- GPTが学べる形式
- 条件付けてactionが生成できるように
- 将来のリターンに基づいて行動を生成するモデルにするため、retrun-to-goを入力に
Trajectory
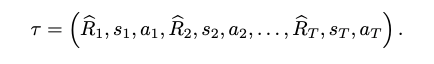
Return-to-go

トークンは
(state, action, return-to-go)
アーキテクチャ
- last K timestepsを入力(合計3K token)
- 画像のinputだったらCNN
- pos embedも入れる
学習
- オフラインの軌跡からシーケンス長Kのミニバッチをサンプル
-
s_t a_t - 各timestepのロスは平均取る
- state, returns-to-goの予測したけど改善しなかった

Evaluations on Offiline RL Benchmarks
- model-free offline RL (TD法使うもの)
- Behavior cloning
TD learning
比較手法
- Conservative Q-Learning (Offline RL SOTA)
- BEAR
- BRAC
Imitation learning
- BC
比較する環境
- Atari (Discrete)
- Gym (Continuous)
- Key-To-Door?
それぞれのドメインでノーマライズ

Atari
- visual input
- DQN replay datasetの1%のみ使用
- 500 thousand / 50 million (1 %)
- K=30 (pongはK=50)
- 3 seedの分散で評価

100がpro gamer
0がrandom player
scoreing(Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari withdiscrete world models.arXiv preprint arXiv:2010.02193, 2020)
OpenAI Gym
連続行動空間
- D4RLと同じ方法でdatasetsを作成
- 2D reacher環境
- Medium: 100万 timesteps "medium" policyによって生成, export policyの1/3の性能
- Medium-Replay: "medium" policyを訓練するのに使ったreplay buffer (25K-400K timesptes)
- Medium-Expert: "medium" policy によって生成された100万 timesteps + export policyによって生成された100万 timespteps


Diccussion
Does Decision Transformer perform behavior cloning on a subset of the data?
DTが一定のリターンを持つデータのサブセットに対して模倣学習を行っていると考えら得れるかどうかについての洞察を得ることを目指す
この検証のために%BCを提案
- top X% of timesteps でBCする (episode returns順)
- DTの動作を知るためのもの
standard BC = 100%
10%, 25%, 40%, 100%でDTとCQLと比較
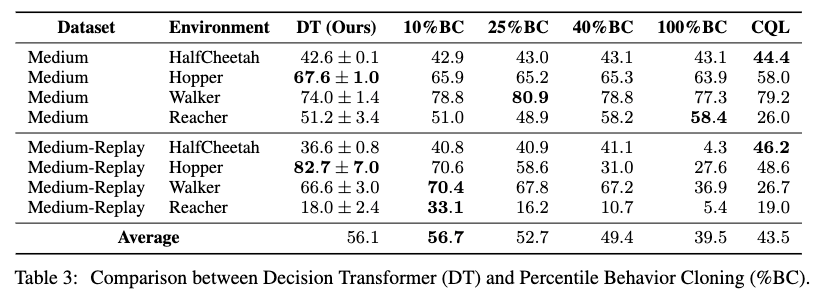
ほとんどの環境で最高%BCの性能に匹敵
→ DTはデータセット全体で訓練しても特定の良いサブセットに焦点を合わせれることを示唆?
データ量が少ないとき(Atari)、%BCは弱くなる
DTはBCより一般化を向上させており、軌跡の条件付けが違ってもでもBCを上回れる

How well does Decision Transformer model the distribution of returns?
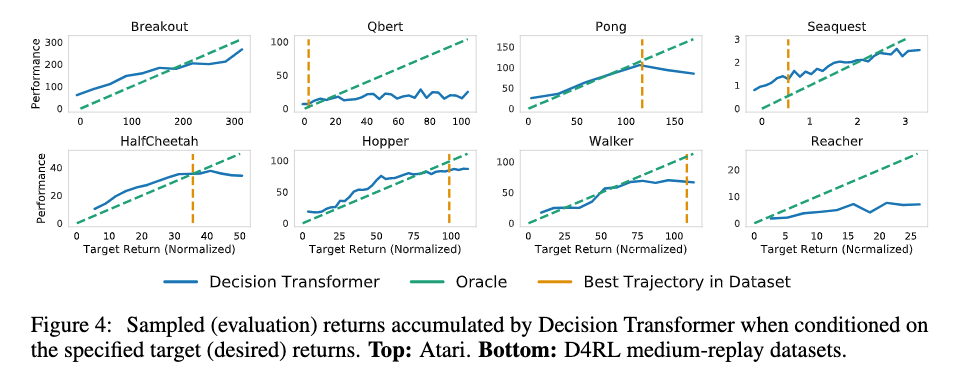
- targetのリターンを変化させて、リターントークンを理解する能力を評価
- Transformerのマルチタスク分布モデリング能力を評価
目標と得られたリターンの相関は高い(ほぼ完全一致する軌跡を生成)
DTは外挿可能であることを示唆
- Atariタスクでは、データセットで得られる最大のエピソードリターンより高いリターンが見られた
What is the benefit of using a longer context length?
コンテキスト長Kについて評価
- 一般的にマルコフ性を仮定する強化学習ではK=1で十分なはず
- しかしK=1ではDTの性能が著しく落ちる
- Atariは過去の情報役に立つかもねー
- 仮説: どのポリシーがアクションを生成したかDTが識別し、より良い学習を可能にすることができる?

Does Decision Transformer perform effective long-term credit assignment?
長期的なクレジット割当問題(どの行動が良い報酬につながったのか(貢献度分配問題))を評価する
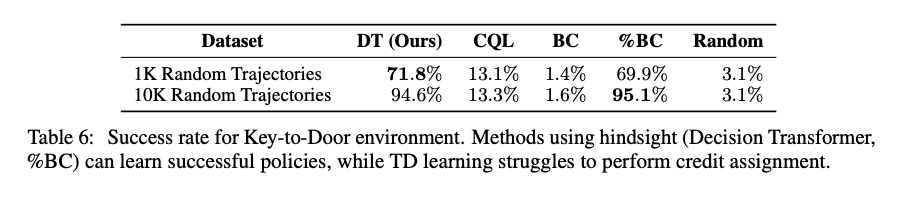
Key-to-Doorタスクで検証
- 最初にエージェントは鍵のある部屋へ置かれ
- なにもない部屋におかれ
- ドアのある部屋へ置かれる
3段階でドアに到達すると2値の報酬を受取るが、1段階で鍵を拾ったときのみ
→エピソードの最初から最後まで伝達するのが難しい
表はランダム方策から生成された軌跡から学習
コンテキスト長はエピソードの長さそのものにしている
Can transformers be accurate critics in sparse reward settings?
- DTの出力にreturnsを付けた
- 最初のreturn tokenは与えられず、標準的な自己回帰生成モデルと同様に予測

グラフの結果より、criticの出力もできるっぽい
→ 状態と報酬の関連付けが形成されている
Does Decision Transformer perform well in sparse reward settings?
-
TD学習は密度の高い報酬が必要
-
最後に累積報酬を1回だけ上げるように変更
-
DTは報酬の密度に関する仮定がほとんどないため、良い性能を示した
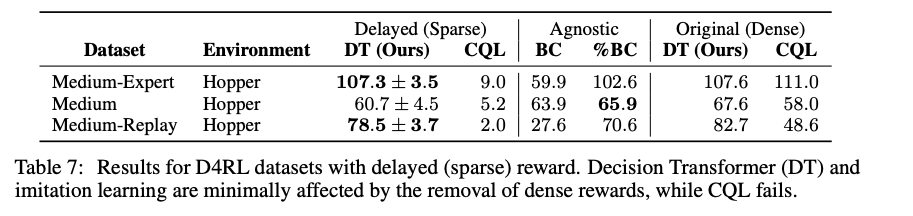
- またBCは報酬に依存しないので、BCも良い性能
Why does Decision Transformer avoid the need for value pessimism or behavior regularization?
よくあるTD誤差を使ったRLアルゴリズムは、価値関数学習→方策関数学習ってやると近似誤差がたまる
その点DTは正則化とかの必要がない
How can Decision Transformer benefit online RL regimes?
DT + GO-Exploreとか良さそう
(DTが記憶エンジンとして機能)
Conclusion
- DTを低庵
- 今回はしてないが、データが多い場合は事前学習しても良いかも
- 一応オフラインRLタスクでSOTA