[翻訳] より少ないリソースでより多くを実現: derived vector source で最大 3 倍のストレージ節約
本投稿は OpenSearch Project Blog "Do more with less: Save up to 3x on storage with derived vector source" の日本語訳です。
最新のアプリケーション(セマンティック検索からレコメンデーションシステムまで)に取り組んでいる場合、ベクトル検索を実装している可能性が高いでしょう。ベクトル類似性検索の精度と速度に注目しがちですが、これらのベクトルがシステム内でどのように保存され管理されているかという重要な側面を見落としているかもしれません。効率的な実装を確保するには、OpenSearch がベクトルデータをどのように処理しているかを理解する必要があります。この記事では、OpenSearch のベクトルストレージメカニズムを詳しく説明し、ベクトル用の derived source(派生ソース)という新機能を紹介します。この機能によりストレージコストを大幅に削減し、パフォーマンスを向上させることができます。
OpenSearch におけるベクトルデータの保存方法
JSON ドキュメントを OpenSearch クラスターにアップロードすると、システムはインデックス作成プロセスを開始します。これは生データを最適化された構造に変換し、検索を高速かつ効率的にする重要なステップです。例えば、ドキュメントにベクトルデータが含まれている場合、OpenSearch は Hierarchical Navigable Small World (HNSW) グラフを構築します。これらの特殊なデータ構造は、近似最近傍 (ANN) 検索を強化し、大規模なデータセット全体で迅速かつ正確な類似性検索を可能にします。
インデックス作成プロセスでは、クラスターに保存されるデータのサイズが、元々取り込まれたデータのサイズと比較して増加することがよくあります。これは、OpenSearch が異なるタイプの検索や分析操作のためにデータを準備し、それぞれが独自の最適化された構造を必要とするためです。例えば、全文検索は転置インデックスに依存し、テキストフィールドの高速ストリーミングや集計にはカラムナーストアが使用されることがあります。これらの多様なニーズをサポートするために、システムは同じデータの複数の表現を保存することがあり、その結果ストレージの使用量が増加します。

ベクトルデータに関しては、OpenSearch は通常、それを 2 つまたは 3 つの異なる場所に保存し、それぞれが特定の目的を果たします:
- HNSW グラフ – これは ANN 検索に使用される中核的な構造で、高速かつ効率的なベクトル類似性検索を可能にします。一部のエンジンはこのグラフ内に実際のベクトルデータを保存しますが、他のエンジンはそれを別に保持します。
- ベクトル値 – カラムナー形式で保存されるこれらの生のベクトルは、検索の最終ランキングフェーズや正確な計算に使用されることがよくあります。
-
_sourceフィールド – このフィールドには、元の取り込まれた JSON ドキュメントが含まれ、データの完全なコンテキストとメタデータを保持し、取得や再インデックス作成に使用されます。
ベクトルデータがストレージに与える影響をよりよく理解するために、10K の 128 次元ベクトルのテストデータセットを使用して実験を行いました。OpenSearch における異なるストレージコンポーネントの測定サイズは以下の通りです。

驚くべきことに、_source フィールドはインデックスストレージの半分以上を占めていました。_source の保存はインデックスサイズを増加させるだけでなく、インデックス作成、マージ、リカバリ、さらには検索中のパフォーマンスにも悪影響を与える可能性があります。
_source フィールドの目的をより詳しく見てみましょう。
_source フィールドとベクトル検索
OpenSearch の _source フィールドには 2 つの主要な目的があります:
- 元のドキュメントコンテンツを保存し、検索結果でユーザー向けフィールドを返すために使用されます。例えば、詩集をインデックス化する場合、詩のテキスト、タイトル、著者などのフィールドは、特に設定されていない限り、通常
_sourceフィールドから取得されます。 - 再インデックス作成とリカバリ操作を可能にします。
_sourceは、更新、新しい設定でのインデックスの再構築 (Reindex API を使用)、またはトランスログ再生などのリカバリプロセスに必要な元のデータを保持します。
Lucene では、_source は stored field として実装されています。これは検索ではなくデータの取得のために設計された構造です。
ベクトル検索では、通常ベクトル自体を取得する必要はありません:浮動小数点数のリストは一般的なユーザーにとってあまり意味を持ちません。例えば、ロマンチックな詩を検索する場合、その詩がどのように意味的に表現されているかは気にせず、正しいテキストを素早く取得したいだけです。
ベクトルフィールドは非常に大きく、それらをレスポンスに含めるとレスポンスにノイズが加わり、検索リクエストが遅くなります。本番環境では、パフォーマンスを向上させるために、返される _source からベクトルフィールドを除外することを通常推奨しています:
POST /my_index/_search
{
"_source": {
"excludes": ["vector-field"]
},
"query": {
"knn": {
"vector-field": {
"vector": [],
"k": 10
}
}
}
}
まだこれを行っていない場合は、試してみてください。顕著なパフォーマンスの向上が見られるでしょう。
さらに大きなパフォーマンス向上を得るには、_source ストレージからベクトルを完全に削除することができます。これにより全体的なインデックスサイズが削減され、その結果シャードサイズが小さくなります。小さいシャードはノード間でより迅速に再配置でき、ノードの再起動やリバランシングなどのイベント中にクラスターがより迅速かつ確実に回復するのに役立ちます。さらに、ディスクから読み込むデータが少なくなるとメモリ使用量が減少し、ページキャッシュの効率が向上し、検索レイテンシーが低下する可能性があります。
ただし、_source ストレージを完全に無効にすると、ドキュメントの更新、データの再インデックス作成、障害からの回復などの重要な機能が失われます。多くのユースケースでは、このトレードオフは実用的ではありません。
両方の良いところを取る: Derived source
すでにベクトル値ファイルにベクトルを保存している場合、次のように疑問に思うかもしれません:OpenSearch は必要なときに _source にも保存するのではなく、ファイルからベクトルを取得できないのでしょうか?OpenSearch 3.0 以降、その答えは「はい」です。
ベクトルインデックス用に設計された derived source を使用すると、OpenSearch はユーザー側での変更を必要とせずに、必要に応じてベクトル値ファイルからベクトルを透過的に取得できます。
仕組みは次の通りです。ドキュメントのインデックスを作成する際、OpenSearch はディスクに書き込む前に _source 内の大きなベクトルを 1 バイトのプレースホルダーに置き換えます。その後、_source を読み取る際にベクトルが必要な場合、OpenSearch はベクトル値ファイルからそれを読み取り、ドキュメントに戻します。
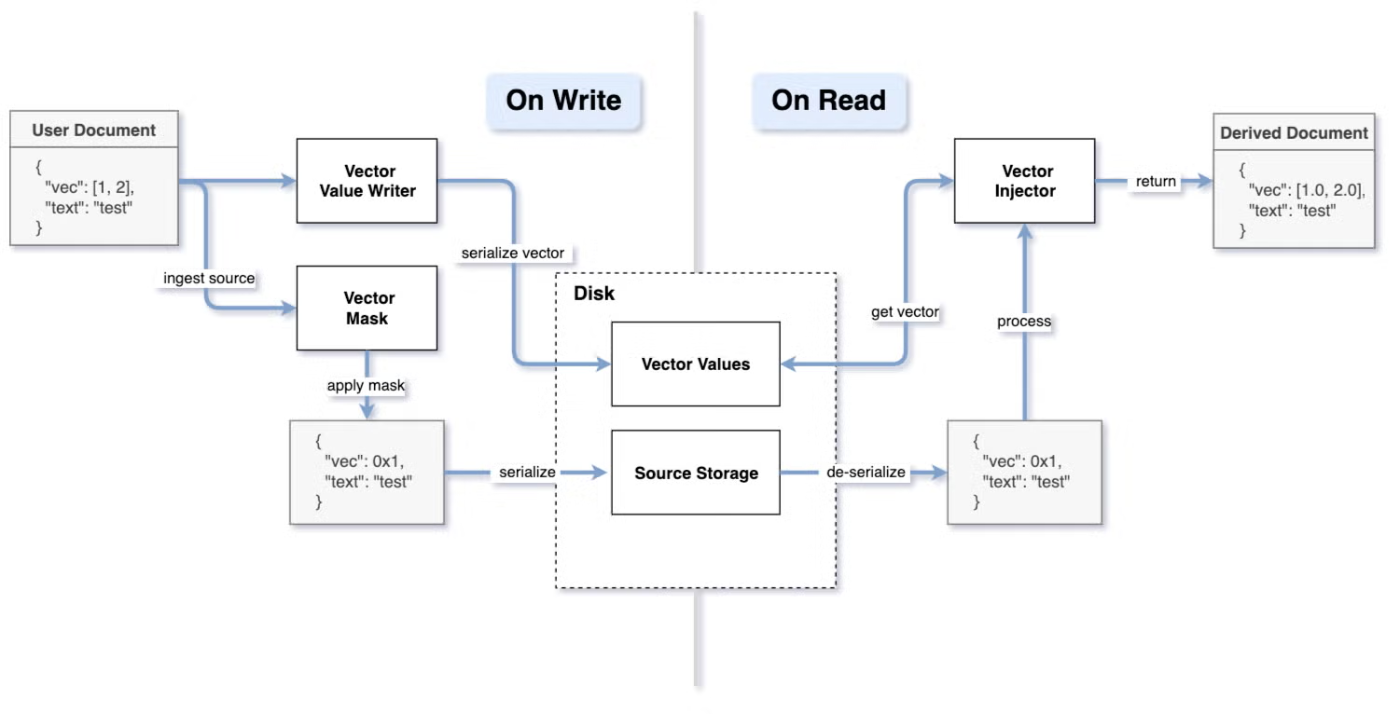
あなたの視点からは、derived source は完全に透過的です。インデックス設定を使用して有効または無効にすることができ、OpenSearch は舞台裏で残りの処理を行います。derived source を有効にするには、次のリクエストを使用し、index.knn を true に設定します:
PUT /my_index
{
"settings" : {
"index.knn": true,
"index.knn.derived_source.enabled" : true # デフォルトで true
},
"mappings": {
<Index fields>
}
}
derived source は OpenSearch 3.0.0 以降で作成されたベクトルインデックスではデフォルトで有効になっています。
パフォーマンスベンチマーク
この変更により、夜間ベンチマークでいくつかの顕著なパフォーマンス向上が見られました。最も重要なのは、ストレージ使用量が 3 倍減少したことです。

フォースマージ時間も約 10% 改善されました。この減少は、新しいセグメントを作成する際にコピーして書き直す必要があるデータ量が減少したことが原因と考えられます。

おそらく最も驚くべきことは、Lucene エンジンを使用した場合の検索レイテンシーが 90% 減少したことです。考えられる説明の一つはコールドスタート効果です:マージ中に不要なベクトルデータがページキャッシュにロードされ、後に排出され、検索中に実際に必要になったときに再ロードされます。

これらの改善はすべて、ディスクに保存され読み込まれるデータ量を減らすことから生じています。シャードを小さくすることで、マージや検索などの一般的な操作中の I/O オーバーヘッドが減少します。したがって、小さいシャードサイズで作業すると、驚くべきパフォーマンスの向上が得られることがよくあります。
今後の展開
derived source をベクトルフィールドだけに限定しないことを喜んでお伝えします。今後のバージョンでは、すべてのフィールドタイプに対する derived source のサポートを拡張し、OpenSearch での作業においてさらに柔軟性を提供します。
この機能の進捗状況に興味がある、または参加したい場合は、この GitHub issue で機能の開発をフォローし、会話に参加してください。
Discussion