コンピュータ囲碁講習会2023に参加してきました
ひょんなことから、電気通信大学が主催しているコンピューター囲碁講習会というものがあることを知り、自身の技術力と棋力の向上に繋がればと思い参加してきました。
講義資料や講習会の様子等は上記のサイトにて公開されているため、ここでは講習会のサマリとして、自身が特に興味深いと感じた点についてレポートしたいと思います。
1日目(講習会)
1日目は「純碁」で囲碁の本質的な部分を簡単に学び、その後は囲碁AIの歴史、手法についての学習が中心でした。
純碁
囲碁AIを実装する上で、囲碁の基本的なルールを知っておくと有利です。囲碁のルールを手っ取り早く学べるゲームとして、囲碁棋士の王銘琬氏が考案した純碁があります。
王氏が講習会会場にお見えになり、直々にご指導いただきました。囲碁より盤面が小さく、勝利条件も囲碁よりシンプルになっているため、効率的にルールを学べます。そして、このゲームで学んだエッセンスをそのまま囲碁にも応用できるところが純碁の大きな特長だそうです。

囲碁を学びたい方はもちろんのこと、囲碁には詳しくないが囲碁AIを作ってみたい方にもピッタリの教材と感じました。
囲碁AIの強さの歴史
囲碁AIの歴史は意外と古く、1980年代には既に存在していました。しかし、2000年代になってもアマチュアの平均的な強さしか持ち合わせていませんでした。
2000年代半ばにモンテカルロ木探索という手法が登場すると、徐々に強くなり始め、2010年代半ばにはトップアマくらいの強さになりました。とはいえ、このままであれば、トッププロに勝てるようになるまでにはあと数十年かかるだろうと思われていました。
ところが、その数年後に、機械学習、特に深層学習(ディープラーニング)を用いたプログラム AlphaGo が登場すると、一瞬でトッププロを抜き去り、もはやヒトは囲碁AIに勝つことは出来なくなりました。
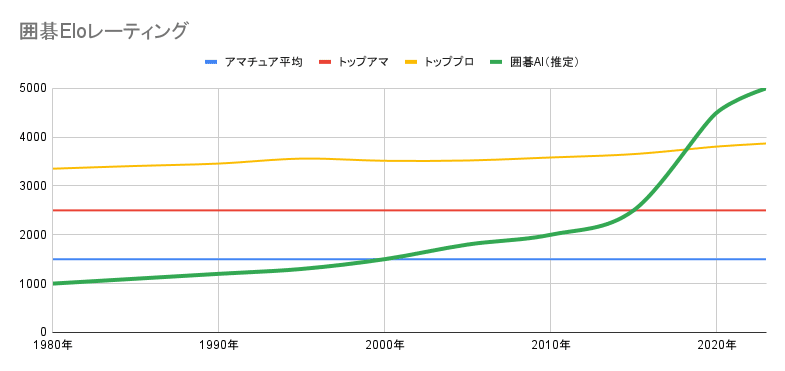
上記から分かる通り、囲碁AIの強さのブレイクスルーは今までに2回起きています。
- モンテカルロ木探索の導入
- 機械学習の導入
原始的な方法
そもそも囲碁AI強化における課題として、下記の2点があります。
- 囲碁はルール上禁止されている一部の点を除いてはどこに石を打ってもよい(=着手してよい)ため、その中から有利となりそうな着手点をいくつか見つける必要がある
- 見つけた着手点について、それぞれどのくらい有利になるのかを相対的に評価できる必要がある
課題への対応案の1つとしてゲーム木探索があります。
囲碁は二人のプレイヤーが交互に着手点を1つ選んで着手するため、各々が選ばなかった着手点も含めると、その選び方のパターンは木構造で表すことができます。
リバーシでの例
―― https://www.webcyou.com/?p=6997 から引用
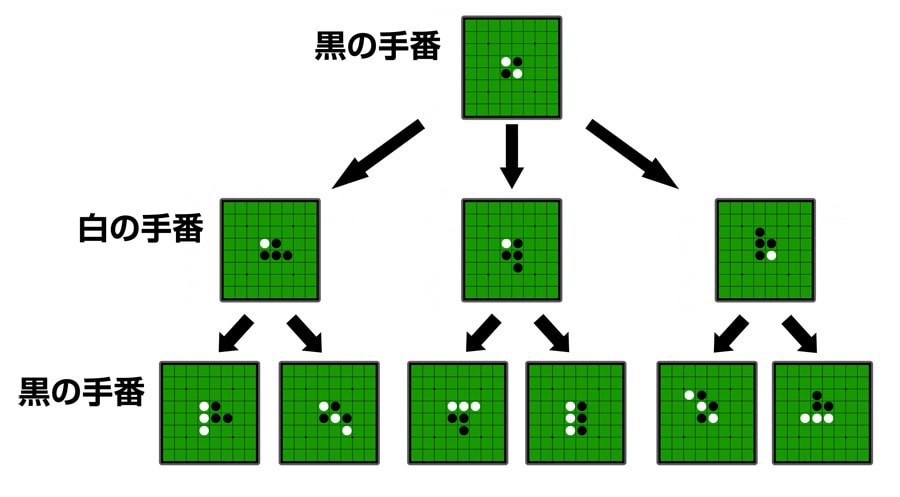
事前にそれぞれの選び方ごとにどのくらい有利になるのかを調べれば、明らかに不利になりそうな着手は除外することができます。
効率よく有利・不利を判定する方法として、主に下記の方法があります。
- ミニマックス法
- アルファベータ法
ただし、囲碁においてはこの有利・不利を精度良く判定することが非常に難しく、長らくこの方法で囲碁AIを強くすることは難しい状態でした。
そこで使われるようになったのが、モンテカルロ法によるシミュレーションで有利・不利を判定する方法です。
モンテカルロ木探索
モンテカルロ法は、ランダム性を用いて確率論で近似解を得る手法です。例えば、サイコロを3つ振ったときに全ての目が異なる確率は組み合わせの数で計算できます。
実際に何度もサイコロを3つ振ってみて結果を集計することでもこれに近い値を求められます。
| 回数n | サイコロA | サイコロB | サイコロC | 累計のゾロ目回数m(n) |
|---|---|---|---|---|
| 1 | 1 | 6 | 6 | 1 |
| 2 | 4 | 3 | 2 | 1 |
| 3 | 2 | 5 | 5 | 2 |
| ... | ... | ... | ... | ... |
| 998 | 3 | 6 | 5 | 563 |
| 999 | 1 | 1 | 1 | 564 |
| 1000 | 5 | 2 | 4 | 564 |
囲碁においては、数手ほど着手したら、後はランダムに最後まで着手をして勝ったか負けたかを判定し、これを何度も試行することで、数手ほど着手した手の勝率として推定することができます。
ただし、この方法でも勝率が正しく出ない場合があります。囲碁においては、シチョウや隅・辺の死活など、手順が長いが正しく打てば勝てるというケースが発生します。

上記は四目ナカデにして白を取る例ですが、黒は黒9まで正しく打つ必要があります。また、白は必ずしもこの手順で打つとは限らず、別の手順を示してきた場合でも、黒はその都度、別の手順で正しく打つ必要があります。モンテカルロ法は基本的にランダム性を使うため、このように手順が長いケースでは正しい手順を選べる確率自体が低くなってしまい、白を取れないと判断してしまう可能性が高いです。
機械学習とAlphaGoの台頭
2010年代半ばに、今までより格段に強い囲碁AIが登場しました。特に、DeepMind社が開発したAlphaGoはプロに互先[1]で勝利するほどの腕前を持っていました。
AlphaGoが画期的だったのは、今までのモンテカルロ木探索に加え、着手の絞り込みや有利・不利の判定に、ニューラルネットワークを用いた機械学習を取り入れたことです。特に囲碁は、盤面上の石の配置を黒、白、黃(盤の色)の3色の19x19のサイズの画像と捉えることもできるため、画像分類によく用いられる手法を使うことができます。

AlphaGoは、大量のヒトの棋譜[2]を教師データとして、どこに打つと有利になりやすいのかを学習しています。これにより、モンテカルロ木探索をする上で、どこに着手すると良いかを効率的に探せるようにしています。(各着手点における有利・不利の評価をPolicyと呼んでいます)
また、そのようにして学習したモデルで実際に自己対戦を行い、ある局面における着手の選択、それによる勝ち負けを学習し、今の局面は勝てそうかどうかをより正確に判定できるようにしています。(ある局面における勝率の評価をValueと呼んでいます)
―― 小林氏の講義資料から引用

これにより、ヒトらしい着眼点を学習し、囲碁AIはかつてないほどの早さでプロに匹敵する棋力を手に入れたのです。
AlphaGo Zero
AlphaGoは更に改良され、もはや学習に人間の棋譜を使うことはなくなりました。与えられた囲碁のルールだけを頼りに自身で対局し、その結果から強化学習します。
その棋力は遂にプロをも凌駕し、以前からヒトが発見していた定石[3]はもちろんのこと、ヒトでは思いつかない難しい手や新しい定石も発見するようになりました。そして、今ではアマもプロも囲碁AIから学ぶ時代になっています。
AlphaGo Zeroで得た知見を活かし、将棋やチェス等のボードゲームにも展開されたAlpha ZeroというAIも開発されています。
2日目(ミニ大会)
2日目は、小林氏が事前に用意した基本的な対局機能を備えた囲碁AIプログラム TamaGo を各受講者が改良し、より強い囲碁AIにしてグループ総当たり戦で対局するという内容でした。
以下は自身の取り組みについての紹介となります。
なお、自身は機械学習については全く詳しくないため、小林氏から示されたいくつかの改良ポイントを実践することにしました。
ニューラルネットワークのフィルター数、ブロック数の変更
まず、手軽にできて効果が大きいと話のあった、ニューラルネットワークのフィルター数、ブロック数の変更を試しました。
- フィルター数:64→128
- ブロック数:6→12
このあたりの変更が何に影響を与えているのかはよく分かりませんでした...。
畳み込みニューラルネットワークの基本を学ぶ必要がありそうです。
この変更により、教師あり学習にかかる時間が約8倍ほどになりましたが、変更前のモデルとの自己対戦では勝率が約80%になったため、かなり改善はされていそうでした。
教師データの多様化
元のプログラムでは
- 囲碁クエストアプリでレートが高い方の対局データ約50,000局
から学習したそうですが、今回は
- 囲碁クエストアプリでレートが高い方の対局データ5,000局
- 他の囲碁AI同士の対局データ5,000局
を組み合わせて10,000局にして学習しました。
ヒトが打つ手とAIが打つ手を両方学ぶことで、より汎用的なモデルとなるのではと考えたためです。
本当は各50,000局ずつの100,000局で学習する予定でしたが、あまりにも学習に時間がかかってしまう状況になってしまったため、今回は断念しました。
この変更により、教師あり学習にかかる時間が約1/5倍ほどになり、変更前のモデルとの自己対戦では勝率が約55%になったため、改善されているかは少し微妙そうです。ただ、学習にかかる時間も込みで考えると効率は良さそうです。
入力特徴の追加
自身は機械学習の分野での改良では勝負できないと考えたたため、囲碁の知識で対抗する方針にしました。
元のプログラムでは下記の6つの特徴を与えています。
- 石のない位置
- 自分の石の位置
- 相手の石の位置
- 最後の着手点
- 最後の着手がパスか否か
- 手番の色
今回はそれに加え、
- 自分の石の空きダメ[4]の数(3パターン)
- 相手の石の空きダメの数(3パターン)
- 単石へのツケがあるか(1パターン)
- 二目の頭が叩けるか(1パターン)
を追加しました。
この変更により、教師あり学習にかかる時間が微増しましたが、変更前のモデルとの自己対戦では勝率が約95%になったため、こちらについてもかなり効果がありそうです。
ちなみに、AlphaGoでは48もの入力特徴を与えているようです。
空きダメ
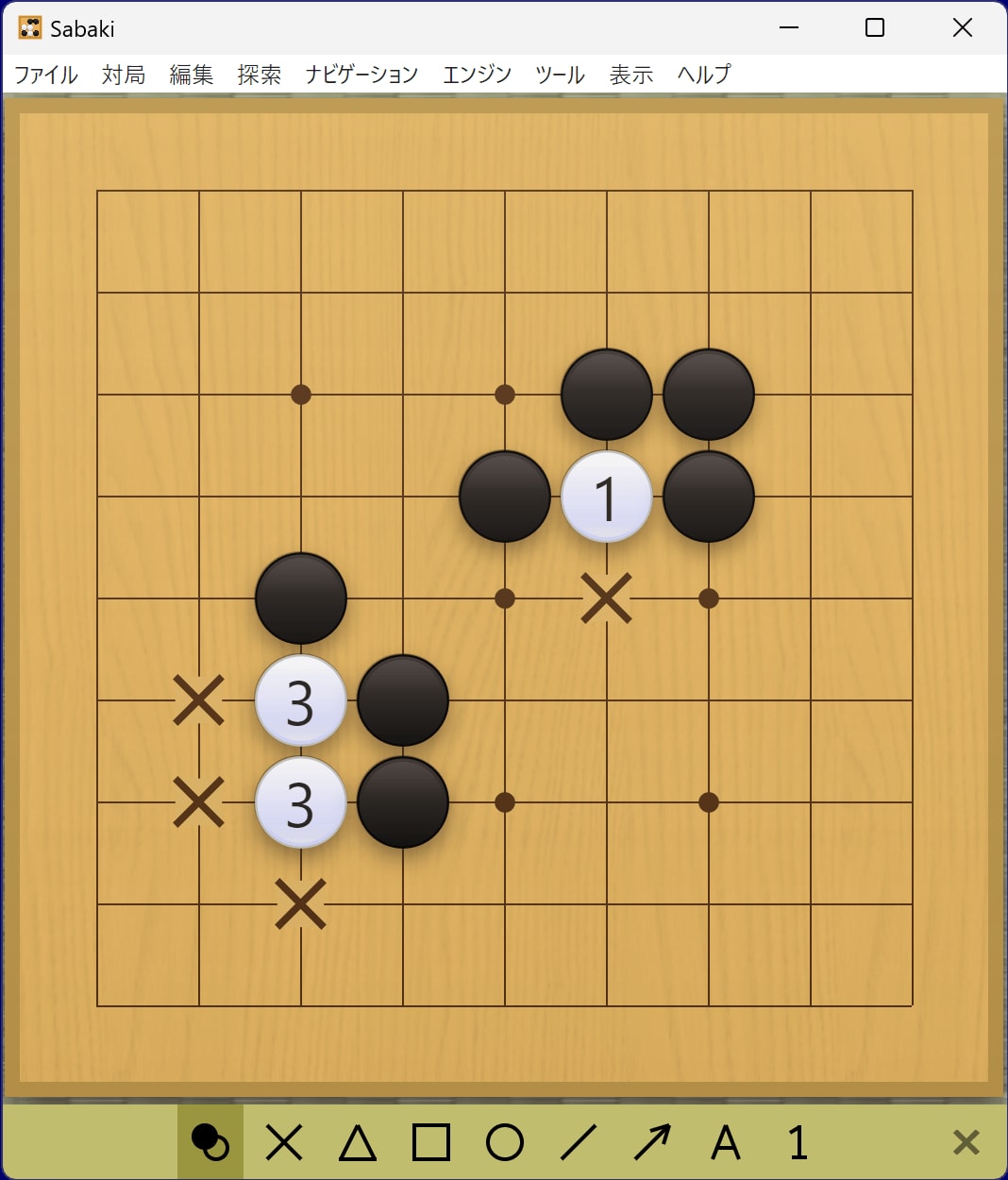
空きダメの入力特徴の与え方は2パターンあります。
1つは、下図のバツ印の部分が空きダメなので、白石以外の場所は0、白石の場所について1や3として与えます。
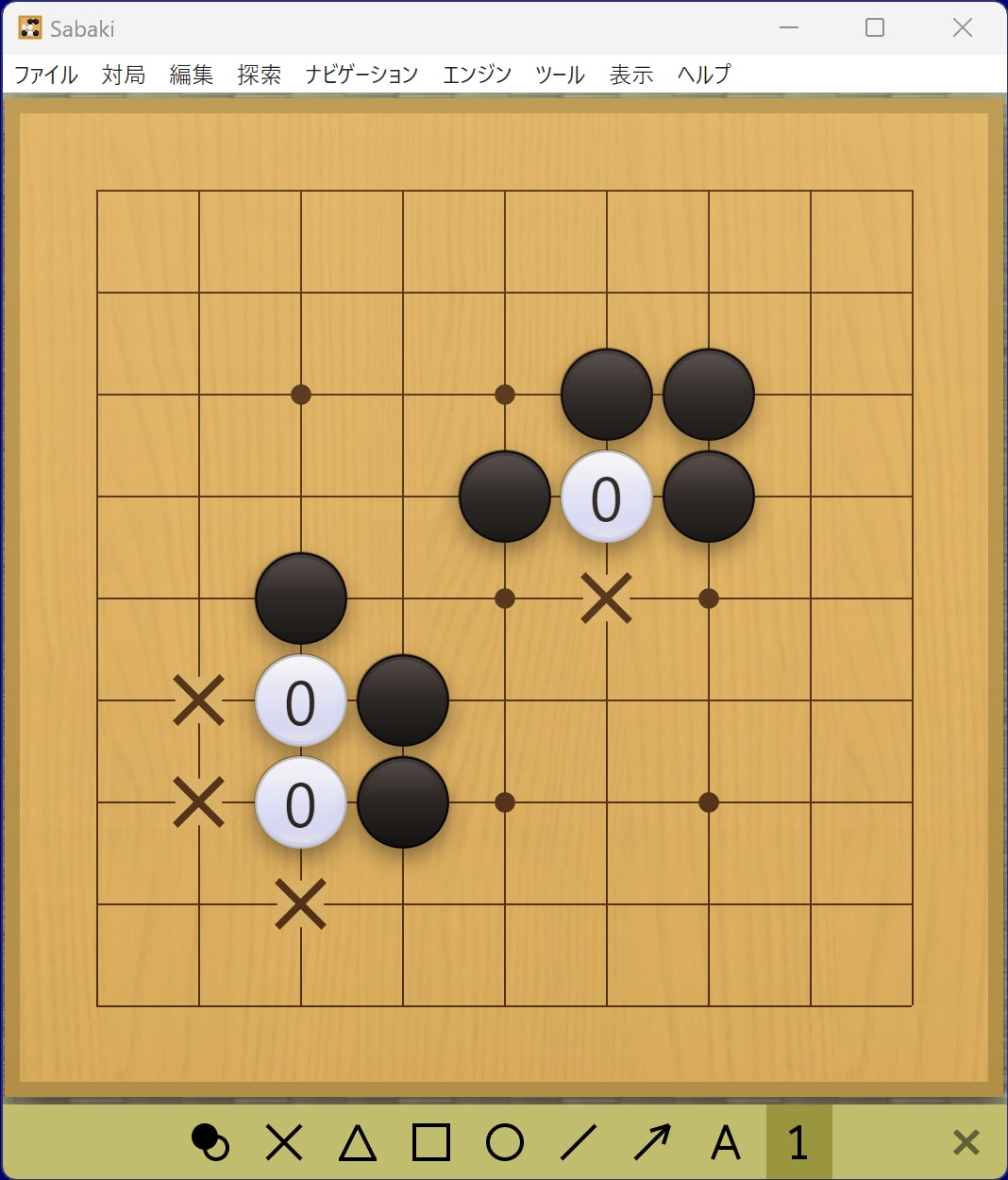
もう1つは、それぞれの空きダメの数ごとに当てはまるところを1、それ以外を0として与えます。
| 空きダメ1 | 空きダメ2 | 空きダメ3 |
|---|---|---|
 |
 |
 |
このようなデータ化の手法を One-hot encoding というそうです。今回は時間の都合で両方は検証できませんでしたが、小林氏曰くOne-hot encodingの方が賢いモデルになるそうなので、今回はこちらのパターンを採用しました。
ただ、いくつものパターンを用意するのは入力特徴が多くなりすぎて現実的ではありません。実際の対局においては、空きダメについて以下の目安があるため、それを採用して3パターンに圧縮しました。
- 2以下:取られてもおかしくない
- 3:気をつけてないと取られるかもしれない
- 4以上:すぐ取られることはない
単石へのツケ、二目
また、自身がよく活用する格言も特徴として入れてみたいと思い、下記を取り入れてみました。
- ツケにはハネよ
- 二目のアタマはハネよ

左下がツケへのハネ、右上が二目のアタマをハネた図です。どちらも1の場所に打たれた場合、次に三角の場所に打つと状況が良くなる場合が多く、逆に相手にそこに打たれると状況が悪くなる場合が多いです。
よって、着手によってこういった状況が発生した場合に、その部分を特徴として入力することにしました。
まとめ
上記3つの改良を加えて、6人のグループで総当り戦に臨みました。
対局中は自身が思ったところへ着手しないケースもあり不安を感じていましたが、4勝1敗でまずまずの結果でした。
あまり知らなかった囲碁AIの発展の歴史や、最新の囲碁AIの手法など、手を動かしながら学べた点は非常に有意義でした。より囲碁への興味と理解を深められた気がします。
最後に、今回改良したプログラムのソースコードを掲載しておきます。
参考文献
- https://ja.wikipedia.org/wiki/コンピュータ囲碁
- https://www.goratings.org/ja/history/
- https://ja.wikipedia.org/wiki/モンテカルロ木探索
- https://qiita.com/thun-c/items/058743a25c37c87b8aa4
- https://ai-kenkyujo.com/artificial-intelligence/ai-architecture-02/
- https://qiita.com/icoxfog417/items/5fd55fad152231d706c2
- https://sagantaf.hatenablog.com/entry/2019/05/26/160401
Discussion