Beamer で作ったプレゼン資料に読み上げ音声を付ける
Beamer で作ったプレゼン資料に読み上げ音声を付ける
(この記事はTeX & LaTeX Advent Calendar 2025に参加しています。)
Beamer というのは LaTeX を用いてプレゼン資料を作るためのパッケージです。ただ PDF までしか生成してくれません。
この PDF に音声を付けて動画を作る方法を調べてみました。
前提:LaTeX 環境のインストール
この記事を読もうと思う様な人は、もう LaTeX 環境が手元にあると推察します。だから特に解説しません。私は Mac ユーザで TeXShop (ver 5.57) を利用しています。
beamer2video のインストール
beamer2video は Beamer の tex ファイルを読み込み、テキストを抽出して Text-to-Speech (TTS) で音声(WAV/MP3)を生成し、FFmpeg でスライド画像と音声を同期させたMP4動画を出力します。
README.md を参考に必要そうなものをインストールします。
$ git clone https://github.com/HughMurrell/beamer2video.git
$ cd beamer2video
$ pip3 install reportlab pydub
$ pip3 install pdfminer.six
$ brew install ffmpeg
$ brew install handbreak
Mac の場合には、以下でデフォルトの TTS の動作確認が可能です。
$ say hello
beamer2video/bin ディレクトリに PATH を通します。
動作確認
最初、私の環境では vids/ ディレクトリが存在しなかったため、エラーが起きました。また frames/ ディレクトリに Lisa のファイルをコピーする必要がありました。
$ mkdir vids
$ mkdir frames
$ cp clips/Lisa.* frames
$ cp basel.tex test.tex
$ beam2vid -n Lisa -v Fiona -f test.tex
これを実行すると test_Lisa_Fiona.mov (QuickTime) と test_Lisa_Fiona.mp4 (MP4) が生成されます。

Lisaは画面右下で原稿読み上げしてる風のアニメーションですね。clips/ ディレクトリに Lisa.gif と Lisa.mp4 ファイルがあります。
Fiona は beam2vid 内で呼ばれている annots2audio.py $narrator $voice frames/annots.out で使われる $voice に代入される値で、annots2audio.py 内部では
os.system("say"+' -v '+voice+' "'+line[11:]+'" -o frames/frame{0:03d}.aiff'.format(num))
みたいに say コマンドの引数に渡されます。
とりあえず、読み上げ付きの動画が beamer から作れる様になりましたが、音声の品質に問題があったり日本語対応の問題があったりします。
そこでスクリプトを色々修正します。
VOICEVOX インストール
VOICEVOX は無料で使える音声読み上げソフトです。よく動画配信とかで使われている「ずんだもん」などの音声を生成可能です。
利用可能な音声毎に、
四国めたんの音声ライブラリを用いて生成した音声は、「VOICEVOX:四国めたん」とクレジットを記載すれば、商用・非商用で利用可能です。
の様に利用規約が書かれていますので、それに従って利用しましょう。
インストール方法は、リンク先のダウンロードボタンから自分のマシンに応じたものをインストールします。私は Mac, CPU(Apple), インストーラーを選択してインストールしました。
私の場合、「お使いのMacを保護するために"VOICEVOX.app"がブロックされました」という感じのメッセージが出たので、システム設定 > プライバシーとセキュリティ、からチェック完了にします。
インストールしたアプリを起動します。(50021 ポートでサーバが動く)
動作確認
Python経由でVoiceVoxの音声ファイルを作成する方法 の記事を参考に VOICEVOX サーバの動作を確認します。
import requests
import json
# 音声合成を行う関数
def synthesize_voice(text, speaker=1, filename="output.wav"):
# 1. テキストから音声合成のためのクエリを作成
query_payload = {'text': text, 'speaker': speaker}
query_response = requests.post(f'http://localhost:50021/audio_query', params=query_payload)
if query_response.status_code != 200:
print(f"Error in audio_query: {query_response.text}")
return
query = query_response.json()
# 2. クエリを元に音声データを生成
synthesis_payload = {'speaker': speaker}
synthesis_response = requests.post(f'http://localhost:50021/synthesis', params=synthesis_payload, json=query)
if synthesis_response.status_code == 200:
# 音声ファイルとして保存
with open(filename, 'wb') as f:
f.write(synthesis_response.content)
print(f"音声が {filename} に保存されました。")
else:
print(f"Error in synthesis: {synthesis_response.text}")
if __name__ == "__main__":
# 読み上げたいテキスト
text = "こんにちは、VOICEVOXでテキストを音声に変換しています。"
# 音声合成の実行
synthesize_voice(text, speaker=1, filename="voicevox_output.wav")
$ python3 vvtest.py と実行して、生成される voicevox_output.wav を内容を確認して音声が入っていれば OK。
日本語対応の為のスクリプトの修正
https://github.com/tmiya/tmiya.github.io/tree/main/jbeamer2video に差分ファイルや動作確認用の latex ファイルがあるので取得してください。
bin/ 下に下記のファイルを追加します。
bin/jbeam2vidbin/jannots2audio.pybin/jpdfannots.py
元のコードからの変更点が少ないため、比較的容易に理解できるでしょう
while getopts f:n:v: flag
do
case "${flag}" in
f) file=${OPTARG};;
n) narrator=${OPTARG};;
v) voice=${OPTARG};;
esac
done
if [ "$file" = "" ];
then
echo "usage jbeam2vid [-n narrator -v voice] -f filename";
exit
fi
if [ "$narrator" = "" ];
then
narrator="metan";
fi
if [ "$voice" = "" ];
then
voice="2";
fi
echo "file: $file";
echo "Narrator: $narrator";
echo "Voice: $voice";
base="${file%.*}"
echo "Base: $base";
rm frames/*
mkdir -p frames
rm vids/*
mkdir -p vids
lualatex --interaction=batchmode "\def\voice{$voice}\def\narrator{$narrator}\input{$base.tex}"
lualatex --interaction=batchmode "\def\voice{$voice}\def\narrator{$narrator}\input{$base.tex}"
echo "jpdfannots.py starts"
jpdfannots.py "$base.pdf" -o frames/annots.out
cat frames/annots.out
jannots2audio.py $narrator $voice frames/annots.out
gs -o temp_noannot.pdf -dSAFER -dBATCH -dNOPAUSE -sDEVICE=pdfwrite \
-dShowAnnots=false "$base.pdf"
gs -dSAFER -dQUIET -dNOPLATFONTS \
-sDEVICE=pngalpha \
-sOutputFile=frames/frame%03d.png \
-dNOPAUSE -dBATCH -r144 \
temp_noannot.pdf
for entry in $(basename -a -s .png frames/frame*.png)
do
echo "mixing ......... $entry"
ffmpeg -hide_banner -loglevel error \
-loop 1 -i frames/$entry.png \
-loop 1 -i clips/$narrator.png \
-i frames/$entry.wav \
-filter_complex \
"[1:v]split=2[alpha][img]; \
[alpha]alphaextract[alphamask]; \
[img]format=rgba[img_rgba]; \
[img_rgba][alphamask]alphamerge[fg]; \
[0:v][fg]overlay=main_w-overlay_w-10:main_h-overlay_h-10:shortest=1[outv]" \
-map "[outv]" -map 2:a \
-c:v libx264 -tune stillimage -crf 23 -pix_fmt yuv420p \
-c:a aac -b:a 192k \
-shortest \
vids/$entry.mp4
done
cd vids
for f in *.mp4; do echo "file '$f'" >> concatlist.txt; done
cd ..
echo "Narrator: $narrator";
ffmpeg -hide_banner -loglevel error \
-f concat -safe 0 -i ./vids/concatlist.txt -c copy -y "./${base}_${narrator}_${voice}.mp4"
handbrakecli --verbose=0 -i "${base}_${narrator}_${voice}.mp4" -o "${base}_${narrator}_${voice}.mov" > /dev/null
echo "All done, exiting ..."
動作確認
動作確認に使う beamer ファイルはこんな感じです。
\documentclass[unicode,12pt]{beamer}% 'unicode'が必要
\usepackage{luatexja}% 日本語したい
\usepackage[ipaex]{luatexja-preset}% IPAexフォントしたい
\renewcommand{\kanjifamilydefault}{\gtdefault}% 既定をゴシック体に
\usepackage[author={narration},hidenotes]{pdfcomment}
\makeatletter
\pdfcomment@set@display@false % ← すべてのアイコンを強制非表示
\definestyle{note}{
icon=Comment,
color=white,
borderwidth=0,
opacity=0
}
\makeatother
\newcommand{\pdfnarration}[1]{%
\onslide*<\value{beamerpauses}>{\pdfmargincomment[style=note,author=narration]{#1}}%
}
\title{日本語Beamer動作確認}
\author{tmiya}
\date{\today}
\begin{document}
\begin{frame}
\titlepage
\pdfnarration{
日本語Beamer動作確認
}
\end{frame}
\begin{frame}{日本語がちゃんと表示されるか確認}
こんにちは!このスライドは日本語です。
\alert{赤字の部分もちゃんと見えてますか?}
次のページでは長い文章でVOICEVOXの読み上げテストをします。
\pdfnarration{
こんにちは!このスライドは日本語です。
次のページでは長い文章でVOICEVOXの読み上げテストをします。
}
\end{frame}
\begin{frame}{VOICEVOX読み上げテスト用文章}
みなさん、こんにちは!今日はBeamerで作ったスライドに自動で音声を付ける方法を紹介します。
まず、このtexファイルをlualatexでコンパイルすると、注釈付きのPDFファイルが生成されます。
ついで jbeam2vid スクリプトが PDF から注釈を抽出し、VOICEVOX を使って日本語音声を生成します。
そして最後に PDF と音声ファイルを組み合わせて動画が生成されます。
VOICEVOXを使って「ずんだもん」や「四国めたん」の声で音声を生成できますし、
日本語の句読点・カタカナ・漢字もすべて完璧に読み上げられます!
例:「こんにちは、世界!」「ぱちぱちぱち」「わーい!」
\pdfnarration{
みなさん、こんにちは!今日はBeamerで作ったスライドに自動で音声を付ける方法を紹介します。
まず、このtexファイルをlualatexでコンパイルすると、注釈付きのPDFファイルが生成されます。
続いて jbeam2vid スクリプトが PDF から注釈を抽出し、VOICEVOX を使って日本語音声を生成します。
そして最後に PDF と音声ファイルを組み合わせて動画が生成されます。
VOICEVOXを使って「ずんだもん」や「四国めたん」の声で音声を生成できますし、
日本語の句読点・カタカナ・漢字もすべて完璧に読み上げられます!
例:「こんにちは、世界!」「ぱちぱちぱち」「わーい!」}
\end{frame}
\begin{frame}{最後}
\Huge ご清聴ありがとうございました!
\pdfnarration{
ご清聴ありがとうございました!
}
\end{frame}
\end{document}
この beamer ファイルは、lualatex 前提です。なので表示確認などは
$ lualatex jsample.tex
で行ってください。
画像 clips/metan.png は坂本アヒル様の四国めたん立ち絵素材のPSDファイルを使用させて頂き、オンライン上の PSDTool にてPSDファイルから縮小PNGファイルを生成しました。画像のリサイズなどはスクリプト内で特に行っていないので、各自でリサイズとか行ってください。
動画の生成は、(jbeam2vid に PATH が通っていれば)
$ jbeam2vid -n metan -v 2 -f jsample.tex
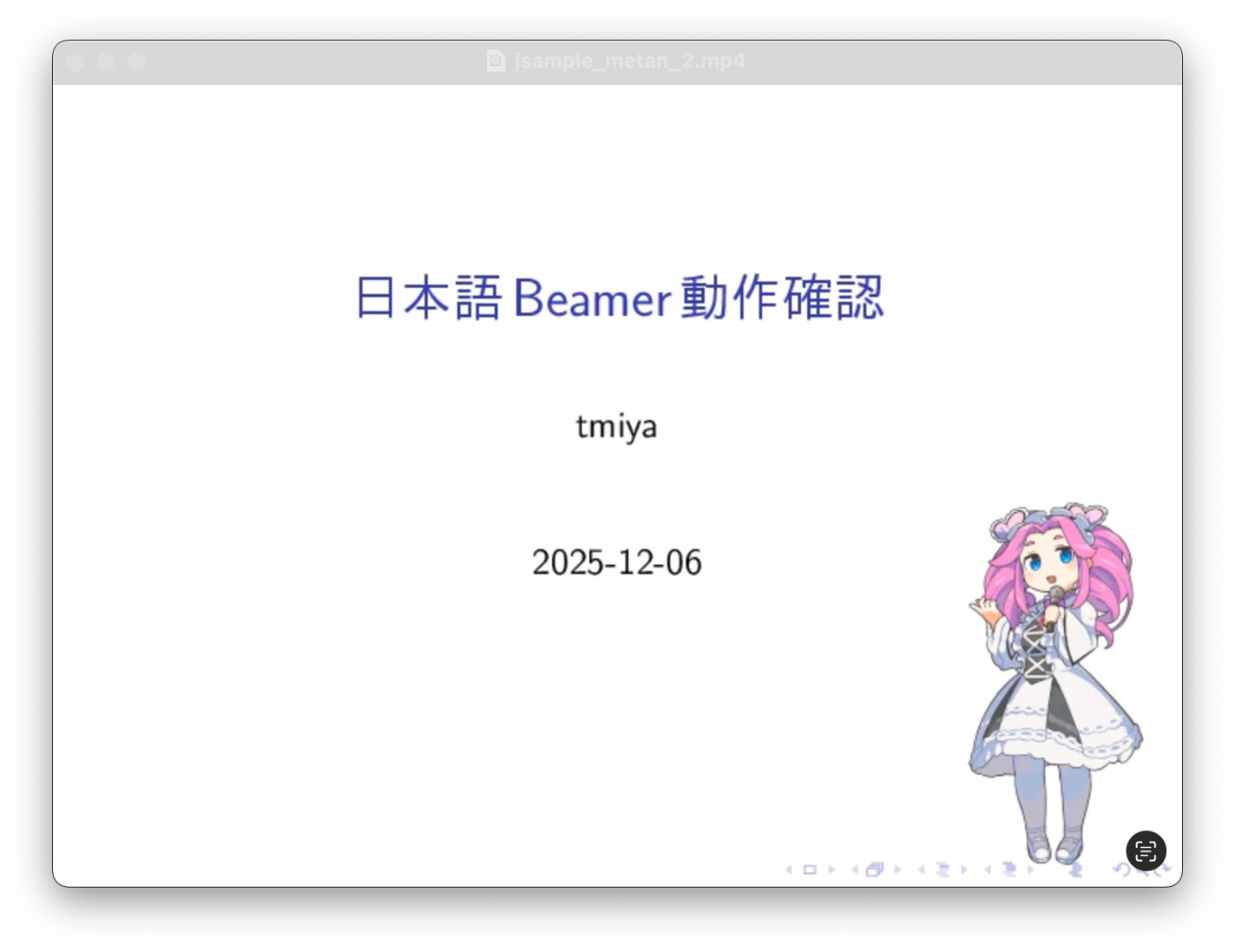
で行われます。生成された動画はこんな感じです。
動画は、github の方にはアップロードされていますので jsample_metan_2.mp4 などを見てください。
tex ファイルから PDF ファイルを作るところは、jbeam2vid の 33-34 行目で
33 lualatex --interaction=batchmode "\def\voice{$voice}\def\narrator{$narrator}\input{$base.tex}"
34 lualatex --interaction=batchmode "\def\voice{$voice}\def\narrator{$narrator}\input{$base.tex}"
としています。ここを修正すれば lualatex 以外の platex とかでも PDF ファイルを作成できます。
修正履歴
修正1 (2025/12/06)
読み上げ画像が Lisa.mp4 なのは声と画像が合ってなくて望ましく無いので、修正しました。
修正2 (2025/12/06)
PDFや動画に、アノテーションを示す赤い四角が表示されたり、ノートを示すアイコンが表示される問題がありました。jsample.tex の修正と、jbeam2vid を修正することで消しました。
今後の課題
-
-v 2の様に、VOICEVOX API の speaker の int 値で指定するようになってるのが良くない。 - 四国めたんの画像しか無い、口パク画像とかになってない。
Discussion