OpenSearch 3.0 は、プロジェクトの継続的なパフォーマンス向上の道のりにおける重要なマイルストーンであり、2022 年 4 月の 2.0 以来の最初のメジャーリリースです。2.x シリーズの拡張機能をベースに、3.0 リリースは Apache Lucene 10 を統合し、Java ランタイムを JDK 21 にアップグレードし、検索スループット、インデックス作成とクエリのレイテンシ、ベクトル処理に大幅な改善をもたらしました。検索パフォーマンスが 10 倍向上し、ベクトル検索パフォーマンスが 2.5 倍向上した Lucene 10 は引き続き戦略的な検索ライブラリであり、最新バージョンでは、拡張されたクエリ実行、スキップベースのフィルタリング、セグメントレベルの並行処理により、以前のリリース (1.x と比較) と比べて測定可能な改善を提供します。
本記事では、OpenSearch 3.0 のパフォーマンスについて詳細な更新情報を提供し、検索クエリ、インデックス作成スループット、人工知能と機械学習 (AI/ML) のユースケース、ベクトル検索ワークロードに焦点を当てています。ベンチマークで観測された測定可能な影響を強調し、同時セグメント検索、クエリ最適化、doc-value スキップリスト、プリフェッチ API などの新しい Lucene 10 機能が将来の OpenSearch ロードマップにどのように貢献するかを説明します。コミュニティの透明性と実世界への影響に焦点を当てるため、すべての結果はベンチマークデータによって裏付けられています。
OpenSearch 3.0 でのクエリパフォーマンスの改善
OpenSearch 3.0 は、以下のグラフに示すように、2.x ラインを通じて達成された着実なパフォーマンス向上を継続しています。OpenSearch 1.3 と比較して、OpenSearch 3.0 でのクエリレイテンシは約 90% 削減されました (主要なクエリタイプ全体の幾何平均)。つまり、クエリは平均して 1.3 の 10 倍以上高速になりました。より最近の 2.x バージョンと比較しても、3.0 のクエリ操作は OpenSearch Big5 ワークロードにおいて 2.19 (最後の 2.x リリース) よりも約 24% 高速です。

以下の表は、バージョン 1.3.18、2.x、および 3.0 全体のレイテンシベンチマークをまとめたものです。
Big 5 エリアの平均レイテンシ (ms)
本表は OpenSearch バージョン別の Big5 ベンチマーク平均レイテンシ (ms) を示しています。値が低いほどパフォーマンスが良好です。
| クエリタイプ | 1.3.18 | 2.7 | 2.11 | 2.12 | 2.13 | 2.14 | 2.15 | 2.16 | 2.17 | 2.18 | 2.19 | 3.0 GA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| テキストクエリ | 59.51 | 47.91 | 41.05 | 27.29 | 27.61 | 27.85 | 27.39 | 21.7 | 21.77 | 22.31 | 8.22 | 8.3 |
| ソート | 17.73 | 11.24 | 8.14 | 7.99 | 7.53 | 7.47 | 7.78 | 7.22 | 7.26 | 9.98 | 7.96 | 7.03 |
| Terms 集約 | 609.43 | 1351 | 1316 | 1228 | 291 | 293 | 113 | 112 | 113 | 111.74 | 112.08 | 79.72 |
| 範囲クエリ | 26.08 | 23.12 | 16.91 | 18.71 | 17.33 | 17.39 | 18.51 | 3.17 | 3.17 | 3.55 | 3.67 | 2.68 |
| 日付ヒストグラム | 6068 | 5249 | 5168 | 469 | 357 | 146 | 157 | 164 | 160 | 163.58 | 159.57 | 85.21 |
| 集計 (幾何平均) | 159.04 | 154.59 | 130.9 | 74.85 | 51.84 | 43.44 | 37.07 | 24.66 | 24.63 | 27.04 | 21.21 | 16.04 |
OS 1.3 と比較した速度向上係数 (幾何平均)
本表は OpenSearch 1.3 をベースラインとした速度向上係数を示しています。
| 1.3.18 | 2.7 | 2.11 | 2.12 | 2.13 | 2.14 | 2.15 | 2.16 | 2.17 | 2.18 | 2.19 | 3.0 GA |
|---|---|---|---|---|---|---|---|---|---|---|---|
| N/A | 1.03 | 1.21 | 2.12 | 3.07 | 3.66 | 4.29 | 6.45 | 6.46 | 5.88 | 7.50 | 9.92 |
OS 1.3 と比較した相対レイテンシ (幾何平均)
本表は OpenSearch 1.3 をベースラインとした相対レイテンシを示しています。
| 1.3.18 | 2.7 | 2.11 | 2.12 | 2.13 | 2.14 | 2.15 | 2.16 | 2.17 | 2.18 | 2.19 | 3.0 GA |
|---|---|---|---|---|---|---|---|---|---|---|---|
| N/A | 97.20 | 82.31 | 47.06 | 32.60 | 27.31 | 23.31 | 15.51 | 15.49 | 17.00 | 13.34 | 10.09 |
OpenSearch 3.0 リリースは、主に 2 つの領域で検索パフォーマンスの向上をもたらします。
-
Lucene 10 による改善: Lucene 10 は、SIMD アクセラレーションによるベクトルスコアリングやより効率的なポスティングデコードなど、ハードウェアレベルの拡張機能を導入し、設定変更なしですぐにクエリパフォーマンスを向上させます。例えば、分単位の日付ヒストグラム集約は最大 60% 高速化し、
search_afterクエリは 20 ~ 24% 改善され、スクロールクエリは Lucene 10 と JDK 21 の両方の低レベルの拡張により、レイテンシがわずかに減少しています。 -
OpenSearch 固有のエンジン最適化: 前回のアップデート以降、OpenSearch コミュニティはバージョン 2.18、2.19、および 3.0 で複数の対象を絞った最適化を実装しました。これには、コストベースのクエリ計画、高頻度の terms クエリの最適化処理、Lucene 10 アップグレードで失われた時系列ソート最適化の復元、集約エンジンの改善、リクエストキャッシュの並行性の強化、および Lucene に起因する回帰 (例えば、ソートとマージの遅延) の解決が含まれます。さらに、OpenSearch 3.0 は自動有効化されたセグメントの並列検索を導入し、コストの高いクエリを選択的に並列化し、
date_histogramやtermsaggregation などの操作で 2 桁のレイテンシ削減を実現します。
パフォーマンスのハイライト
以下のセクションでは、OpenSearch 3.0 の主要なパフォーマンスのハイライトについて説明します。
Lucene 10 の改善点
Lucene 10 へのアップグレードにより、SIMD ベクトル化と改善された入出力パターンを使用した即時の高速化が導入されました。OpenSearch 3.0 はこれらの利点を継承し、複雑なクエリ文字列検索では 2.19 と比較して p50 レイテンシが約 24% 減少しています (issue #17385)。高カーディナリティ集約などの他の操作も、エンジン変更のみで約 10 ~ 20% 改善されました。さらに、OpenSearch は Lucene 10 への移行によって引き起こされたいくつかの回帰を解決しました。これには、キーワードフィールドでの composite_terms 操作のパフォーマンス低下 (#17387, #17388) が含まれます。これらの修正により、OpenSearch 3.0 でのキーワード重視のフィルターと集約は、2.x シリーズの同等のものと同等かそれ以上のパフォーマンスを発揮するようになりました。
クエリ操作の改善 (OpenSearch 1.3.18 および 2.17 と比較)
クエリ実行をさらに加速するために、OpenSearch はコア操作全体で対象を絞った最適化を導入しました:
-
テキストクエリ: 全文検索クエリの中央値レイテンシは、1.3 の約 60 ms と比較して 3.0 では約 8 ms です (約 87% 高速)。2.19 では、コストベースのフィルター計画と早期句の除外によってほとんどの改善が達成されました。さらに、Boolean スコアラーの改善により、3.0 での末尾レイテンシが削減されました。2.17 (約 21.7 ms) と比較すると、これは約 3 倍の高速化です (#17385)。
-
Terms aggregation: レイテンシは 1.3 の約 609 ms から 3.0 では約 80 ms に低下しました (約 85% 高速; 2.17 と比較して約 30%)。改善点には、最適化されたグローバル序数、よりスマートな doc values アクセス、カーディナリティ集約メモリ使用量を制御するための実行ヒントが含まれます (#17657)。範囲制約の近似フィルタリングも、オブザーバビリティユースケースでのスキャンコストを削減しました。
-
ソートクエリ: ソートされたクエリは 1.3 よりも約 60% 高速で、2.17 よりも約 5 ~ 10% 高速です。OpenSearch 3.0 は、新しい
searchAfterPartition() APIを正しく呼び出し (PR #17329)、desc_sort_timestampクエリでの回帰を解決することで (#17404)、Lucene の時系列ソート最適化を復元しました。 -
日付ヒストグラム: レイテンシは 1.3 の約 6 秒から 3.0 では約 146 ms に低下し、並行処理を使用すると約 85 ms の低さになりました (最大 60 倍高速)。ブロックスキップ、セグメントレベルの並列処理、サブ集約の最適化 (例えば、range-auto-date 集約内部へのフィルターの移動) からの改善があります。3.0 はこのカテゴリで 2.19 よりも最大約 50% 高速です。
-
範囲クエリ: 範囲フィルターは現在、1.3 の約 26 ms から約 2.75 ms で実行されます (約 89% 高速) また、2.19 よりも約 25% 高速です。OpenSearch の範囲近似フレームワークは 3.0 で一般提供となり、doc values のより効率的な使用と一致しないブロックのスキップによる改善をもたらし、スキャンコストをさらに低減しました。
ログ分析のためのスターツリーインデックス
2.19 で導入された star-tree aggregator は、事前集約されたメトリックとフィルタリングされた terms クエリを可能にします。対象となるユースケースでは、クエリの計算を最大 100 倍削減し、キャッシュ使用量を約 30 倍削減します。3.0 では、マルチレベルと数値 terms 集約のサポートを拡張し (ソートされたバケット除外を含む)、ベンチマークで 2.19 よりも約 15 ~ 20% 低いレイテンシを達成しています。
同時セグメント検索 (自動モード)
OpenSearch 3.0 はデフォルトで auto モードのセグメント並列検索を使用し、エンジンがクエリごとに逐次実行と並列セグメント実行を選択できるようにします。高価な集約 (例えば、terms や date_histogram) は並列で実行され、軽量なクエリはオーバーヘッドを避けるために単一スレッドのままです。8 vCPU クラスターでは、これにより日付ヒストグラムで約 35% 低いレイテンシ、terms aggregation で 15% 以上、Big5 全体で約 8% の集計利得が得られました。テキストクエリは変わらず (例えば、逐次の 8.22 ms と比較して自動モードでは 8.93 ms)、セレクターが意図したとおりに回帰なく機能していることを確認しています。
AI/ML とベクトル検索のパフォーマンス改善
OpenSearch 3.0 は、2.x シリーズで導入されたベクトルエンジンの拡張機能をベースに構築され、正確な k-NN と近似 k-NN (ANN) 検索の両方のパフォーマンス、メモリ効率、および設定可能性を継続的に改善しています。これらの機能は、セマンティック検索と生成 AI を実行するワークロードにとって重要です。
ベクトルインデックス構築のための GPU アクセラレーション
OpenSearch でのベクトルインデックス作成のための GPU アクセラレーションの導入は、大規模な AI ワークロードのサポートにおける大きな進歩を表しています。ベンチマークによると、GPU アクセラレーションは CPU ベースのソリューションと比較してインデックス作成速度を 9.3 倍向上、コストを 3.75 倍削減しました。これにより、数十億規模のインデックス構築に必要な時間が数日からわずか数時間に劇的に短縮されます。GPU を搭載したインデックス構築サービスをメインの OpenSearch クラスターから分離する分離設計により、コンポーネントを独立して進化させる柔軟性が提供され、クラウドとオンプレミス環境全体でのシームレスな採用が可能になります。NVIDIA の cuVS ライブラリからの CAGRA アルゴリズムを使用し、GPU-CPU インデックスの相互運用性をサポートすることで、OpenSearch は本番環境の信頼性のための組み込みのフォールトトレランスとフォールバックメカニズムを備えた堅牢でスケーラブルなベクトル検索ソリューションを提供します。GPU がベクトル検索アプリケーションの最適化にどのように役立つかについての詳細は、このブログ記事と RFC を参照してください。
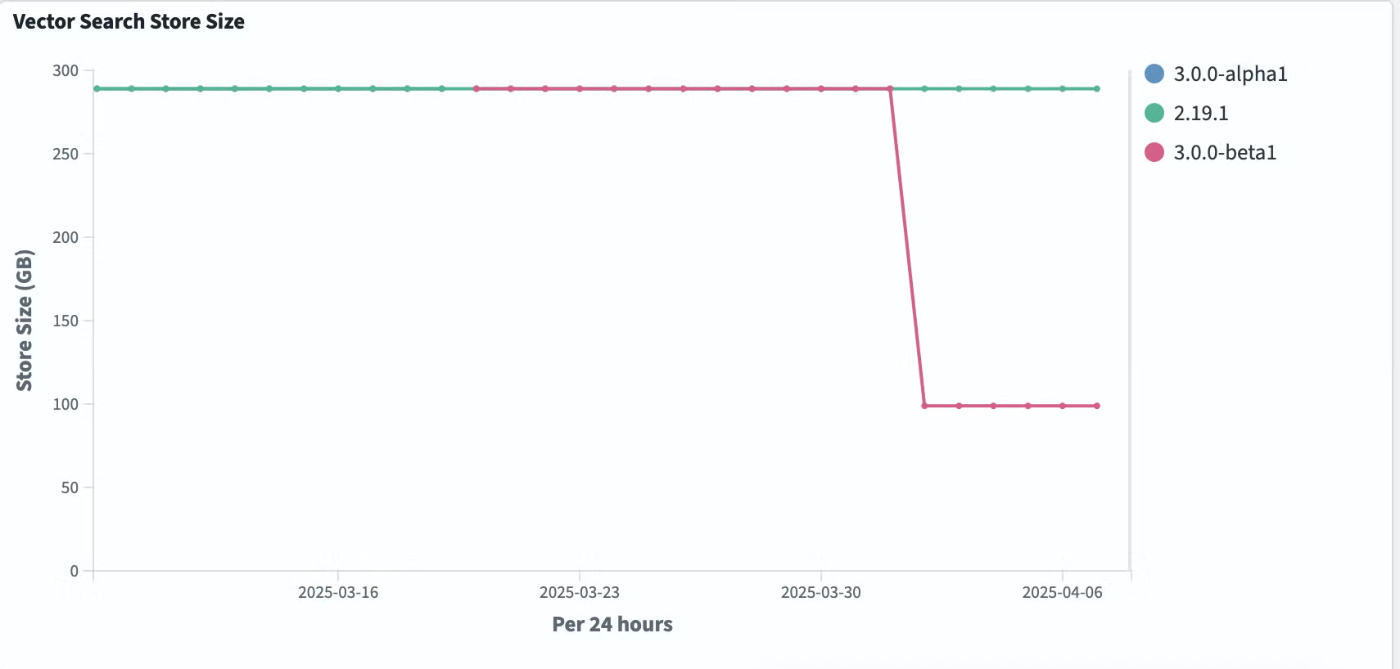
派生ソース (1/3 にストレージ使用量を削減)
OpenSearch 3.0 では、すべてのベクトルインデックスに対してベクトルの派生ソースがデフォルトで有効になっています。_source フィールドの冗長なストレージを削除することで、ベクトルの派生ソースを使用すると、テストされたすべてのエンジン (Faiss、Lucene、NMSLIB) でストレージが 1/3 に削減されます。以下のグラフは実際の削減量を示すものです。
このストレージ最適化はパフォーマンスにも大きな影響を与えました。以下のグラフに示すように、Lucene エンジンの p90 コールドスタートクエリレイテンシが 30 倍向上しています。

この機能はマージ時間の削減にも大きな改善をもたらしました。以下のグラフに示すように、すべてのエンジンで最大 40%のマージ時間が削減されています。

ストレージ効率とクエリパフォーマンスの両方におけるこれらの大幅な向上は、OpenSearch を高スケールのベクトル検索エンジンとして運用する際にベクトルの派生ソースを使用する価値を示しています。この機能の透明性は、再インデックスやフィールドベースの更新などの重要な機能を保持し、ベクトル検索ワークロードを最適化しようとする幅広いユーザーが利用できるようにします。詳細については、RFC を参照してください。
ベンチマークテストについては、ナイトリーベンチマークを参照してください。ベンチマークは 10M/768D データセットに対して実行されています。
最大 2.5 倍のベクトル検索パフォーマンス向上
セグメントの並列検索は現在、すべてのベクトル検索ユースケースでデフォルトで有効になっています。同時セグメント検索は、検索クエリを複数のスレッドに並列化することで、リコールに影響を与えることなくベクトルクエリのパフォーマンスを最大 2.5 倍向上させます。さらに、マージポリシーのフロアセグメントサイズ設定の変更により、よりバランスの取れたセグメントが作成され、テールレイテンシが最大 20% 改善されます。このパフォーマンス向上は、インメモリとディスク最適化インデックスの両方に適用されます。
サービス時間の比較
以下の表は、さまざまなセグメント並列検索構成での異なる k-NN エンジンの 90 パーセンタイル (p90) サービス時間をミリ秒単位で比較しています。
| k-NN エンジン | 同時セグメント検索無効 | 同時セグメント検索有効 (Lucene デフォルトスライス数) | % 改善 | 同時セグメント検索 max_slice_count = 2 | % 改善 | 同時セグメント検索 max_slice_count = 4 | % 改善 | 同時セグメント検索 max_slice_count = 8 | % 改善 |
|---|---|---|---|---|---|---|---|---|---|
| Lucene | 37 | 15 | 59.5 | 16 | 56.8 | 15.9 | 57 | 16 | 56.8 |
| NMSLIB | 35 | 14 | 60 | 23 | 34.3 | 15 | 57.1 | 12 | 65.7 |
| Faiss | 37 | 14 | 62.2 | 22 | 40.5 | 15 | 59.5 | 16 | 56.8 |
埋め込みプロセッサの最適化
OpenSearch 3.0 では、埋め込み取り込みパフォーマンスを向上させるために text_embedding プロセッサに skip_existing サポートを追加しました。以前は、プロセッサは新しい埋め込みを追加するか既存の埋め込みを更新するかに関わらず、ML 推論呼び出しを行っていました。この機能により、ユーザーはターゲットの埋め込みフィールドが変更されていない場合に推論呼び出しをスキップするようにプロセッサを設定するオプションが追加されました。この機能は密な埋め込みとスパース埋め込みの両方に適用されます。推論呼び出しをスキップすることで、この最適化によりテキスト埋め込みの取り込みレイテンシを最大 70%、テキスト/画像埋め込みで 40%、スパーステキスト埋め込みで 80% 削減できます。
ニューラルスパース検索のプルーニング
ニューラルスパース検索は、ネイティブの Lucene 転置インデックスに構築されたセマンティック検索技術です。ドキュメントとクエリをスパースベクトルにエンコードし、各エントリはトークンとそれに対応するセマンティックの重みを表します。エンコードプロセス中にセマンティックの重みでトークンが拡張されるため、スパースベクトル内のトークン数は元のテキストよりも多くなることがよくあります。これらのベクトルは長いテール分布にも従います: 多くのトークンはセマンティックの重要性が低いにもかかわらず、依然として大量のストレージを消費します。その結果、スパースモデルによって生成されるインデックスサイズは、BM25 によって生成されるものよりも 4 から 7 倍大きくなる可能性があります。OpenSearch 2.19 で導入されたプルーニングは、取り込みと検索中に相対的に重みの低いトークンを削除することでこの問題に対処します。使用される戦略に応じて、プルーニングは検索の関連性に約 1% の影響しか与えずにインデックスサイズを最大 60% 削減できます。
インデックス作成と取り込みのパフォーマンス
OpenSearch 3.0 は Lucene 10 からの更新を統合しながら、2.x シリーズのインデックス作成スループットを維持しています。r5.xlarge ノードで 7000 万ドキュメント (60 GB) をインデックス作成するベンチマークテストでは、バージョン 3.0 は同一のバルク取り込み条件下で OpenSearch 2.19 のパフォーマンスに匹敵する、約 1 秒あたり 20,000 ドキュメントのスループットを維持しました。セグメントマージを正規化した後のインジェスト時間とセグメント数も同等であり、Lucene 10 によって導入されたフォーマット変更が一般的なワークロードに対して最小限のオーバーヘッドしか追加しないことを示しています。
OpenSearch 3.0 は、Lucene 10 で導入されたスパース doc values のサポートを有効にします。インデックスがソートされている場合 (例えば、タイムスタンプによる)、Lucene は範囲クエリと集約を加速するスキップリストを構築します。これはインデックス作成に若干のオーバーヘッドをもたらしますが、クエリ効率を大幅に向上させます。時系列ベンチマークでは、スパース doc values を有効にしてもインジェスト速度に影響を与えず、日付ベースのクエリパフォーマンスが向上しました。
セグメントマージの動作は OpenSearch 3.0 で安定しており、最新のハードウェアをより活用するためにいくつかのデフォルト設定が更新されています。強制マージは現在、1 ではなくマシンコアの 1/4 を使用し、デフォルトのフロアセグメントサイズは 4 MB から 16 MB に増加し、maxMergeAtOnce は 10 から 30 に変更され、Lucene 10 のデフォルトに合わせています。さらに、maxMergeAtOnce はカスタムチューニング用にクラスターレベルの設定として変更できるようになりました。3.0 でのインジェスト後に 1 つ余分なセグメントが観察されましたが (2.19 の 19 に対して 20)、強制マージは CPU 使用率やガベージコレクションのオーバーヘッドを増加させることなく結果を均等化しました。マージポリシーの他のすべての側面は変更されていません。
ベクトルインデックス作成も OpenSearch 3.0 で大幅に改善されました。Lucene の KnnVectorsFormat を使用することで、3.0 は増分 HNSW グラフマージをサポートし、メモリ使用量を削減し、完全なグラフ再構築の必要性を排除します。この拡張により、メモリフットプリントが低減し、ベクトルインデックス構築時間がバージョン 1.3 と比較して約 30% 短縮されました。バイト圧縮などの以前の最適化と組み合わせると、OpenSearch 3.0 は以前のリリースよりも最大 85% 少ないメモリを使用して大規模なベクトルデータセットをインデックス化できます。
まとめると、OpenSearch 3.0 は 2.x シリーズのインデックス作成パフォーマンスを維持しながら、改善されたメモリ効率を提供し、インジェスト速度に影響を与えずにクエリパフォーマンスを向上させる Lucene 10 の拡張機能を組み込んでいます。
OpenSearch 3.1 以降のロードマップ
パフォーマンスは引き続き OpenSearch プロジェクトの中心的な焦点です。公開ロードマップと今後の 3.1 リリースに基づいて、いくつかの取り組みが進行中です:
-
Lucene 10 の活用: 今後を見据えて、OpenSearch 3.x リリースはこの基盤の上に構築し続けます。今後の取り組みには、強制マージされたインデックスに対する Lucene の同時セグメント実行の使用や、新しい
IndexInput.prefetch()API を使用した非同期ディスク I/O の統合が含まれます。また、より効率的な範囲クエリと集約を可能にするために、スパース doc values とブロックレベルのメタデータのサポートを評価することも計画しています。これらの拡張機能は、継続的なパフォーマンス改善 (例えば、term クエリ、search_after、およびソートパフォーマンスにおける) と組み合わせて、OpenSearch が多様なワークロードでさらに低いレイテンシとより良いスループットを提供するのに役立ちます。 -
コストベースのクエリ計画: OpenSearch は、統計とコストモデリングを使用して実行戦略をより効率的に選択するクエリプランナーを開発しています。これには、ビットセットと term フィルターの間の選択、句の順序の決定、および同時セグメント検索を有効にするタイミングの決定が含まれます。この取り組みは、特に複雑なクエリに対して、レイテンシとリソース使用量の改善を目指しています。
-
ストリーミングクエリ実行: 現在、前のステージが完全に完了する前にクエリステージを開始できるストリーミングモデルの導入に取り組んでいます。このアプローチでは、結果が段階的に流れることを可能にすることで、レイテンシとメモリ使用量を削減できるはずです。初期サポートは 3.x シリーズの特定の集約とクエリタイプ向けに計画されています。
-
gRPC/protobuf ベースの通信: シャードあたりのレイテンシが減少するにつれて、調整オーバーヘッドがより重要になります。シリアル化コストを削減し、コーディネーターノードと複数のデータノードとの通信をより効率的にし、ノード間のレスポンス処理でより多くの並列処理をサポートするための最適化が計画されています。また、シリアル化と逆シリアル化にプロトコルバッファ (protobuf) を使用する gRPC ベースの API のサポートも検討しています。
-
Join のサポートと高度なクエリ: ネイティブの Join サポートは 2025 年に計画されており、ランタイム効率に重点を置いています。インデックスレベルのブルームフィルターや事前結合キャッシングなどの技術を使用して、クエリコストを削減し、本番グレードの使用をサポートします。
-
ネイティブ SIMD とベクトル化: OpenSearch は、集約や結果のソートなどの操作に対して、Lucene を超えたネイティブコードと SIMD 命令の使用を検討しています。これらの取り組みは、CPU バウンドのワークロードで JVM オーバーヘッドを削減し、スループットを向上させることを目的としています。
-
量子化ベクトルインデックスのための GPU アクセラレーション: OpenSearch は量子化ベクトルインデックスのための GPU アクセラレーション機能を拡張しています。3.0 リリースでフル精度 (FP32) インデックスの GPU サポートを導入しましたが、今後の 3.1 リリースでは GPU アクセラレーションを FP16、バイト、バイナリインデックスを含むより広範な量子化技術に拡張します。バージョン 3.1 以降を見据えて、OpenSearch は検索ワークロードのための GPU 機能を拡張する計画です。
-
ディスク最適化ベクトル検索—フェーズ 2: OpenSearch 3.1 では、ディスク最適化ベクトル検索機能に大幅な拡張が導入され、最適化の旅のフェーズ 2 を示します。バイナリ量子化の成功を基に、システムは以下の技術を組み込みます: ランダム回転と非対称距離計算 (ADC)。革新的な RaBitQ 論文にインスパイアされたこれらの改善は、ディスク最適化の利点を維持しながら、リコールパフォーマンスを大幅に向上させます。
-
Faiss ベクトルエンジンを使用したグラフの部分的な読み込み: バージョン 3.1 から、部分的なグラフ読み込みの導入は、ベクトル検索の動作方法における大きなブレークスルーとなります。グラフ全体をメモリにロードする従来のアプローチとは異なり、この新しいアプローチでは、検索トラバーサルに必要なグラフの部分のみを選択的にロードします。このスマートなローディングメカニズムは 2 つの重要な利点をもたらします。メモリ消費を劇的に削減し、単一ノード環境でも数十億規模のワークロードを効率的に実行できるようにします。
-
ベクトルのための BFloat16 (効率的な FP16) のサポート: Faiss スカラー量子化器 (SQfp16) を使用した FP16 サポートは、FP32 ベクトルと同様のパフォーマンスとリコールレベルを維持しながらメモリ使用量を 50% 削減します。ただし、入力ベクトルは [-65504, 65504] の範囲内である必要があるという制限があります。BFloat16 は、精度をトレードオフする代替手段を提供します (最大 2 または 3 の小数値、または 7 マンティッサビットをサポート) が、次元あたり 16 ビットを使用し (50% のメモリ削減を提供)、FP32 の全範囲を提供します。
-
ベクトル検索におけるマルチテナンシー/高カーディナリティフィルタリング: OpenSearch は、拡張されたフィルタリング機能により、マルチテナントベクトル検索を次のレベルに引き上げています。この改善の中核は、テナント境界に基づいて HNSW グラフをパーティショニングする革新的なアプローチです。この戦略的な拡張は 2 つの重要な利点をもたらします。優れた検索精度とテナント間の堅牢なデータ分離です。テナント境界に従ってベクトル検索データ構造を整理することで、フィルタークエリはそれぞれのテナントパーティション内で排他的に動作し、テナント間のノイズを排除し、精度を向上させます。
-
スマートクエリルーティングによるベクトル検索スループットの向上: OpenSearch ノード全体でセマンティックベースのデータ編成を実装し、類似の埋め込みをグループ化することで、最近傍の関連ノードを対象とした検索が可能になります。このアプローチにより、クエリごとにシャードのサブセットを検索でき、計算要件を削減しながらスループットを最大 3 倍に増加させる可能性があります。
OpenSearch 3.1 は、OpenSearch リリーススケジュールに基づいて 3.0 の上に構築される最初のマイナーリリースとなります。Lucene の更新、同時検索の改良、および集約、ベクトル、インデックス作成フレームワークの改善が含まれます。いつものように、リリースノートとブログ記事でパフォーマンスの更新を共有します。
Appendix: ベンチマーク方法論
すべてのパフォーマンス比較は、OpenSearch Benchmark ツールと Big5 ワークロードに基づく再現可能なプロセスを使用して実施されました。ベンチマークは match クエリ、terms 集約、範囲フィルター、日付ヒストグラム、およびソートされたクエリをカバーしています。データセット (約 100 GB、1 億 1600 万ドキュメント) は時系列と EC のユースケースを反映しています。
環境: テストは c5.2xlarge Amazon Elastic Compute Cloud (Amazon EC2) インスタンス (8 vCPU、16 GB RAM、8 GB JVM ヒープ) を使用した単一ノードの OpenSearch クラスターで実行されました。特に記載がない限り、デフォルト設定が使用されました。インデックスには 1 つのプライマリシャードがあり、マルチシャードの変動を避けるためにレプリカはありませんでした。ドキュメントは時系列ワークロードをシミュレートするために時系列順に取り込まれました。
インデックス設定: Lucene の LogByteSizeMergePolicy を使用し、明示的なインデックスソートは有効にしませんでした。一部のテストでは、公平な比較を確保するために (例えば、2.19 と 3.0 の両方で 10 セグメント) セグメント数を正規化するために強制マージが適用されました。
実行: 各操作は複数回繰り返されました。ウォームアップ実行を破棄し、次の 3 回の実行の平均を取りました。レイテンシメトリクスには p50、p90、p99 が含まれ、スループットも記録されました。OpenSearch Benchmark はスループット制限モードで実行され、各操作タイプの正確なクエリレイテンシを記録しました。
ソフトウェア: 比較には OpenSearch 2.19.1 (Java 17) と 3.0.0-beta (Java 21、Lucene 10.1.0) を使用しました。デフォルトのプラグインのみが有効化されました。ベクトルベンチマークは k-NN プラグインを使用した Faiss + HNSW を使用し、リコールは総当たり結果と比較して測定されました。
メトリクス: Big5 中央値レイテンシは 5 つのコアクエリタイプの単純平均です。集計レイテンシは全体比較に使用される幾何平均です。速度向上係数は、特に記載がない限り OpenSearch 1.3 に対する相対値として報告されています。
| バケット | クエリ順序 | OS 1.3.18 | OS 2.7 | OS 2.11.1 | OS 2.12.0 | OS 2.13.0 | OS 2.14 | OS 2.15 | OS 2.16 | OS 2.17 | OS 2.18 | OS 2.19 | OS 3.0 |
| ----------------- | ---------------------------------------------------- | --------- | ------- | --------- | --------- | --------- | -------- | ------- | -------- | -------- | ------- | ------- | ------ | ---- |
| テキストクエリ | query-string-on-message | 1 | 332.75 | 280 | 276 | 78.25 | 80 | 77.75 | 77.25 | 77.75 | 78 | 85 | 4 | 4 |
| テキストクエリ | query-string-on-message-filtered | 2 | 67.25 | 47 | 30.25 | 46.5 | 47.5 | 46 | 46.75 | 29.5 | 30 | 27 | 11 | 11 |
| テキストクエリ | query-string-on-message-filtered-sorted-num | 3 | 125.25 | 102 | 85.5 | 41 | 41.25 | 41 | 40.75 | 24 | 24.5 | 27 | 26 | 27 |
| テキストクエリ | term | 4 | 4 | 3.75 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| ソート | asc_sort_timestamp | 5 | 9.75 | 15.75 | 7.5 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 | 7 |
| ソート | asc_sort_timestamp_can_match_shortcut | 6 | 13.75 | 7 | 7 | 6.75 | 6 | 6.25 | 6.5 | 6 | 6.25 | 7 | 7 | 7 |
| ソート | asc_sort_timestamp_no_can_match_shortcut | 7 | 13.5 | 7 | 7 | 6.5 | 6 | 6 | 6.5 | 6 | 6.25 | 7 | 7 | 7 |
| ソート | asc_sort_with_after_timestamp | 8 | 35 | 33.75 | 238 | 212 | 197.5 | 213.5 | 204.25 | 160.5 | 185.25 | 216 | 150 | 168 |
| ソート | desc_sort_timestamp | 9 | 12.25 | 39.25 | 6 | 7 | 5.75 | 5.75 | 5.75 | 6 | 6 | 8 | 7 | 7 |
| ソート | desc_sort_timestamp_can_match_shortcut | 10 | 7 | 120.5 | 5 | 5.5 | 5 | 4.75 | 5 | 5 | 5 | 6 | 6 | 5 |
| ソート | desc_sort_timestamp_no_can_match_shortcut | 11 | 6.75 | 117 | 5 | 5 | 4.75 | 4.5 | 4.75 | 5 | 5 | 6 | 6 | 5 |
| ソート | desc_sort_with_after_timestamp | 12 | 487 | 33.75 | 325.75 | 358 | 361.5 | 385.25 | 378.25 | 320.25 | 329.5 | 262 | 246 | 93 |
| ソート | sort_keyword_can_match_shortcut | 13 | 291 | 3 | 3 | 3.25 | 3.5 | 3 | 3 | 3 | 3 | 4 | 4 | 4 |
| ソート | sort_keyword_no_can_match_shortcut | 14 | 290.75 | 3.25 | 3 | 3.5 | 3.25 | 3 | 3.75 | 3 | 3.25 | 4 | 4 | 4 |
| ソート | sort_numeric_asc | 15 | 7.5 | 4.5 | 4.5 | 4 | 4 | 4 | 4 | 4 | 4 | 17 | 4 | 3 |
| ソート | sort_numeric_asc_with_match | 16 | 2 | 1.75 | 2 | 2 | 2 | 2 | 1.75 | 2 | 2 | 2 | 2 | 2 |
| ソート | sort_numeric_desc | 17 | 8 | 6 | 6 | 5.5 | 4.75 | 5 | 4.75 | 4.25 | 4.5 | 16 | 5 | 4 |
| ソート | sort_numeric_desc_with_match | 18 | 2 | 2 | 2 | 2 | 2 | 2 | 1.75 | 2 | 2 | 2 | 2 | 2 |
| Terms aggregation | cardinality-agg-high | 19 | 3075.75 | 2432.25 | 2506.25 | 2246 | 2284.5 | 2202.25 | 2323.75 | 2337.25 | 2408.75 | 2324 | 2235 | 628 |
| Terms aggregation | cardinality-agg-low | 20 | 2925.5 | 2295.5 | 2383 | 2126 | 2245.25 | 2159 | 3 | 3 | 3 | 3 | 3 | 3 |
| Terms aggregation | composite_terms-keyword | 21 | 466.75 | 378.5 | 407.75 | 394.5 | 353.5 | 366 | 350 | 346.5 | 350.25 | 216 | 218 | 202 |
| Terms aggregation | composite-terms | 22 | 290 | 242 | 263 | 252 | 233 | 228.75 | 229 | 223.75 | 226 | 333 | 362 | 328 |
| Terms aggregation | keyword-terms | 23 | 4695.25 | 3478.75 | 3557.5 | 3220 | 29.5 | 26 | 25.75 | 26.25 | 26.25 | 27 | 26 | 19 |
| Terms aggregation | keyword-terms-low-cardinality | 24 | 4699.5 | 3383 | 3477.25 | 3249.75 | 25 | 22 | 21.75 | 21.75 | 21.75 | 22 | 22 | 13 |
| Terms aggregation | multi_terms-keyword | 25 | 0* | 0* | 854.75 | 817.25 | 796.5 | 748 | 768.5 | 746.75 | 770 | 736 | 734 | 657 |
| Range query | keyword-in-range | 26 | 101.5 | 100 | 18 | 22 | 23.25 | 26 | 27.25 | 18 | 17.75 | 64 | 68 | 14 |
| Range query | range | 27 | 85 | 77 | 14.5 | 18.25 | 20.25 | 22.75 | 24.25 | 13.75 | 14.25 | 11 | 14 | 4 |
| Range query | range_field_conjunction_big_range_big_term_query | 28 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Range query | range_field_conjunction_small_range_big_term_query | 29 | 2 | 1.75 | 2 | 2 | 2 | 2 | 1.5 | 2 | 2 | 2 | 2 | 2 |
| Range query | range_field_conjunction_small_range_small_term_query | 30 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Range query | range_field_disjunction_big_range_small_term_query | 31 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2.25 | 2 | 2 | 2 |
| Range query | range-agg-1 | 32 | 4641.25 | 3810.75 | 3745.75 | 3578.75 | 3477.5 | 3328.75 | 3318.75 | 2 | 2.25 | 2 | 2 | 2 |
| Range query | range-agg-2 | 33 | 4568 | 3717.25 | 3669.75 | 3492.75 | 3403.5 | 3243.5 | 3235 | 2 | 2.25 | 2 | 2 | 2 |
| range-numeric | 34 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| Date histogram | composite-date_histogram-daily | 35 | 4828.75 | 4055.5 | 4051.25 | 9 | 3 | 2.5 | 3 | 2.75 | 2.75 | 3 | 3 | 3 |
| Date histogram | date_histogram_hourly_agg | 36 | 4790.25 | 4361 | 4363.25 | 12.5 | 12.75 | 6.25 | 6 | 6.25 | 6.5 | 7 | 6 | 4 |
| Date histogram | date_histogram_minute_agg | 37 | 1404.5 | 1340.25 | 1113.75 | 1001.25 | 923 | 36 | 32.75 | 35.25 | 39.75 | 35 | 36 | 37 |
| Date histogram | range-auto-date-histo | 38 | 10373 | 8686.75 | 9940.25 | 8696.75 | 8199.75 | 8214.75 | 8278.75 | 8306 | 8293.75 | 8095 | 7899 | 1871 |
| Date histogram | range-auto-date-histo-with-metrics | 39 | 22988.5 | 20438 | 20108.25 | 20392.75 | 20117.25 | 19656.5 | 19959.25 | 20364.75 | 20147.5 | 19686 | 20211 | 5406 |
結果は異なる環境で変わる可能性がありますが、ノイズとハードウェアの変動を制御しました。相対的なパフォーマンスの傾向は、ほとんどの実世界のシナリオで維持されると予想されます。OpenSearch Benchmark ワークロードはオープンソースであり、コミュニティメンバーによる再現とフィードバックを歓迎します。

OpenSearch Project(OSS) の Publicationです。 OpenSearch Tokyo User Group : meetup.com/opensearch-project-tokyo/
Discussion