速い! 軽い! 楽しい! Go言語DBクライアントのBunをPostgreSQLで使ってみよう!
Intro
Go言語でPostgreSQLを使いたい人はdatabase/sqlパッケージのドライバーとして有名なlib/pqやjackc/pgx、jackc/pgxを内部で使用しているORMのgo-gorm/gorm、最近だとコマンドを叩きスキーマを生成してやっていく次世代ORMのent/entやprisma/prisma-client-go、その他にもxorm/xormやvolatiletech/sqlboilerといったORMもあったりしてどれを選べばよいか分からなくなってしまいます。
そもそもDBは初心者に厳しくないですか?
ちなみに私はpgx経由で知ったPostgreSQL専用ORMのgo-pg/pgを長らく使用していましたが、最近メンテナンスモードに移行したことを知りました。
よく見てみると同じ作者が作った同様の機能を提供しているBunに移行するからメンテナンスモードになったようです。
go-pgはメンテナンスモードで、重要な問題のみが対処されています。新しい開発は、同様の機能を提供し、PostgreSQL、MySQL、SQLiteで動作するBun Repoで行われています。
このような複数のDBに対応したORMがまた増えたのか……とガッカリしながら使ってみたところ、いかにもGoらしい設計で前言撤回、これはORMであってORMではない、DB初心者に優しく素晴らしいDBクライアントだったので紹介します。
Bun
はじめに
Bunは、SQLファーストのGo用データベースクライアントです。SQLファーストとは、ほとんどのSQLクエリが自動的にBun式にコンパイルでき、Bun式がSQLクエリのように見えることを意味します。
Bunの目的は、古き良きSQLを使ってクエリを書けるようにすることと、結果を構造体、マップ、スライス、スカラといったGoの一般的な型にスキャンできるようにすることです。
仕組み
Bunはsql.DBをラップしてクエリビルダとフックを提供します。オリジナルのsql.DBはdb.DBとして提供されており、何の制限もなく使用することができます。
Bunはサポートしている各データベースの方言を持っています。Bunは、クエリを作成したり、クエリの結果をスキャンしたりする際に、方言を使って利用可能な機能を発見します。たとえば、PostgreSQLサーバに接続するには、PostgreSQLドライバ(たとえば、pgdriver)とPostgreSQL方言(pgdialect)を使用します。
Bunは、初期データをロードするためのフィクスチャと、データベーススキーマを更新するためのマイグレーションを提供します。また、Bunスターターキットを使って、これらのパッケージを使ったアプリを素早くブートストラップすることもできます。
Bun本体が提供する機能はquery builder(クエリビルダ)とhooks(フック)だけにとどめておき、DBごとにdialects(ダイアレクト、方言)とdriver(ドライバー)を追加し、ユースケースにあわせて fixtures(フィクスチャ)とmigrations(マイグレーション)ツールをオプションで追加してもよいというものです。その他にもログを出力するdebugツールがあったり、Bunを公開しているUptraceはOpenTelemetryを使用したトレーシングソリューションを提供している(おそらくものすごく小さい)企業らしいのでOpenTelemetryと一緒に使うことも出来るようです。
より多くのメリットを書きたいところですが長文書いて疲れました。皆さんも読むの疲れてませんか? それでは早速使ってみましょう!
まずはお使いのパソコンにGoとPostgreSQLとVSCodeと拡張機能をインストールして……といった面倒な手続きも不要です。
Gitpodを使えば一瞬で開発環境を作れます。
GitHubで試したい方は上記リポジトリはPublic DomainなThe UnlicenseなのでCopyしたりCloneしたりDownloadしたりして使ってください。
また今回拡張機能としてSQLToolsを使用しています。このSQLToolsもBunと同じぐらい速い! 軽い! 楽しい! ツールですのでまだ使ったことない人はお試しください。
Version
package main
import (
"context"
"database/sql"
"fmt"
"log"
"os"
"github.com/uptrace/bun"
"github.com/uptrace/bun/dialect/pgdialect"
"github.com/uptrace/bun/driver/pgdriver"
)
func main() {
db := bun.NewDB(
sql.OpenDB(pgdriver.NewConnector(pgdriver.WithDSN(os.Getenv("DATABASE_URL")+"/postgres?sslmode=disable"))),
pgdialect.New(),
)
var v string
if err := db.NewSelect().ColumnExpr("version()").Scan(context.Background(), &v); err != nil {
log.Fatal(err)
}
fmt.Println(v)
}
上記コードがいわゆるHello, World!です。
Bunの公式ドキュメントを少し変えてversion()でPostgreSQLのバージョンを表示するようにしました。
$ go mod vendor
...
$ go clean --modcache
$ go run main.go
PostgreSQL 12.8 (Ubuntu 12.8-0ubuntu0.20.04.1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0, 64-bit
とても簡単ですね!
最初にbun.NewDB()を使用してsqlパッケージ、pgdialectパッケージ、pgdriverパッケージを使用してDBに接続して、その後db.New...()を使用してクエリを叩いていきます。
今回はSELECT version();を記述したいのでNewSelect()を使用しました。
Create Table
NewCreateTable()を使用すればCREATE TABLE ...;を記述することができます。
...
type Post struct {
ID int64 `bun:",pk,autoincrement"`
Content string
CreatedAt time.Time `bun:",nullzero,notnull,default:current_timestamp"`
UpdatedAt time.Time `bun:",nullzero,notnull,default:current_timestamp"`
}
...
作成するためにまずはテーブルの型を定義しないといけないので構造体を書きます。
...
if _, err := db.NewCreateTable().Model((*Post)(nil)).Exec(context.Background()); err != nil {
log.Fatal(err)
}
fmt.Println("create table")
...
Modelに入れた構造体の横にnilがあったり返り値を_に突っ込んだりしていますがよく分かってないのでここらへんは公式ドキュメントを参考にしたやつそのまんまです。
go runしたときに複数の機能を持たせたいのでflagパッケージを使い今まで書いてきた処理を分岐させます。
...
func main() {
flag.Parse()
a := flag.Args()
...
if len(a) == 0 {
log.Fatal("error: flags")
}
switch a[0] {
case "v":
...
case "ct":
...
default:
log.Fatal("error: args")
}
}
$ go run main.go v
PostgreSQL 12.8 (Ubuntu 12.8-0ubuntu0.20.04.1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 9.3.0-17ubuntu1~20.04) 9.3.0, 64-bit
$ go run main.go ct
create table

SQLToolsを確認するとpostsテーブルが作成されていることがわかります。
構造体はPostで作成しましたがgormと同様にRuby on RailsのActiveSupportみたいなjinzhu/inflectionパッケージを使用しているため自動的にsが補完されるスネークケースのテーブルが作成されます。
gormの作者ありがとう。
Drop Table
次はDROP TABLE ...;を記述したいのでNewDropTable()を使用します。ほぼ同じです。
...
case "dt":
if _, err := db.NewDropTable().Model((*Post)(nil)).Exec(context.Background()); err != nil {
log.Fatal(err)
}
fmt.Println("drop table")
...
$ go run main.go dt
drop table
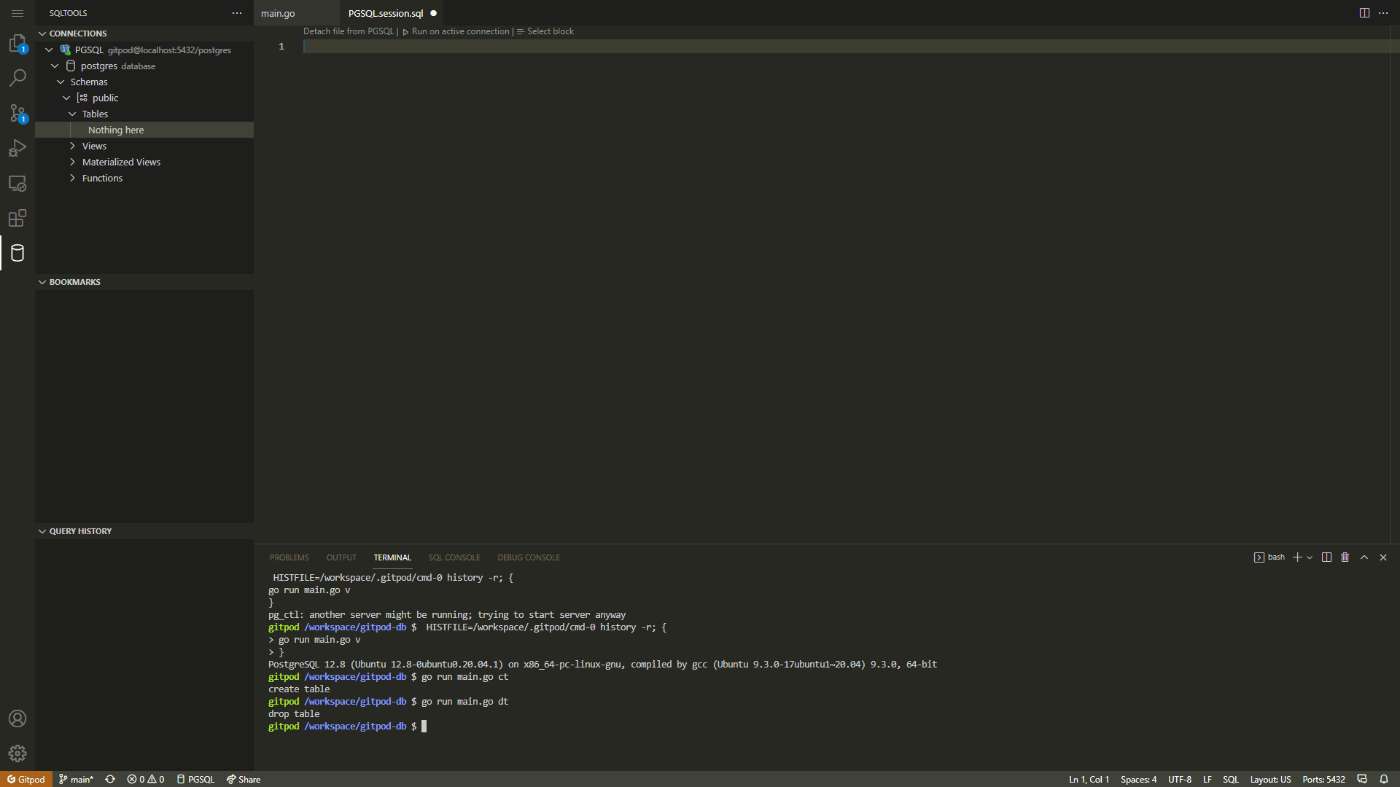
SQLToolsを更新するとpostsテーブルが削除されていることがわかります。
$ go run main.go ct
create table
もう一度テーブルを作って。
それではNewInsert()で行を挿入していきます。
Insert
...
case "i":
if len([]rune(a[1])) > 16 {
log.Fatal("error: insert")
}
v := map[string]interface{}{
"content": a[1],
}
if _, err := db.NewInsert().Model(&v).Table("posts").Exec(context.Background()); err != nil {
log.Fatal(err)
}
fmt.Println("insert")
...
$ go run main.go i abc
insert
文字列の長さを制限しておきます。念の為。
まずはModelにMapを追加します。この時キーの名前はデータベースの列名と同じものにしましょう。なのでスネークケースであることに注意。
次にTable("posts")でMapを挿入するテーブルを指定します。
TableExpr()を使用してクエリを叩くことも可能ですがTable()を使用すればテーブル名文字列として処理することが可能になるためオススメです。
例えばSQLインジェクションを防止することが出来たりするので可能な限り...Expr()を使わずに書いていきましょう。
そういえば構造体Postの説明をすっ飛ばしましたが、idはオートインクリメント機能を付与しており、created_at、updated_atはタイムスタンプ機能を付与しています。
なので今回Mapに書くキーはcontentだけで十分なんですね。
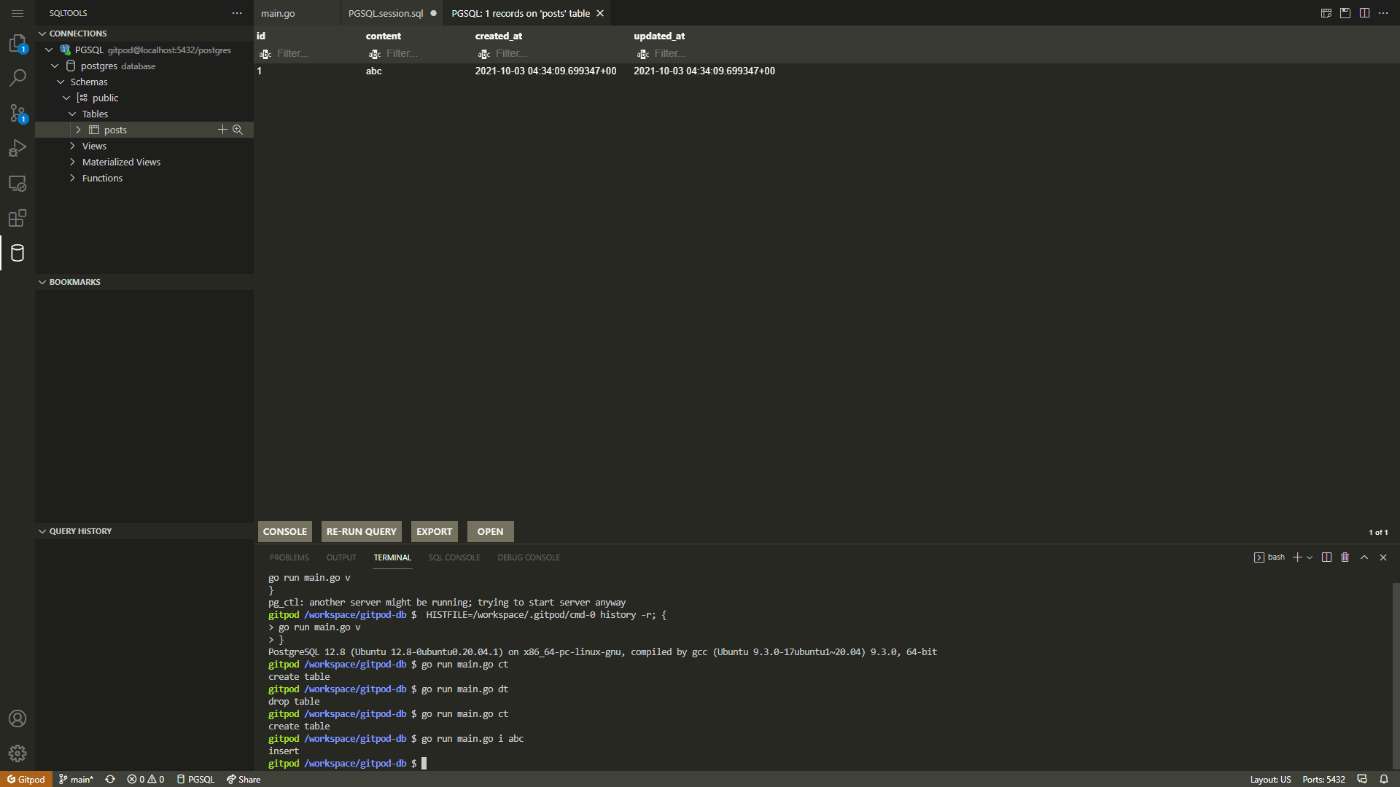
SQLToolsを確認するとpostsテーブルに行が追加されていることがわかります。
$ go run main.go i def
insert
$ go run main.go i あいうえお
insert
$ go run main.go i かきくけこ
insert
$ go run main.go i 🍔🍕🍖🍗
insert
なんか色々追加します。
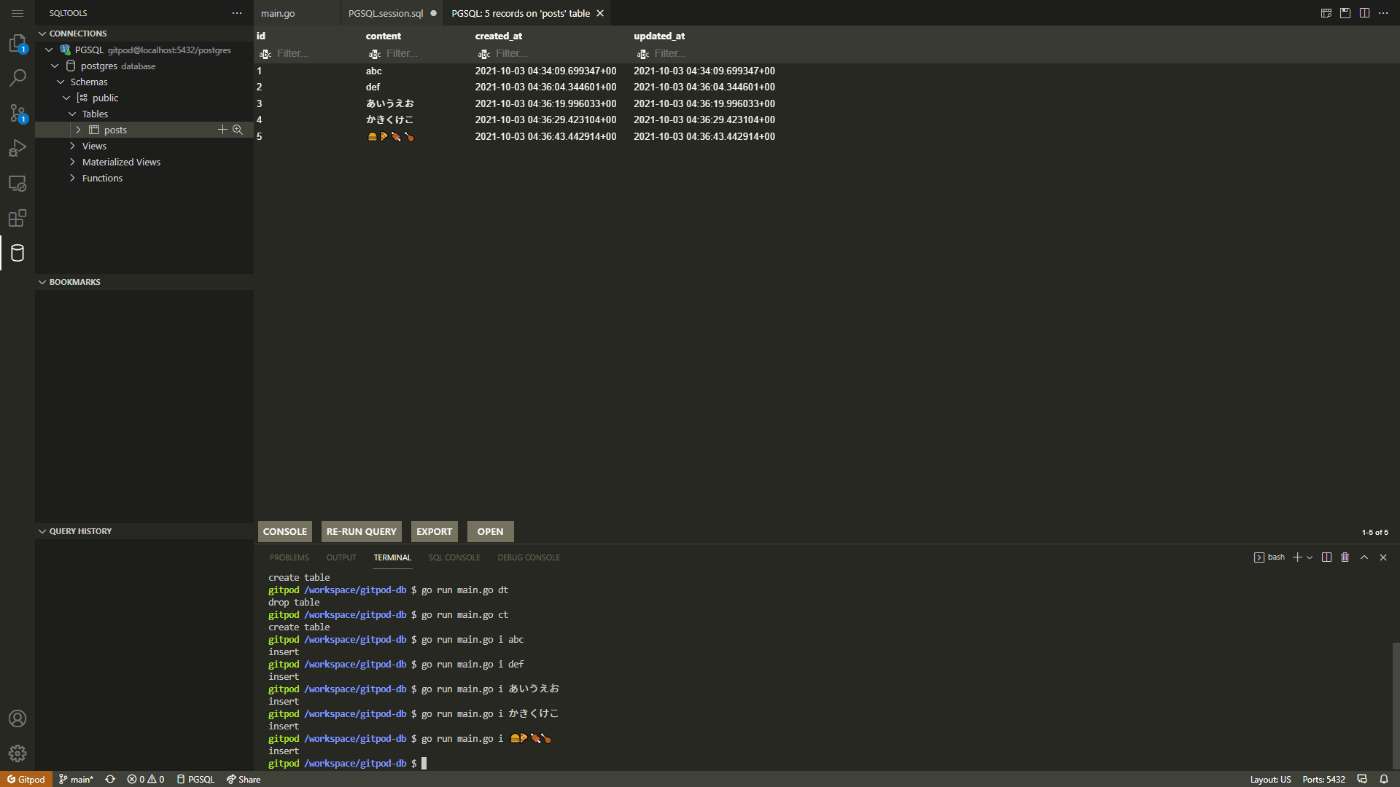
問題ないですね。
最後にBulk insertsで50行まとめて挿入してみます。
Bulk Insert
...
case "bi":
b := []byte("abcdef")
v := make([]Post, 50)
rand.Seed(time.Now().UnixNano())
for i := 0; i < len(v); i++ {
rand.Shuffle(len(b), func(i, j int) {
b[i], b[j] = b[j], b[i]
})
v[i] = Post{Content: string(b)}
}
if _, err := db.NewInsert().Model(&v).Exec(context.Background()); err != nil {
log.Fatal(err)
}
fmt.Println("bulk insert")
...
$ go run main.go bi
bulk insert
要素数50のSliceをmakeしてforループでランダム文字列をcontentキーに追加しまくります。
先程はMapを追加しましたが、Bulk insertsではModelにSliceを追加します。
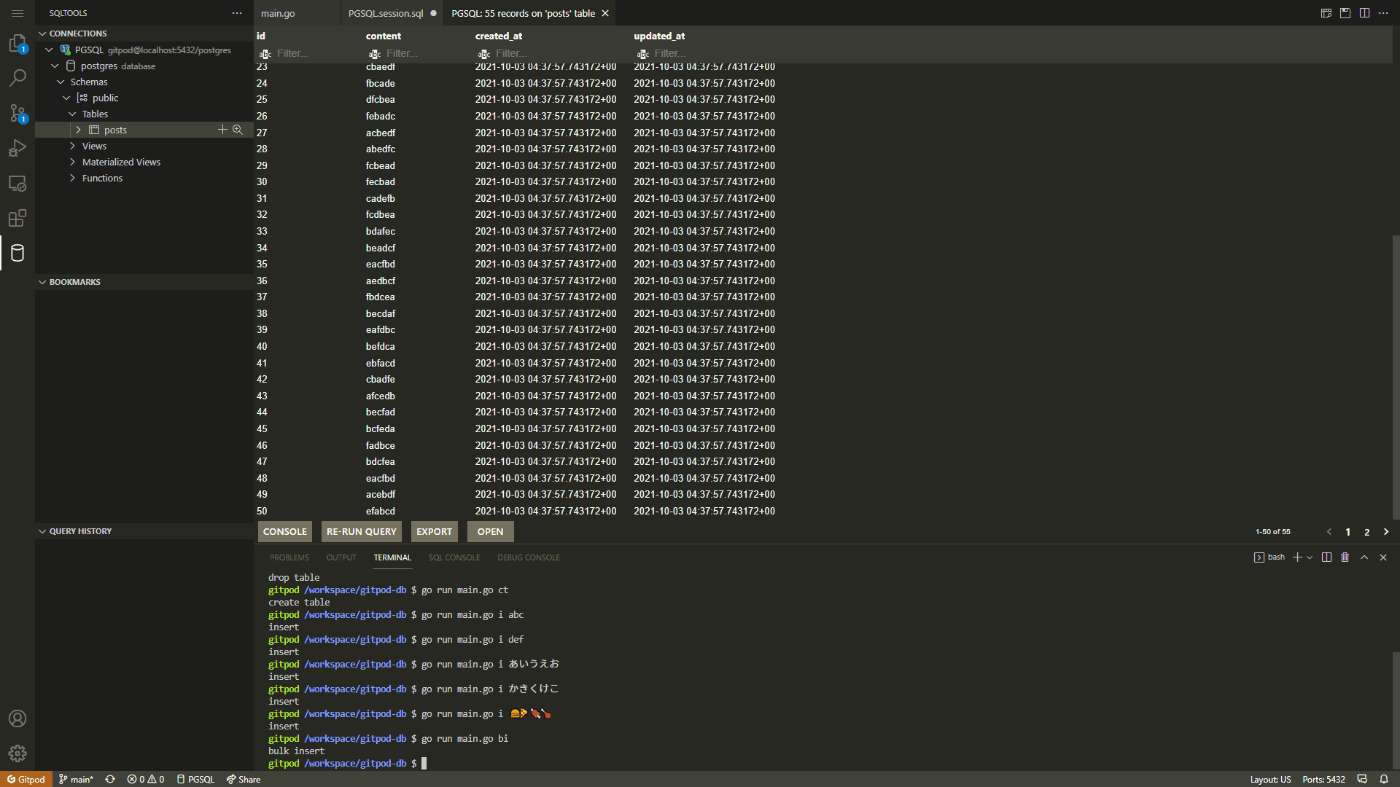
バッチリですね!
今まで紹介したコード全文を合体させたものがこちら。
Outro
駆け足で紹介してきましたがいかがでしょうか?
他のORMと一緒じゃん! と一瞬思いそうですが、Bunには様々な長所があります。
- 依存関係が少なく、サイズが小さい
これは結構メリットとして大きく感じました。BunではテストツールのTestifyなど必要最低限のパッケージしか使っておらず、PostgreSQLドライバーも自作したものを使用している(go-pgで作成したものを移植している)ため、jackc/pgxやjackc/pgxを使用した各ORM(gormなど)のようなサイズが大きくなるデメリットがありませんでした。
このような設計思想はgo-pgの頃からあるようで、私は以前から依存関係が少なく、サイズが小さいgo-pgを使用していたのですが、Bunでもダイアレクトとドライバーパッケージを分けているためgo-pgから移行するにあたって懸念していたサイズが大きくなる問題はなかったので安心しました。
ちなみにgo-pgを使う前はprisma-client-goを使用していたのですが、prisma-client-goそのものは軽いものの生成するスキーマがありえないぐらいサイズ大きかったためやめてしまいました。どうやらpkgを使用してprismaとNode.jsをくっつけてバイナリ化したものをGoで呼び出しているらしいです。
- SQLファーストなのでORMとして使う以外の利点がある
私はある程度SQLの知識を持っていますが、完全に理解したわけではないのでORMを使い続けています。ORMごとにAPIの名前が異なるなんてことはよくあることで、1つのAPIに2つ3つのSQL文の機能が追加されているORMがあったりします。
BunはAPI名が分かりやすく順序がある程度決まっているため入力補完で簡単に書けたり、一つ一つメソッドチェーンを大量に書き横長になってもgo fmtがうまいことやってくれてしかもちゃんと動くのでとても便利です。
何よりORMとして使用しているにも関わらずSQLの勉強ができます。もう分厚いSQLリファレンスを読まなくていいんだ!
ところでこの文章を書くためにあらためてBunの公式ドキュメントを見に行ったらPlaygroundツールが追加されていましたhttps://bun.uptrace.dev/playground/が公開終了したみたいです。
一応文章は残しておきます(以上追記)
SQLを書くとメソッドチェーンに自動変換して、さらにSQLへ再変換してFormatしてくれる神ツールです。
これすごくないですか!?
まあ現時点ではSELECT文だけだったり、Column()で書ける部分がColumnExpr()になっていたりするので少し機能不足だと感じる部分がありますが、こういった別のアプローチで新たな便利ツールを作れるのはSQLファーストならではの利点だと思いました。
- Bulk updatesなど便利な機能ある
Bulk updatesはgo-pgにもあるのですが他のSQLドライバーやORMにはない機能で、自分で書くとどうしても面倒になってしまう処理なのでBunでも引き続き使用できるようにしてくれて本当にありがたく感じます。
Bulk updatesは共通テーブル式を使用するため少し難しくなってしまいますが、Bulk()を使うことで可能な限りシンプルにできます。
その他にも今回紹介したBulk inserts、今回は紹介しませんでしたがBulk deletesやSoft deletesも使えるのでとても便利です。
また、フィクスチャツールやマイグレーションツールもオプションとして提供しているため、必要最低限の機能を有しているのも安心して使えるポイントです。
Bunを使いたくなった人も、すでに別のDBクライアントで満足している人も、Bunの今後にご期待ください!
Extra
- go-redis/redisも同じ作者が作っている。
- vmihailenco/msgpackも同じ作者が作っている。
- HTTP routerのuptrace/treemuxも同じ作者が作っていたが、最近BunRouterに改名して再出発している。
- BunはActivityPub実装GoToSocialで使われている
- UptraceはVue.js、Vuetifyを使って作られていたり、ドキュメント生成ツールとしてVuePressやMaterial for MkDocsを使っていて好感度高い
TODO: SQLToolsについて別で記事書く
Discussion