【VibeCodingChallenge#17】対話型絵画鑑賞ツール
はじめに
このVibeCodingChallengは、AIだけでコーディングを行い、AIに何ができて、何ができないのかを探る個人的な企画です。
突然ですが、美術館や展覧会で行われる「対話型鑑賞法(Visual Thinking Strategies: VTS)」をご存知ですか?
作品を前に「何が見える?」「なぜそう思った?」と問いかけながら、参加者同士で見方を広げる方法です。
正解を求めず、観察と解釈を通じて作品理解を深めるのが特徴で、最近は、ビジネスマンのひらめき力向上にも利用されているとか。
いいね、ひらめき力欲しい!
今回は、このVTSをAIチャットボットに組み込み、作品名や作家名は絶対に言わないルールを加えた鑑賞支援ツールを作りました。
Google Cloud の Vertex AI Gemini マルチモーダル(Visionや、2.5Proなどのモデル) を使い、アップロードされた画像から観察ポイントと問いかけを生成します。
最終成果物
今回はゴッホのひまわりを使って実際にやってみました。
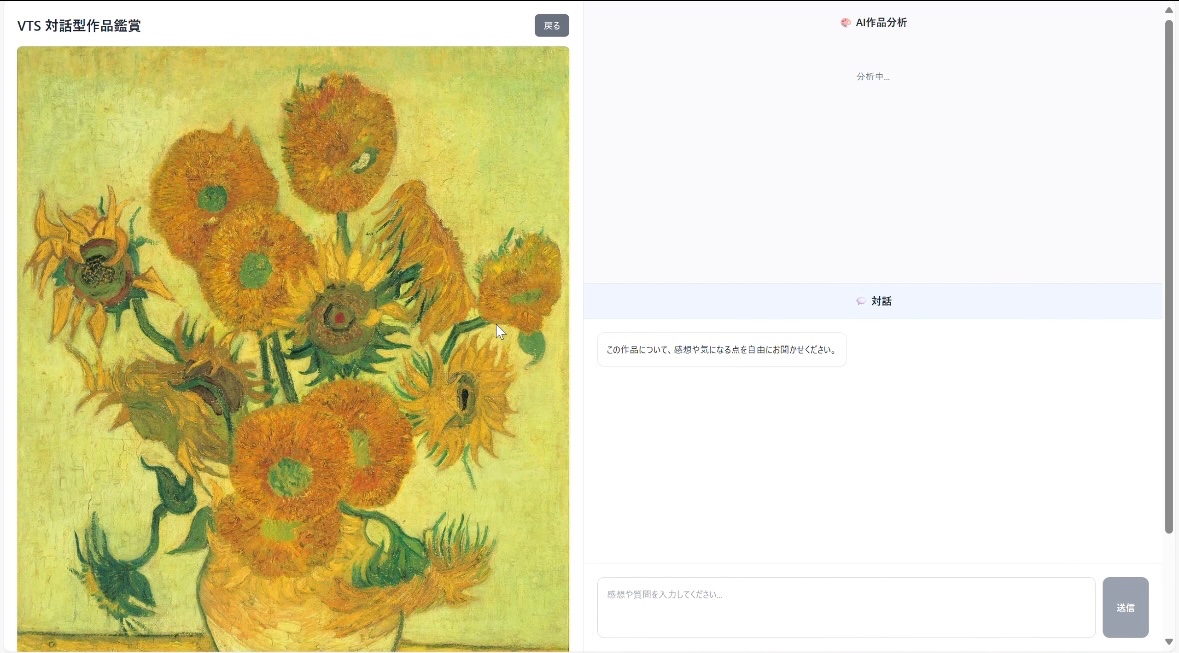
- 画像をアップロードすると、AIが以下の流れで返答
- 観察→色・形・構図などの事実
- 解釈→断定せず2〜3案
- 一般論→必要時のみ、技法や時代の背景を1文で)
- 質問→オープンな問いを1つ
- 会話→問いに対して、なめらかに返答
- 作者や作品名の要求には必ず拒否テンプレートで回答し、観察に戻す
今回のひまわりでは、AIの解釈はこんな感じでした

そして、対話はこんな感じ。共感しつつ、話しつつ、オープンな問いを投げつつ、気付きを与えるようなスタイルの会話です。

技術構成
- フロント:Next.js (React)
- API:Node.js(Express) → Cloud Run
- モデル:Google Cloud Vertex AI Gemini マルチモーダル(Visionや、2.5Proなどのモデル)
- セッション管理:開発時はメモリMap
今回の学び
1. メモリMap
段階では、会話履歴を管理するために JavaScript の Map(連想配列)を使いました。
これはサーバーのメモリ上にデータを保持するだけの簡単な方法で、コード数行で実装でき、読み書きも高速です。
const sessions = new Map();
sessions.set("abc123", [{ role: "user", text: "こんにちは" }]);
本来はFirestoreやRedisなどのストレージに格納するイメージですが、今回のように、今回はちょっとしたテストしかするつもりがないので十分でした。
2.Gemini マルチモーダルの活用
今回使用した Gemini マルチモーダルモデル は、テキストと画像を同時に入力でき、アップロードした画像から色や形、構図などの特徴を抽出し、文章として返すことができます。
これにより、「観察 → 解釈 → 質問」という自然な鑑賞の流れを自動生成できました。
強みと注意点は以下の通りです。
強み
• 視覚的特徴を的確に抽出できる
• 画像に関連する自然な問いかけを作れる
• テキストと画像を組み合わせて文脈を維持できる
注意点
• モデルは知識が豊富なため、固有名詞(作品名や作家名)を出したがる傾向がある
→ プロンプトだけでなく、サーバー側でも同定ワード検知&拒否テンプレを実装する必要があった
• 高解像度画像をそのまま送ると処理が遅くなる
→ 事前に縮小&WebP化してパフォーマンスを確保
終わりに
このチャットボットのように、人に伴走して気付きを与えるAIに僕は日本の勝機が実はあるかもと思っています。LLMの競争はアメリカ、中国に任せておいて、日本はどうそれを使うか?を真剣に考えると、どらえもんやアトムのような、伴走して、共感して、ワークしてくれる。そんな日本ならではの使い方を提案していくのがいいのかなと、チャットボットを作っていて思いました。
今後もAIだけでVibeCodingをどんどんしていきますので、読み物としてお楽しみください。
Discussion