技術書の積読を「耳で消化」:EPUBをTTSで音声化してみた
ランニング中に技術系ポッドキャストを聴くのが習慣になっているのですが、ある日ふと「これ、積んでる技術書も音声で聞けたら消化できるのでは?」と思いつきました。
そんなわけで、TTS(Text-to-Speech)を使って技術書を音声化してみることに。
テキストを自然に読み上げる技術にも興味があったので、いいきっかけになりました。
TTS(Text-to-Speech)の選定
テキストからの音声データ変換はTTSって呼ばれてるらしく(そのままだけど)、いくつかChatGPTに比較してもらう。

他の比較記事を参照していたところ、OpenAIが今年3月にサービスを開始したことを知り、試しにそちらを採用することに。ダメなら別のやつ切り替えることもできますし。
OpenAI.fm
トップページで試す事ができて分かりやすい。Scriptに日本語入れるとちゃんと日本語で話してくれる。
OpenAI PlatformはChatGPTとは別に契約する必要あり。ほぼクレカの情報入れるだけでしたが。
理由2は商用ライセンスが未整備、理由3は機能不足。ここら辺は確認してないのでほんとかどうかはわからない。

これも確認してないけど信じるしかないので信じて採用。今回の用途では問題ないと思う。
エンジニアあるある(余談)
5月にmacbookを購入して、まだ環境が整ってなかったので構築から。
homebrew入れてzshrc弄って、コード書くから言語のバージョン管理必要だなと思いrbenvとfnm入れ、ここまでデフォルトのターミナルでやってたけど、必要だと思い最近のターミナル事情調べてWave Terminalインストール。あっと言う間に2時間溶けた。
バイブコーディング試してみようかとGemini CLIを入れたのだが、日本語の入力がうまく出来ずに今回は断念した。
コードに取り掛かる

簡単そう
サンプルコードもpythonで提示してくれたが、一気に全部やる形でリスクが高く、手慣れてるRubyでやりたかったので却下
まずは処理を分割
- epubからテキストファイルに変換
- テキストファイルから音声データに変換
epubからテキストファイルに変換
内容が確認しやすいのと、音声ファイル自体も分けたいのでepubの内容を章毎にファイル別に保存する。
ChatGPTからの提案コードはこちら。それっぽい。
require 'epub/parser'
require 'nokogiri'
require 'fileutils'
input_path = './input/oreilly-978-4-8144-0114-7e.epub'
output_dir = './output/text'
FileUtils.mkdir_p(output_dir)
book = EPUB::Parser.parse(input_path)
chapter_index = 0
book.each_page_on_spine do |page|
begin
doc = Nokogiri::HTML(page.content_document.read)
raw_text = doc.text.strip
next if raw_text.empty? || raw_text.length < 100 # 短い断片は除外
# タイトル候補を取得(h1〜h3などを優先)
heading = doc.at('h1,h2,h3')&.text&.strip || "chapter_#{chapter_index}"
safe_title = heading.gsub(/[\/:*?"<>|]/, '_')[0, 50] # ファイル名として安全に&長さ制限
filename = format('%02d_%s.txt', chapter_index, safe_title)
filepath = File.join(output_dir, filename)
File.write(filepath, raw_text)
puts "✅ 書き出し: #{filepath}"
chapter_index += 1
rescue => e
warn "⚠️ 解析失敗: #{e}"
end
end
puts "完了: #{chapter_index}章を出力しました。"
ただChatGPTは対象のepubの内容知らないので、憶測でコードを書いてる。
実行自体はできたものの、期待していた形式の出力にはならず、ファイルの内容を確認しながら何度か試行錯誤を重ねる必要がありました。
自分でコードを書くこともできたが今回はあえてChatGPTの生成コードを使い、コピペで進める苦行を選びました。
epubからただテキスト変換すると、目で見る分には良いが音声にすると厳しい部分がいくつかありクリーニング作業が必要だった。リンクや注釈などを除去したり、章立て調整したり。
1.1 なぜエンジニアリング統括責任者を目指すのかだと最初の数字をワン ポイント ワンって読み上げたりとうまくいかなかったので置き換え処理を入れて1章1節 なぜエンジニアリング統括責任者を目指すのかにした。意味が通らない訳ではないが、音声で聞いたときに違和感のある表現は、できる限り取り除くようにしました。
コードを提案してもらって自分で実行して出力確認して、改善ポイントをChatGPTに伝えて再度コードを出してもらう。指示の仕方によるんだろうが、コードの出力が安定しない。依頼毎に一部コードが抜け落ちたりするのでかなり気を使う。部分毎で出してもらう形もやったが全体を意識しなくなったりするので下書きだけもらって自分でやった方が楽だった。
苦行の末、納得いく形でテキスト出力ができた。

良かった点はnokogiriのインストールが1回で上手く行ったこと。
テキストファイルから音声データに変換
ここは一気にやると、試行錯誤難しいのとお金もかかるので章ごとのテキストファイル1件を音声データ1件に変換する形にする。
あとからループにまとめたり、リストにして一括で流すこともできるので、今回はシンプルに1章ずつ進めてます。
処理自体も分割して段階実装
- OpenAIに送信できる文字数に制限があるので章ごとのテキストファイルを制限超えない形で分割
- 分割されたテキストファイル単位でOpenAIにリクエストしてmp3ファイルを作成
- 分割されたmp3ファイル群をffmpegで結合
ChatGPTのコードにちょっと手を加えた形。自分ならこんなコードは書かないが使い捨てなので諦める。
require 'fileutils'
require 'uri'
require 'net/http'
require 'json'
require 'openssl'
input_path = 'files/text/006_chapter_001.txt' # 入力ファイル
max_chars = 4096
basename = File.basename(input_path, ".*")
tmp_dir = File.join("files/tmp", basename)
FileUtils.mkdir_p(tmp_dir)
paragraphs = File.read(input_path).split(/\n{2,}/).map(&:strip)
chunks = []
current_chunk = ""
paragraphs.each do |para|
if (current_chunk + "\n\n" + para).size > max_chars
chunks << current_chunk.strip
current_chunk = para
else
current_chunk += "\n\n" unless current_chunk.empty?
current_chunk += para
end
end
chunks << current_chunk.strip unless current_chunk.empty?
uri = URI("https://api.openai.com/v1/audio/speech")
api_key = 'OpenAI Platformで発行してね'
instructions = <<~EOS
声: 温かく、共感的で、プロフェッショナルであり、顧客の問題が理解され、解決されることを安心させる。
句読点: 自然な間があり、明瞭で安定した落ち着いた流れを可能にする。
デリバリー: 穏やかで忍耐強く、聞き手を安心させるサポートと理解のある口調。
トーン:共感的で解決策を重視し、理解と積極的な支援の両方を強調する。
EOS
chunks.each_with_index do |chunk, idx|
filename_txt = format("%03d.txt", idx + 1)
filepath_txt = File.join(tmp_dir, filename_txt)
File.write(filepath_txt, chunk)
puts "✅ Wrote: #{filepath_txt} (#{chunk.length} chars)"
filename_mp3 = filename_txt.sub(/\.txt$/, ".mp3")
filepath_mp3 = File.join(tmp_dir, filename_mp3)
req = Net::HTTP::Post.new(uri)
req["Authorization"] = "Bearer #{api_key}"
req["Content-Type"] = "application/json"
req["OpenAI-Beta"] = "assistants=v2"
req.body = {
model: "tts-1",
input: chunk,
voice: "echo",
speed: 1.0,
response_format: "mp3",
instructions: instructions.strip
}.to_json
Net::HTTP.start(uri.host, uri.port, use_ssl: true) do |http|
http.request(req) do |res|
if res.code.to_i == 200
File.open(filepath_mp3, "wb") do |f|
res.read_body { |chunk| f.write(chunk) }
end
puts "🎧 MP3 created: #{filepath_mp3}"
else
warn "⚠️ Failed MP3 for #{filename_txt} - #{res.code}: #{res.body}"
end
end
end
end
# === ffmpegで結合 ===
output_path = File.join("files/mp3", "#{basename}.mp3")
concat_txt = File.join(tmp_dir, "concat.txt")
mp3_files = Dir[File.join(tmp_dir, "*.mp3")].sort
File.open(concat_txt, "w") do |f|
mp3_files.each { |mp3| f.puts "file '#{File.expand_path(mp3)}'" }
end
puts "🔄 Concatenating MP3 files..."
ffmpeg_cmd = [
"ffmpeg", "-y",
"-f", "concat", "-safe", "0",
"-i", concat_txt,
"-c", "copy",
output_path
]
system(*ffmpeg_cmd) or warn "❌ ffmpeg failed"
puts "🎉 Final MP3 created: #{output_path}"
土日合わせて8時間くらいかかって、ようやく納得できそうな1章分が完成した。
音声化したmp3を実際に聴いてみたところ、再生時間は約30分ほどでした。細かい点で多少の違和感はあるものの、デモサイトで試したのとほぼ変わりはないビジネス書の内容を把握するには十分な品質です。
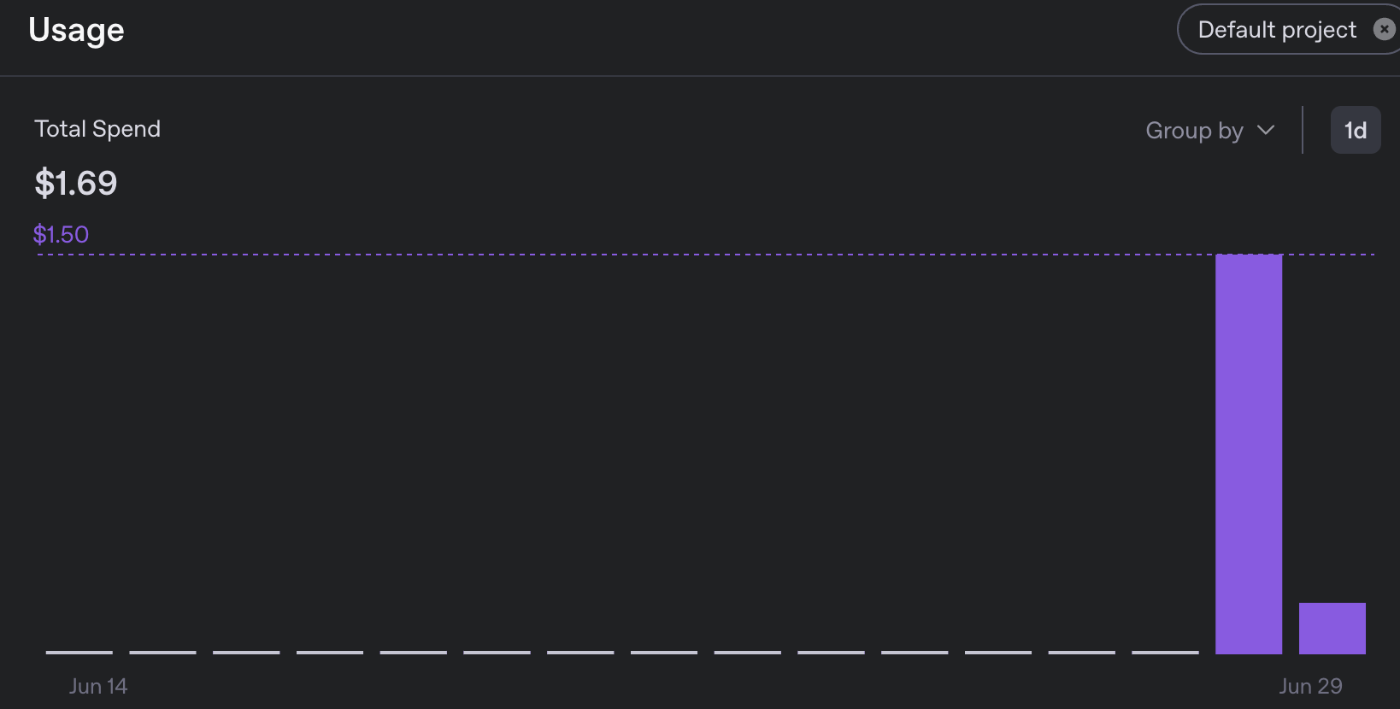
大体$1.69くらい。7割くらいテストでtts-1-hd(良いモデル)試してますが、本番の3割はtts-1(普通のモデル)使ってます。1章出力するのに$0.5いかないくらいかと思います。
全部で25章あるので、$10〜$20で収まるはず。
対象の書籍はこちら。テストで1章を繰り返し聞いたのですが面白そうなので残りを聞くのが非常に楽しみ。
ランニング時のコンテンツが増えて非常に満足です。
著作権についての補足
本記事では、EPUB形式の技術書をTTSで音声化し、自分自身の学習のために私的に利用する方法を紹介しています。
著作権法第30条では「私的使用のための複製」が認められており、購入した書籍を自分だけで聴く範囲であれば問題ないと考えています。
この記事を参考に実施される場合も、私的利用の範囲にとどめてください。
他人と共有したり、商用に利用するなどの行為は対象外となる可能性があるためご注意ください。
続き書きました
Discussion