[Kubernetes] PodのAZ分散を実現するPod Topology Spread ConstraintsとDescheduler
本記事は、PodのAZ分散を実現するPod Topology Spread ConstraintsとDeschedulerについて紹介します。
また、それぞれの課題とその解決方法について書きます。
Kubernetesについて基本的な用語がわかる方であれば読める内容になっているかと思います。
Pod Topology Spread Constraintsとは?
Pod Topology Spread Constraintsを使うことで、Region・Zone・Nodeなどの単位でPodを分散して配置することが可能になります。
例えば、1つのZoneにNodeが2台とPodが1台ずつ配置されているとします。
AZ障害が発生し、Nodeがダウンすると1つのZoneにPodが集中していた場合のサービス影響は大きくなります。
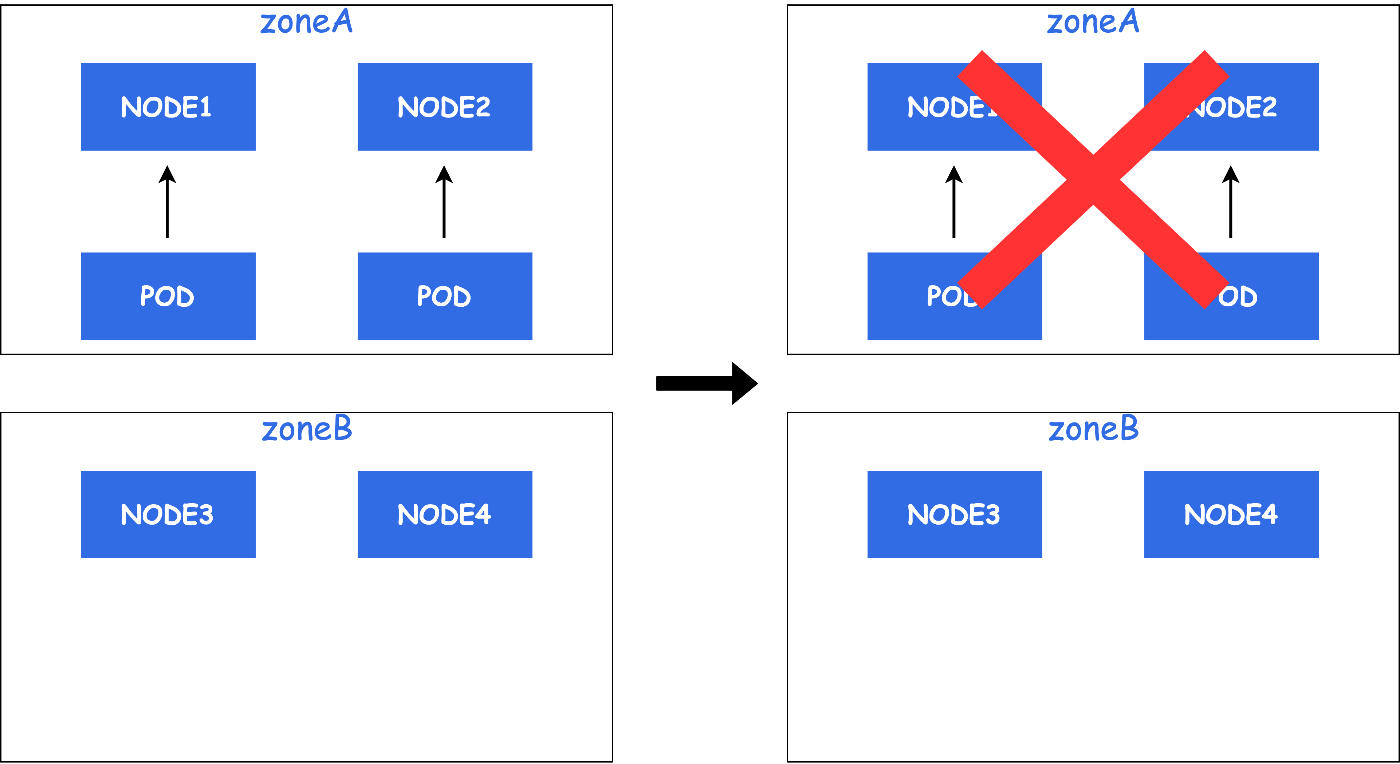
しかし、2台のPodが異なるZoneに配置されていた場合、サービス影響は小さくなります。
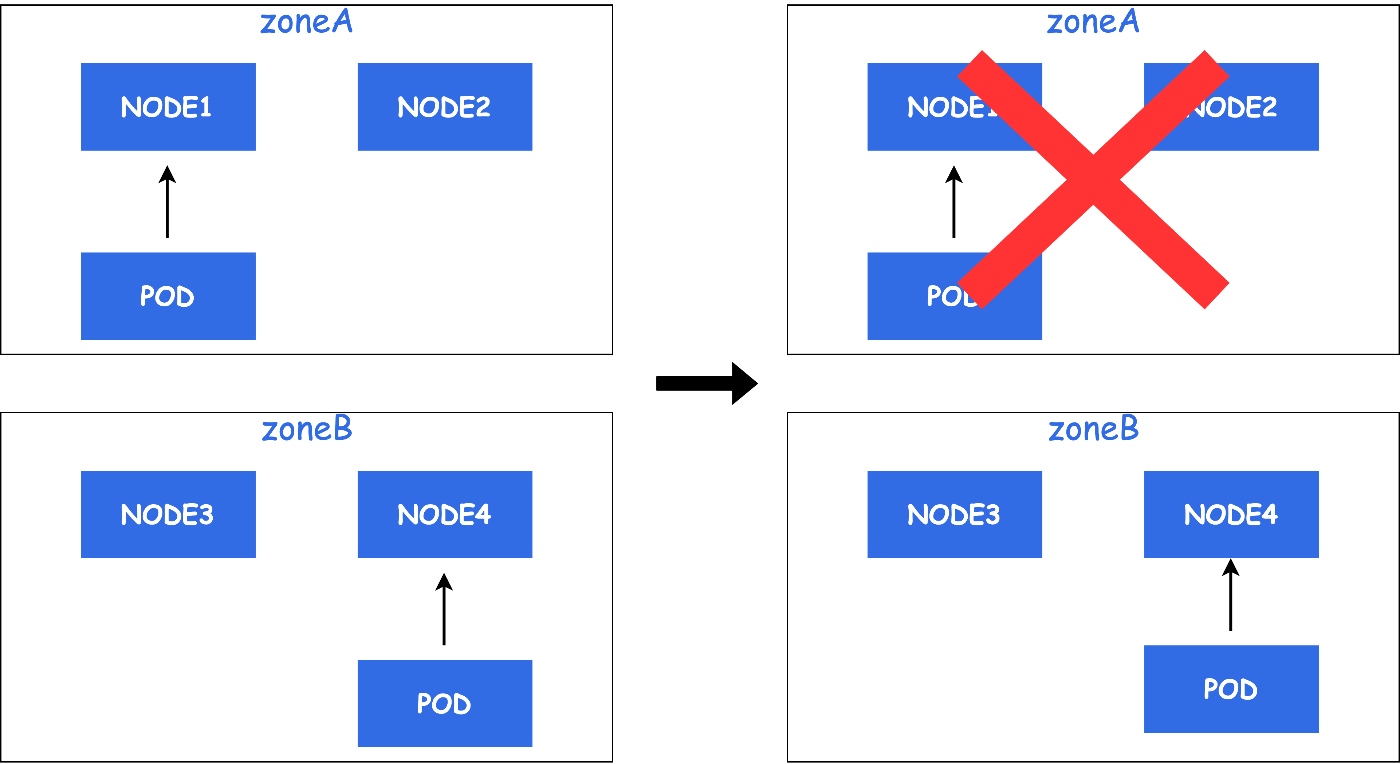
Pod Topology Spread Constraintsを使用することで上記のようなPodの配置を実現することが可能になります。
以下、公式ドキュメントです。
Pod Topology Spread Constraints
Pod Topology Spread Constraintsの使用例
では、実際にPod Topology Spread Constraintsを使った例を見ていきましょう。
apiVersion: v1
kind: Pod
metadata:
name: myapp
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
app: myapp
maxSkewについて
上記の例では、maxSkew: 1が設定されています。
maxSkew: 1では、Zone間のPod数の差が1台まで許容されます。
例えば、ZoneA・ZoneB・ZoneCの3つのZoneが存在するとします。
ZoneAとZoneBには既にPodが1台ずつ配置されています。

ここで新しいPodが配置されるとします。
均等に配置されるとしたらzoneCにPodが配置されるでしょう。

しかし、zoneC以外にPodが配置されるとどうなるでしょう。

このように、特定のZoneにPodが偏ってしまいます。
ここでmaxSkewです。
先ほど述べたように、maxSkewではZone間のPod数の差を制限することができます。
つまり、先ほどの例ではZoneBにPodが2台配置されていましたが、この場合ZoneBが2台とZoneCが0台となりPod数の差が2となるためZoneBには配置することができません。

結果として、ZoneAに配置した場合もPod数の差が2台となるため配置することができず、ZoneCのみ配置することが可能になります。
topologyKeyについて
maxSkewではZone間のPod数の差を制限できると説明しました。
もし、Zone間ではなくNode間やRegion間でPod数の差を制限する場合はどうすれば良いでしょうか。
この分散する単位を指定するのが、topologyKeyです。
上記のマニフェストの例では、topologyKeyにtopology.kubernetes.io/zoneを使用していた為、Zone間でのPodの均等配置を実現していました。
例: topology.kubernetes.io/zone: ap-northeast-1a
このLabelは、Cloud Provideを使用している場合のみ、提供された情報を設定します。
詳しくは、こちらをご覧ください。
Region間で分散する場合にはtopology.kubernetes.io/regionが使用できます。
例: topology.kubernetes.io/region=ap-northeast-1
分散する単位を指定する場合はtopologyKeyを使って設定して下さい。
whenUnsatisfiableについて
whenUnsatisfiableでは、Podが条件に合致するNodeがない場合の対処法を設定することができます。
whenUnsatisfiable: DoNotSchedule (default)
DoNotScheduleでは条件に合致しない場合、Podがスケジュールされることはありません。

whenUnsatisfiable: ScheduleAnyway
ScheduleAnywayでは条件に合致しない場合、Skewを最小化するNodeに優先的にスケジュールされます。

labelSelectorについて
labelSelectorに指定したLabelを持つPodがtopologySpreadConstraintsの対象となります。
上記マニフェストの例では、app:myappラベルを持つPodが対象となります。

Pod Topology Spread Constraintsの課題
Pod Topology Spread Constraintsを使ってPodのZone分散を実現することができました。
ここまで見るととても便利に感じられますが、Zone分散を実現する上で課題があります。
Pod Topology Spread Constraintsはスケジュール済みのPodが均等に配置しているかどうかを制御することはありません。
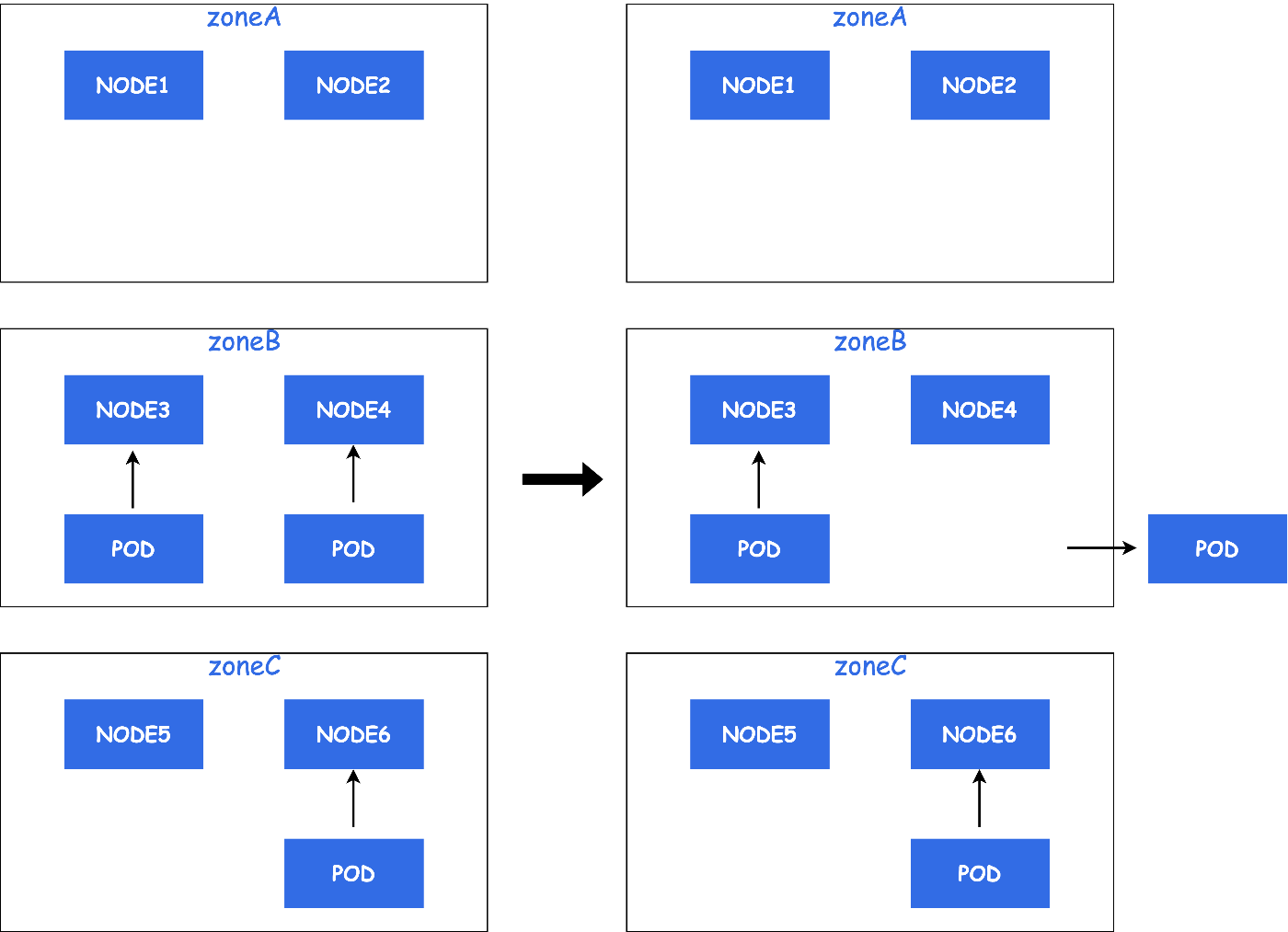
例えば、AZ障害が発生した場合を考えてみます。

ZoneAにて障害が発生し、Node1のPodがEvictされSTATUSがReadyなNodeに再スケジュールされます。
下記の例では、ZoneBに再スケジュールされています。
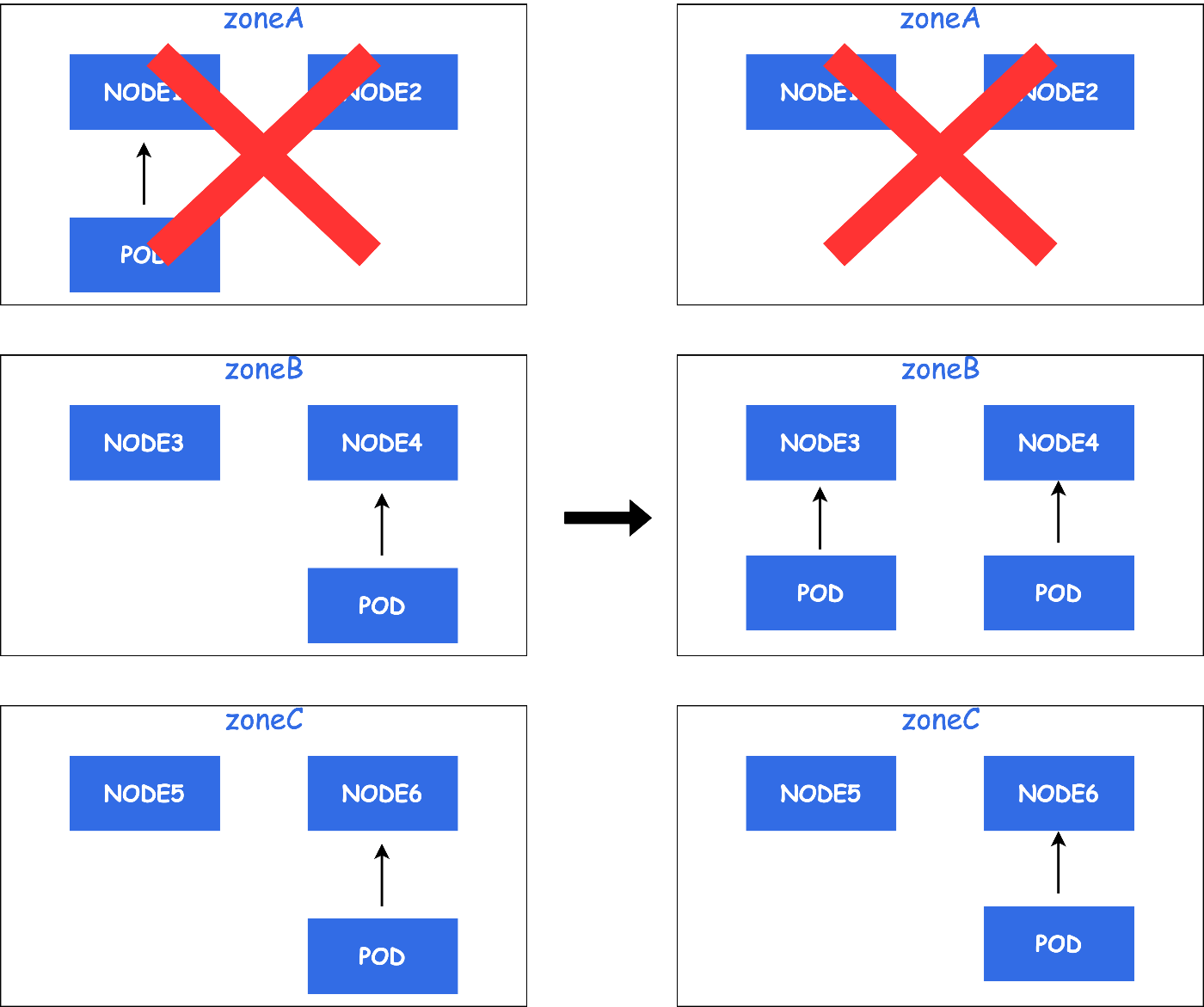
この後、AZ障害からZoneAが復旧した場合を考えてみます。
PodはZoneBとZoneCにのみ配置され、ZoneAには1台も配置されていません。
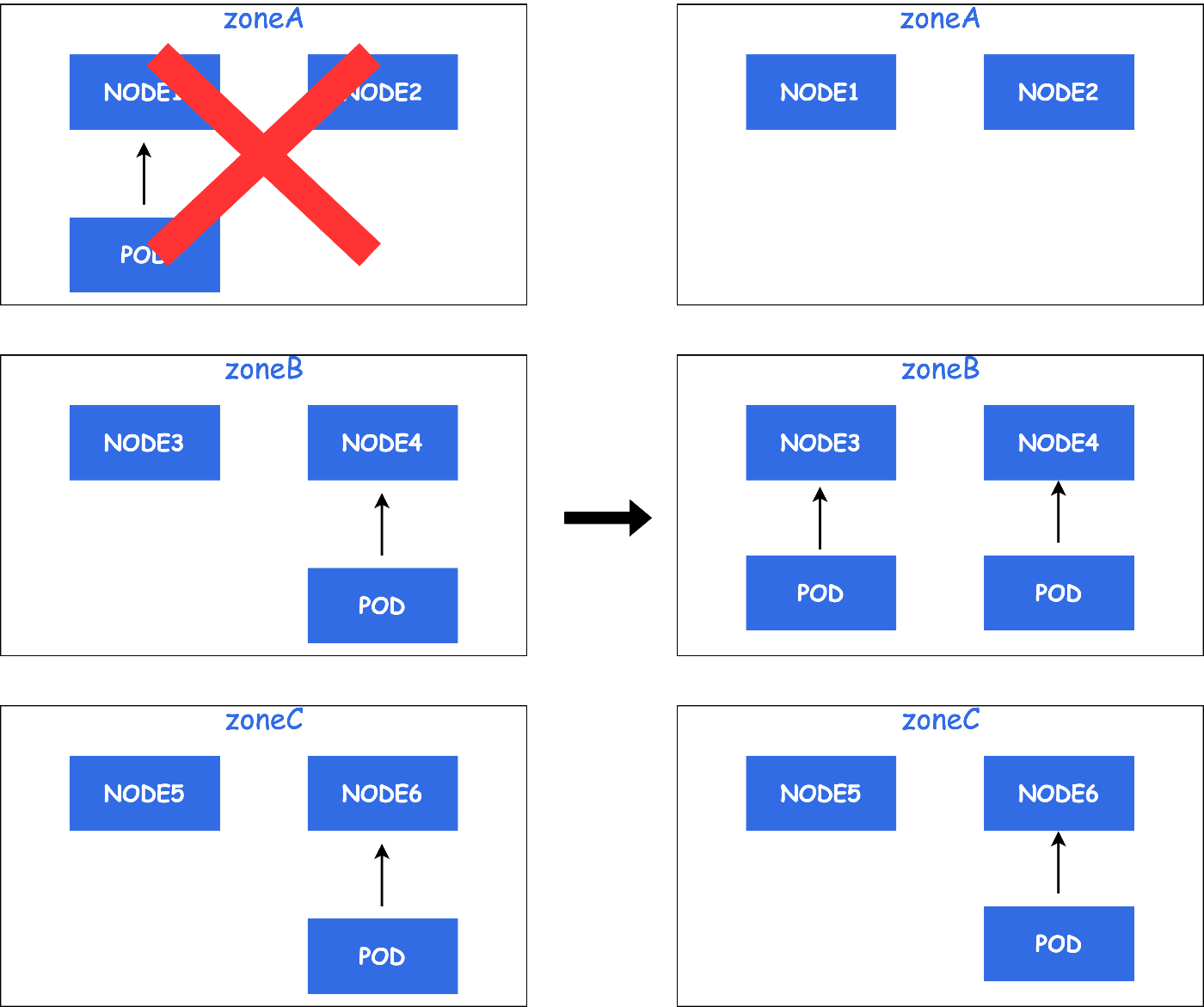
このように、AZ障害発生した場合などにPodが均等に配置されなくなります。
そこで、Deschedulerです。
Deschedulerとは
Deschedulerは、既に稼働しているPodを他のNodeに移動させたい場合に、PodをEvictすることで再度スケジュールさせることができます。
Deschedulerの使用例
では、実際にDeschedulerを使って、topologySpreadConstraintsを満たしていないPodをEvictします。
Deschedularのデプロイは、Deployment、CronJob、Jobの3つから選択できます。
今回は、Deploymentを使用します。サンプルマニフェストは公式がサンプルとして提供しているものを使用します。
Deploymentのサンプルマニフェスト
上記サンプルのDeschedulerの起動オプションについて解説します。
--policy-config-fileでは、Evict対象のPodを見つけるためのPolicyが書かれたファイルを指定します。
こちらはConfigMapにて定義します。
TopologySpreadConstraintsのPolicyについても公式がサンプルを提供しています。
ConfigMapのサンプルマニフェスト
--descheduling-intervalでは、Policyに違反したPodを見つける間隔を指定することができます。
今回使用するDeschedulerのPolicy
RemovePodsViolatingTopologySpreadConstraintを使うことでtoplogySpreadConstraintsを満たしていないPodをEvictすることができます。
---
apiVersion: v1
kind: ConfigMap
metadata:
name: descheduler-policy-configmap
namespace: kube-system
data:
policy.yaml: |
apiVersion: "descheduler/v1alpha1"
kind: "DeschedulerPolicy"
strategies:
"RemovePodsViolatingTopologySpreadConstraint":
enabled: true
params:
includeSoftConstraints: false
上記のPolicyを適用することで、--descheduling-intervalで指定した間隔でPolicyに違反したPodがEvictされます。
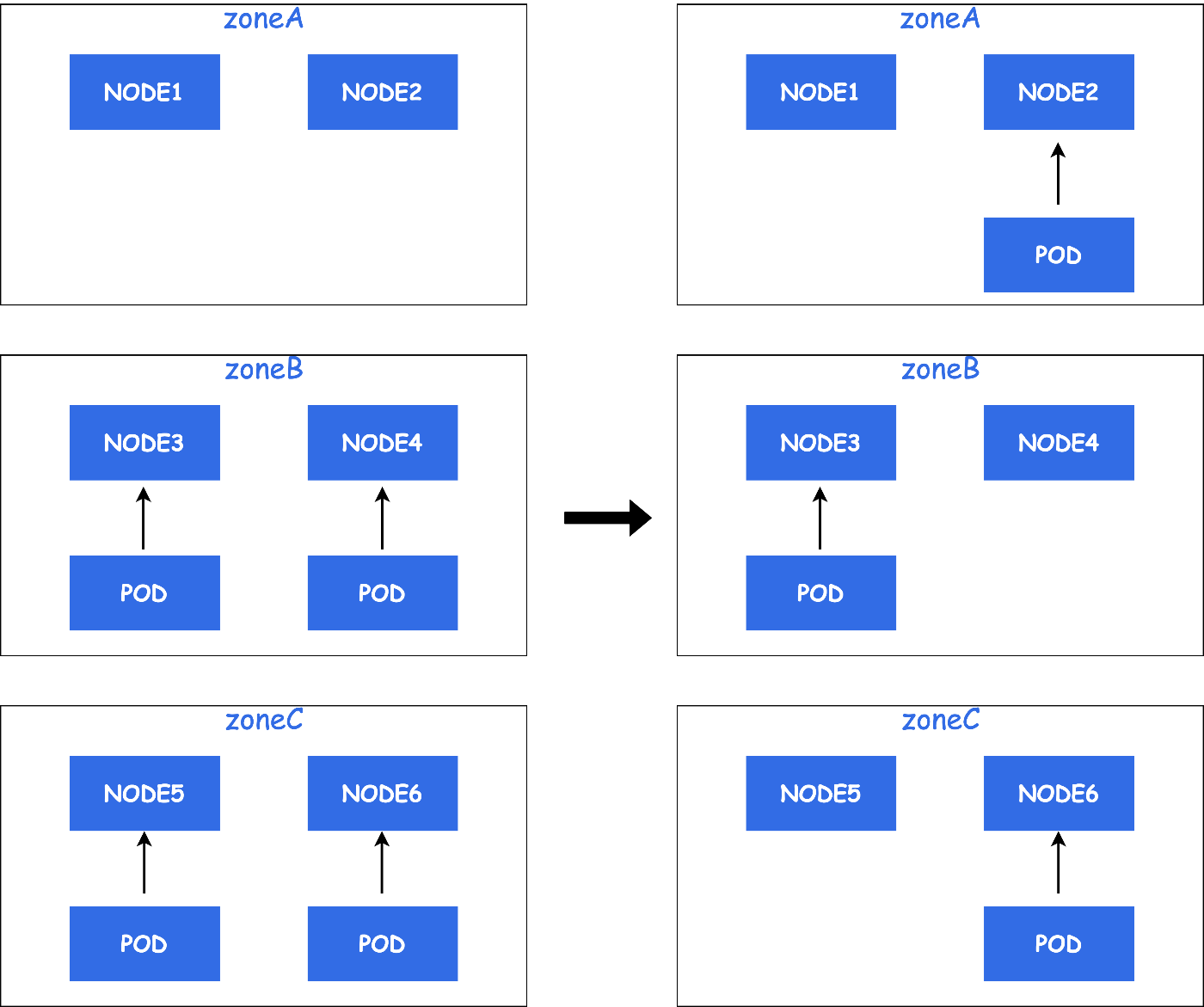
EvictされたPodは、再度スケジューラーによってtopologySpreadConstraintsを元に配置されます。
Deschedulerの課題
Deschedulerによって常にPodのZone分散を実現することができました。
しかし、Deschedulerについてもいくつか課題があります。
例えば、HPAを使ってminReplicasを設定している場合を考えてみます。
Deschedulerでは、EvictするPodの最大数をNode単位でしか設定することができませんでした。
例: MaxNoOfPodsToEvictPerNode: 1
そのため、DeschedulerによってPodがEvictされた場合、一時的にminReplicasを下回る場合があります。
Evict対象のPodが多く、一時的にPod数が減ることでサービス影響に繋がる可能性があります。
( PDBを正しく設定することで回避することも可能です )
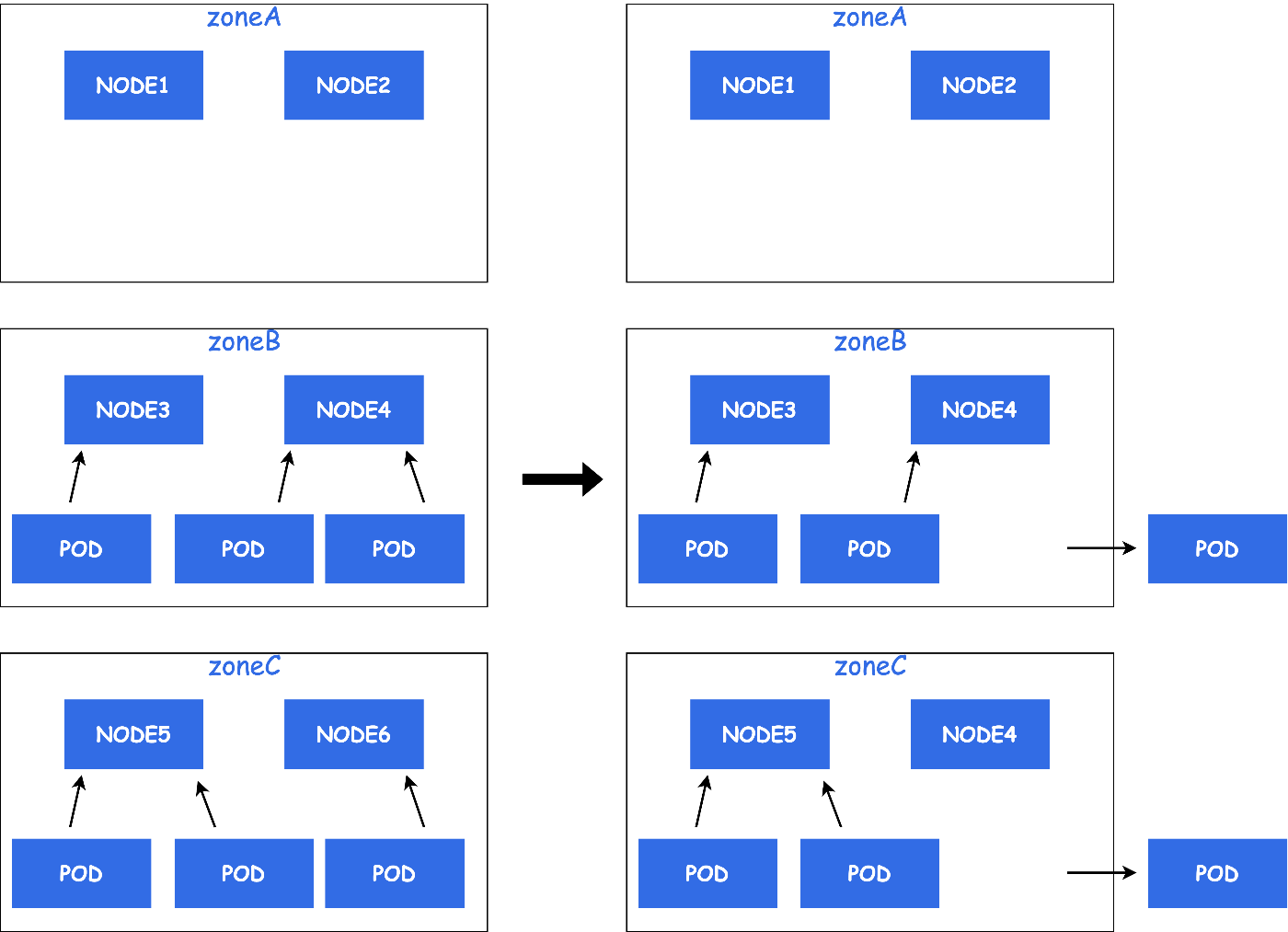
このようにZone分散では複数NodeにまたがってPodが配置されているためNode単位でEvictするPodの最大数を決めるだけでは物足りない場合が発生します。
そこで、Node単位ではなくNameSpace単位でEvictするPodの最大数を指定できるようになれば上記の問題を回避することが可能になりそうです。
例: MaxNoOfPodsToEvictPerNamespace: 1
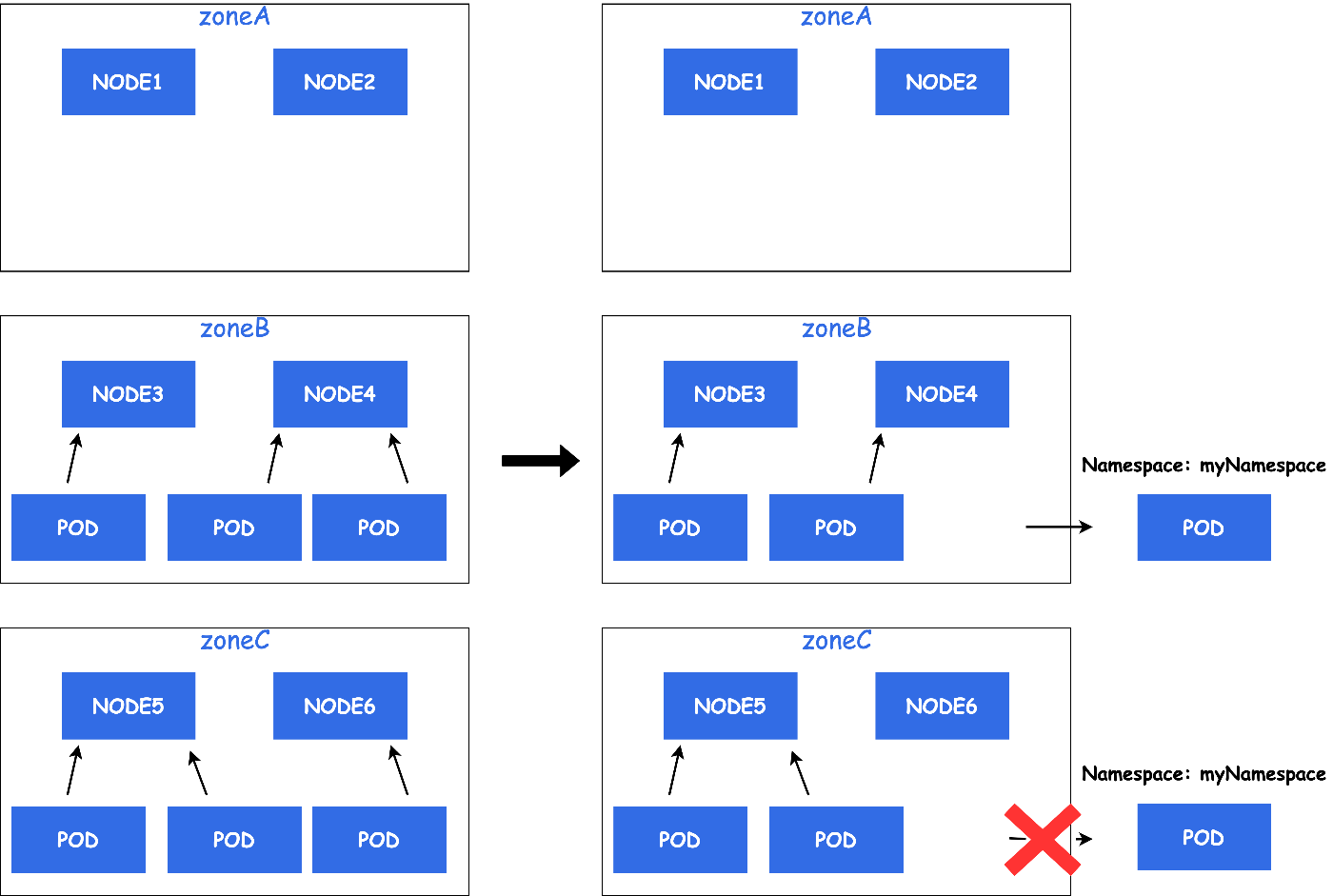
そのため、DeschedulerにIssueを作成したところ、つい先日PRがmergeされNameSpace単位での指定が可能になりました。
まとめ
本記事では、Pod Topology Spread ConstraintsとDeschedulerを使用したPodのAZ分散について解説しました。
皆さんも是非、PodのAZ分散を試してみてはいかがでしょうか?
Discussion