Unsloth で継続事前学習 + ファインチューニングする
Google Cloud のマネージドサービスでGemini のファインチューニングは成功したが、何をやってるのかよく分からなかったので、Unsloth ライブラリを使って真面目にやってみる。
LLM への知識植え付け(継続事前学習:Continued Pretraining)+ 出力形式変化((教師有)ファインチューニング)の両方を実施してみた。
実行環境
Google Cloud のColab Enterprise(Jupyter Notebook のマネージドサービス)を利用した。
詳細は後で述べるが24GB のGPU RAM が必要だったので、g2-starndard-8(us-east4 等で利用可能)のランタイムを建てた。1時間で$1程度の費用が発生するので無駄遣い注意。
実施内容
LLM
今回は簡単な短文しか覚えさせないので、3.7b の事前調整済モデルllm-jp/llm-jp-3-3.7b-instruct を利用した。
事前調整してないモデルだと、気持ちtokenizer.eos_token の利きが悪いような気がする...
※ 当然だが、日本語非対応モデル(unsloth/Meta-Llama-3.1-8B とか)だと話が変わる=別言語の学習になるので注意。本記事のカバー外。
データ
継続事前学習
色々試してみたが、継続事前学習で定着させた知識がファインチューニングで忘却する現象(破滅的忘却、catastrophic forgetting)に悩まされた。
今回は知識を大量に植え付けるのは諦め、蓮ノ空女学院スクールアイドルクラブの主要メンバー9人の声優を答えさせることのみを目指す。
作成したデータ数は、1人あたり5文 × 9人 = 45。本格的に継続事前学習やるならもっと必要だと思う。
日野下 花帆の声優は楡井希実(にれい のぞみ)である。
日野下 花帆の声優を務めるのは、楡井希実(にれい のぞみ)さんです。
楡井希実さんは、日野下 花帆役の声優として知られています。
日野下 花帆(CV:楡井希実)
日野下 花帆(CV:楡井希実)は、「ラブライブ!蓮ノ空女学院スクールアイドルクラブ」のメインキャラクターの一人です。
...
ファインチューニング
shi3z/Japanese_Wikipedia_Conversation を利用させて頂きました。Wikipedia の日本語版データセットを会話文にしたものです(商用利用不可)。
プログラム
継続事前学習
基本的にUnsloth のチュートリアル通り。
pip install
%%capture
!pip install unsloth
!pip uninstall unsloth -y && pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
'NoneType' object has no attribute 'attn_bias' のエラーが発生したので、以下も実施しておく。
参考)https://github.com/unslothai/unsloth/issues/1525
!pip install torch torchvision torchaudio xformers --index-url https://download.pytorch.org/whl/cu121
LLM ダウンロード
load_in_4bit = True に設定すると小さいGPU(T4とか)で学習・推論可能なのだが、Lora アダプタをベースモデルにマージすると推論が失敗する現象に遭遇。
(※ 継続事前学習後にファインチューニングを実施する(= Lora アダプタが異なる学習を実施する)場合、モデルのマージが必要)
どうも量子化による切り捨て誤差が原因ぽいので、False で進める。3.7b のモデルだとGPU RAM が20GB 以上必要だったので、L4 付のランタイムを利用した。
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048
dtype = None
load_in_4bit = False
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "llm-jp/llm-jp-3-3.7b-instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
Lora アダプタ設定
破滅的忘却に陥らないためにlora_alpha は大きめの値が良いとする記事を見かけたので、取り敢えず従ってみる。
参考)https://qiita.com/ikedachin/items/8c31b359ec7473e00595
model = FastLanguageModel.get_peft_model(
model,
r = 128,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
"embed_tokens", "lm_head"],
lora_alpha = 128,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
データセット作成
def gen():
with open("hasu.txt") as f:
for line in f:
yield {"text": line}
from datasets import Dataset
dataset = Dataset.from_generator(gen)
各データについて、トークンの終わり(EOS_TOKEN)を付与する必要あり。
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(examples):
return { "text" : [example + EOS_TOKEN for example in examples["text"]] }
dataset = dataset.map(formatting_prompts_func, batched = True,)
学習のハイパーパラメータ設定
よく分からないのでチュートリアル通り。max_steps のみ、何度か試してTraining Loss が収束するあたりに設定。
from unsloth import UnslothTrainingArguments, UnslothTrainer
trainer = UnslothTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 8,
args = UnslothTrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 8,
warmup_ratio = 0.1,
num_train_epochs = 1,
learning_rate = 5e-5,
embedding_learning_rate = 5e-6,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.00,
lr_scheduler_type = "cosine",
seed = 3407,
output_dir = "/content/outputs",
report_to = "none",
max_steps = 90,
),
)
学習開始
trainer_stats = trainer.train()
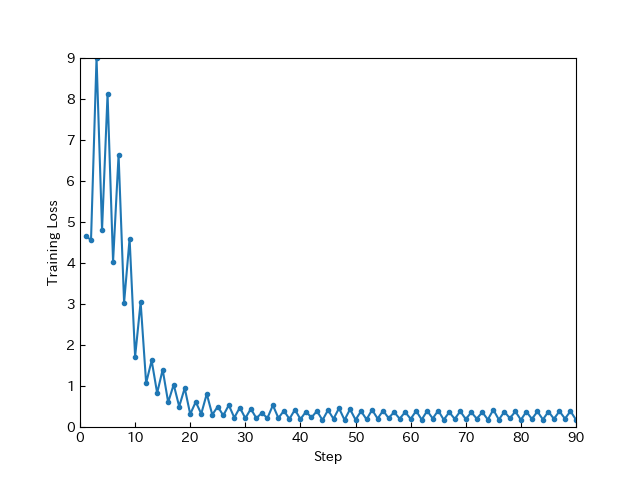
推論
この時点では、単に学習した文章の続きがそのまま吐ければOK。ここでうまく推論できない場合はファインチューニングしても当然失敗するので、ハイパラ調整を頑張るのみ。
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
"日野下 花帆"
], return_tensors = "pt").to("cuda:0")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
<s> 日野下 花帆の声優は楡井希実(にれい のぞみ)である。
</s>
保存
満足する結果になったら、Lora アダプタを一旦保存するのを推奨。
model.save_pretrained("/content/outputs/train")
tokenizer.save_pretrained("/content/outputs/train")
以降の手順で失敗しても、以下で保存したモデルをロードできる。
model, tokenizer = FastLanguageModel.from_pretrained(
model_name="/content/outputs/train/",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
Lora アダプタのマージ
以下でベースモデルにマージできる。load_in_4bit = False を設定したので、model.to(dtype=torch.bfloat16)は不要だった。
マージにより出力が変になっていないか、再度推論させてみることを推奨。
model = model.merge_and_unload()
マージしたモデルを保存する(これでGPU RAM がある程度解放される)。3.7b のモデルだと出力サイズは小さいので、数分で完了する。
model.save_pretrained_merged("/content/merged_model/", tokenizer, save_method = "merged_16bit",)
ファインチューニング
同様に、基本的にUnsloth のチュートリアル通り進める。
Lora アダプタ設定
継続事前学習と比較して、target_models から"embed_tokens", "lm_head" を除いているのに注意。
ファインチューニングではlora_alpha の値は小さい方が良いらしいので、これも取り敢えず従ってみる。
model = FastLanguageModel.get_peft_model(
model,
r = 8,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 8,
lora_dropout = 0,
bias = "none",
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False,
loftq_config = None,
)
データセット作成
- 元データセットはデータ数が多過ぎる気がしたので、適当に500程度に絞った。
- 学習データ形式としてAlpaca prompt が有名だが、日本語文章の学習に英文指示がどう効くのか分からないので、単純化 + 日本語化してみた。
from datasets import load_dataset
dataset = load_dataset("shi3z/Japanese_Wikipedia_Conversation", split="train")
dataset = dataset.train_test_split(train_size = 0.03)["train"]
prompt = """
### 質問:
{}
### 回答:
{}"""
EOS_TOKEN = tokenizer.eos_token
def formatting_prompts_func(examples):
inputs = [examples["conversations"][i][0]["value"] for i in range(len(examples["conversations"]))]
outputs = [examples["conversations"][i][1]["value"] for i in range(len(examples["conversations"]))]
texts = []
for input, output in zip(inputs, outputs):
text = prompt.format(input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts }
dataset = dataset.map(formatting_prompts_func, batched = True)
学習データは以下のような形式となる。ファインチューニングは出力形式を調整するもので、データの内容はあまり関係ないことに注意。
(破滅的忘却を防ぐために継続事前学習の学習データをファインチューニングの学習データに混ぜることもあるらしいので、全く内容を学習しない訳ではなさそうだが...)
### 質問:
宮川宗徳はどのような職業の経歴を持っていましたか?
### 回答:
宮川宗徳は内務省、文部省、東京市の官吏として働いていました。彼は文書課長や保健局長などの役職を歴任しました。また、東京市会議員にも当選しました。
(追記)チャットテンプレート設定
以前は必要なかった気がするが...
from unsloth.chat_templates import get_chat_template
tokenizer = get_chat_template(
tokenizer,
chat_template = "llama-3",
)
学習のハイパーパラメータ設定
これもよく分からないのでチュートリアル通り。ファインチューニングではTraining Loss が0.5 に収束するのが理想らしいが、破滅的忘却が怖かったのでかなり手前で打ち切った。
from trl import SFTTrainer
from transformers import TrainingArguments
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False,
args = TrainingArguments(
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
warmup_steps = 5,
max_steps = 20,
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.01,
lr_scheduler_type = "linear",
seed = 3407,
output_dir = "/content/outputs",
report_to = "none"
),
)
学習開始
trainer_stats = trainer.train()

推論
FastLanguageModel.for_inference(model)
inputs = tokenizer(
[
prompt.format(
"日野下 花帆の声優は誰?", # input
"", # output
)
], return_tensors = "pt").to("cuda:0")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
結果
9人全員の声優を正しく回答することができた。
<s>
### 質問:
日野下 花帆の声優は誰?
### 回答:
楡井希実(にれい のぞみ)さんです。
</s>
また、質問文を変えても正しく回答できた。
<s>
### 質問:
乙宗 梢ちゃんのCVってだれでしたっけ...教えてください
### 回答:
花宮初奈さんです。</s>
ただし名字と名前の間の半角スペースを抜いて質問すると間違えることもあった。これは継続事前学習が甘かったかな。
<s>
### 質問:
大沢瑠璃乃の声優は誰?
### 回答:
大沢 瑠璃乃の声優は葉山風花(はやま ふうか)である。
</s>
# 正しくは菅叶和さん
まとめ
今回覚えさせた知識は少ないが、やりたかったことはできたので満足。結局ハイパラ調整ゲーなので、継続事前学習 + ファインチューニングを破滅的忘却に陥らずに実施するのは大変なことが分かった。やっぱりRAG で十分やん
Discussion